The Importance Of Being Parameterized
Parameterization has many benefits for queries.
- You tend to make better use of the plan cache, which usually means less time spent compiling and recompiling queries
- Your queries will be more secure, because they won’t be prone to SQL injection attacks, which are horribly common
But first, let’s cover two things that aren’t exactly parameters!
Much more details at the post, but local variables are any variable that you declare inside a code block, e.g.
DECLARE
@a_local_variable some_data_type;
And unsafe dynamic SQL is when parameters or local variables are concatenated into a string like so:
@sql += N'AND H.user_name = ''' + @injectable + ''';';
Note the series of single quotes and + operators (though the same would happen if you used the CONCAT function), and that square brackets alone won’t save you.
Now let’s talk about actual parameterization.
The same concept applies to ORM queries, but I can’t write that kind of code so go to this post to learn more about that.
Stored Procedures
The most obvious way is to use a stored procedure.
CREATE OR ALTER PROCEDURE
dbo.Obvious
(
@ParameterOne int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
END;
There are millions of upsides to stored procedures, but they can get out of hand quickly.
Also, the longer they get, the harder it can become to troubleshoot individual portions for performance or logical issues.
Developers without a lot of SQL experience can make a ton of mistakes with them, but don’t worry: young, good-looking consultants are standing by to take your call.
Inline Table Valued Functions
There are other kinds of functions in SQL Server, but these are far and away the least-full of performance surprises.
CREATE OR ALTER FUNCTION
dbo.TheOnlyGoodKindOfFunction
(
@ParameterOne int
)
RETURNS table
AS
RETURN
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
GO
Both scalar and multi-statement types of functions can cause lots of issues, and should generally be avoided when possible.
Inline table valued functions are only as bad as the query you put in them, but don’t worry: young, good-looking consultants are standing by to take your call.
Dynamic SQL
Dynamic SQL gets a bad rap from people who have:
- No idea what they’re talking about
- All the wrong kinds of experience with it
DECLARE
@sql nvarchar(MAX) = N'',
@ParameterOne int;
SELECT
@sql += N'
SELECT
records = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Id = @ParameterOne;
';
EXEC sys.sp_executesql
@sql,
N'@ParameterOne int',
@ParameterOne;
This kind of dynamic SQL is just as safe and reusable as stored procedures, but far less flexible. It’s not that you can’t cram a bunch of statements and routines into it, it’s just not advisable to get overly complicated in here.
Note that even though we declared @ParameterOne as a local variable, we pass it to the dynamic SQL block as a parameter, which makes it behave correctly. This is also true if we were to pass it to another stored procedure.
Dynamic SQL is only as bad as the query you put in it, but don’t worry: young, good-looking consultants are standing by to take your call.
Forced Parameterization
Forced parameterization is a great setting. It’s unfortunate that everything thinks they want to turn on optimize for adhoc workloads, which is a pretty useless setting.
