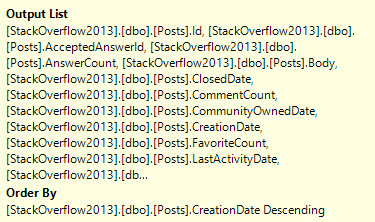
Odor Of Gas
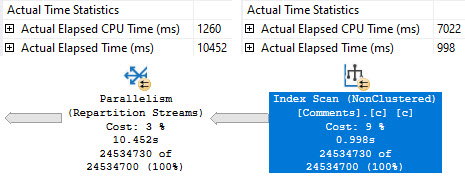
One problem with Lookups, aside from the usual complaints, is that the optimizer has no options for when the lookup happens.
If the optimizer decides to use a nonclustered index to satisfy some part of the query, but the nonclustered index doesn’t have all of the columns needed to cover what the query is asking for, it has to do a lookup.
Whether the lookup is Key or RID depends on if the table has a clustered index, but that’s not entirely the point.
The point is that there’s no way for the optimizer to decide to defer the lookup until later in the plan, when it might be more opportune.
Gastric Acid
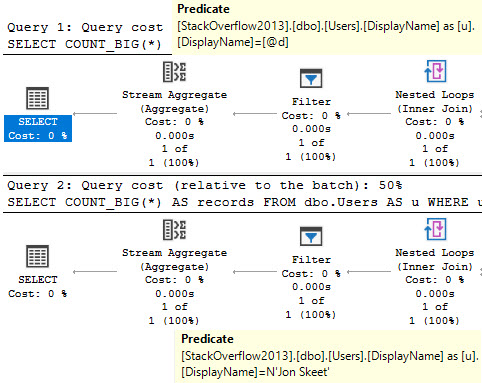
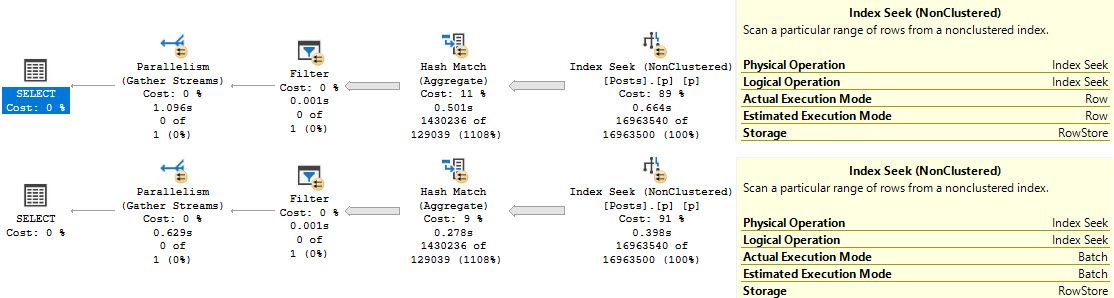
Let’s take one index, and two queries.
CREATE INDEX p
ON dbo.Posts(PostTypeId, Score, CreationDate)
INCLUDE(OwnerUserId);
Stop being gross.
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
The main point here is not that the lookup is bad; it’s actually good, and I wish both queries would use one.
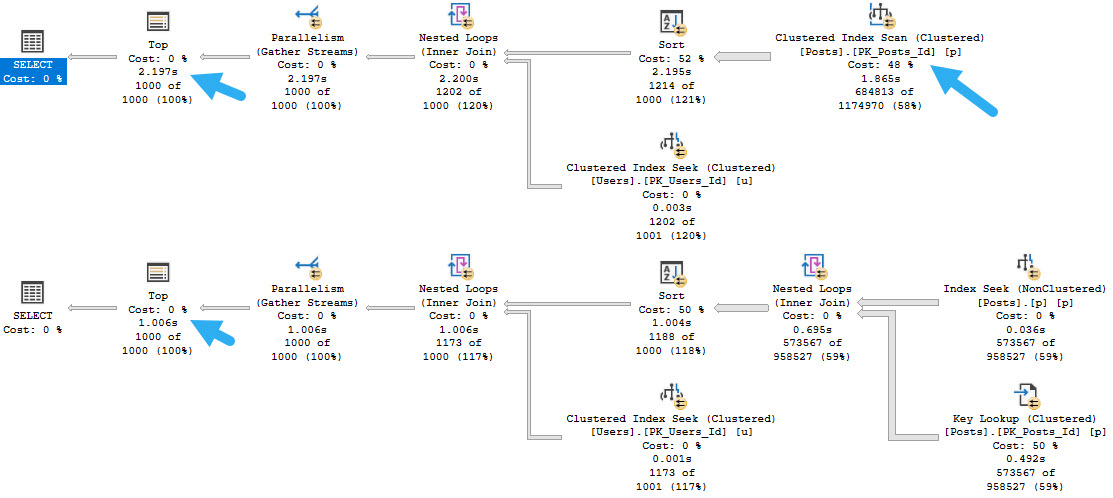
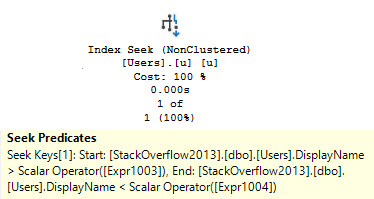
If we hint the first query to use the nonclustered index, things turn out better.
