Cardinality Estimation For Local Variables And Parameters
I’m working on ramping up my recording and streaming setup now that life has settled down a little bit, and publishing the results to YouTube while I work out the wrinkles. Enjoy some free video content!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
When one thinks of effective communicators, indexes aren’t usually at the top of the list. And for good reason!
They’re more the strong, silent type. Like Gary Cooper, as a wiseguy once said. But they do need to talk to each other, sometimes.
For this post, I’m going to focus on tables with clustered indexes, but similar communication can happen with the oft-beleaguered heap tables, too.
Don’t believe me? Follow along.
Clustered
This post is going to focus on a table called Users, which has a bunch of columns in it, but the important thing to start with is that it has a clustered primary key on a column called Id.
Shocking, I know.
CONSTRAINT PK_Users_Id
PRIMARY KEY CLUSTERED
(
Id ASC
)
But what does adding that do, aside from put the table into some logical order?
The answer is: lots! Lots and lots. Big lots (please don’t sue me).
Inheritance
The first thing that comes to my mind is how nonclustered indexes inherit that clustered index key column.
Let’s take a look at a couple examples of that. First, with a couple single key column indexes. The first one is unique, the second one is not.
/*Unique*/
CREATE UNIQUE INDEX
whatever_uq
ON dbo.Users
(AccountId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
/*Not unique*/
CREATE INDEX
whatever_nuq
ON dbo.Users
(AccountId)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
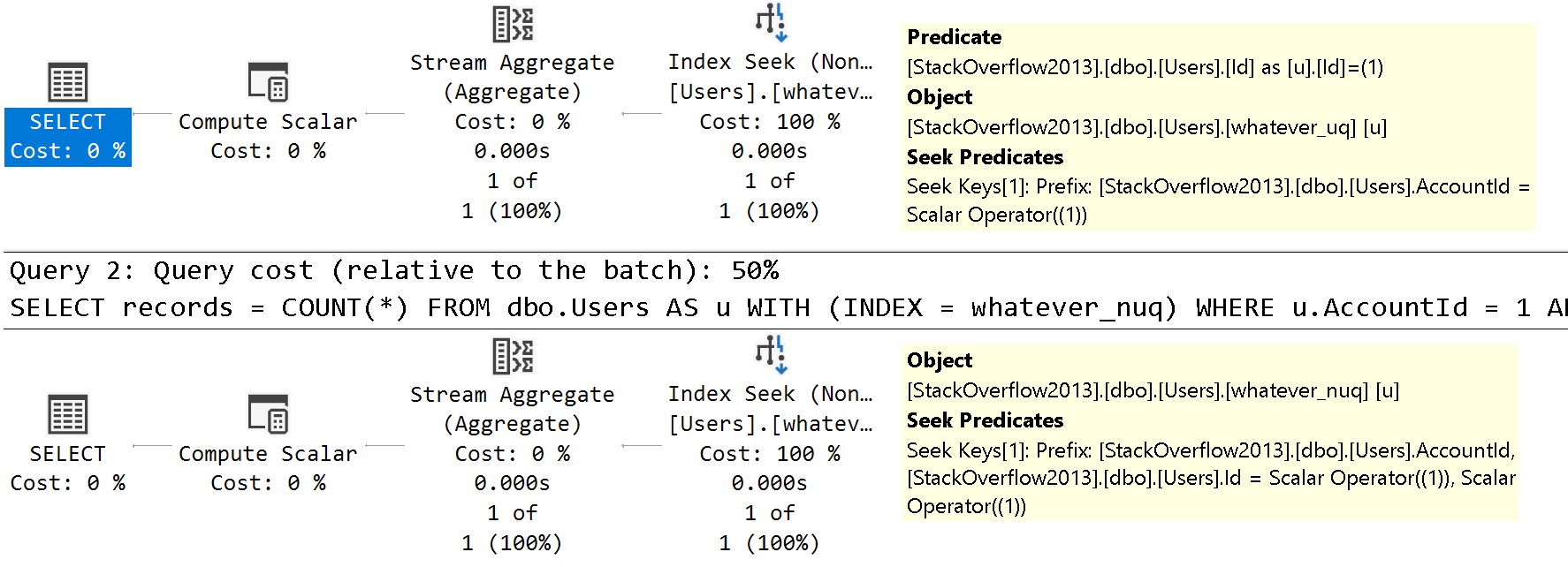
For these queries, pay close attention to the where clause. We’re searching on both the AccountId column that is the only column defined in our index, and the Id column, which is the only column in our clustered index.
SELECT
records = COUNT(*)
FROM dbo.Users AS u WITH (INDEX = whatever_uq)
WHERE u.AccountId = 1
AND u.Id = 1;
SELECT
records = COUNT(*)
FROM dbo.Users AS u WITH (INDEX = whatever_nuq)
WHERE u.AccountId = 1
AND u.Id = 1;
The query plans are slightly different in how the searches can be applied to each index.
dedicated
See the difference?
