Two Words
Alright, I’ve lied to you already. There are way more than two words involved, here.
I recently had breakfast (JUST BREAKFAST, GOD) with Microsoft’s Most Handsome Man™, and the topic came up.
Partially because there are such fundamental changes coming to SQL Server, and also because it’s already the default in Azure SQL DB.
If I had to name a redeeming quality of Azure SQL DB, that would be it.
Unboxing
I’ve seen pessimistic locking causing problems and heartache on many, many servers.
While it wasn’t totally the fault of the isolation level (query and index tuning was needed, and there was some other silliness), it shouldn’t take that kind of dedication to make It Just Run Faster©.
Possibly the worst side effect is people leaning heavily on reading dirty data (via read uncommitted/nolock) to avoid issues.
You can’t preach about the evils of dirty reads without offering ways to avoid blocking.
Yes, I’m looking at you.
You all cackle at seeing NOLOCK everywhere, but I don’t hear much about solving blocking problems without it.
Standards and Futures
Right now “other major database platforms” offer optimistic locking as the default.There are implementation differences, but the net result is the same.
Readers and writers don’t suffer locking contention, and only fully committed data is read.
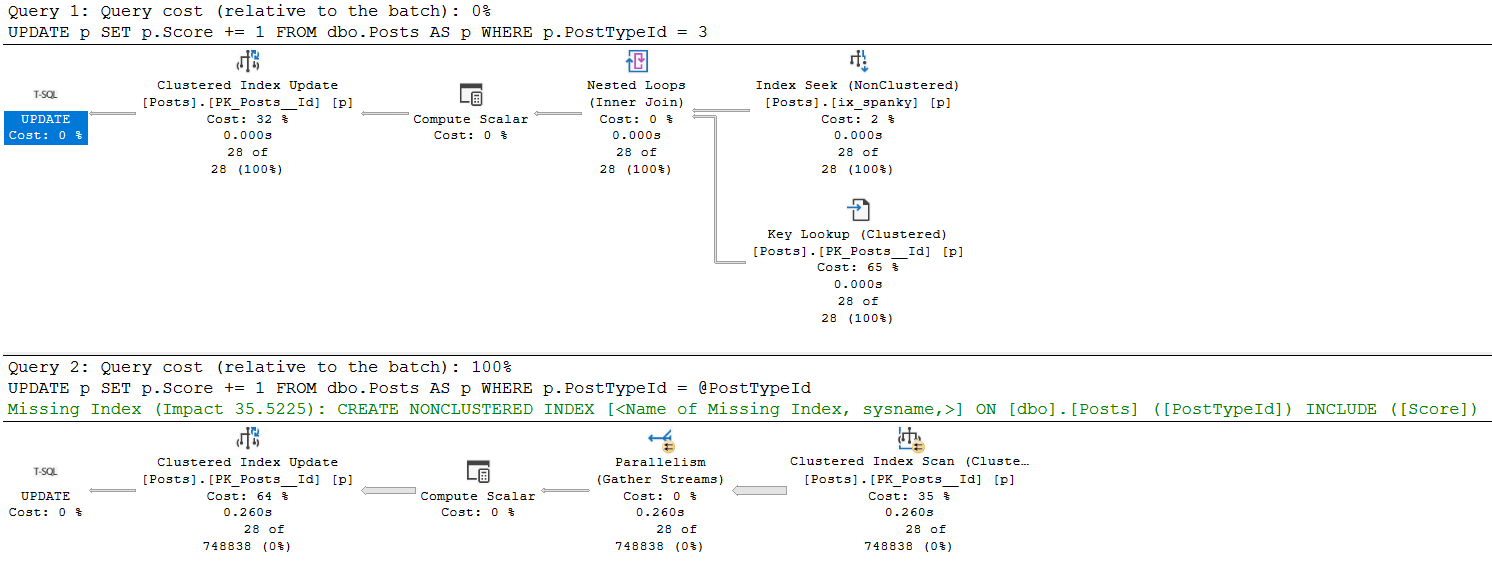
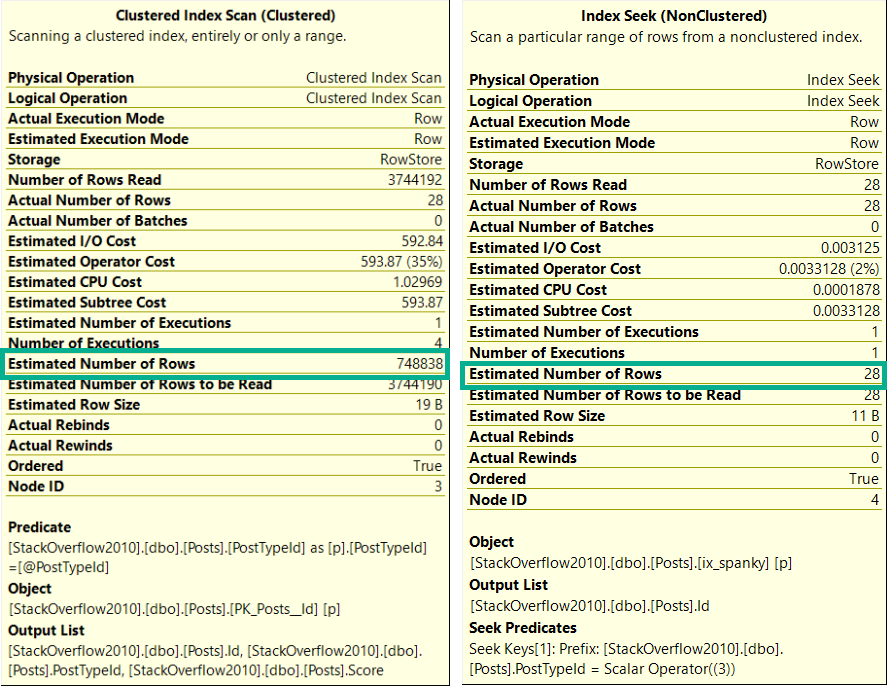
SQL Server currently offers optimistic locking via Read Committed Snapshot Isolation (RCSI from here), and Snapshot Isolation (SI from here).
Right now, they both send row versions to tempdb. But in the works for SQL Server 2019 is a feature called Accelerated Database Recovery (ADR from here). The mechanism that makes this possible is a Persistent Version Store (PVS from here) that’s local to the database, not tempdb.