SELECT TOP (1000)
u.DisplayName,
p.*
FROM dbo.Posts AS p WITH(INDEX = p)
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;

Running a full second faster seems like a good thing to me, but there’s a problem.
Ingest
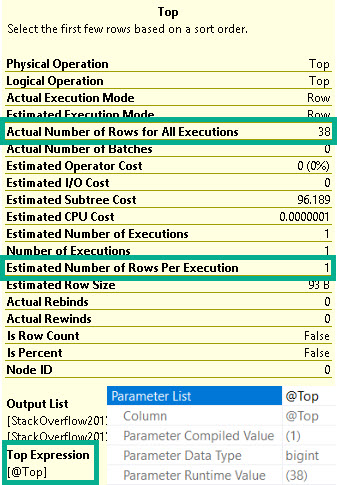
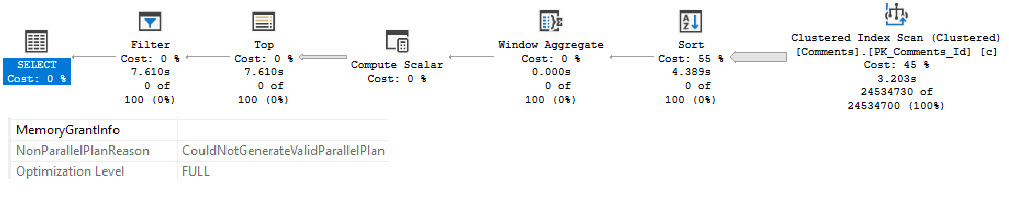
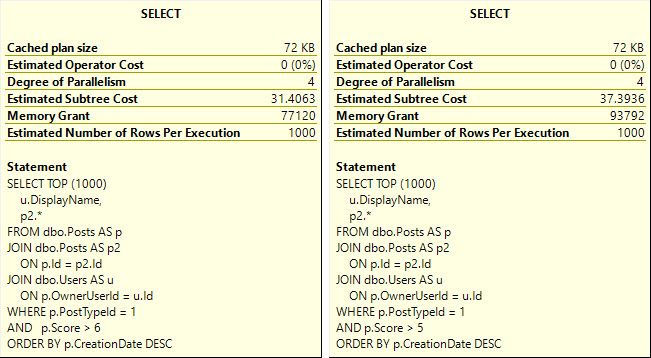
Whether we use the lookup or scan the clustered index, all of these queries ask for rather large memory grants, between 5.5 and 6.5 GB
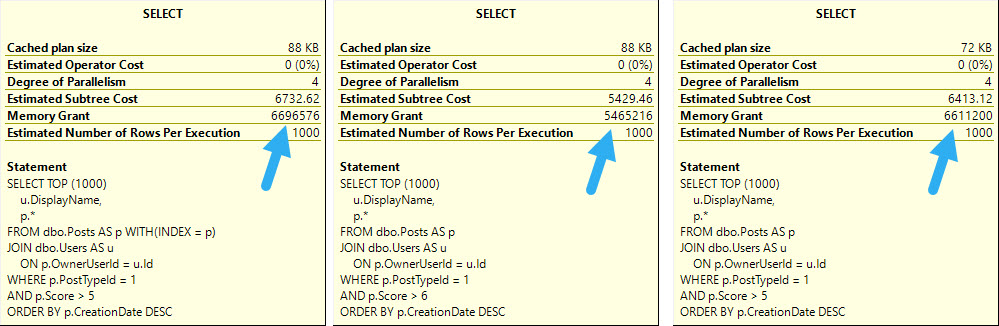
The operator asking for memory is the Sort — and while I’d love it if we could index for every sort — it’s just not practical.
So like obviously changing optimizer behavior is way more practical. Ahem.
The reason that the Sort asks for so much memory in each of these cases is that it’s forced to order the entire select output from the Posts table by the CreationDate column.
