What You Make Of It
We’ve got this query. Handsome devil of a query.
You can pretend it’s in a stored procedure, and that the date filter is a parameter if you want.
SELECT u.DisplayName, p.Score FROM dbo.Users AS u JOIN dbo.Posts AS p ON p.OwnerUserId = u.Id WHERE u.CreationDate >= '20131201';
A long time ago, when we migrated Stack Overflow from Access to SQL Server 2000, we created indexes.
This one has worked alright.
CREATE INDEX ix_whatever
ON dbo.Posts(OwnerUserId);
But Now We’re On 2019
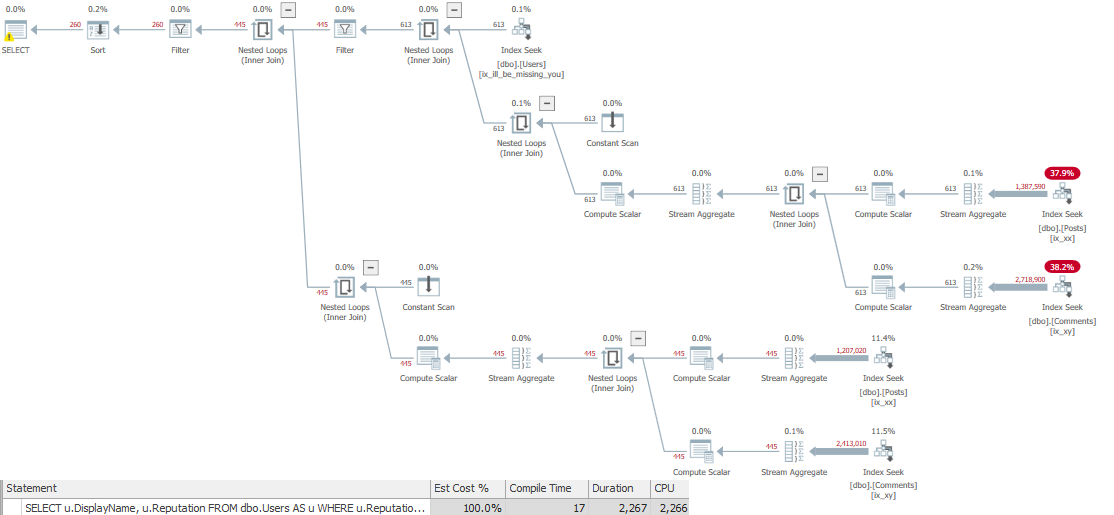
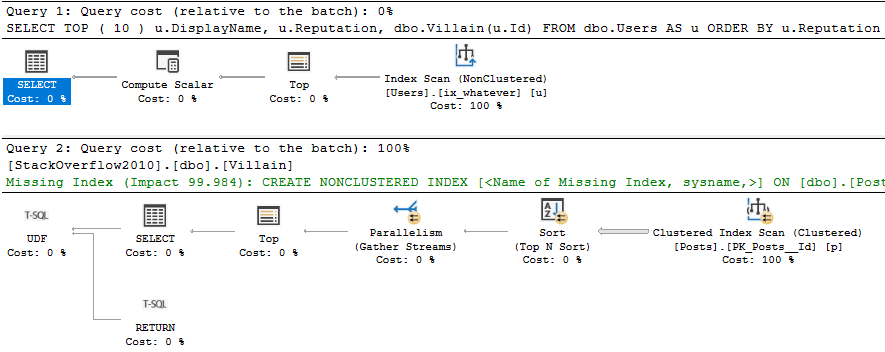
