If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
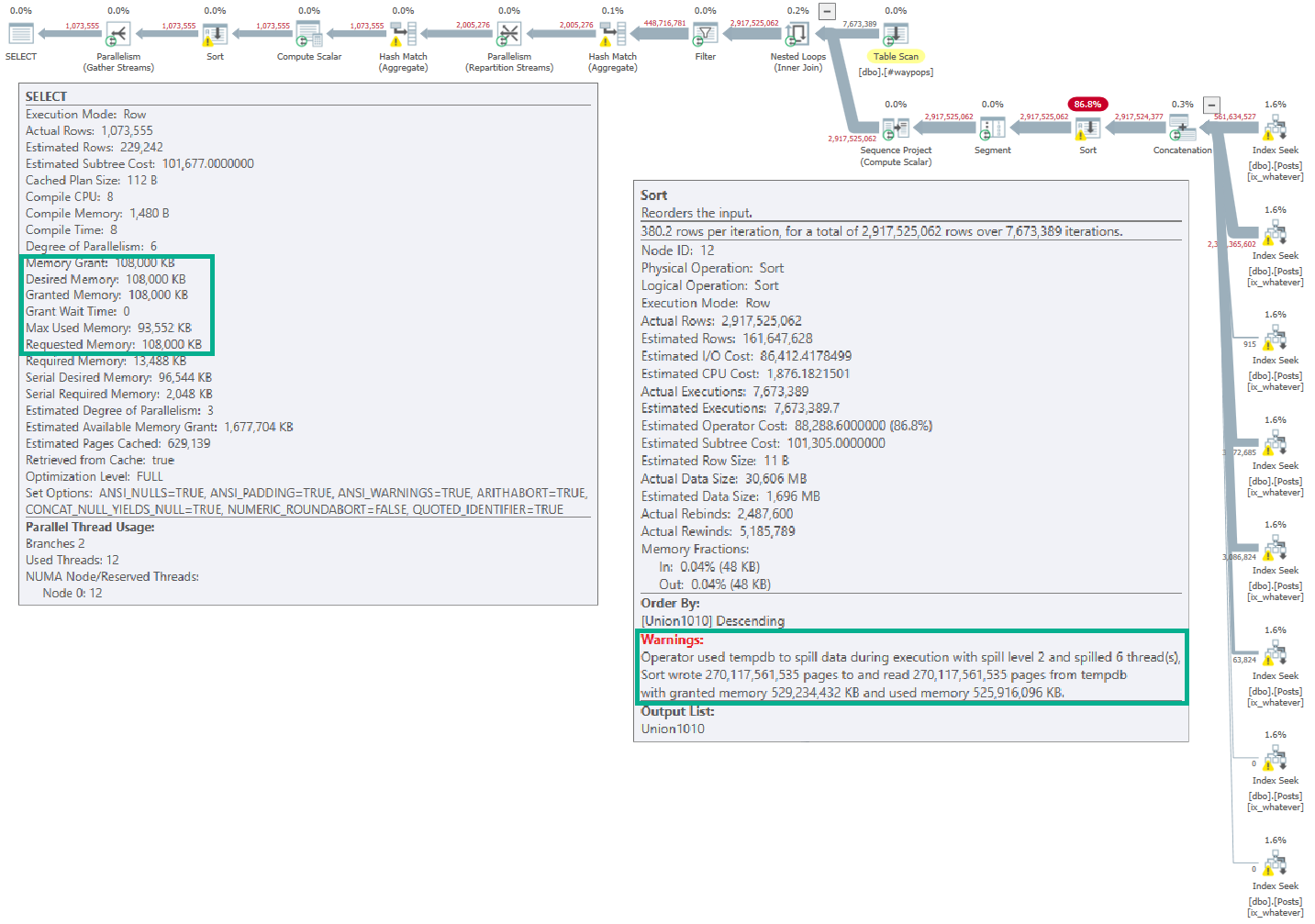
I have no idea if this is a bug or not, but I thought it was interesting. Looking at information added to spills in SQL Server 2016…
If you open the linked-to picture, you’ll see (hopefully) that the full memory grant for the query was 108,000KB.
But the spill on the Sort operator lists a far larger grant: 529,234,432KB.
This is in the XML, and not an artifact of Plan Explorer.
Whaddya think, Good Lookings? Should I file a bug report?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
To test FROID, which is the codename for Microsoft’s initiative to inline those awful scalar valued function things that people have been griping about for like 20 years, I like to take functions I’ve seen used in real life and adapt them a bit to work in the Stack Overflow database.
