If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In yesterday’s post, we looked at a clever way to reduce calls to a scalar UDF using APPLY.
Today, we’re going to see if 2019 changes anything, and if our old trick still tricks.
Because, you know, what else do you do when you need to write 5 blog posts a week?
LOVE YOU!
Don’t Be A Donkey
I’m going to abridge this a little bit, since all the code is referenced at the link up there.
I’m also going to show you some stuff using Plan Explorer.
Why?
Because SSMS kept opening the plan XML as XML, and that makes for crap screenshots.
Here’s the results for the plan with two function references. It runs for ~2.2 seconds.
Honesty, at last.
If you remember yesterday’s post (and why wouldn’t you, hm?) the query plans didn’t show us touching other tables at all.
Just seeking into the Users table and then magically computing scalars and filtering.
One of the nice things about scalar UDF inlining: honesty.
But, you know, the two where clause references end up expanding. We’re hitting pretty big tables, here, too.
Apply-ish-ness
Using APPLY has a similar *ffect here. The function is only referenced and filtered once, and the duration is cut roughly in half.
Now, I know you’re probably thinking, because YOU REMEMBER YESTERDAY’S POST!
Ming the Merciless
How come these queries are so much slower with the functions inlined?
Well, they’re not. With query plans turned off, the first one runs in ~900ms, and the second one runs in ~500ms.
Yesterday’s plans run for 1.6s and 600ms respectively with plans turns off.
Apparently observation has overhead. If only there were a clever phrase for that.
Not All Functions
The idea behind FROID is that it removes some restrictions around scalar valued functions.
They can be inlined into the query, not run per-row returned
They don’t force serial execution, so you can get a parallel plan
If your functions already run pretty quickly over a small number of rows, and the calling query doesn’t qualify for parallelism, you may not see a remarkable speedup.
That’s fine, though, because inlining has other benefits:
Query plans are honest about the work they do
Measuring the query will show you work that used to be hidden behind the function call(s)
Even if every query doesn’t magically finish before you run it, you’ll see pretty good gains.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The things I see people doing with them range from “you know there’s a system function that does that” to “oh wow, you wrote an entire program in here”.
I’m not kidding. I once saw a function that was a wrapper for ISNULL that returned the results of ISNULL. I have no idea why.
If I had to think of a DBA prank, writing scalar UDFs that are just wrappers for system functions would be pretty high up there.
Especially if they had the same names as the system functions.
Turning Down The Suck
A while back, Jonathan Kehayias blogged about a way to speed up UDFs that might see NULL input.
Which is great, if your functions see NULL inputs.
But what if… What if they don’t?
And what if they’re in your WHERE clause?
And what if they’re in your WHERE clause multiple times?
Oh my.
Tick, Tick, Tick
Here’s our function.
CREATE FUNCTION dbo.TotalScore(@UserId INT)
RETURNS BIGINT
WITH RETURNS NULL ON NULL INPUT, SCHEMABINDING
AS
BEGIN
DECLARE @TotalScore BIGINT;
SELECT @TotalScore =
(
SELECT ISNULL(SUM(p.Score), 0)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
) +
(
SELECT ISNULL(SUM(c.Score), 0)
FROM dbo.Comments AS c
WHERE c.UserId = @UserId
)
RETURN @TotalScore;
END
GO
What it does is go out to the Posts and Comments tables and sums up the Score columns for a user.
We’ll use it in our query like this:
SELECT u.DisplayName,
u.Reputation
FROM dbo.Users AS u
WHERE u.Reputation >= 100000
AND dbo.TotalScore(u.Id) >= 10000
AND dbo.TotalScore(u.Id) < 20000
ORDER BY u.Id;
We want to find people with a total score between 10 and 20 thousand.
Right on.