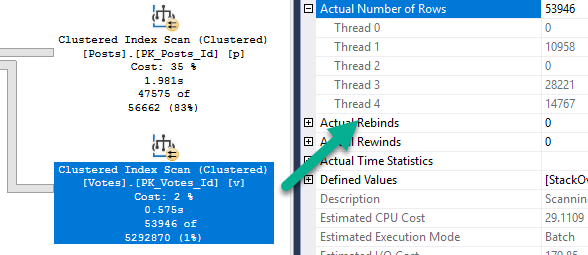
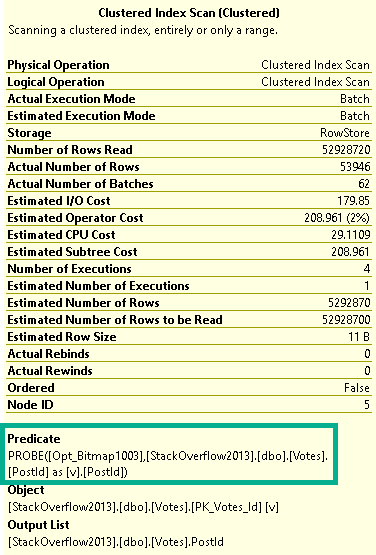
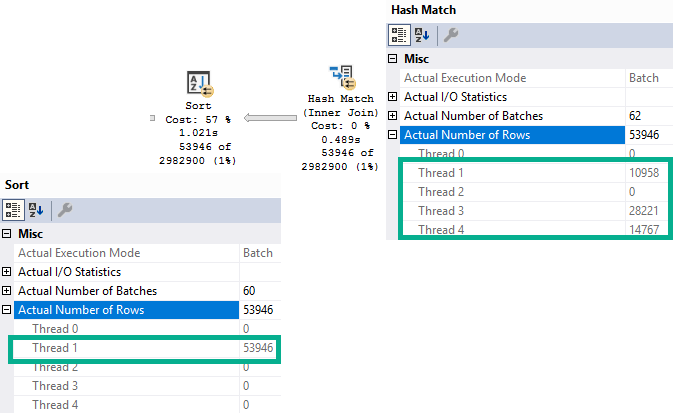
And we’ve, like, read a lot about Adaptive Joins, and we think this’ll be cool to see in action.
Unfortunately, our query doesn’t seem to qualify.
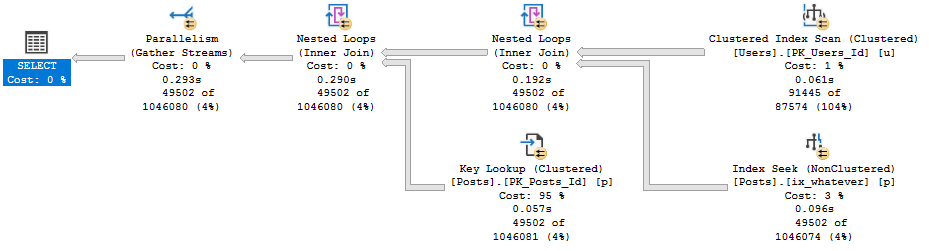
Now, there’s an Extended Event that… Used to work.
These days it just stares blankly at me. But since I’ve worked with this before, I know the problem.
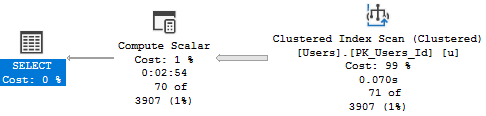
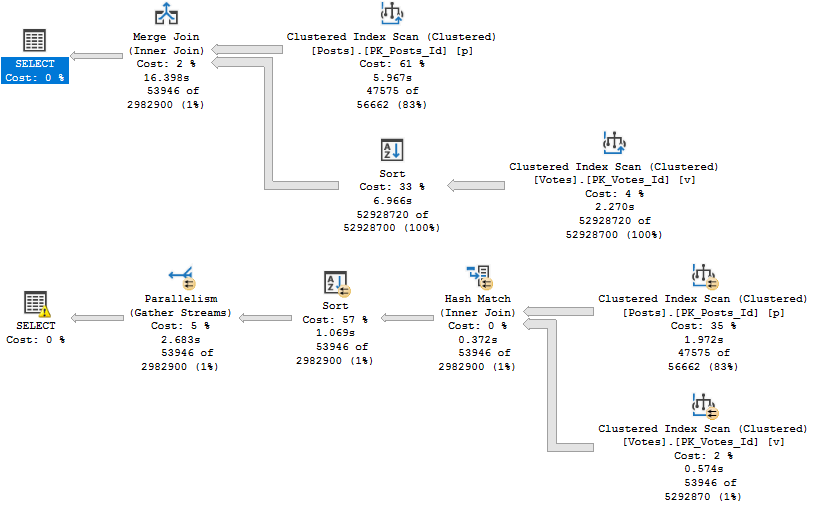
It’s that Key Lookup — I’ll explain more in a minute.