The funny thing is that no matter how many times I see the same function doing the same thing in a different way, someone tells me it’s unrealistic.
Doesn’t matter what it does: Touch data. Not touch data. Do simple formatting. Create a CSV list. Parse a CSV list. Pad data. Remove characters. Proper case names.
“I would never use a function for that.”
Okay, Spanky ?
Too Two!
In CTP 2.2, I had a function that ended up with this query plan:
Tell Moses to get the baseball bat.
The important detail about it is that it runs for 11 seconds in nested loops hell.
Watch Out Now
For reader reference: The non-inlined version runs for about 6 seconds and gets an adaptive join plan.
The plan is forced serial with inlining turned off, naturally.
You’re cool.
I sent the details over to my BESS FRENS at Microsoft, and it looks like it’s been fixed.
To Three!
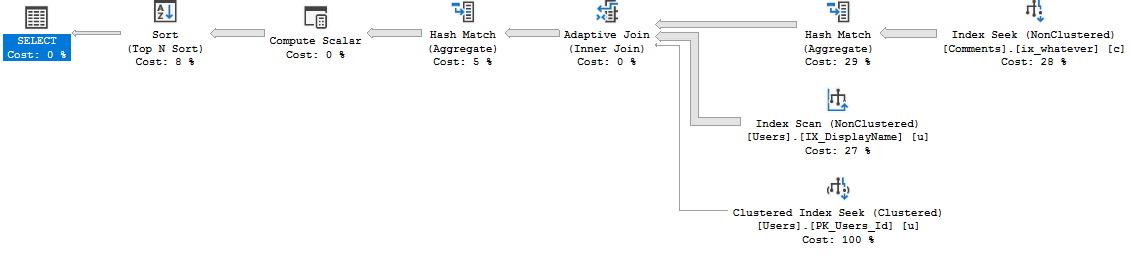
In CTP 2.3, when we turn on functioning inlining and do the same thing:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;
Fad Gadget
No more nested loops hell. Now the function gets an adaptive join plan with parallelism, and finishes immediately.
Thanks, frens.
And thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Thank you to everyone who donated, attended the session, and of course the lovely people at SQLBits for putting on a great conference. Hope to see everyone again next year…
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are plenty of spools in query plans, and they’re all pretty well labeled.
Index
Table
Rowcount
Window
They can be either eager or lazy.
An eager spool will take all the rows at once and cache them, and a lazy spool will only go get rows as needed.
But what else can act like a spool?
Phases On
In general, a blocking operator, or as my upside down friend Paul calls them, “phase separators” can act as a spool.
A spool, after all, is just something that keeps track of some rows, which is exactly what a Sort or a Hash do.
They keep track of rows that arrive, and either sort them according to a need, or create a hash table of the value.
While either of these happen, any downstream work in the query have to wait for them to complete. This is why they’re called blocking, stop and go, or, more eloquently, phase separators.
Eager spools have the same basic feature: wait for all the rows from downstream to arrive, and perform an action (or just feed them to another operator).
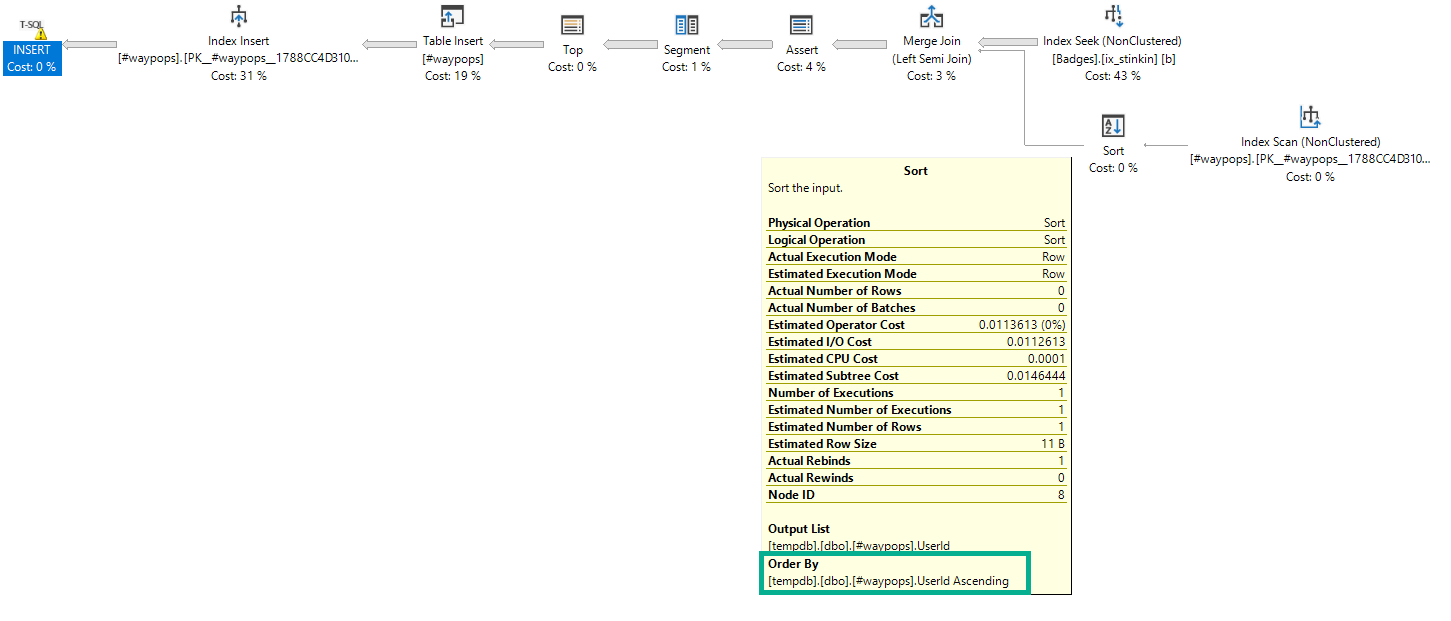