Detach
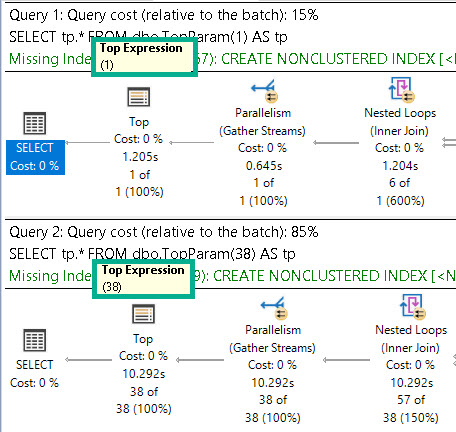
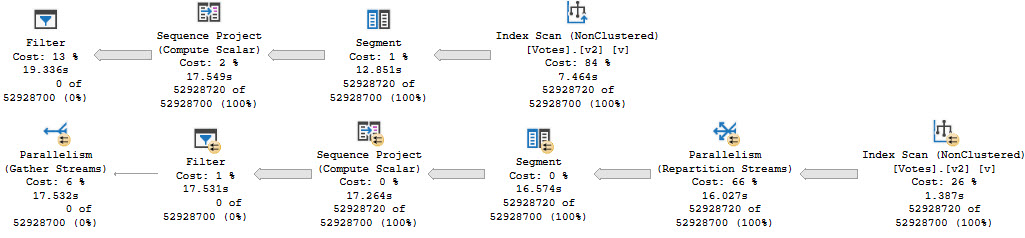
If we rewrite the query a bit, we can get the optimizer to sort data long before we go get all the output columns:
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 5
ORDER BY p.CreationDate DESC;
SELECT TOP (1000)
u.DisplayName,
p2.*
FROM dbo.Posts AS p
JOIN dbo.Posts AS p2
ON p.Id = p2.Id
JOIN dbo.Users AS u
ON p.OwnerUserId = u.Id
WHERE p.PostTypeId = 1
AND p.Score > 6
ORDER BY p.CreationDate DESC;
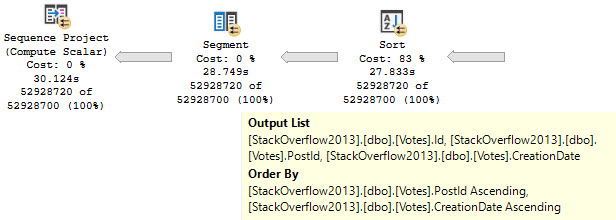
In both cases, we get the same query plan shape, which is what we’re after:
- Seek into the nonclustered index on Posts
- Sort data by CreationDate
- Join Posts to Users first
- Join back to Posts for the select list columns
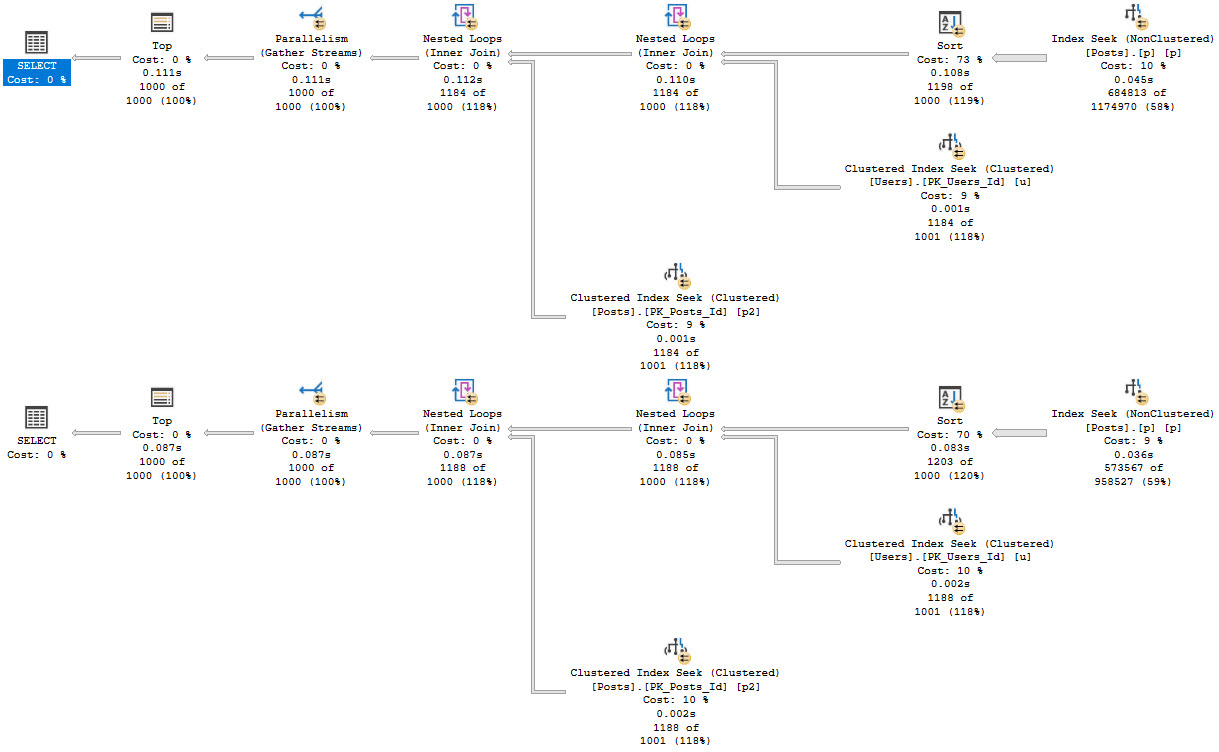
Because the Sort happens far earlier on in the plan, there’s less of a memory grant needed, and by quite a stretch from the 5+ GB before.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.