Upon reading the title, you may be thinking that of course parallel scans will be slow in the cloud. Cloud storage storage simply isn’t very fast. I would argue that there’s a bit more to it.
The Timeout
A query timed out the other day in production after running for 600 seconds. Of note, one of the tables used by the stored procedure is in a database with data files hosted by Azure blob storage. I grabbed the wait stats for the timed out query using query store:
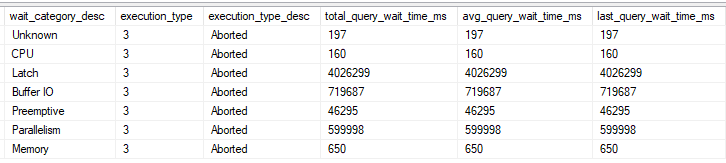
According to the documentation, the latch category maps to LATCH_% wait types and the preemptive category maps to PREEMPTIVE_% wait types. I wasn’t able to reproduce the timeout when executing the same query text, even if I forced the exact same query plan with a USE PLAN. Admittedly, I was puzzled by the wait stats distribution for a while.
Decoding the Categories
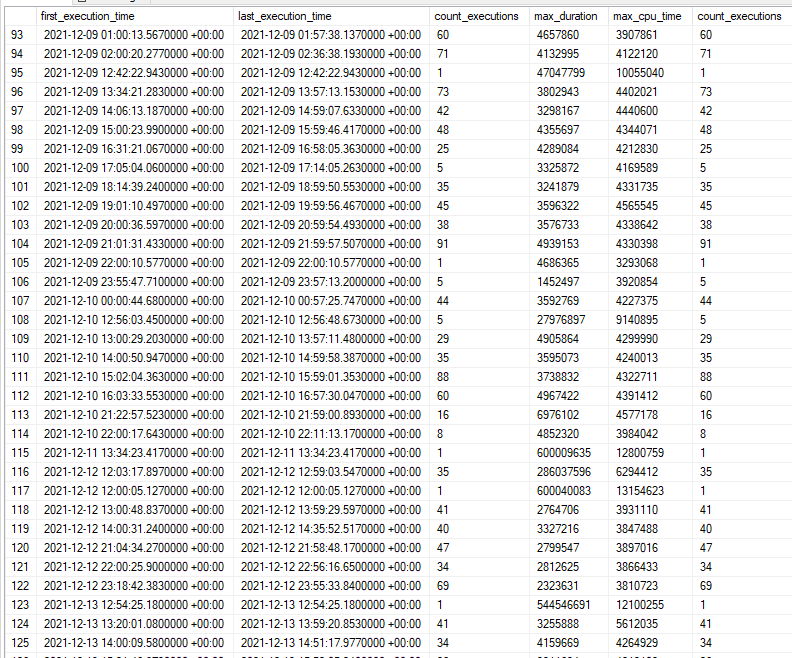
I eventually realized that typically the first execution of the stored procedure for the business day tended to be the slowest. Sorting query store runtime DMV results by time:
I also noticed that the timed out executions tended to have higher physical I/O than the other executions. Sorting query store runtime DMV results by I/O:
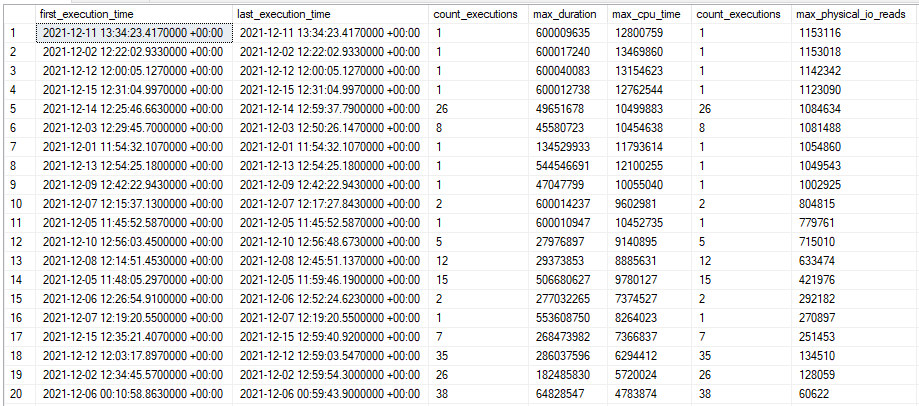
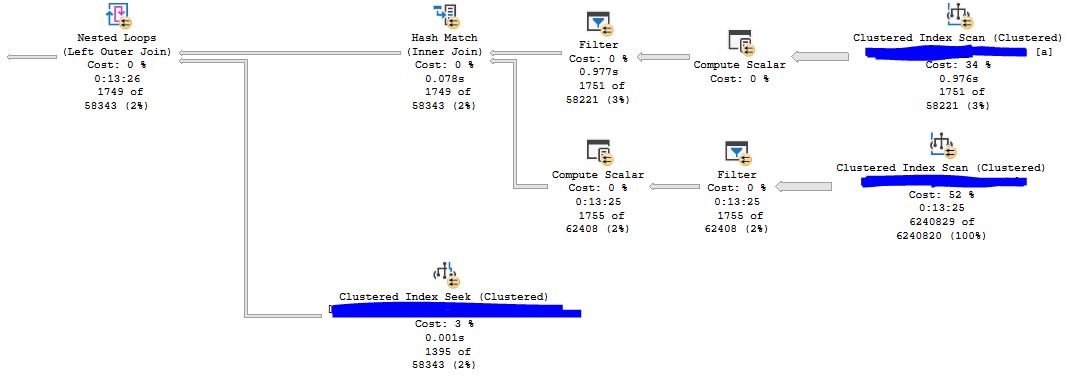
