Such Optimize
At this point in your life, you’ve probably seen, and perhaps even struggled with how to fix a key lookup that was causing you some grief.
This post isn’t going to go terribly deep into anything, but I do want to make a few things about them more clear, because I don’t usually see them mentioned anywhere.
- Lookups are joins between two indexes on the same table
- Lookups can only be done via nested loops joins
- Lookups can’t be moved around in the execution plan
I don’t want you to think that every lookup is bad and needs to be fixed, but I do want you to understand some of the limitations around optimizing them.
The Join
When you see a lookup in an execution plan, it’s natural to focus on just what the lookup is doing.
But there’s something else lurking in here, too.
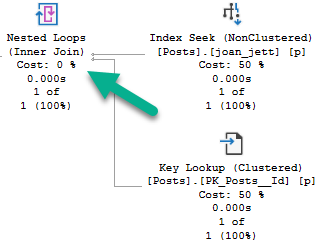
That nested loops join is what’s bringing the data from a nonclustered index to the data in a clustered index (or heap, but but whatever).
For every row that comes out of the index seek on the nonclustered index, we go back to the clustered index to find whatever data is missing from it in the clustered index. It could be columns in the select list, where clause, or both.
Much like index union or index intersection, but much more common. For a table with a clustered index, the join condition will be on the clustered index key column(s), because in SQL Server, nonclustered indexes inherit clustered index key columns. For heaps, it’ll be on the row identifier (RID).
You can most often see that by looking at the tool tip for the Lookup, under Seek Predicates.
The Loop
At this point, SQL Server’s optimizer can’t use merge or hash joins to implement a lookup.
It can only use nested loops joins.
That’s a pretty big part of why they can be so tricky in plans with parameter sniffing issues. At some point, the number of loops you can end up doing is far more work than just scanning as clustered index all in one shot.
There’s also no “adaptive join” component to them, where SQL Server can bail on a loop join after so many executions and use a scan instead. Maybe someday, but for now this isn’t anything that intelligent query processing touches.
They can look especially off in Star Join plans sometimes, where it’s difficult to figure out why the optimizer went with the lookup for many more rows than what people often call the “tipping point” between lookups and clustered index scans.
The Glue
Another pesky issue with lookups is that the optimizer doesn’t currently support moving the join between the two indexes around at all.
You can get this behavior on your own by rewriting the lookup as a self join (which is all a lookup really is anyway — a self join that the optimizer chose for you).
For instance, here are two query plans. The first one is where the optimizer chose a lookup plan. The second is one where I wrote the query to self join the Users table to itself.
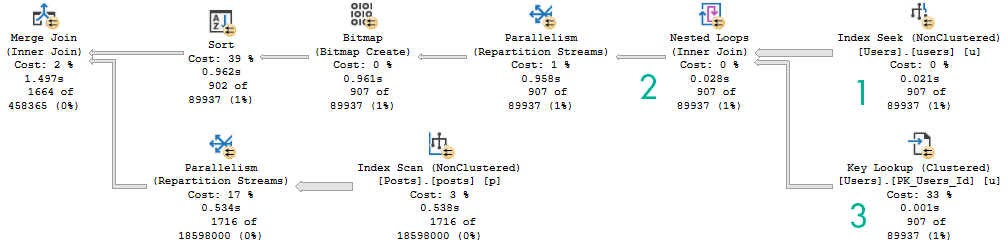
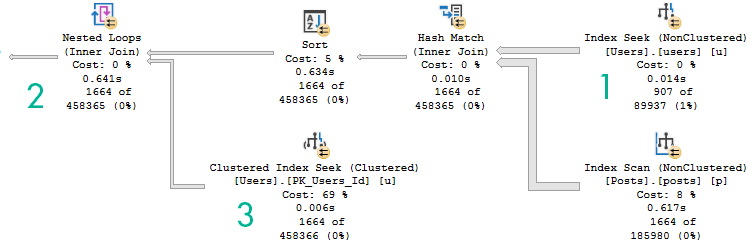
The thing to understand here is that when there’s a lookup in a query plan, it is inseparably coupled.
When you write queries as self joins, the optimizer has many more choices available to it as far as join order, join type, and all the other usual steps that it can take during optimization. A simplified example of doing that (not related to the query plans above), would look like this:
CREATE INDEX joan_jett
ON dbo.Posts
(
PostTypeId, Score
);
/* Not In The Index */
SELECT p.Id, p.PostTypeId, p.Score, p.CreationDate
FROM dbo.Posts AS p
WHERE p.PostTypeId = 7
AND p.Score = 0
AND p.OwnerUserId = -1;
/* Not In The Index*/
/* From p2 */
SELECT p.Id, p.PostTypeId, p.Score, p2.CreationDate
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2 --Self join
ON p2.Id = p.Id
WHERE p.PostTypeId = 7
AND p.Score = 0
AND p2.OwnerUserId = -1;
/* From p2 */
The index is only on PostTypeId and Score, which means the CreationDate and OwnerUserId columns need to come from somewhere.
Probably more interesting is the second query. The Posts table is joined to itself on the Id column, which is the primary key and clustered index (for style points, I suppose), and the columns not present in the nonclustered index are selected from the “p2” alias of the Posts table.
AND BASICALLY
Sometimes I take these thing for granted, because I learned them a long time ago. Or at least what seems like a long time ago.
But they’re things I end up talking with clients about frequently, and sometimes even though they’re not optimizer oddities they’re good posts to write.
Hopefully they’re also good posts for reading, too.
Thanks for doing that.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.