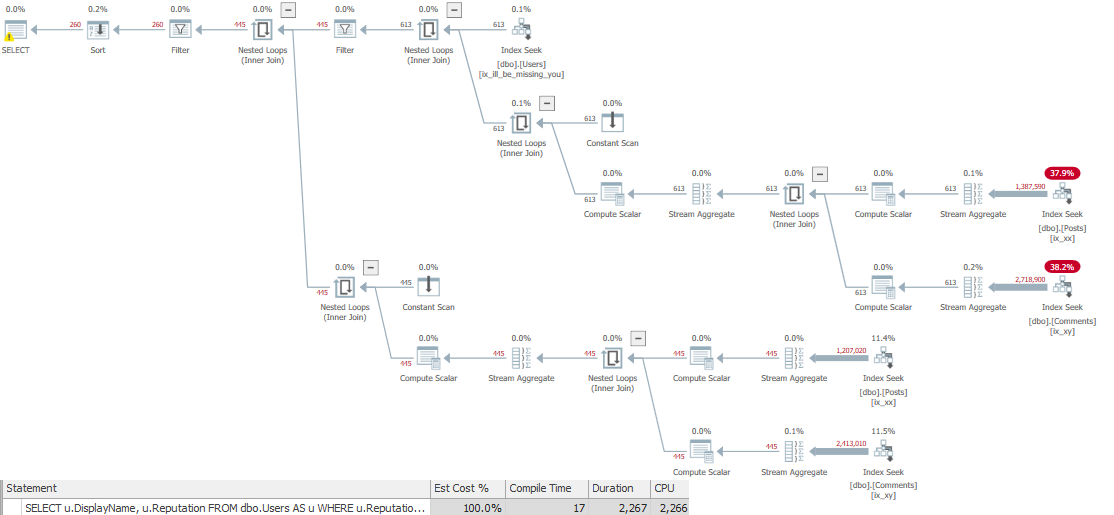
When we run the query, the plan looks like this, showing 2 seconds of runtime.
Two seconds for 260 rows is kinda wack tho
Tock, Tock, Tock
I know, I know. Get to the point. Make it faster, bouncer-man.
Our goal is to get the function to run fewer times, so we’ll replace multiple calls to it with one call.
SELECT u.DisplayName,
u.Reputation
FROM dbo.Users AS u
CROSS APPLY
(
VALUES (dbo.TotalScore(u.Id))
) AS t (Score)
WHERE u.Reputation >= 100000
AND t.Score >= 10000
AND t.Score < 20000
ORDER BY u.Id;
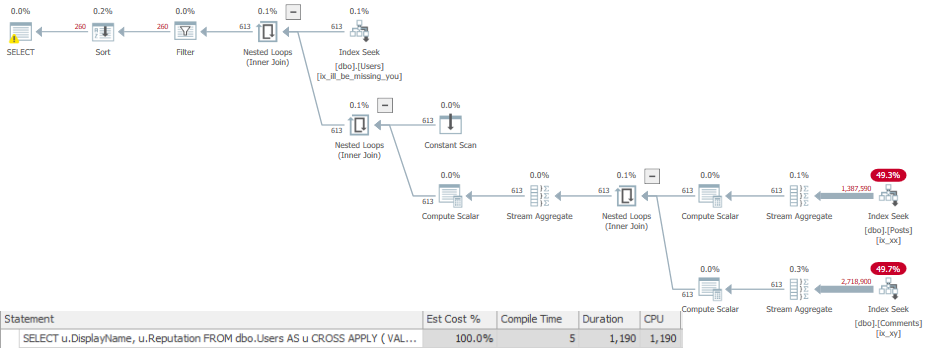
Using this technique, the query runs for about 780ms.
Check you out.
Tale of the XE
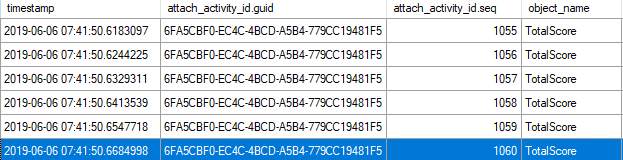
What happens that makes this faster is more evident if we use the XE session from Jonathan’s post for similar reasons, and look at how many times the function was called.
If we look at the activity sequence, it goes up to 1060 for the first query:
Moved Out The Hood
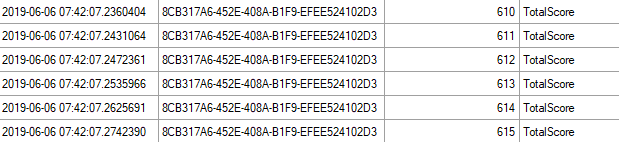
And only 615 for the second query:
Thinner~
Exeunt
Right now, if we want scalar UDFs to run faster, we can:
Tune the underlying query (if there is one)
Have them run fewer times
Wait for SQL Server 2019
In tomorrow’s post, I’ll look at the same scenario using CTP 3 of SQL Server 2019.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In query plans where an Eager Index Spool is directly after a data access operator, a missing index should be generated in the query plan, and/or missing index DMVs that describes the definition of the index needed to make the spool unnecessary.