In the unique index plan, there is one seek predicate to AccountId, and one residual predicate on Id
In the non-unique index plan, there are two seeks, both to AccountId and to Id
The takeaway here is that unique nonclustered indexes inherit clustered index key column(s) are includes, and non-unique nonclustered indexes inherit them as additional key columns.
Fun!
Looky, Looky
Let’s create two nonclustered indexes on different columns. You know, like normal people. Sort of.
I don’t usually care for single key column indexes, but they’re great for simple demos. Remember that, my lovelies.
CREATE INDEX
l
ON dbo.Users
(LastAccessDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
c
ON dbo.Users
(CreationDate)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
How will SQL Server cope with all that big beautiful index when this query comes along?
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.CreationDate >= '20121231'
AND u.LastAccessDate < '20090101';
How about this bold and daring query plan?
indexified!
SQL Server joins two nonclustered indexes together on the clustered index column that they both inherited. Isn’t that nice?
Danes
More mundanely, this is the mechanism key lookups use to work, too. If we change the last query a little bit, we can see a great example of one.
SELECT
u.*
FROM dbo.Users AS u
WHERE u.CreationDate >= '20121231'
AND u.LastAccessDate < '20090101';
Selecting all the columns from the Users table, we get a different query plan.
uplook
The tool tip pictured above is detail from the Key Lookup operator. From the top down:
Predicate is the additional search criteria that we couldn’t satisfy with our index on Last Access Date
Object is the index being navigated (clustered primary key)
Output list is all the columns we needed from the index
Seek Predicates define the relationship between the clustered and nonclustered index, in this case the Id column
And this is how indexes talk to each other in SQL Server. Yay.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Most applications have a grace period that they’ll let queries run for before they time out. One thing that I notice people really hate is when that happens, because sometimes the effects are pretty rough.
You might have to roll back some long running modification.
Even if you have Accelerated Database Recovery enabled so that the back roll is instant, you may have have 10-30 seconds of blocking.
Or just like, unhappy users because they can’t get access to the information they want.
Monitoring for those timeouts is pretty straight forward with Extended Events.
Eventful
Here’s the event definition I used to do this. You can tweak it, and if you’re using Azure SQL DB, you’ll have to use ON DATABASE instead of ON SERVER.
CREATE EVENT SESSION
timeouts
ON SERVER
ADD EVENT
sqlserver.sql_batch_completed
(
SET collect_batch_text = 1
ACTION
(
sqlserver.database_name,
sqlserver.sql_text
)
WHERE result = 'Abort'
)
ADD
TARGET package0.event_file
(
SET filename = N'timeouts'
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 5 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = OFF,
STARTUP_STATE = OFF
);
GO
ALTER EVENT SESSION timeouts ON SERVER STATE = START;
GO
There are a ton of other things you can add under ACTION to identify users running the queries, etc., but this is good enough to get us going.
The sql_batch_completed event is good for capturing “ad hoc” query timeouts, like you might see from Entity Framework queries that flew off the rails for some strange reason 🤔
If your problem is with stored procedures, you might want to use rpc_completed or sp_statement_completed which can additionally filter to an object_name to get you to a specific procedure as well.
Stressful
To do this, I’m going to use the lovely and talented SQL Query Stress utility, maintained by ErikEJ (b|t).
Why? Because the query timeout setting in SSMS are sort of a nightmare. In SQL Query Stress, it’s pretty simple.
command timeout
And here’s the stored procedure I’m going to use:
CREATE OR ALTER PROCEDURE
dbo.time_out_magazine
AS
BEGIN
WAITFOR DELAY '00:00:06.000';
END;
GO
Why? Because I’m lazy, and I don’t feel like writing a query that runs for 6 seconds right now.
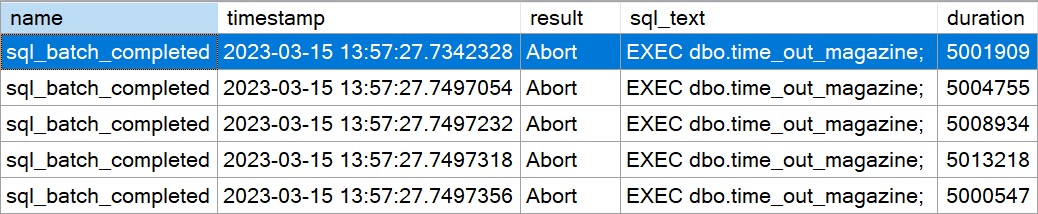
Wonderful
After a few seconds, data starts showing up in our Extended Event Session Viewer For SSMS Pro Azure Premium For Business 720.
caught!
But anyway, if you find yourself hitting query timeouts, and you want a way to capture which ones are having problems, this is one way to do that.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If you take performance for your SQL Servers seriously, you should be using Query Store for your business critical databases.