While RCSI and SI could end up sending quite a bit of data to tempdb, which could cause contention there without a lot of precautions and setup work, any potential contention from ADR would be localized.
I know, Microsoft has been addressing tempdb, too. Setup now configures tempdb in a mostly sane way, and trace flags 1117 and 1118 are the default behavior in 2016+. That should make optimistic locking a more comfortable setting for people, but no. No. I hardly ever see it in use.
Dependencies
Breaking changes are hard. I know, there are people out there who depend on pessimistic locking for certain patterns to maintain correctness.
The thing is, it’s a lot easier to have just these processes use pessimistic locking while allowing the rest of the us to not have to sprinkle NOLOCK hints every which where to get a report to run.
An example of a process that requires some locking hints is Paul White’s post about Sequence Tables.
At this point in time, if you’re implementing a queue in SQL Server, you should be the one learning about how to get the kind of locking you need to get it working. Normal people who just want their app to work shouldn’t be the ones staring at articles about isolation levels, locking hints, lock escalation, etc.
Get It, Get It
This is a good problem to get in front of. I’d be quite happy to not have to talk about the reader/writer aspects of locking anymore.
In the same way, it would be nice to not have to talk to users who are endlessly frustrated by locking problems, explain dirty reads, explain optimistic isolation levels, caution them against certain issues, and then tell them to have fun removing all those old lock hints.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.