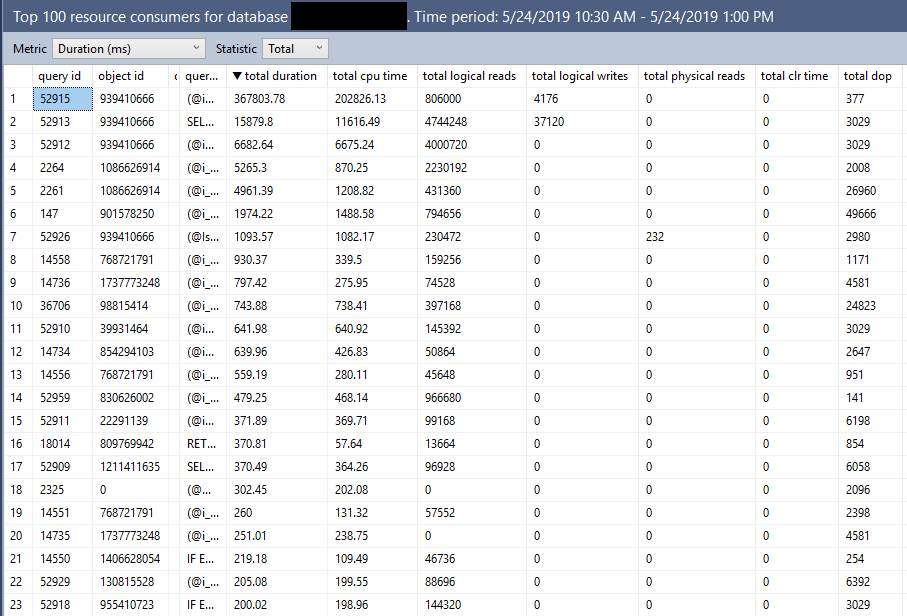
I was workload testing on SQL Server 2019 RC1 when I ran into a wait type I’d never noticed before: PVS_PREALLOCATE. Wait seconds per second was about 2.5 which was pretty high for this workload. Based on the name it sounded harmless but I wanted to look into it more to verify that.
The first thing that I noticed was that total signal wait time was suspiciously low at 12 ms. That’s pretty small compared to 55000000 ms of resource wait time and suggested a low number of wait events. During testing we log the output of sys.dm_os_wait_stats every ten seconds so it was easy to graph the deltas for wait events and wait time for PVS_PREALLOCATE during the workload’s active period:
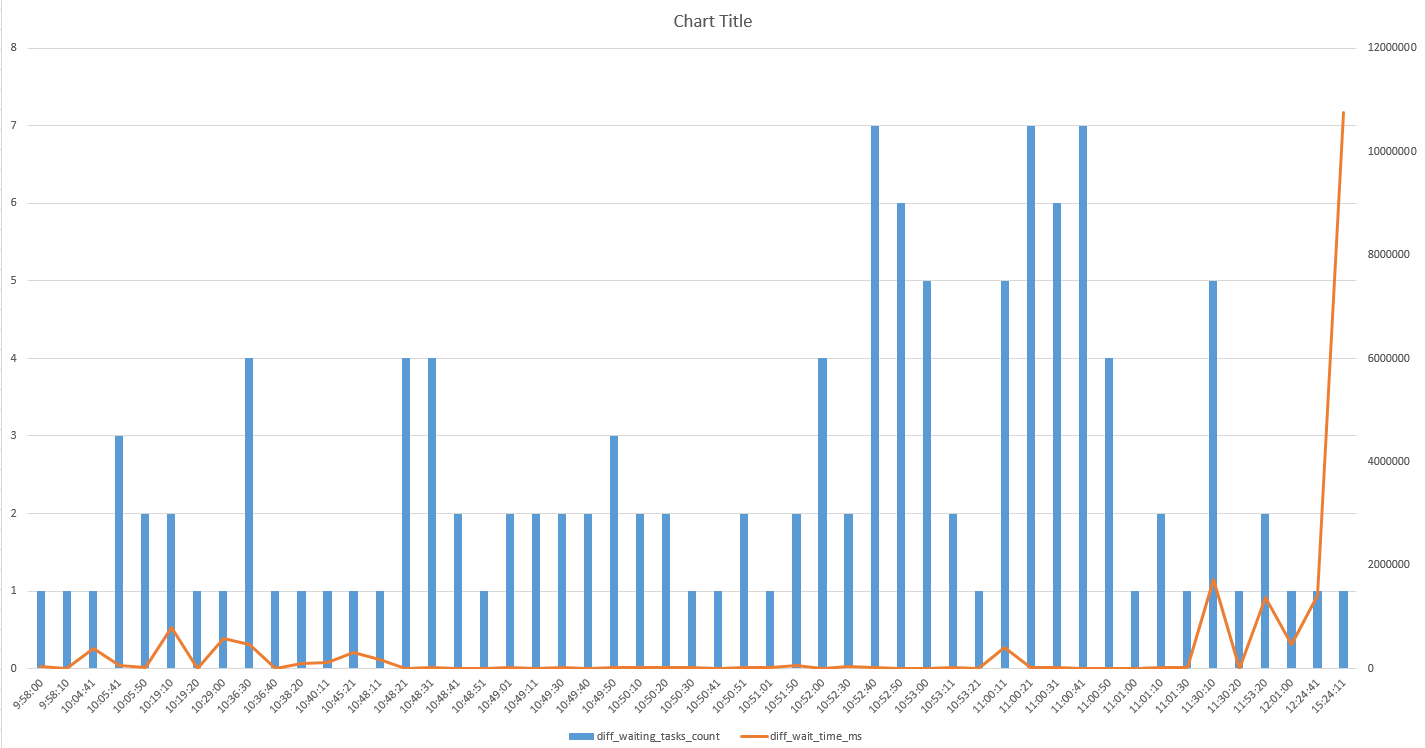
This is a combo chart with the y-axis for the delta of waiting tasks on the left and the y-axis for the delta of wait time in ms on the right. I excluded rows for which the total wait time of PVS_PREALLOCATE didn’t change. As you can see, there aren’t a lot of wait events in total and SQL Server often goes dozens of minutes, or sometimes several hours, before a new wait is logged to the DMV.
