I am not great at numbers. Especially big numbers, or numbers that need to get converted, like going from KB to GB.
Not KGB. I don’t wanna ever end up there.
Being but a mere mortal, I always find it a whole lot easier to figure out what I’m looking at when there are some separators in there.
For me in all my American Glory, that’s properly placed commas.
🫡🇺🇸
BigNumber4U
Some queries can rack up some pretty impressive resource consumption numbers, especially in Query Store where historical data is held for much longer times than the plan cache.
Making matters worse is that it makes sense to scale things to precise numbers that can look really confusing when they hit anything more than eight or nine digits.
That’s why I wanted to make sure sp_QuickieStore had a way to make things easier on us numerically-challenged public school kids.
EXEC sp_QuickieStore
@format_output = 1;
Any number that meets the prerequisites for comma insertion will get one. here’s a small example:
commacastic
Isn’t that nice?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Query Store gives you no way to really search through it. There are knobs and you can filter to specific times and stuff, but… That’s not really helpful most of the time.
If you need to find information about a particular query, but it’s not showing up in the places that it should be showing up, you’re screwed.
Unless you wanna write a bunch of horrible queries to dive into the Query Store DMVs on your own, or you’re the kind of Awesome Blossom who uses sp_QuickieStore.
Then you can find queries in a bunch of different ways.
It’s fun. You’ll love it.
Positive ID
In query store, most of the views are related by a couple different things:
query id
plan id
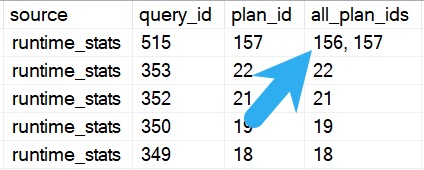
One query id can be attached to many plan ids, and what often happened to me is wanting to filter in to a specific set of query and plan ids.
Note that these parameters are all pluralized, which means you can pass in a list. That’s particularly helpful when you team the plan id parameter up with the all_plan_ids column in the procedure’s output.
bang on
You can copy and paste those out and use them directly to search through Query Store with sp_QuickieStore.
You can do that with any of the other parameters too, to include or ignore certain queries.
Handle Hash Mustache
More recently, I added the ability to track down queries in Query Store by different hashes and handles in Query Store, using sp_QuickieStore.
@include_query_hashes
@include_plan_hashes
@include_sql_handles
@ignore_query_hashes
@ignore_plan_hashes
@ignore_sql_handles
Just like with the ids above, these accept CSV lists of hashes and handles to include or ignore.
But why? Well… Troubleshooting blocking and deadlocks is a whole lot easier when you can see query plans. You might see something obvious like…
A bunch of foreign keys need to be validated on modification
Some god awful trigger fires off
Modification queries don’t have useful indexes
The problem is that neither the blocking or deadlock XML reports give you query plans. You only get ways to identify them — you might get the full query text if you’re lucky — but no query plans to give you more information.
Here’s an XML fragment from the blocked process report:
Now you can find query plans by handle and hash really easily in Query Store.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
These can be useful things to tweak based on your situation.
Details, Details
You can do some really cool stuff with these to narrow search results to things you care about. I’m gonna highlight those here, even if they may seem obvious.
@database_name: some databases are more important than others
@sort_order: if your server has a particular bottleneck, it can be useful to find queries using the most of that bottleneck
@top: sometimes there’s red meat beyond the top 10, like when you’re looking at high execution counts
@start_date: know when you had a problem? start here.
@end_date: know when the problem stopped? stop here.
@execution_count: you may not want to see queries with low execution counts, because they might just run once at night
@duration_ms: low duration queries may not be tunable, and you may not want to see them
@wait_filter: does a particular wait stat stick out on your server? Find the queries responsible for it!
I tried to give you plenty of options to focus in on high-level things that can help lead you to queries that are causing you problems.
You can also zoom in to specific queries using a few different searchables, and we’ll talk about that tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Microsoft has invested some engineering time in the plumbing behind Query Store in SQL Server 2022. Really cool stuff, like the ability to add hints to a query and force it to use the plan with that hint in place.
That’s going to solve a crazy amount of problems for me, with queries that I can’t actually touch (and not because they’re priceless works of art).
But… the front end of Query Store still hasn’t changed. It’s clunky, it’s ugly, it’s not very configurable, and I find it downright unfriendly.
