Oft Evil
I had a client recently with, wait for it, a performance problem. Or rather, two problems.
The OLTP part was working fine, but there was a reporting element that was dog slow, and would cause all sorts of problems on the server.
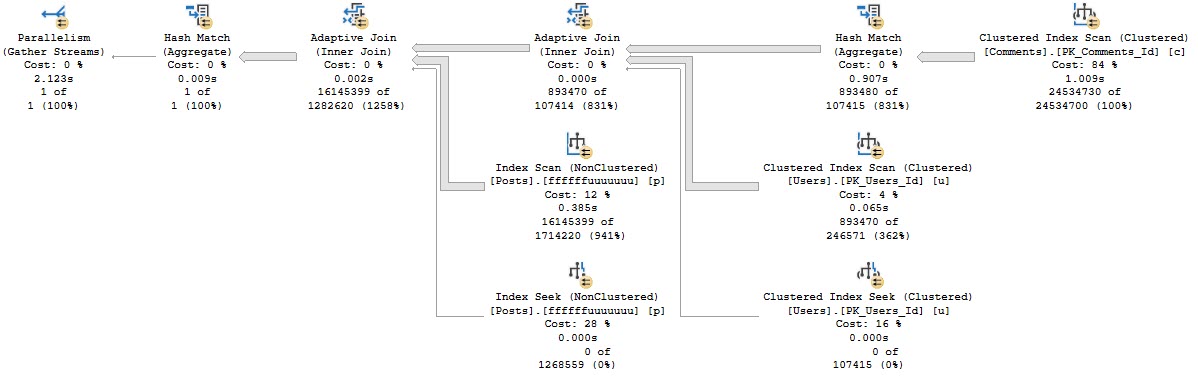
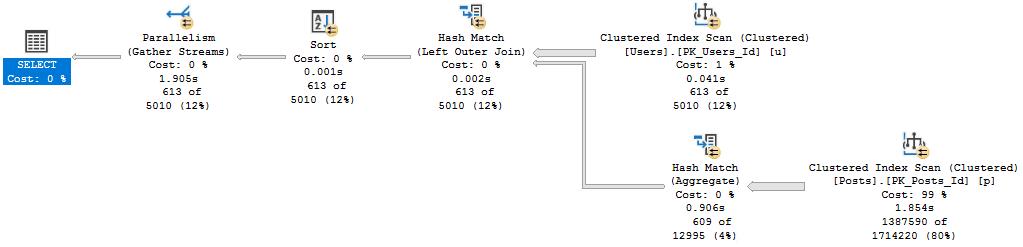
When we got into things, I noticed something rather funny: All of their reporting queries had very high estimated costs, and all the plans were totally serial.
The problem came down to two functions that were used in the OLTP portion, which were reused in the reporting portion.
Uh Ohs
I know what you’re thinking: 2019 would have fixed it.
Buuuuuuuuuuut.
No.
As magnificent and glorious as FROID is, there are a couple limitations that are pretty big gotchas:
The UDF does not invoke any intrinsic function that is either time-dependent (such as GETDATE()) or has side effects3 (such as NEWSEQUENTIALID()).
And
1 SELECT with variable accumulation/aggregation (for example, SELECT @val += col1 FROM table1) is not supported for inlining.
Which is what both were doing. One was doing some date math based on GETDATE, the other was assembling a string based on some logic, and not the kind of thing that STRING_AGG would have helped with, unfortunately.
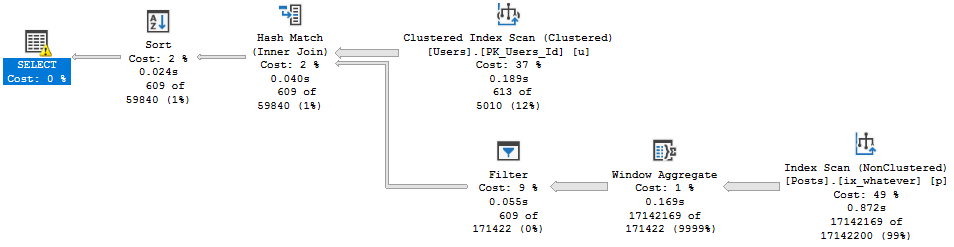
They could both be rewritten with a little bit of work, and once we did that and fixed up the queries using them, things looked a lot different.
Freeee
For these plans, it wasn’t just that they were forced to run on one CPU that was harming performance. In some cases, these functions were in WHERE clauses. They were being used to filter data from tables with many millions of rows.
Yes, there was a WHERE clause that looked like AND dbo.function(somecol) LIKE ‘%thing%’, which was… Brave?
Getting rid of those bottlenecks relieved quite a lot of pain.
If you want to find stuff like this on your own, here’s what you can do:
- Looking at the execution plan, hit get the properties of the select operator and look for a “NonParallelPlanReason”
- Run sp_BlitzCache and look for “Forced Serialization” warnings
- Inspect Filter operators in your query plans (I’m almost always suspicious of these things)
- Review code for scalar valued function calls
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.