Underscoring The Importance
When I first sat down to write about this, I made a funny mistake: I kept writing DATE_TRUNC over and over again.
In SQL Server it’s DATETRUNC.
Why? Because that’s the way it’s implemented in Postgres and DB2. Oracle, of course, just calls it TRUNC.
So, while it’s nice to have (what appears to be) the same behavior, it doesn’t exactly help to not have a 1:1 calling equivalent to other platforms.
I assume most of these additions to T-SQL are for cross-platform development and migrations.
Of course, Microsoft being so gosh darn late to this game means folks have probably been rolling-their-own versions of these functions for years.
If they went and called their system function DATE_TRUNC or even TRUNC, they might have some object naming issues to contend with.
Well, okay. But how does it work?
Childish Games
Here are some quick examples of how you call it.
SELECT TOP (10)
u.DisplayName,
year =
DATETRUNC(YEAR, u.LastAccessDate),
quarter =
DATETRUNC(QUARTER, u.LastAccessDate),
month =
DATETRUNC(MONTH, u.LastAccessDate),
dayofyear =
DATETRUNC(DAYOFYEAR, u.LastAccessDate),
day =
DATETRUNC(DAY, u.LastAccessDate),
week =
DATETRUNC(WEEK, u.LastAccessDate),
iso_week =
DATETRUNC(ISO_WEEK, u.LastAccessDate),
hour =
DATETRUNC(HOUR, u.LastAccessDate),
minute =
DATETRUNC(MINUTE, u.LastAccessDate),
second =
DATETRUNC(SECOND, u.LastAccessDate),
millisecond =
DATETRUNC(MILLISECOND, u.LastAccessDate),
microsecond =
DATETRUNC(MICROSECOND, u.LastAccessDate) /*Doesn't work with datetime because there are no microseconds*/
FROM dbo.Users AS u;
And here are the results:

The thing to note here is that there’s no rounding logic involved. You just go to the start of whatever unit of time you choose. Of course, this doesn’t seem to do anything to the millisecond portion of DATETIME, because it’s not precise enough.
But for anyone out there who was hoping for a SOMONTH function to complement the EOMONTH function, you get this instead.
Works well enough!
But does it perform, Darling?
UnSARGable?
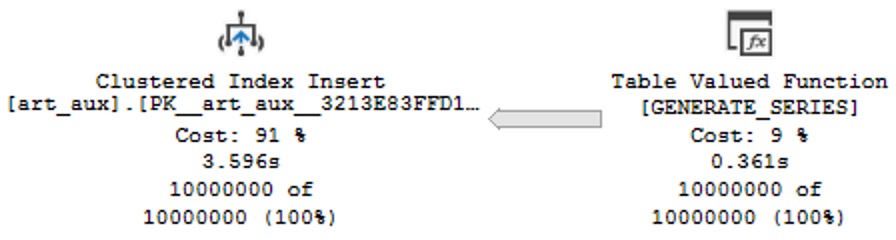
To make any test like this worthwhile, we need an index to make data searchable.
CREATE INDEX
v
ON dbo.Votes
(CreationDate)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
You know, because that’s what they do. To make searching faster. Hello.
So look, under these perfect circumstances, everything performs well. But we have to do a lot of typing.