It can also be really slow and, golly and gosh, the number of times I’ve seen the queries that fill in the GUI show up in there is sort of depressing.
So I wrote sp_QuickieStore to fill in the gaps. No, it doesn’t populate a GUI (I don’t have those chops), but it does get you actionable results pretty quickly.
Explain Plan
By default, sp_QuickieStore will give you the top ten queries in query store by average CPU over the last 24 hours. I’m going to talk about other things you can do with it later this week.
For now, let’s just look at the first thing you see when you run it without any additional parameters. Most folks will stick sp_QuickieStore in the master database, but Query Store can only be turned on in user databases.
Of course, sp_QuickieStore has a parameter to tell it which database you want to analyze (@database_name). It’d be utterly insane for me to ask you, dear user, to install it in every user database.
The nice thing is that if you run sp_QuickieStorefrom a user database context, it will assume that that’s the database you want to analyze Query Store in.
EXEC sp_QuickieStore;
Right up front, you get the stuff that helps you figure out if you want to dig any deeper:
big machine
There’s a lot more information if you keep scrolling to the right that’ll tell you about resource usage, but here’s what you get:
query_id: how Query Store identifies the query text
plan_id: how Query Store identifies the query plan
all_plan_ids: if your query has generated multiple plans, you’ll get a CSV list of them here
execution_type_desc: if you query ran successfully or not
object_name: if your query came from a store procedure
query_sql_text: XML clickable of the query text
compatibility_level: uh… compatibility level
query_plan plan_forcing_type_desc: if Query Store is forcing a plan
top_waits: the high-level wait stats that your query has generated
first_execution_time: um… c’mon
last_execution_time: don’t make me say it
count_executions: oh gosh darn it to heck.
By The Numbers
There’s plenty for you to think about up there. Most folks know if they care about something by looking at some combination of object_name and query_sql_text. Sometimes count_executions will come into play.
Other times, you might have no idea what you’re looking at or why it’s showing up here. And baby. Baby, baby, baby. I am here for you.
bingo
These results are sorted by average CPU (that’s the default, remember), but there’s plenty of other memes here like logical reads for you to nod at sagely.
Something for everyone, really.
All this stuff is nice, but… Maybe you need something more. Maybe you’re searching for something in particular, maybe you want the results to look a little different, or uh… maybe you want to be an expert.
I would also love to be an expert. I would tell people expert things like “don’t throw eggs”.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I have sort of a love/hate relationship with wait stats scripts and analysis. Sometimes they’re great to correlate with larger performance problems or trends, and other times they’re totally useless.
When you’re looking at wait stats, some important things to figure out are:
How much of a wait happened compared to uptime
If the waits lasted a long time on average
And you can do that out of the box with SQL Server. What you can’t get are two very important things:
When the waits happened
Which queries caused the waits
This stuff is vitally important for figuring out if wait stats are benign overall to the workload.
For example, let’s say your server has been up for 100 hours, and you spent 50 hours waiting on PAGEIOLATCH_SH waits. Normally I’d be pretty worried about that, and I’d be looking at if the server has enough memory, if queries are asking for big memory grants, if important queries are missing any indexes, etc.
But if we knew that all 50 of those hours were outside of normal use activity, and maybe even happened in a separate database for warehousing or archiving off data, we might be able to ignore it and focus on other portions of the workload.
When this finishes running, you’ll get three results back:
Overall wait stats for the period of time
Wait stats broken down by database for the period of time
Wait stats broken down by database and query for the period of time
And because I don’t want to leave you hanging, you’ll also get details about the waits themselves, like
How much of a wait happened compared to sampled time
How long the waits lasted on average in the sampled time
If you need to figure out which queries are causing wait stats that you’re worried about, this is a great way to get started with that investigation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Like query compilations, query recompilations can be annoying. The bigger difference is that even occasional recompiles can introduce a bad query plan.
If your monitoring tools or scripts are warning you about high compiles or recompiles, sp_HumanEvents can help you dig in further.
We talked about compilations yesterday (and, heck, maybe I should have added that point in there, but hey), so today we’ll talk about recompilations.