I would not expect this to happen when a Lazy Index Spool occurs above a subtree.
I’d appreciate it if you’d consider voting for it. It’s something that I was able to implement pretty easily in sp_BlitzCache.
In query plans where an Eager Index Spool is directly after a data access operator, wait stats should be generated while the Spool is built. In a parallel plan, EXECSYNC waits are generated, but in a serial plan, you don’t see anything. Problem scenarios will become more common when FROID is released and adopted.
I would not expect this to happen when a Lazy Index Spool occurs above a subtree.
Thanks for reading!
And voting as many times as possible ?
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ve trademarked: Froidrage, Froidulent, and Froidpocalypse.
If you want to use them, you have to pay me $10,000.
Alright, I’m being told by my lawyer that writing them on cocktail napkins and showing them to confused bartenders doesn’t actually register a trademark.
Nevermind.
Here’s What’s Gonna Happen
And it’s not a problem that you need SQL Server 2019 to see. All you have to do is try to rewrite a function.
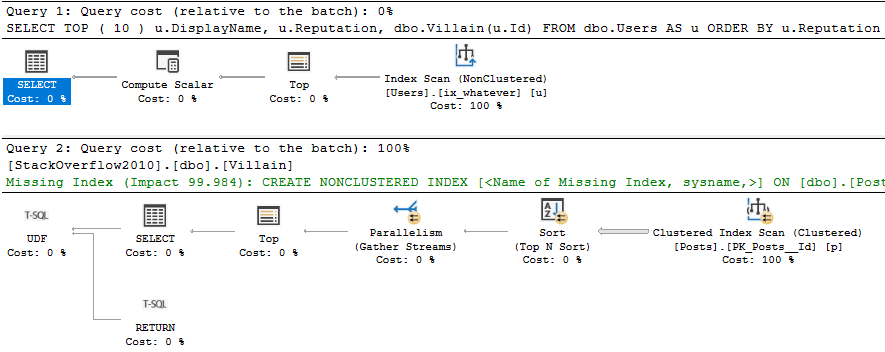
Here’s our Villain, a scalar UDF.
CREATE FUNCTION dbo.Villain (@UserId INT)
RETURNS INT
WITH SCHEMABINDING, RETURNS NULL ON NULL INPUT
AS
BEGIN
DECLARE @Score INT
SELECT TOP (1)
@Score = p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
AND p.PostTypeId = 1
ORDER BY p.Score DESC;
RETURN @Score;
END
GO
Here’s the query that’s gonna call it:
SELECT TOP ( 10 )
u.DisplayName,
u.Reputation,
dbo.Villain(u.Id)
FROM dbo.Users AS u
ORDER BY u.Reputation DESC;
GO
I’m Going To Show You Two Things
The estimated plan, and the actual plan.
I need to show you the estimated plan so you can see what the function does, because that’s not included in the actual plan.
Yes, the estimated plan is more accurate than the actual plan.
Marinate on that.
On The Dancefloor
The important thing is the second plan, which is the function’s execution plan. Notice that it generated a missing index request, and doesn’t spool anything at all.
It handles the query logic with a Top N Sort.
Here’s the actual plan:
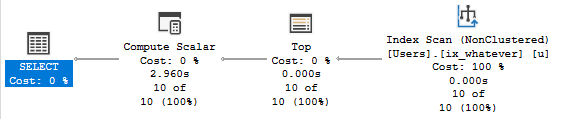
A NONCLUSTERED INDEX SCAN!!!
Let’s talk about a couple things:
A nonclustered index scan that costs 100% and runs for 0.000s
A compute scalar that costs 0% and runs for ~3s
The compute scalar thing is well documented by… Well, not by official Microsoft documentation.
Would say “I can rewrite that function and make things better”.
Because of course an inline function is always better than a scalar function.
Enter our Hero.
