Olympus
In my session on using dynamic SQL to defeat parameter sniffing, I walk through how we can use what we know statistically about data to execute slightly different queries to get drastically better query plans. What makes the situation quite frustrating is that SQL Server has the ability to do the same thing.
In fact, it does it every time it freshly compiles a plan based on parameter values. It makes a whole bunch of estimates and comes up with that it thinks is a good plan based on them.
But it sort of stops there.
Why am I talking about this now? Well, since Greatest and Least got announced for Azure SQL, it kind of got my noggin’ joggin’ that perhaps a new build of the box-product might make its way to the CTP phase soon.
I Dream Of Histograms
When SQL Server builds execution plans, the estimates (mostly) come from statistics histograms, and those histograms are generally pretty solid even with low sampling rates. I know that there are times when they miss crucial details, but that’s a different problem than the one I think could be solved here.
You see, when a plan gets generated, the entire histogram is available. It would be neat if there were a process to do one of a few things:
- Mark objects with significant skew in them for additional attention
- Bucket values by similar populations
- Explore other plan choices for values per bucket
If you team this up with other features in the Intelligent Query Processing family, it could really help solve some of the most basic parameter sniffing issues. That’s what you want these features for: to take care of the low-hanging nonsense. Just like the cardinality estimation feedback that got announced at PASS Summit.
Take the VoteTypeId column in the Votes table. Lots of these values could safely share a plan. Lots of others have catastrophe in mind when plans are shared, like 2 and… well, most others.
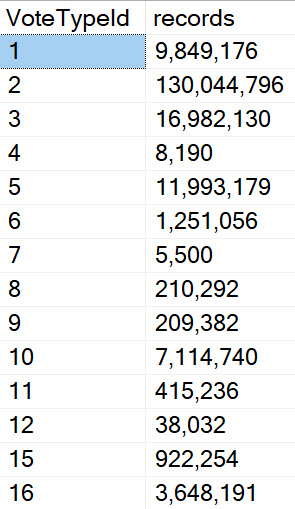
Sort of like how optimistic isolation levels take care of basic reader/writer blocking that sucks to deal with and leads to all those crappy NOLOCK hints. Save the hard problems for young handsome consultants.
Ahem ?
Overboard
I know, this sounds crazy-ambitious, and it could get out of hand quickly. Not to mention confusing! We’re talking about queries having multiple cached and usable plans, here. Who used what and when would be crucial information.
You’d need a lot of metadata about something like this, so you can tweak:
- The number of plans
- The number of buckets
- Which plan is used by which buckets
- Which code and parameters should be considered
I’m fine with auto-pilot for this most of the time, just to get folks out of the doldrums. Sort of like how Query Store was “good enough” with a bunch of default options, I think you’d find a lot of preconceived notions about what works best would pretty quickly be relieved of their position.
Anyway, I have a bunch of other posts about similar solvable problems. I have no idea when the next version of SQL Server will come out, or what improvements or features might be in it, but I hear that blog posts are basically wishes that come true. I figure I might as well throw some coins in the fountain.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Related Posts
- Things SQL Server vNext Should Address: How Did I Do?
- Things SQL Server vNext Should Address: Add Lock Pages In Memory To Setup Options
- Things SQL Server vNext Should Address: Add Cost Threshold For Parallelism To Setup Options
- Changes Coming To SQL Server’s STRING_SPLIT Function: Optional Ordinal Position