There are a lot of reasons why a query might recompile:
Schema changed
Statistics changed
Deferred compile
Set option change
Temp table changed
Remote rowset changed
For browse permissions changed
Query notification environment changed
PartitionView changed
Cursor options changed
Option (recompile) requested
Parameterized plan flushed
Test plan linearization
Plan affecting database version changed
Query Store plan forcing policy changed
Query Store plan forcing failed
Query Store missing the plan
Interleaved execution required recompilation
Not a recompile
Multi-plan statement required compilation of alternative query plan
Query Store hints changed
Query Store hints application failed
Query Store recompiling to capture cursor query
Recompiling to clean up the multiplan dispatcher plan
That list is from SQL Server 2022, so there are going to be some listed here that you might not see just yet.
But let’s face it, the reasons you’re gonna see most often is probably
Schema changed
Statistics changed
Temp table changed
Option (recompile) requested
Mad Dog
To capture which queries are recompiling in a certain window, I’ll usually do something like this:
Schema changed: use a new index that suits the query better
Statistics changed: use newer statistics that more accurately reflect column data
Temp table changed: use a new histogram for a temp table more relevant to the query
Option (recompile) requested: burn it flat, salt the earth
But of course, there’s always an element of danger, danger when a query starts using a new plan. What if it sucks?
To cut down on recompiles, you can use this stuff:
Plan Guides
Query Store forced plans
Keep Plan/KeepFixed Plan query hints
Stop using recompile hints?
One thing that can be a pretty big bummer about recompiles is that, if you’re relying solely on the plan cache to find problem queries, they can leave you with very little (or zero) evidence about what queries are getting up to.
Query Store and some monitoring tools will capture them, so you’re better off using those for more in-depth analysis.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thing that I have to recommend to clients on a fairly regular basis is to enable Forced Parameterization. Many vendor applications send over queries that aren’t parameterized, or without strongly typed parameters, and that can make things… awkward.
Every time SQL Server gets one of those queries, it’ll come up with a “new” execution plan, cache it, and blah blah blah. That’s usually not ideal for a lot of reasons.
There are potentially less tedious ways to figure out which queries are causing problems, by looking in the plan cache or query store.
One way to start getting a feel for which queries are compiling the most, along with some other details about compilation metrics and parameterization is to do this:
Newer versions of SQL Server have an event called query_parameterization_data.
Fired on compile for every query relevant for determining if forced parameterization would be useful for this database.
If you start monitoring compilations with sp_HumanEvents you’ll get details from this event back as well, as long as it’s available in your version of SQL Server.
You can find all sorts of tricky application problems with this event setup.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
In yesterday’s post, I talked through how I capture blocking using sp_HumanEvents. Today I’m going to talk about a couple different ways I use it to capture query performance issues.
One thing I want to stress is that you shouldn’t use yesterday’s technique to gather query performance issues. One thing sp_HumanEvents does is capture actual execution plans, and that can really bog a server down if it’s busy.
I tend to use it for short periods of time, or for very targeted data collection against a single stored procedure or session id running things.
I’ve occasionally toyed with the idea of adding a flag to not get query plans, or to use a different event to get them.
I just don’t think there’s enough value in that to be worthwhile since the actual execution plan has so many important details that other copies do not.
So anyway, let’s do a thing.
Whole Hog
You can totally use sp_HumanEvents to grab absolutely everything going on like this:
You may need to do this in some cases when you’re first getting to know a server and need to get a feeling for what’s going on. This will show you any query that takes 5 seconds or longer in the 20 second window the session is alive for.
If you’re on a really busy server, it can help to cut down on how much you’re pulling in:
This will only pull in data from sessions if their spid is divisible by 5. The busier your server is, the weirder you might want to make this number, like 15/17/19 or something.
Belly
Much more common for me is to be on a development server, and want to watch my spid as I execute some code:
This is especially useful if you’re running a big long stored procedure that calls a bunch of other stored procedures, and you want to find all the statements that take a long time without grabbing every single query plan.
If you’ve ever turned on Actual Execution Plans and tried to do this, you might still be waiting for SSMS to become responsive again. It’s really painful.
By only grabbing query details for things that run a long time, you cut out all the little noisy queries that you can’t really tune.
I absolutely adore this, because it lets me focus in on just the parts that take a long time.
Shoulder
One pretty common scenario is for clients to give me a list of stored procedures to fix. If they don’t have a monitoring tool, it can be a challenge to understand things like:
How users call the stored procedure normally
If the problem is parameter sniffing
Which queries in the stored procedure cause the biggest problems
This will only collect sessions executing a single procedure. I’ll sometimes do this and work through the list.
Hoof
There are some slight differences in how I call the procedure in different circumstances.