CREATE FUNCTION dbo.Hero (@UserId INT)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
SELECT TOP (1)
p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
AND p.PostTypeId = 1
ORDER BY p.Score DESC;
GO
Here’s the query that’s gonna call it:
SELECT TOP ( 10 )
u.DisplayName,
u.Reputation,
h.*
FROM dbo.Users AS u
CROSS APPLY dbo.Hero(u.Id) AS h
ORDER BY u.Reputation DESC;
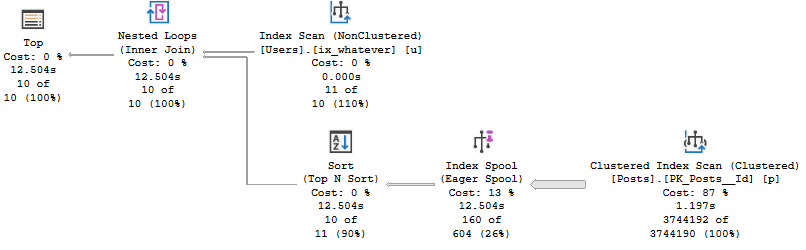
I Only Need To Show You One Thing
Since the function is an inline type, the query processor is honest with us about the full query plan.
Spiced Ham
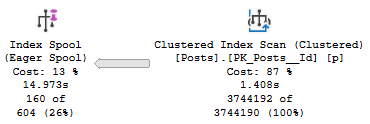
Two things happened here:
The “function body” no longer goes parallel
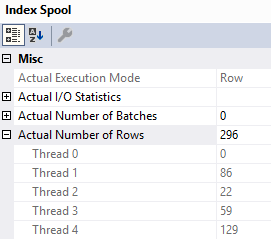
The TOP (1) is run against an eager index spool rather than the clustered index
What’s The Point?
This is what FROID does for you without a rewrite. It’ll inline the scalar UDF.
The plan may be better, or it may be worse.
The scalar UDF plan ran for 3 seconds, and the inline version ran for almost 13 seconds.
Stay tuned for tomorrow’s post. I have a couple suggestions for how The SQL Server team can help end users stay on top of these problems in SQL Server 2019.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This is a short post, since we’re on the subject of index spools this week, to show you that the columns that go into the spool will impact spool size and build time.
I know, that sounds obvious, but once in a while I care about “completeness”.
We’re going to look at two queries that build eager index spools, along with the time the spool takes to build and how many writes we do.
Query 1
On the side of the query where a spool gets built (inside the apply), we’re only selecting one column.
SELECT TOP ( 10 )
u.DisplayName,
u.Reputation,
ca.*
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP ( 1 )
p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
ORDER BY p.Score DESC
) AS ca
ORDER BY u.Reputation DESC;
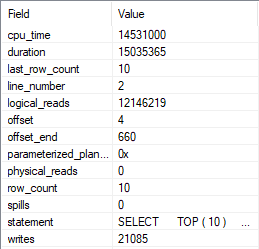
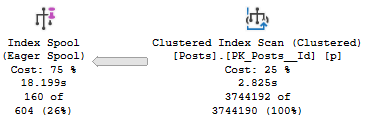
In the query plan, we spend 1.4 seconds reading from the Posts table, and 13.5 seconds building the index spool.
Work it
We also do 21,085 writes while building it.
Insert comma
Query 2
Now we’re going to select every column in the Posts table, except Body.
If I select Body, SQL Server outsmarts me and doesn’t use a spool. Apparently even spools have morals.
SELECT TOP ( 10 )
u.DisplayName,
u.Reputation,
ca.*
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP ( 1 )
p.Id, p.AcceptedAnswerId, p.AnswerCount, p.ClosedDate,
p.CommentCount, p.CommunityOwnedDate, p.CreationDate,
p.FavoriteCount, p.LastActivityDate, p.LastEditDate,
p.LastEditorDisplayName, p.LastEditorUserId, p.OwnerUserId,
p.ParentId, p.PostTypeId, p.Score, p.Tags, p.Title, p.ViewCount
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
ORDER BY p.Score DESC
) AS ca
ORDER BY u.Reputation DESC;
GO
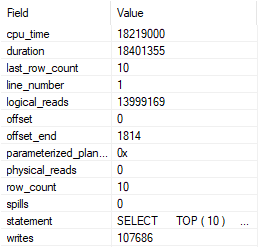
In the query plan, we spend 2.8 seconds reading from the Posts table, and 15.3 seconds building the index spool.
Longer
We also do more writes, at 107,686.
And more!
This Is Not A Complaint
I just wanted to write this down, because I haven’t seen it written down anywhere else.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Certain spools in SQL Server can be counterproductive, though well intentioned.