You can turn it on like so:
ALTER DATABASE [YourDatabase] SET PARAMETERIZATION FORCED;
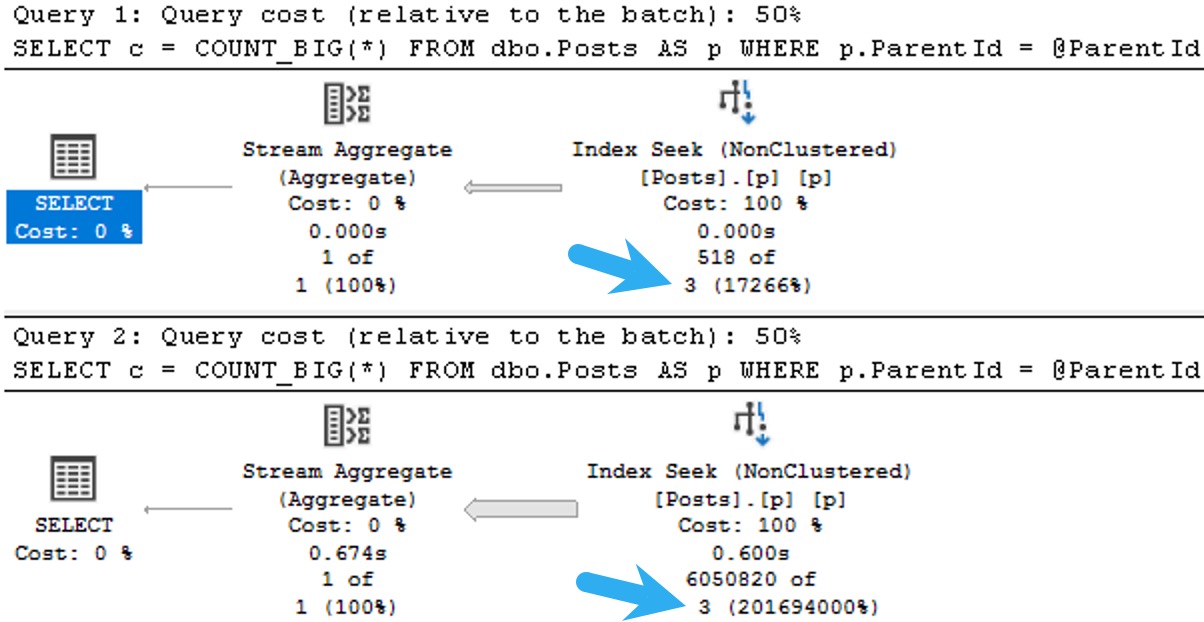
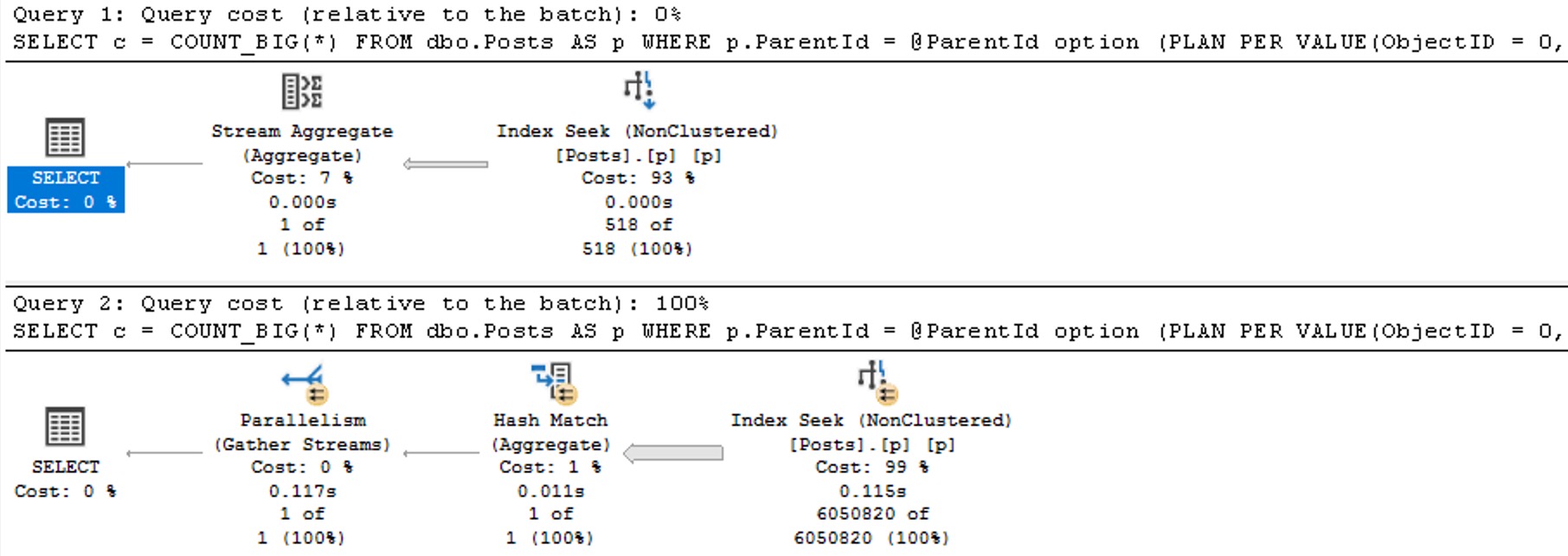
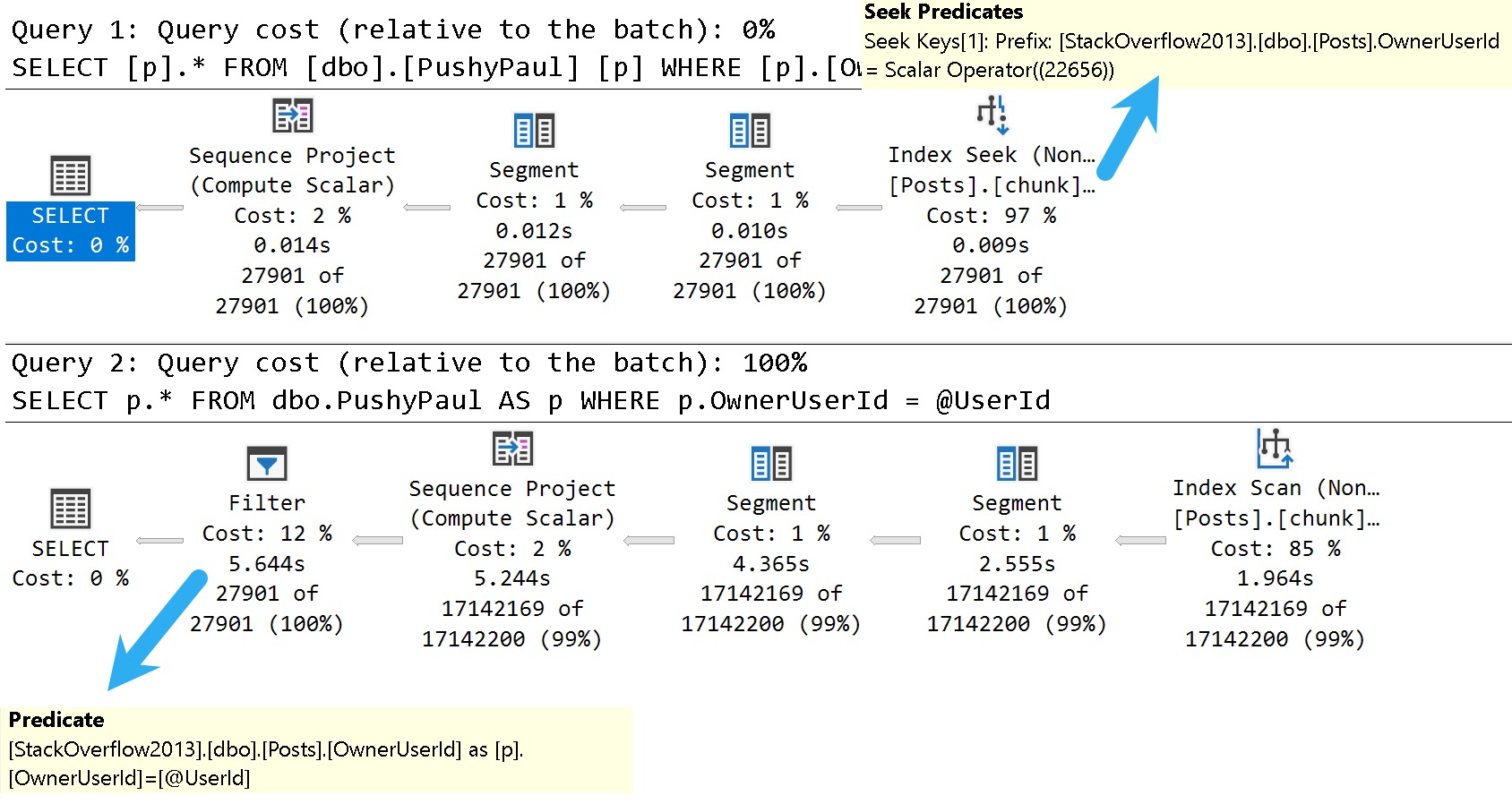
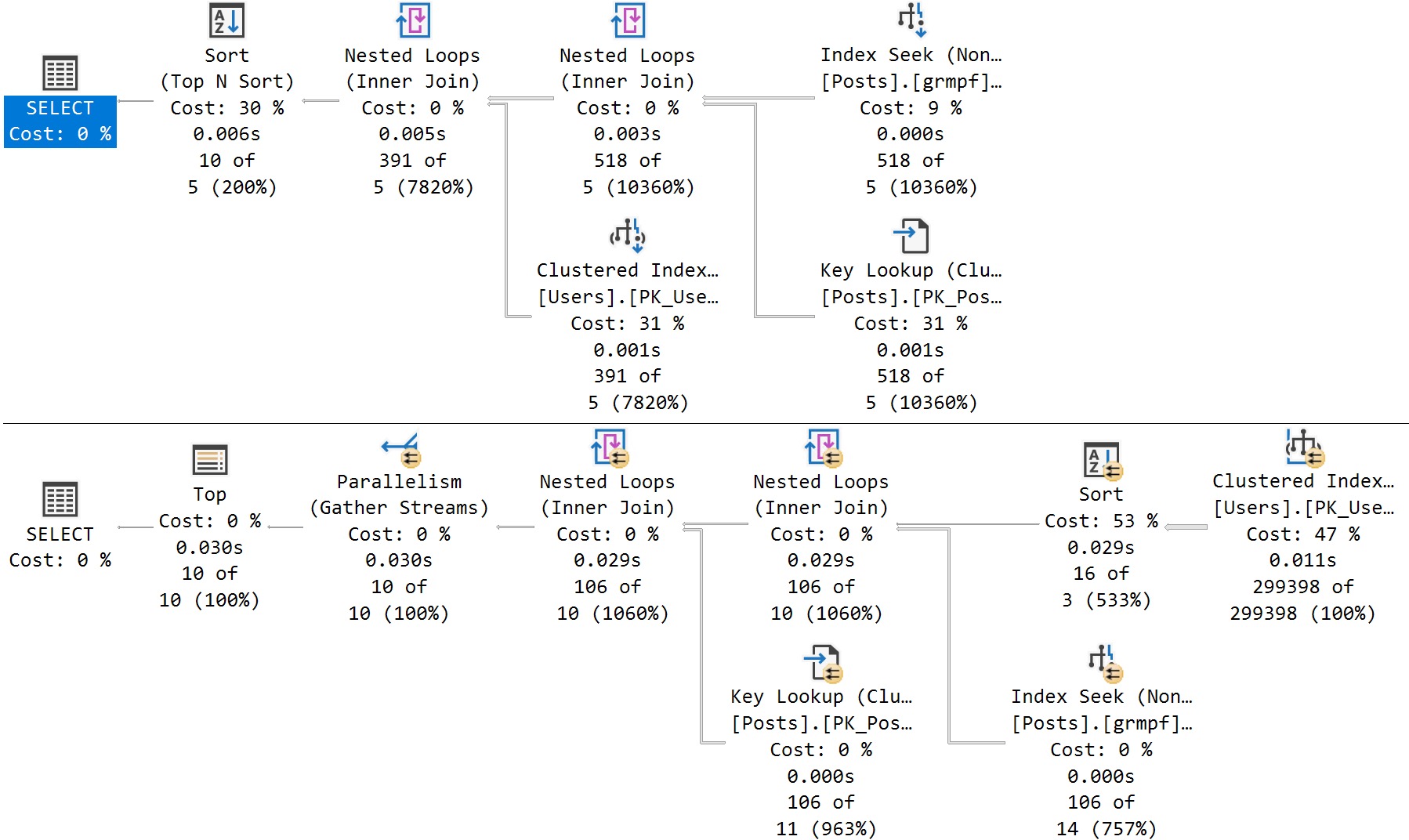
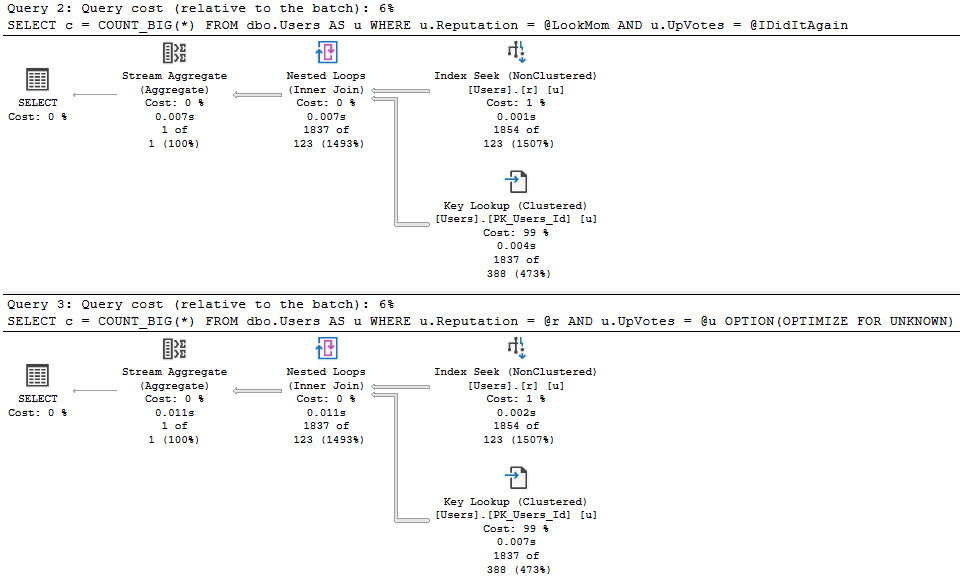