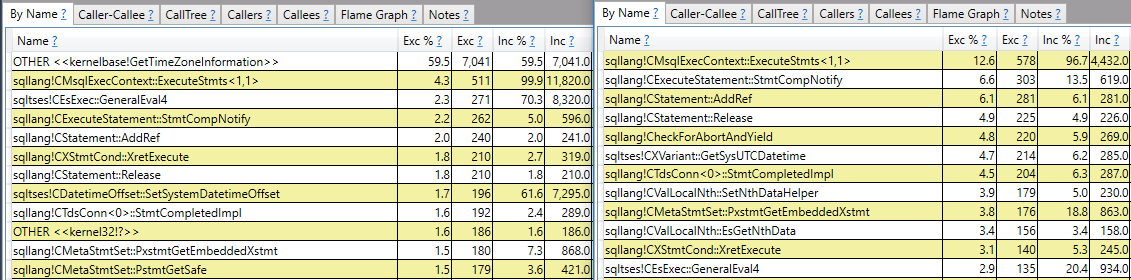
This pattern looked like a single worker that was almost always in a waiting state. To get more evidence for that I tried comparing the difference in logging time with the difference in wait time. Here are the results:
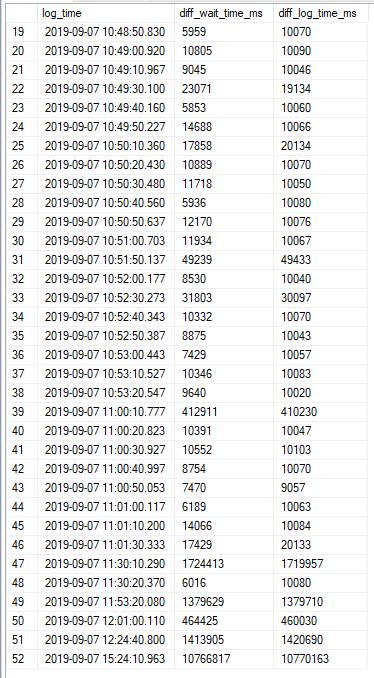
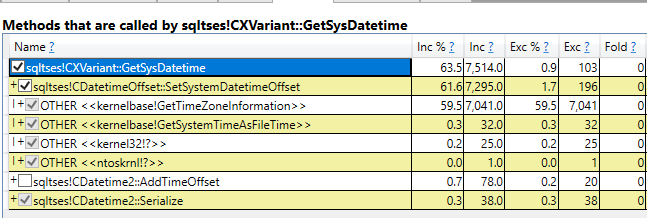
Everything matches within a margin of error of 10 seconds. Wait stats are logged every 10 seconds so everything fits. The data looks exactly as it should if a single session was almost always waiting on PVS_PREALLOCATE. I was able to find said session:

I did some more testing on another server and found that all waits were indeed tied to a single internal session id. The PVS_PREALLOCATOR process starts up along with the SQL Server service and has a wait type of PVS_PREALLOCATE until it wakes up and has something to do. Blogging friend Forrest found this quote about ADR:
The off-row PVS leverages the table infrastructure to simplify storing and accessing versions but is highly optimized for concurrent inserts. The accessors required to read or write to this table are cached and partitioned per core, while inserts are logged in a non-transactional manner (logged as redo-only operations) to avoid instantiating additional transactions. Threads running in parallel can insert rows into different sets of pages to eliminate contention. Finally, space is pre-allocated to avoid having to perform allocations as part of generating a version.
That’s good enough for me. This wait type appears to be benign from a waits stats analysis point of view and I recommend filtering it out from your queries used to do wait stats analysis.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.