In this case, I don’t mean that “if the spool weren’t there, the query would be faster”.
I mean that… Well, let’s just go look.
Bad Enough Plan Found
Let’s take this query.
SELECT TOP (50)
u.DisplayName,
u.Reputation,
ca.*
FROM dbo.Users AS u
CROSS APPLY
(
SELECT TOP (10)
p.Id,
p.Score,
p.Title
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.PostTypeId = 1
ORDER BY
p.Score DESC
) AS ca
ORDER BY
u.Reputation DESC;
Top N per group is a common enough need.
If it’s not, don’t tell Itzik. He’ll be heartbroken.
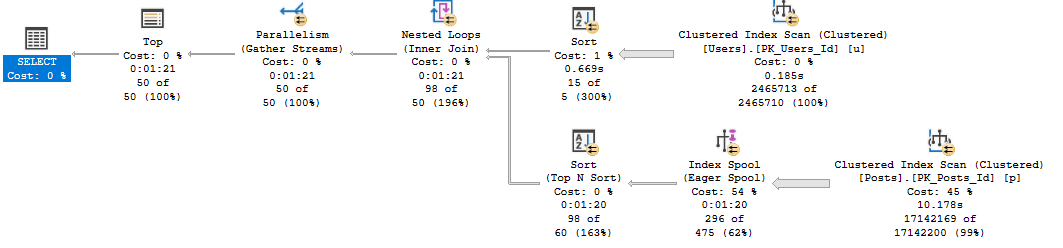
The query plan looks like this:
Wig Billy
Thanks to the new operator times in SSMS 18, we can see exactly where the chokepoint in this query is.
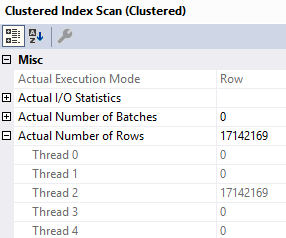
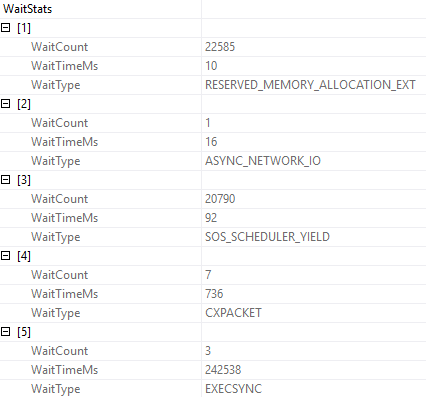
Building and reading from the eager index spool takes 70 wall clock seconds. Remember that in row mode plans, operator times aggregate across branches, so the 10 seconds on the clustered index scan is included in the index spool time.
One thing I want to point out is that even though the plan says it’s parallel, the spool is built single threaded.
One Sided
Reading data from the clustered index on the Posts table and putting it into the index is all run on Thread 2.
If we look at the wait stats generated by this query, a full 242 seconds are spent on EXECSYNC.
Armless
The math mostly works out, because four threads are waiting on the spool to be built.
Even though the scan of the clustered index is serial, reading from the spool occurs in parallel.
Spange
Connected
Eager index spools are built per-query, and discarded afterwards. When built for large tables, they can represent quite a bit of work.
In this example query, a 17 million row index is built, and that’ll happen every single time the query executes.
While I’m all on board with the intent behind the index spool, the execution is pretty brutal. Much of query tuning is situational, but I’ll always pay attention to an index spool (especially because you won’t get a missing index request for them anywhere). You’ll wanna look at the spool definition, and potentially create a permanent index to address the issue.
As for EXECSYNC waits, they can be generated by other things, too. If you’re seeing a lot of them, I’m willing to bet you’ll also find parallel queries with spools in them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’m going to use a funny example to show you something weird that I see often in EF queries.
I’m not going to use EF to do it, because I have no idea how to. Please use your vast imagination.
In this case, I’m going to figure out if a user is trusted, and only if they are will I show them certain information.
Here goes!
Trust Bust
The first part of the query establishes if the user is trusted or not.
I think this is silly because no one should ever trust users.
DECLARE @UserId INT = 22656, --2788872
@PostId INT = 11227809,
@IsTrusted BIT = 0,
@SQL NVARCHAR(MAX) = N'';
SELECT @IsTrusted = CASE WHEN u.Reputation >= 10000
THEN 1
ELSE 0
END
FROM dbo.Users AS u
WHERE u.Id = @UserId;
The second part will query and join a few tables, but one of the joins (to the Votes table) will only run if a user is trusted.