When I use the @seconds_sample parameter, sp_HumanEvents will run for that amount of time and then spit out a result
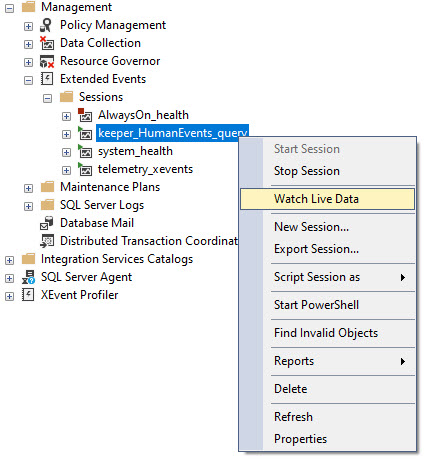
When I use the @keep_alive parameter, all that happens is a session gets created and you need to go watch live data like this:
viewme
Just make sure you do that before you start running your query, or you might miss something important.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Unlike most people who left links in the comments, I read the entire post and decided to use the whole darn month to write about scripts I maintain and how I use them in my work.
Lest I be accused of not being able to read a calendar, I know that these are dropping a little earlier than the 1st of September. I do apologize for September not starting on a Monday.
There are other great tools and utilities out there, like Andy Mallon’s DBA Utility Database, but I don’t use them enough personally to be able to write about them fluently.
My goal here is to help you use each script with more confidence and understanding. Or even any confidence and understanding, if none existed beforehand.
Oral Board
First up is (well, I think) my most ambitious script: sp_HumanEvents. If you’re wondering why I think it’s so ambitious, it’s because the goal is to make Extended Events usable by Humans.
At present, that’s around 4000 lines of T-SQL. Now, sp_HumanEvents can do a lot of stuff, including logging event data to tables for a bunch of different potential performance issues.
When I was first writing this thing, I wanted it to be able to capture data in a few different ways to fit different monitoring scenarios. In this post, I’m going to show you how I most often use it on systems that have are currently experiencing blocking.
First, you need to have the Blocked Process Report enabled, which is under advanced options:
If you want to flip the advanced options setting back, you can. I usually leave it set to 1.
The second command turns on the blocked process report, and tells SQL Server to log any instances of blocking going on for 5 or more seconds. You can adjust that to meet your concerns with blocking duration, but I wouldn’t set it too low because there will be overhead, like with any type of monitoring.
Blockeroos
The way I usually set up to look at blocking that’s currently happening on a system — which is what I most often have to do — is to set up a semi-permanent session and watch what data comes in.
When I want to parse that data, I use sp_HumanEventsBlockViewer to do that. At first, I just want to see what kind of stuff starts coming in.
What this will do is set up an Extended Event session to capture blocking from the Blocked Process Report. That’s it.
From there, you can either use my script (linked above), or watch data coming in via the GUI. Usually I watch the GUI until there’s some stuff in there to gawk at:
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
From query plans, you can get the plan handle and plan hash:
WITH XMLNAMESPACES(DEFAULT 'http://schemas.microsoft.com/sqlserver/2004/07/showplan')
SELECT
session_id,
query_plan,
additional_info,
query_hash =
q.n.value('@QueryHash', 'varchar(18)'),
query_plan_hash =
q.n.value('@QueryPlanHash', 'varchar(18)')
FROM dbo.WhoIsActive AS w
CROSS APPLY w.query_plan.nodes('//StmtSimple') AS q(n);
From additional info, you can get the SQL Handle and Plan Handle:
SELECT
session_id,
query_plan,
additional_info,
sql_handle =
w.additional_info.value('(//additional_info/sql_handle)[1]', 'varchar(131)'),
plan_handle =
w.additional_info.value('(//additional_info/plan_handle)[1]', 'varchar(131)')
FROM dbo.WhoIsActive AS w;
Causation
For the plan cache, you can use your favorite script. Mine is, of course, sp_BlitzCache.
You you can use the @OnlyQueryHashes or @OnlySqlHandles parameters to filter down to queries you’re interested in.
For Query Store, you can use my script sp_QuickieStore to do the same thing.
It has parameters for @include_query_hashes, @include_plan_hashes or @include_sql_handles.
You might want to add some other filtering or sorting to the queries up there to find what you’re interested in, but this should get you started.
I couldn’t find a quick or easy way to combine the two queries, since we’re dealing with two different columns of XML data, and the query plan XML needs a little special treatment to be queried.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.