Here’s an example of a Sort acting as a spool:
DROP TABLE IF EXISTS #waypops;
CREATE TABLE #waypops
(
UserId INT
, PRIMARY KEY NONCLUSTERED (UserId) WITH (IGNORE_DUP_KEY = ON)
);
INSERT #waypops WITH(TABLOCKX)
( UserId)
SELECT b.UserId
FROM dbo.Badges AS b
WHERE b.Name = N'Popular Question';
Enjoy the silence
The Sort is in the same order as the index it’s reading from, but just reading from the index wouldn’t provide any separation.
Just Passing By
This is weird, niche stuff. That’s why I’m posting it on a Friday. That, and I wanna bully someone into writing about using a hash join to do the same thing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sometimes, the optimizer can take a query with a complex where clause, and turn it into two queries.
This only happens up to a certain point in complexity, and only if you have really specific indexes to allow these kinds of plan choices.
Here’s a haphazard query:
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 1
AND p.AcceptedAnswerId <> 0
AND p.CommentCount > 5
AND p.CommunityOwnedDate IS NULL
AND p.FavoriteCount > 0
)
OR (
p.PostTypeId = 2
AND p.CommentCount > 1
AND p.LastEditDate IS NULL
AND p.Score > 5
AND p.ParentId = 0
)
AND (p.ClosedDate IS NULL);
There’s a [bunch of predicates], an OR, then a [bunch of predicates]. Since there’s some shared spaced, we can create an okay general index.
It’s pretty wide, and it may not be the kind of index I’d normally create, unless I really had to.
CREATE INDEX whatever
ON dbo.Posts (PostTypeId, CommentCount, ParentId)
INCLUDE(AcceptedAnswerId, FavoriteCount, LastEditDate, Score, ClosedDate, CommunityOwnedDate);
It covers every column we’re using. It’s a lot. But I had to do it to show you this.
Computer Love
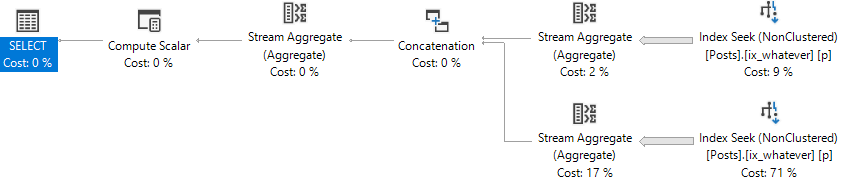
The optimizer took each separate group of predicates, and turned it into a separate index access, with a union operator.
It’s like if you wrote two count queries, and then counted the results of both.
But With A Twist
Let’s tweak the where clause a little bit.
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 1
AND p.AcceptedAnswerId <> 0
AND p.CommentCount > 5
OR p.CommunityOwnedDate IS NULL --This is an OR now
AND p.FavoriteCount > 0
)
OR (
p.PostTypeId = 2
AND p.CommentCount > 1
AND p.LastEditDate IS NULL
OR p.Score > 5 -- This is an OR now
AND p.ParentId = 0
)
AND (p.ClosedDate IS NULL)
Wham!
We don’t get the two seeks anymore. We get one big scan.
Is One Better?