SET @SQL = @SQL + N'
SELECT p.Title, p.Score,
c.Text, c.Score,
v.*
FROM dbo.Posts AS p
LEFT JOIN dbo.Comments AS c
ON p.Id = c.PostId
LEFT JOIN dbo.Votes AS v
ON p.Id = v.PostId
AND 1 = @iIsTrusted
WHERE p.Id = @iPostId
AND p.PostTypeId = 1;
';
EXEC sys.sp_executesql @SQL,
N'@iIsTrusted BIT, @iPostId INT',
@iIsTrusted = @IsTrusted,
@iPostId = @PostId;
See where 1 = @iIsTrusted? That determines if the join runs at all.
Needless to say, adding an entire join in to the query might slow things down if we’re not prepared.
First I’m going to run it for user 2788872, who isn’t trusted.
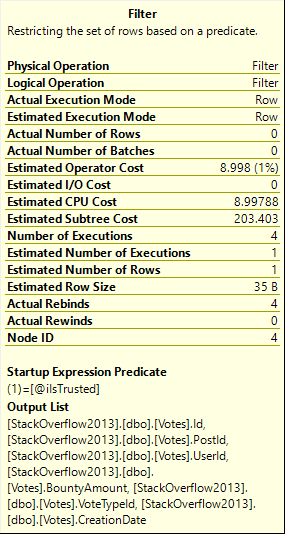
This query finishes rather quickly (2 seconds), and has an interesting operator in it.
Henanigans, S.Pump the brakes
The filter has a startup expression in it, which means it’s sort of a gatekeeper, here. If the parameter is 0, we don’t touch Votes.
If it’s 1… Boy, do we touch Votes. This is another case of where cached plans can lie to us.
Rep Up
If we run this for user 22656 (Jon Skeet) afterwards, we will definitely need to touch the Votes table.
I grabbed the Live Query Plan to show you just how little progress it makes over 5 minutes.
Dirge
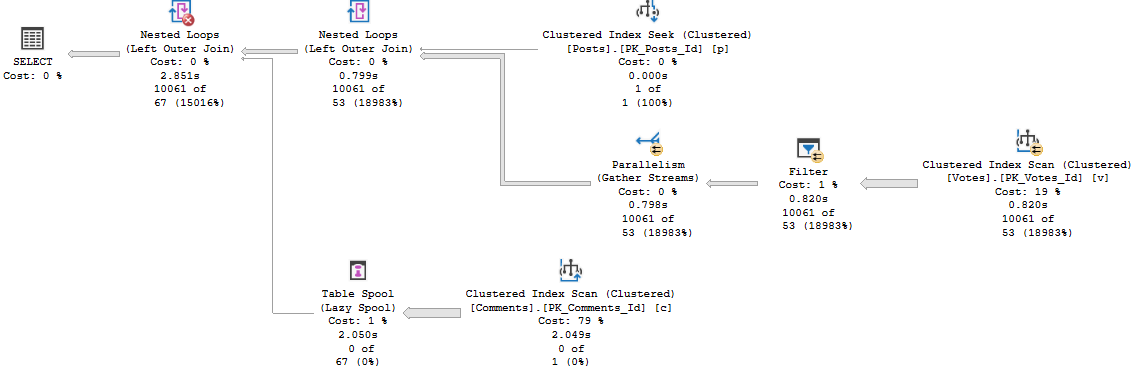
The cached plan will look identical. And looking at the plan, it’ll be hard to believe there’s any way it could run >5 minutes.
CONFESS
If we clear the cache and run this for 22656 first, the plan runs relatively quickly, and looks a little different.
Bag of Ice
Running it for an untrusted user has a similar runtime. It’s not great, but it’s the better of the two.
Fixing It?
It’s difficult to control EF queries with much granularity.
You could branch the application code to run two different queries based on if a user is trusted.
In a perfect world, you’d never even consider that join at all, and avoid having to worry about it.
On the plus side (at least in this case), the good plan for trusted users runs in the same time as the good plan for untrusted users, even though they’re different.
If you’re feeling extra confident, you can try adding an OPTIMIZE FOR hint to your code, or implementing a plan guide.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.