I now finally had a method to reproduce the poor performance of the stored procedure: being the first one to run the code in the morning, presumably when the buffer pool didn’t have anything helpful for this stored procedure. Early in the morning, I was able to capture an actual plan that took 13 minutes at MAXDOP 8. Nearly all of the execution time is spent on an index scan for a table that is hosted on cloud storage:
Here are the top wait stats from the actual plan:
<Wait WaitType=”LATCH_EX” WaitTimeMs=”5423928″ WaitCount=”1971″ />
<Wait WaitType=”PAGEIOLATCH_SH” WaitTimeMs=”977288″ WaitCount=”29210″ />
<Wait WaitType=”CXPACKET” WaitTimeMs=”809678″ WaitCount=”700″ />
<Wait WaitType=”PREEMPTIVE_HTTP_REQUEST” WaitTimeMs=”43801″ WaitCount=”50344″ />
I used the task DMVs during query execution to get information about the latch type:
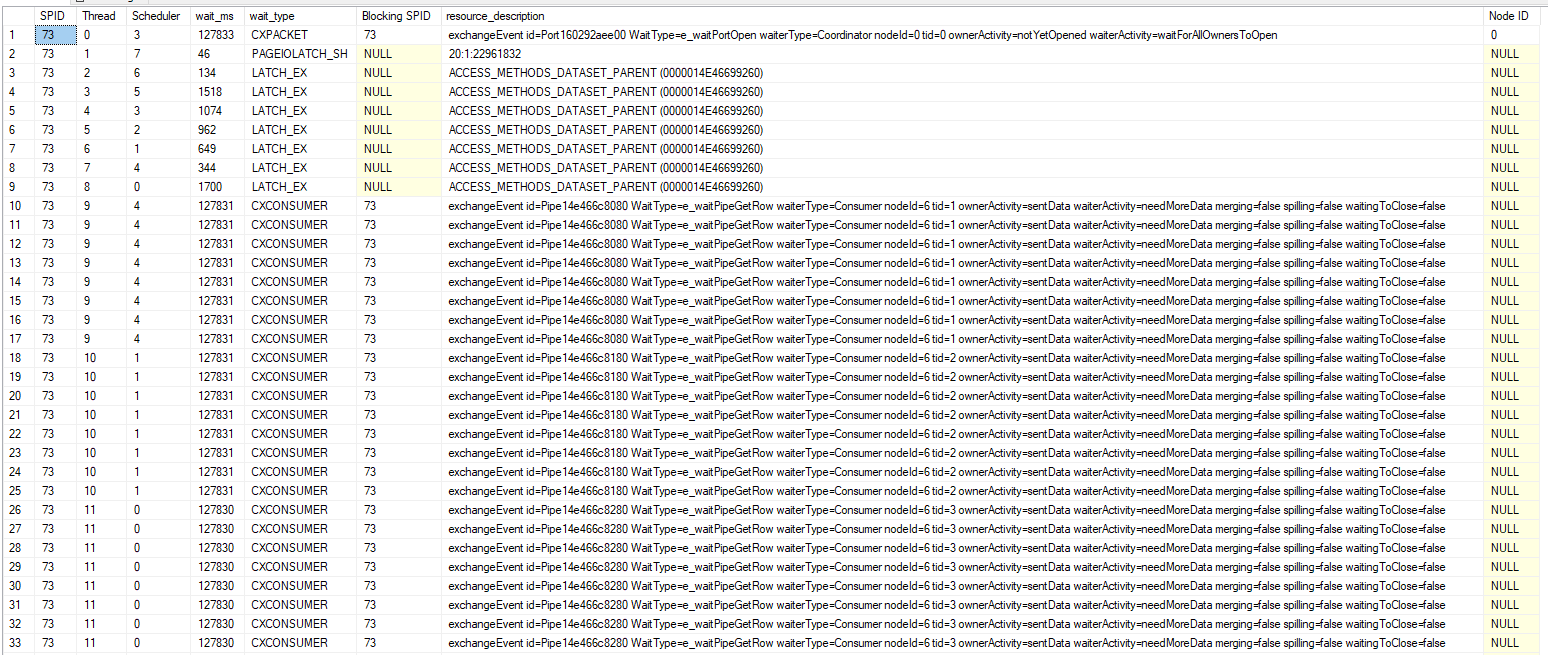
Now I know that the query spends most of its time trying to acquire exclusive latches of the ACCESS_METHODS_DATASET_PARENT type. There is also a fair amount of I/O wait time compared to the mysterious PREEMPTIVE_HTTP_REQUEST wait type.
The ACCESS_METHODS_DATASET_PARENT Latch
I asked the community if this latch was considered to be interesting. The winning option was “What?”. As usual, twitter is useless:
For my query, at times I observed seven out of eight worker threads all waiting for an exclusive latch at the same time. This isn’t surprising considering that the query averaged 6.7 LATCH_EX wait seconds per second. That the other thread was doing an I/O wait while the others were waiting for the latch, so perhaps the worker threads were doing I/Os while holding the latch resource. On a development environment (with unfortunately significantly better I/O), I mocked up a roughly similar table and enabled the latch_acquired, latch_released, file_read, and file_read_completed extended events. The results were quite educational:
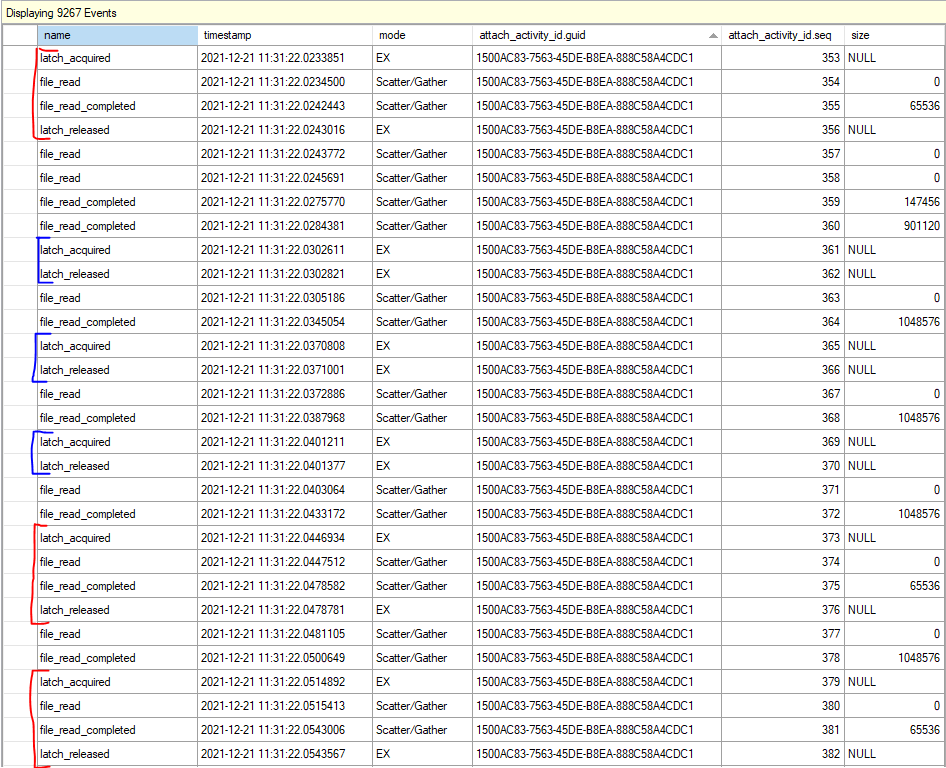
There were two different patterns in the XE files. Sometimes the worker threads would acquire the latch, perform one or more I/Os, and release the latch. Otherwise they would acquire the latch and quickly release it without performing any I/Os. Paul Randal recently wrote the following about this latch:
When either a heap or an index is being accessed, internally there’s an object called a HeapDataSetSession or IndexDataSetSession, respectively. When a parallel scan is being performed, the threads doing the actual work of the scan each have a “child” dataset (another instance of the two objects I just described), and the main dataset, which is really controlling the scan, is called the “parent.”