Index Upgrade
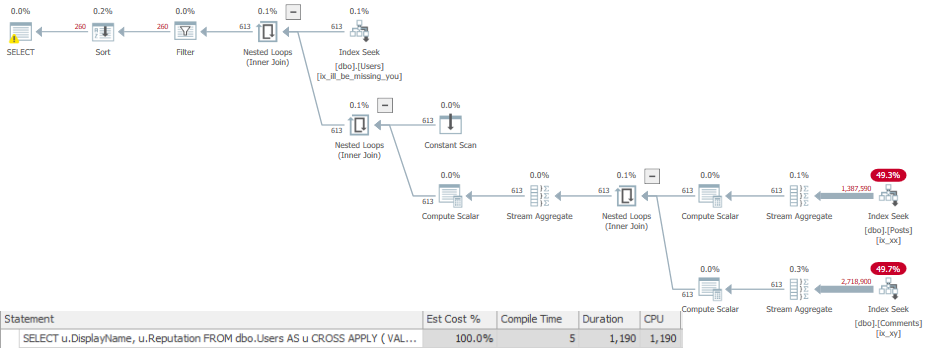
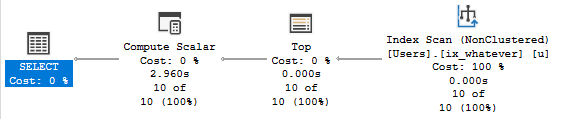
First, let’s get rid of the Lookup so we can see the Adaptive Join happen.
CREATE INDEX ix_adaptathy
ON dbo.Posts(OwnerUserId, Score);
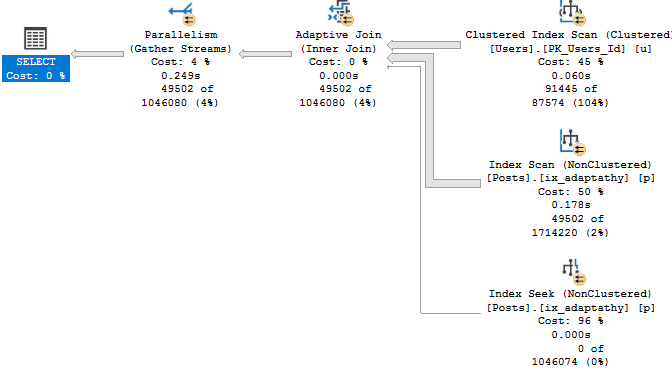
As We Proceed
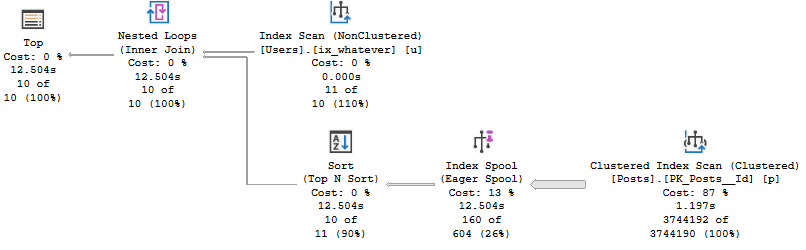
Let’s think about what Adaptive Joins need:
- An index on the column(s) you’re joining
This gives us a realistic choice between using a Nested Loops join to do efficient Seeks, or an easy scan for a Hash Join.
- That index has to cover the query
Without a covering index, there’s too much for the optimizer to think about.
It’s not just making a choice between a Nested Loops or Hash Join, it’s also factoring in the cost of a Lookup.
This used to trigger the XE on eajsrUnMatchedOuter, meaning the outer table didn’t have an index that matched the query.
Why Revisit This?
When SQL Server 2019 comes out, people are gonna have really high hopes for their workloads automagickally getting faster.
While there are lots of things that it’ll likely help, it’s going to take a lot of work on your part to make sure your queries and indexes allow for the automagick to kick in.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.