From The Beginning
Implementing soft deletes for an app that’s been around for a while can be tough. In the same way as implementing Partitioning can be tough to add in later to get data management value from (rebuilding clustered indexes on the scheme, making sure all nonclustered indexes are aligned, and all future indexes are too, and making sure you have sufficient partitions at the beginning and end for data movement).
Boy, I really stressed those parentheses out.
If you do either one from the outset, it’s far less painful to manage. The structural stuff is there for you from the beginning, and you can test different strategies early on before data change become difficult to manage.
Queries
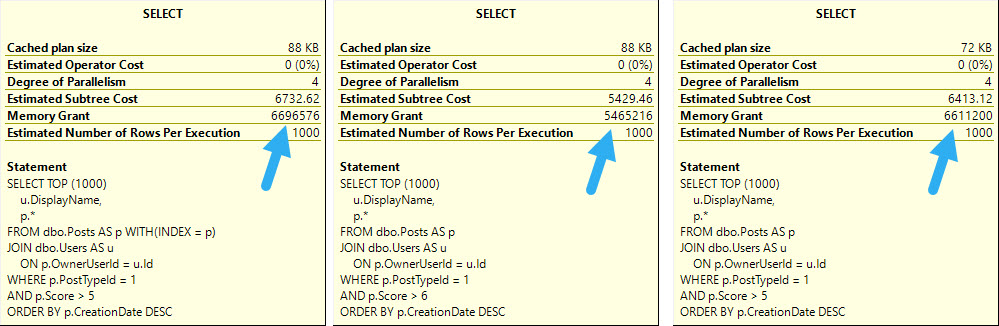
The first and most obvious thing is that all your queries now need to only find data that isn’t deleted.
Almost universally, it’s easier to put views on top of tables that have the appropriate bit search for deleted or not deleted rows than to expect people to remember it.
CREATE VIEW dbo.Users_Active
AS
SELECT
u.*
FROM dbo.Users AS u
WHERE u.is_deleted = 0;
CREATE VIEW dbo.Users_Inactive
AS
SELECT
u.*
FROM dbo.Users AS u
WHERE u.is_deleted = 1;
It’s not that views have any magical performance properties; they’re just queries after all, but it gives you an explicit data source.
Indexes
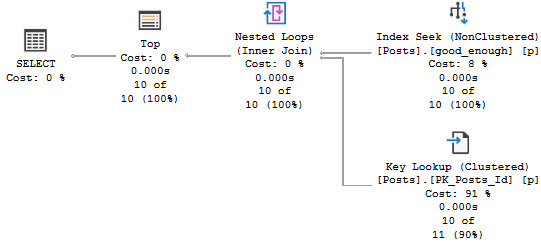
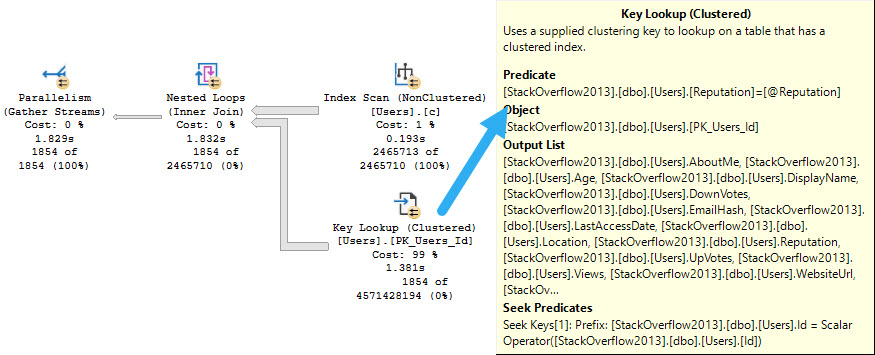
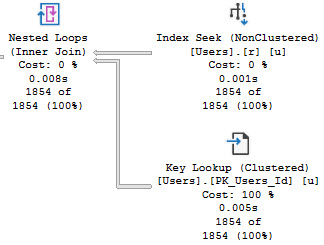
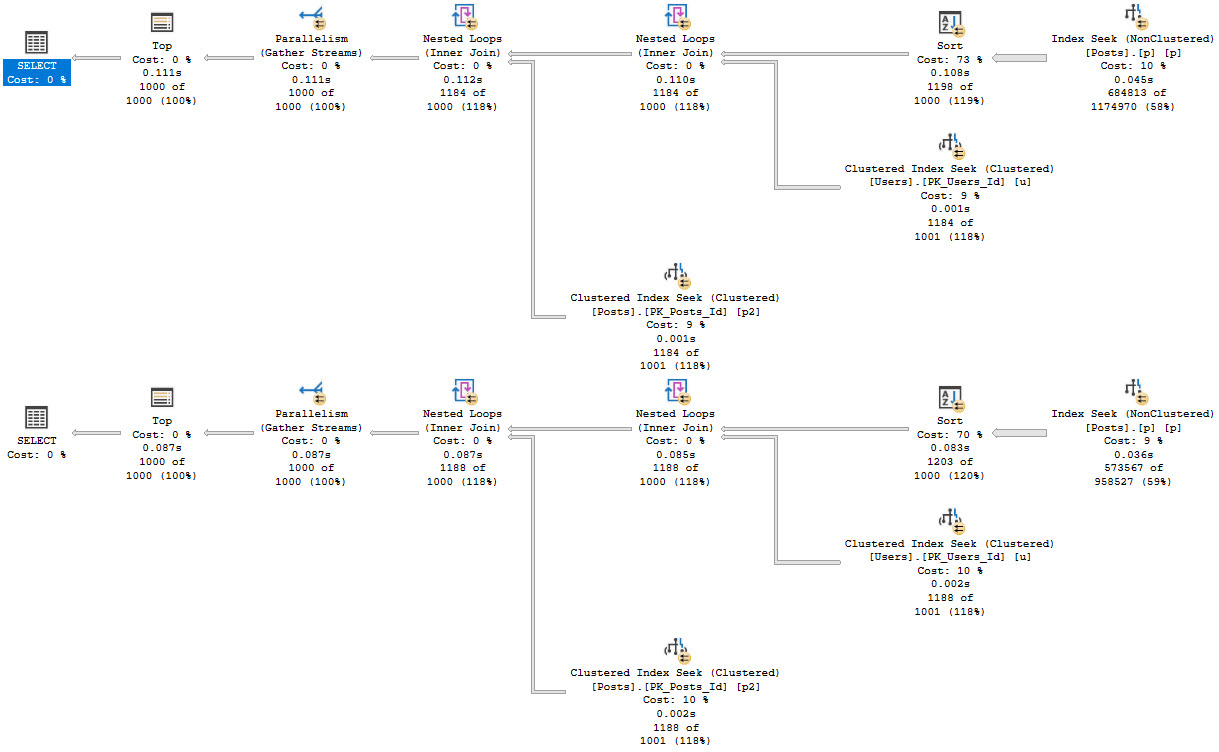
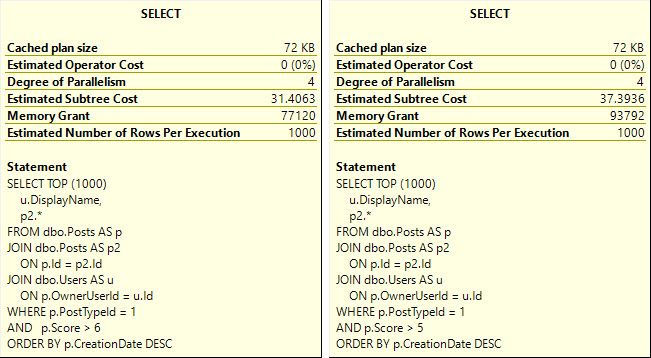
Depending on how your other queries search for data, you may need to start accounting for the is_deleted flag in your indexes. This could make a really big difference if the optimizer stops choosing your narrower nonclustered indexes because it hates key lookups.