When one of the scan worker threads has exhausted the set of rows it’s supposed to scan, it needs to get a new range by accessing the parent dataset, which means acquiring the ACCESS_METHODS_DATASET_PARENT latch in exclusive mode. While this can seem like a bottleneck, it’s not really, and there’s nothing you can do to stop the threads performing a parallel scan from occasionally showing a LATCH_EX wait for this latch.
At a very high level, I suspect that the fast latch releases (marked in blue in the above picture) occur when the worker thread can acquire an already available range of rows from the parent object. The slow latch releases (marked in red) occur when the worker thread tries to acquire a new range, can’t find one, and has to perform I/Os to add more ranges to the parent object. In both cases the parent object needs to be modified, so an exclusive latch is always taken. I don’t know how it actually works behind the scenes, but the theory matches the observed behavior.
In summary, the query does a parallel scan which is protected by the ACCESS_METHODS_DATASET_PARENT latch. The table getting scanned is hosted on cloud storage with high I/O latency. Latency being high contributes to the exclusive latch on ACCESS_METHODS_DATASET_PARENT getting held for a long time which can block all of the other parallel worker threads from proceeding.
The PREEMPTIVE_HTTP_REQUEST Wait Type
I already have enough information to be confident in a query tuning fix for the stored procedure, but for completeness, I also investigated the PREEMPTIVE_HTTP_REQUEST wait type. I was not able to find any useful documentation for this wait type. The official documentation only says “Internal use only.” Thanks, Microsoft.
A common technique to learn more about undocumented waits is to get callstacks associated with the wait type. I’ve seen the PREEMPTIVE_HTTP_REQUEST wait occur in Azure SQL databases, Azure SQL Managed Instances, and for databases hosted in Azure blob storage. It is possible to get callstacks for managed instances, but it is not possible to translate them because Microsoft does not release public symbols for managed instances. However, the blob storage scenario did allow me to get and translate call stacks for the wait. Below are a few of the stacks that I captured:
Performing I/Os to read data not in the buffer pool:
sqldk!XeSosPkg::wait_info_external::Publish
sqldk!SOS_Task::PushWait
sqlmin!SOS_Task::AutoSwitchPreemptive::AutoSwitchPreemptive
sqlmin!BlobAccess::AsyncHttpIOInternal
sqlmin!BlobAccess::AsyncIOInternal
sqlmin!XFCB2::ScatterReadInternal
sqlmin!FCB::ScatterRead
sqlmin!RecoveryUnit::ScatterRead
sqlmin!BPool::GetFromDisk
sqlmin!BPool::Get
sqlmin!BlobBase::FixNode
sqlmin!BlobManager::LocateBlob
sqlmin!BlobManager::OpenInternal
sqlmin!BlobManager::Open
sqlmin!LockBytesSS::Open