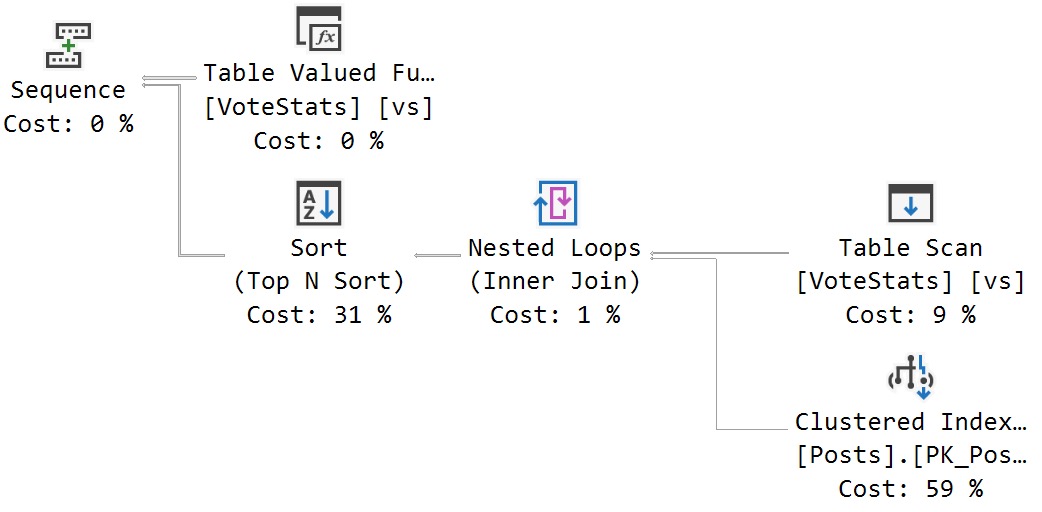
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATETRUNC(YEAR, CONVERT(datetime, '20130101 00:00:00.000'));
Note here that we’re working on a literal value, not a column value, and we have to tell the datetrunc function which type we want via the convert function so that we get a simple seek plan:
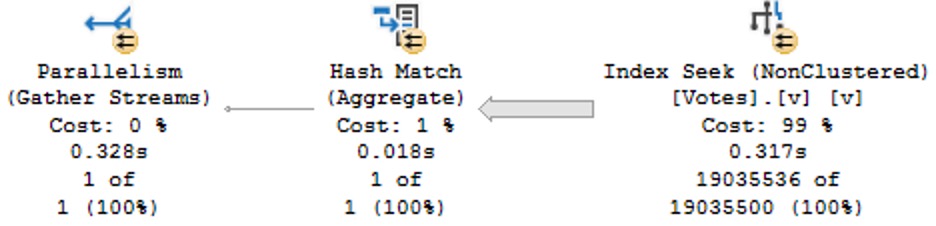
Without all that, we get a dynamic seek plan:
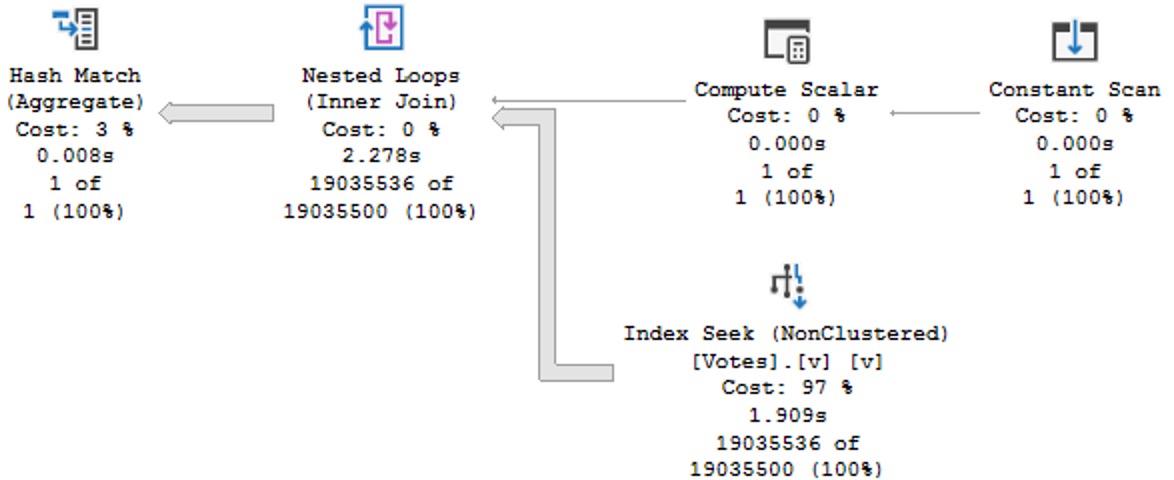
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATETRUNC(YEAR, '20130101 00:00:00.000');
This has some… obvious performance issues compared to the above plan with correct data types.