The two seek plan has this profile:
Table 'Posts'. Scan count 10, logical reads 30678
Table 'Worktable'. Scan count 0, logical reads 0
Table 'Workfile'. Scan count 0, logical reads 0
SQL Server Execution Times:
CPU time = 439 ms, elapsed time = 108 ms.
Here’s the scan plan profile:
Table 'Posts'. Scan count 5, logical reads 127472
SQL Server Execution Times:
CPU time = 4624 ms, elapsed time = 1617 ms.
In this case, the index union optimization works in our favor.
We can push the optimizer towards a plan like that by breaking up complicated where clauses.
SELECT COUNT(*)
FROM (
SELECT 1 AS x
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 1
AND p.AcceptedAnswerId <> 0
AND p.CommentCount > 5
AND p.CommunityOwnedDate IS NULL
AND p.FavoriteCount > 0
)
UNION ALL
SELECT 1 AS x
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 2
AND p.CommentCount > 1
AND p.LastEditDate IS NULL
AND p.Score > 5
AND p.ParentId = 0
)
AND (p.ClosedDate IS NULL)
) AS x
Et voila!
Chicken Leg
Which has this profile:
Table 'Posts'. Scan count 2, logical reads 30001
SQL Server Execution Times:
CPU time = 329 ms, elapsed time = 329 ms.
Beat My Guest
The optimizer is full of all sorts of cool tricks.
The better your indexes are, and the more clearly you write your queries, the more of those tricks you might see it start using
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
CREATE INDEX ix_fraud ON dbo.Votes ( CreationDate );
SELECT *
FROM dbo.Votes AS v
WHERE v.CreationDate >= '20101230';
SELECT *
FROM dbo.Votes AS v
WHERE v.CreationDate >= '20101231';
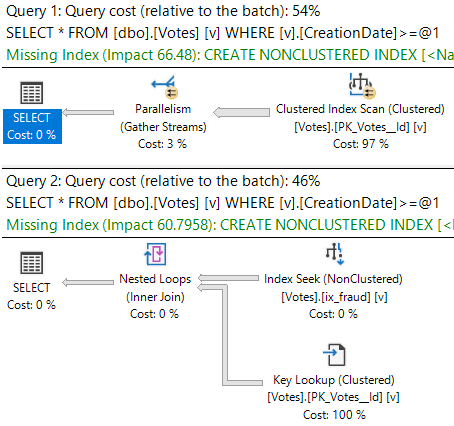
What a difference a day makes to a query plan!
Curse the head
Hard To Digest
Let’s paramaterize that!
DECLARE @creation_date DATETIME = '20101231';
DECLARE @sql NVARCHAR(MAX) = N''
SET @sql = @sql + N'
SELECT *
FROM dbo.Votes AS v
WHERE v.CreationDate >= @i_creation_date;
'
EXEC sys.sp_executesql @sql,
N'@i_creation_date DATETIME',
@i_creation_date = @creation_date;
This’ll give us the key lookup plan you see above. If I re-run the query and use the 2010-12-30 date, we’ll re-use the key lookup plan.
That’s an example of how parameters are sniffed.
Sometimes, that’s not a good thing. Like, if I passed in 2008-12-30, we probably wouldn’t like a lookup too much.
One common “solution” to parameter sniffing is to tack a recompile hint somewhere.
Recently, I saw someone use it like this:
DECLARE @creation_date DATETIME = '20101230';
DECLARE @sql NVARCHAR(MAX) = N''
SET @sql = @sql + N'
SELECT *
FROM dbo.Votes AS v
WHERE v.CreationDate >= @i_creation_date;
'
EXEC sys.sp_executesql @sql,
N'@i_creation_date DATETIME',
@i_creation_date = @creation_date
WITH RECOMPILE;
Which… gives us the same plan. That doesn’t recompile the query that sp_executesql runs.
You can only do that by adding OPTION(RECOMPILE) to the query, like this:
SET @sql = @sql + N'
SELECT *
FROM dbo.Votes AS v
WHERE v.CreationDate >= @i_creation_date
OPTION(RECOMPILE);
'
A Dog Is A Cat
Chalk this one up to “maybe it wasn’t parameter sniffing” in the first place.
I don’t usually advocate for jumping right to recompile, mostly because it wipes the forensic trail from the plan cache.
There are some other potential issues, like plan compilation overhead, and there have been bugs around it in the past.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One is the loneliest number. Sometimes it’s also the hardest number of rows to get, depending on how you do it.
In this video, I’ll show you how a TOP 1 query can perform much differently from a query where you generate row numbers and look for the first one.
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.