sqlmin!OpenLockBytesNew
sqlmin!OpenIlbssWithSeLobHandleRO
sqlmin!IndexDataSetSession::OpenStreamWithSeLobHandle
sqlmin!RowsetNewSS::OpenWithSeLobHandle
sqlmin!CBlobHandleBaseTableFactory::PilbGet
sqlTsEs!CompareLegacyLobNull
sqlTsEs!CTEsCompare<35,35>::BlCompareXcArgArgImpl
sqlTsEs!CEsExec::GeneralEval4
sqlmin!CQScanStreamAggregateNew::GetRowHelper
Writing LOB data to disk:
sqldk!XeSosPkg::wait_info_external::Publish
sqldk!SOS_Task::PushWait
sqlmin!SOS_Task::AutoSwitchPreemptive::AutoSwitchPreemptive
sqlmin!BlobAccess::AsyncHttpIOInternal
sqlmin!BlobAccess::AsyncIOInternal
sqlmin!XFCB2::ScatterReadInternal
sqlmin!FCB::ScatterRead
sqlmin!RecoveryUnit::ScatterRead
sqlmin!BPool::GetFromDisk
sqlmin!BPool::Get
sqlmin!BlobBase::FixNode
sqlmin!Blob::RWBlob
sqlmin!Blob::RWBlob
sqlmin!Blob::ReadWriteAt
sqlmin!BlobManager::ReadAtInternal
sqlmin!BlobManager::ReadAt
sqlmin!LockBytesSS::ReadAt
sqllang!write_LOB_chunked
sqllang!`anonymous namespace’::TSendRowClassNoCount<7,0>::TSendUnlimitedVartype<0>
sqllang!CTds74::SendRowImpl
sqlTsEs!CEsExec::GeneralEval
sqllang!CXStmtQuery::ErsqExecuteQuery
sqllang!CXStmtSelect::XretExecute
sqllang!CMsqlExecContext::ExecuteStmts<1,1>
Transaction log writes:
sqldk!XeSosPkg::wait_info_external::Publish
sqldk!SOS_Scheduler::UpdateWaitTimeStats
sqldk!SOS_Task::PopWait
sqlmin!SOS_ExternalAutoWait::~SOS_ExternalAutoWait
sqlmin!SOS_Task::AutoSwitchPreemptive::~AutoSwitchPreemptive
sqlmin!BlobAccess::AsyncHttpIOInternal
sqlmin!BlobAccess::AsyncIOInternal
sqlmin!XFCB2::AsyncWriteInternal
sqlmin!FCB::AsyncWrite
sqlmin!SQLServerLogMgr::FlushLCOld
sqlmin!SQLServerLogMgr::LogWriter
sqldk!SOS_Task::Param::Execute
sqldk!SOS_Scheduler::RunTask
sqldk!SOS_Scheduler::ProcessTasks
sqldk!SchedulerManager::WorkerEntryPoint
sqldk!SystemThreadDispatcher::ProcessWorker
sqldk!SchedulerManager::ThreadEntryPoint
KERNEL32.DLL+0x0000000000017974
ntdll.dll+0x000000000006A271
I’m guessing this one is renewing the lease as noted in the documentation: “the implementation of SQL Server Data Files in Azure Storage feature requires a renewal of blob lease every 45 to 60 seconds implicitly”
sqldk!XeSosPkg::wait_info_external::Publish
sqldk!SOS_Task::PushWait
sqlmin!SOS_Task::AutoSwitchPreemptive::AutoSwitchPreemptive
sqlmin!BlobAccess::AsyncHttpIOInternal
sqlmin!BlobAccess::AsyncIOInternal
sqlmin!LeaseRenewalManager2::RenewLeases
sqlmin!XStoreLeaseRenewalTask2
sqldk!SOS_Task::Param::Execute
sqldk!SOS_Scheduler::RunTask
sqldk!SOS_Scheduler::ProcessTasks
sqldk!SchedulerManager::WorkerEntryPoint
sqldk!SystemThreadDispatcher::ProcessWorker
sqldk!SchedulerManager::ThreadEntryPoint
Not surprisingly, all of them have to do with accessing azure storage. I was able to observe an interesting pattern during a table scan: every PAGEIOLATCH_SH wait was immediately preceded by a PREEMPTIVE_HTTP_REQUEST wait.