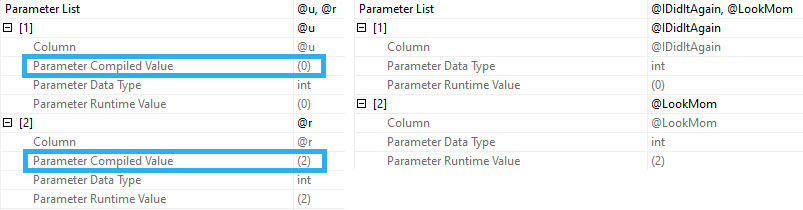
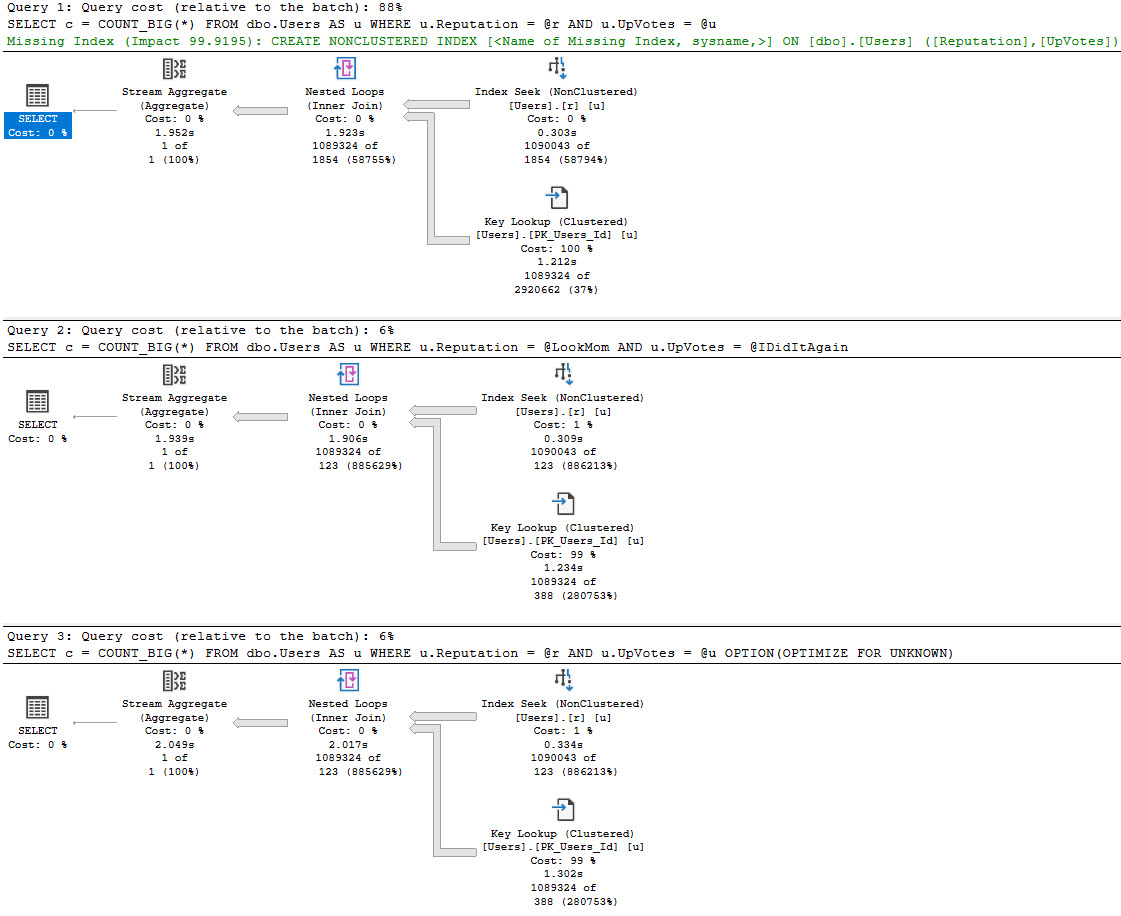
Forced parameterization will take queries with literal values and replace them with parameters to promote plan reuse. It does have some limitations, but it’s usually a quick fix to constant-compiling and plan cache flushing from unparameterized queries.