Typically, other predicates will give you a selective-enough result set that a residual predicate on a bit field won’t make much difference. If you’ve already got a seek to the portion of data you’re interested in and most of it will be not-deleted, who cares?
And let’s be honest, in most implementations deleted rows will be the minority of data, and searches for it will be far less common. Usually it’s just there for an occasional audit.
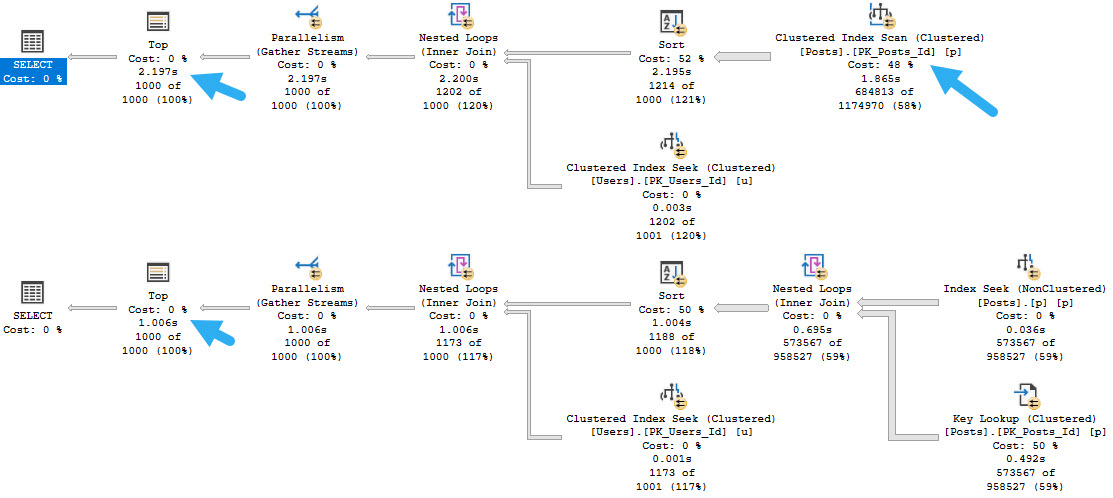
In adjacent cases where instead of deleted you need to designate things as currently active, and you may have many inactive rows compared to active rows, filtered indexes can be your best friend.
Coming back to the views, I don’t think that making them indexed is necessary by default, but it might be if you’re using forced parameterization and filtered indexes.
CREATE TABLE dbo.Users(id int, is_deleted bit);
GO
CREATE INDEX u ON dbo.Users (id) WHERE is_deleted = 0;
GO
SELECT
u.id, u.is_deleted
FROM dbo.Users AS u
WHERE u.is_deleted = 0;
Under simple parameterization, this can be fine. Under forced parameterization, things can get weird.

Tables and Tables
In some cases, it might be easier to create tables specifically for deleted rows so you don’t have unnecessary data in your main tables. You can implement this easily enough with after triggers. Just make sure they’re designed to handle multiple rows.
If you want something out of the box, you might mess with:
- Temporal tables
- Change Data Capture
- Change Tracking
However, none of those help you deal with who deleted rows. For that, you’ll need an Audit.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.