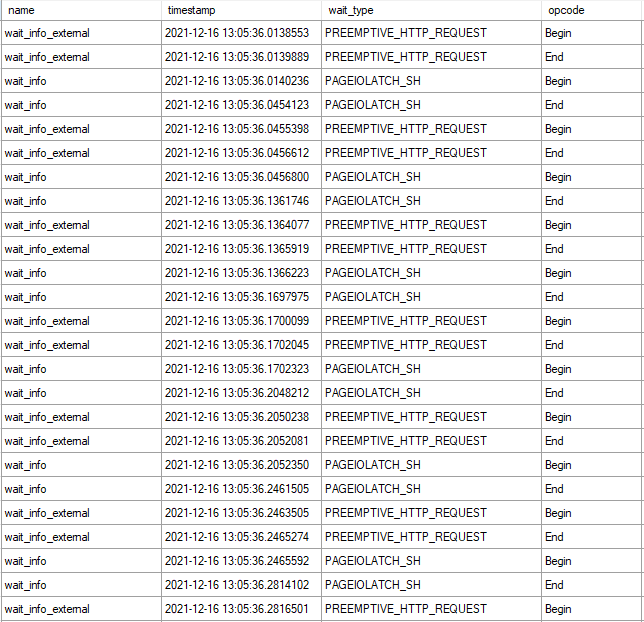
Getting stacks for the waits that are close together, with shared code removed and the I/O wait on top with the preemptive wait on the bottom:
sqldk!XeSosPkg::wait_info::Publish
sqldk!SOS_Task::PreWait
sqldk!WaitableBase::Wait
sqlmin!LatchBase::Suspend
sqlmin!LatchBase::AcquireInternal
sqlmin!BUF::AcquireLatch
sqlmin!BPool::Get
<<SHARED STACKS REMOVED>>sqldk!XeSosPkg::wait_info_external::Publish
sqldk!SOS_Task::PushWait
sqlmin!SOS_Task::AutoSwitchPreemptive::AutoSwitchPreemptive
sqlmin!BlobAccess::AsyncHttpIOInternal
sqlmin!BlobAccess::AsyncIOInternal
sqlmin!XFCB2::ScatterReadInternal
sqlmin!FCB::ScatterRead
sqlmin!RecoveryUnit::ScatterRead
sqlmin!BPool::GetFromDisk
sqlmin!BPool::Get
sqlmin!BlobBase::FixNode
sqlmin!BlobManager::LocateBlob
sqlmin!BlobManager::OpenInternal
sqlmin!BlobManager::Open
sqlmin!LockBytesSS::Open
sqlmin!OpenLockBytesNew
sqlmin!OpenIlbssWithSeLobHandleRO
sqlmin!IndexDataSetSession::OpenStreamWithSeLobHandle
sqlmin!RowsetNewSS::OpenWithSeLobHandle
sqlmin!CBlobHandleBaseTableFactory::PilbGet
sqlTsEs!CompareLegacyLobNull
My understanding is that SQL Server makes an HTTP request to the blob storage in preemptive mode in order to queue an asynchronous I/O. The preemptive wait ends and the PAGEIOLATCH_SH wait begins shortly after. The traditional I/O wait ends when the I/O is received by SQL Server. That’s just a guess though.
I think a reasonable summary is that you should expect to see PREEMPTIVE_HTTP_REQUEST waits if you’re performing I/O against Azure storage. They are a normal part of SQL Server’s operations.
Reducing ACCESS_METHODS_DATASET_PARENT Latch Wait Time
In some situations, a query that is slow due to I/O performance can run faster with a higher DOP. Instead of one thread waiting for I/O you can have many threads waiting and overall runtime will decrease. Of course, this won’t work in all scenarios, such as if you’re hitting an IOPs limit. For my scenario, the DOP 8 query had 6.7 LATCH_EX wait seconds per second of runtime. Latch contention is so bad that it nearly steals all of the theoretical benefits achieved with query parallelism.
The obvious solution is to reduce the amount of I/O that is done by the query. That is what was indeed done to resolve the production issue. Another obvious solution is to improve I/O performance. More on that in the next section. However, in some cases the query may simply need to scan a lot of data and you can’t do anything about storage performance. In that situation, it may sometimes be practical to change the type of parallel scan performed by SQL Server.