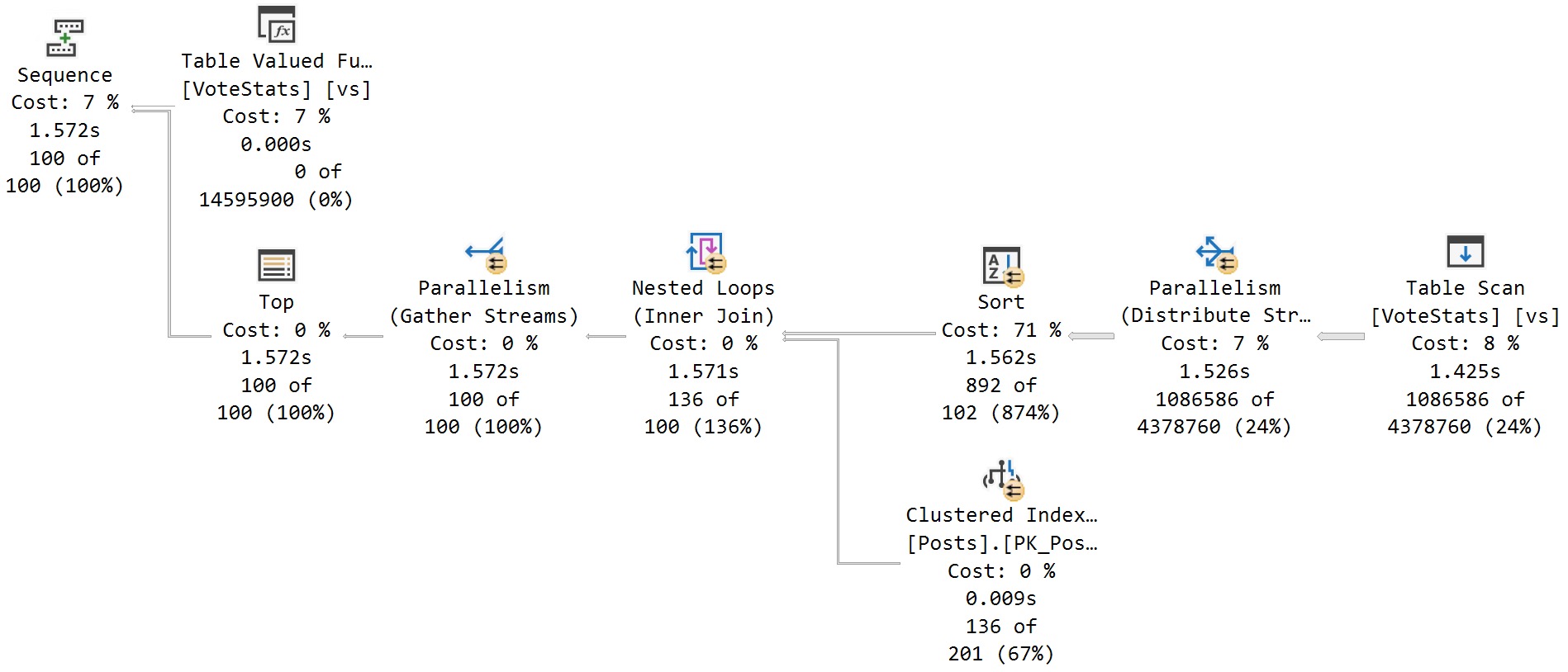
Query Pranks
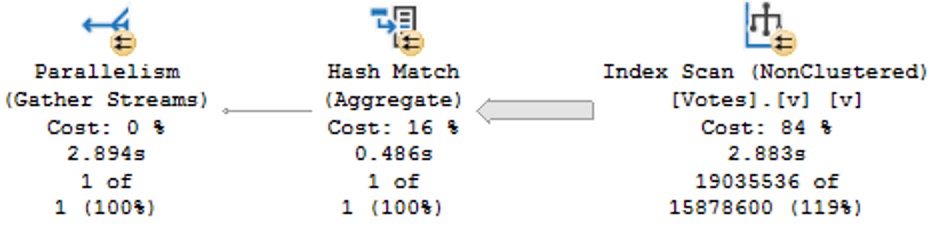
Frequent blog readers will not be surprised that wrapping a table column in the new DATETRUNC function yields old performance problems:
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE DATETRUNC(YEAR, v.CreationDate) >= CONVERT(datetime, '20130101 00:00:00.000');
This is particularly annoying because we’re truncating the column to the beginning of the year, which should be searchable in the index since that’s the sort order of the data in the index.
Like most functions, these are fine in the presentation layer, but terrible in the relational layer. There’s no warning about this performance degradation in the documentation, either at the example of using the function in a where clause, or in the final closing remarks.
But that’s par for the course with any of these built-in functions.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.