Deciding whether or not to turn on this feature can be tough if you’re not sure what problem you’re trying to solve, but don’t worry: young, good-looking consultants are standing by to take your call.
Other
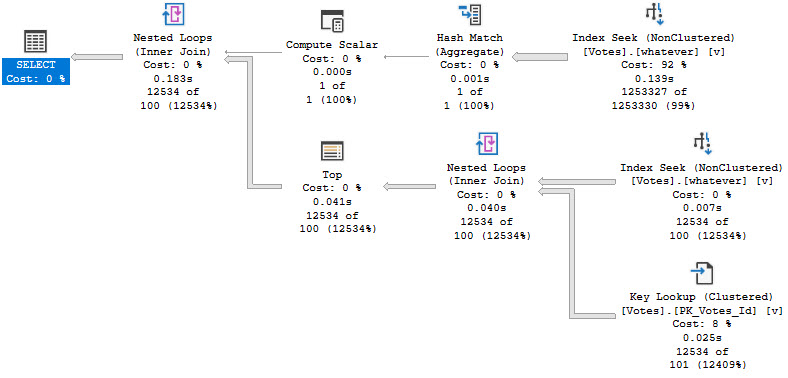
SQL Server may attempt simple parameterization in some cases, but this is not a guaranteed or reliable way to get the majority of the queries in your workload parameterized.
In general, the brunt of the work falls on you to properly parameterize things. Parameters are lovely things, which can even be output and shared between code blocks. Right now, views don’t accept parameters as part of their definitions, so they won’t help you here.
Figuring out the best thing to use and when to use it can be tough, but don’t worry: young, good-looking consultants are standing by to take your call.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.