Consider the following parallel plan against a partitioned table on the probe side:
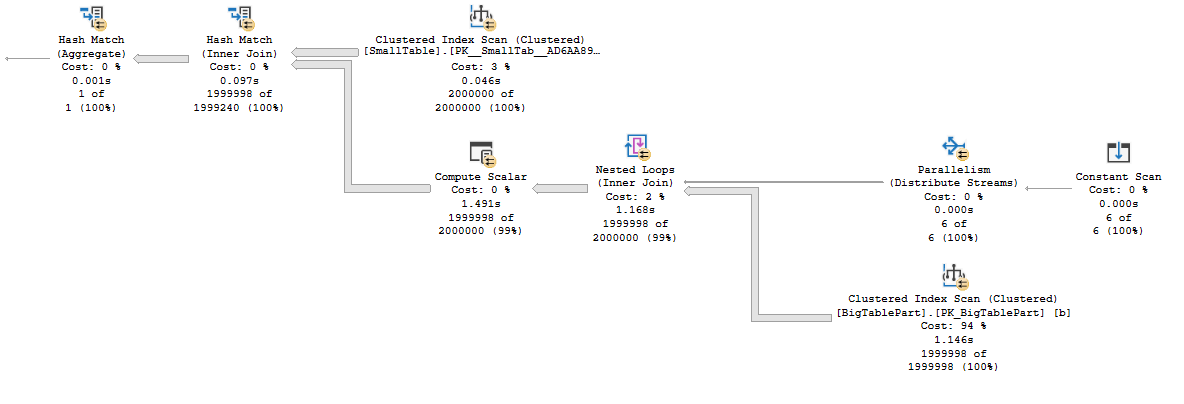
For clarity, here is what the T-SQL looks like:
SELECT SUM(Case WHEN OffPageFiller IS NOT NULL THEN 1 ELSE 0 END)
FROM (
VALUES (1),(2),(3),(4),(5),(6)
) v(v)
CROSS APPLY(
SELECT OffPageFiller
FROM dbo.SmallTable s
INNER JOIN dbo.BigTablePart b ON s.JoinId = b.JoinId
WHERE b.PartId = v.v
) q;
Each thread of the parallel nested loop operator gets assigned an entire partition and reads all of the data for that partition. There is no longer a need for the ACCESS_METHODS_DATASET_PARENT latch because the shared state between worker threads has been removed. I checked using extended events and found that the ACCESS_METHODS_DATASET_PARENT latch wait count was significantly decreased as expected. I suspect that the remaining latch acquisitions were from the hash build side scan. This type of access pattern requires a partitioned table, can be a pain to express in T-SQL, and may not work well if partitions are unevenly sized or if there aren’t enough partitions compared to DOP to get good demand-based distribution.
Perhaps a more reasonable option is to switch to columnstore instead. The query will do less I/O and I assume that the latch pattern is quite different, but I didn’t test this. Testing things in the cloud costs money. Maybe I should start a Patreon.
Reducing PREEMPTIVE_HTTP_REQUEST Wait Time
As I said earlier, I believe that seeing this wait is normal if you’re using azure storage. In my limited experience with it, any noticeable wait time was always tied to even longer PAGEIOLATCH waits. Tuning the query using traditional methods to reduce I/O wait time was always sufficient and I never had a need to specifically focus on PREEMPTIVE_HTTP_REQUEST. However, if you really need to focus on this wait type in particular for some reason, I’ll theorize some ways to reduce it:
- For all platforms, reduce I/O performed by the query using query tuning, schema changes, and so on.
- For managed instances, move your I/O from user databases to tempdb (it uses locally attached storage).
- For azure blob storage databases, make sure that you are using the right geographical region for your storage.
Here are a few more options which may not specifically reduce PREEMPTIVE_HTTP_REQUEST wait time but may improve I/O performance overall:
- For managed instances and azure blob storage databases, try increasing the size of your data files.
- For managed instances, try increasing the number of data files.
- For all platforms, switch to a more expensive tier of storage.
Final Thoughts
The query timed out in production because it performed a large parallel scan against a table that had little to no data in the buffer pool. PAGEIOLATCH waits were not the dominant wait type due to high latency from Azure blob storage. That high latency caused latch contention on the ACCESS_METHODS_DATASET_PARENT latch. My parallel scan was slow because cloud storage isn’t very fast. Maybe it isn’t so complicated after all?
One thought on “Why Some Types of Parallel Scans can be Slow on Cloud Storage”
Comments are closed.