I used to say this about third party monitoring tools, but the landscape for those has really tanked over the last few years. I used to really love SQL Sentry, but it has essentially become abandonware since SolarWinds bought SentryOne.
At this point, I’m happier to enable query store, and then use a couple extended events to capture blocking and deadlocks. While it would be stellar if Query Store also did that, for now life is easy enough.
To analyze blocking and deadlock Extended Events, I use:
This won’t capture absolutely everything, but that’s okay. We can usually get enough to go on with those three things. If you have bad blocking and deadlocking problems, you should start there.
But once you turn on Query Store, where do you go?
Gooey
If you’re okay with all the limitations of the GUI, you can tweak a few things to get more useful information out of it.
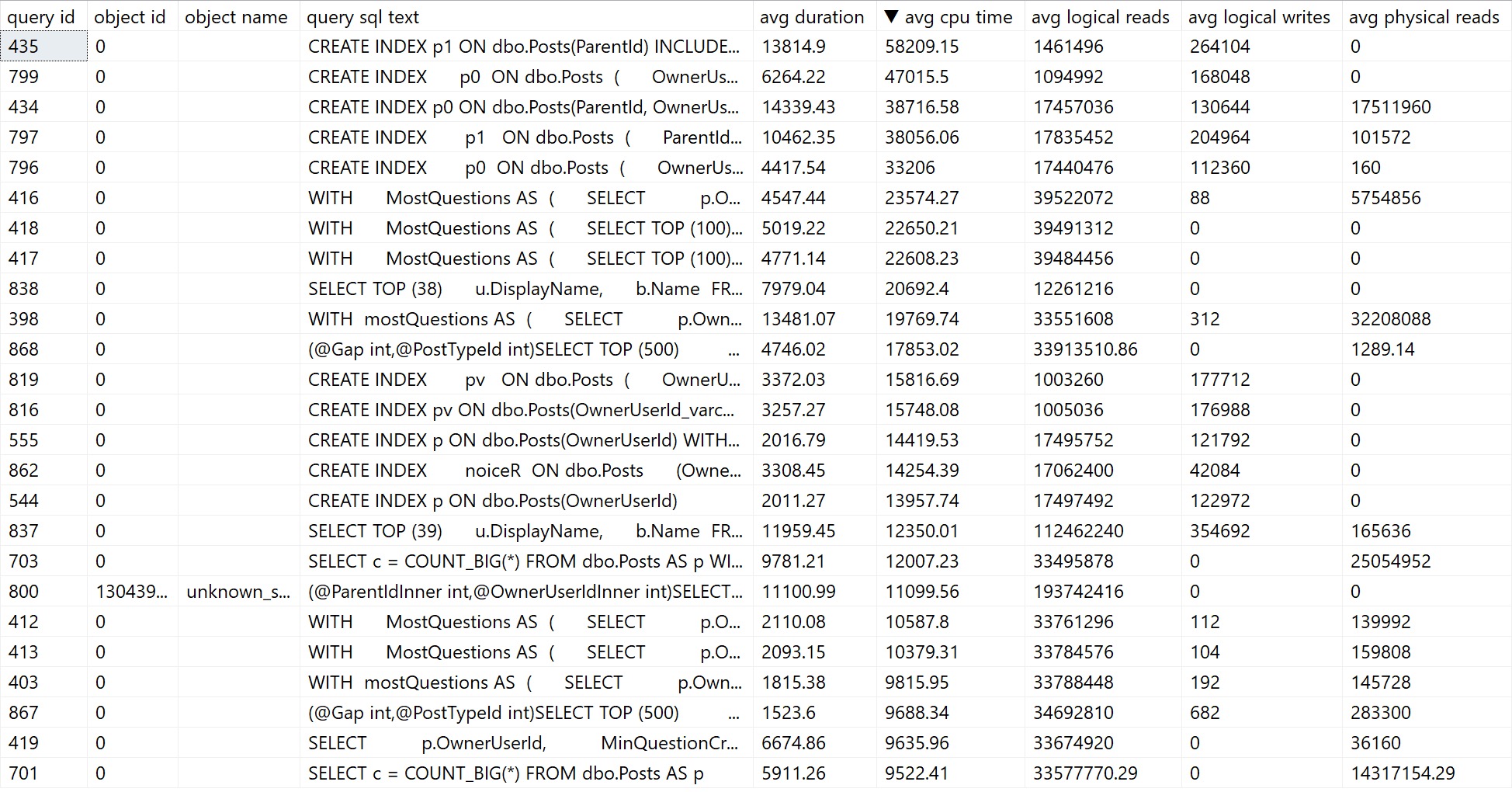
I usually start with the Top Resource Consuming Queries view, since, uh… those are usually good things to tune.
top resource consuming plans
But the crappy bar graph that Query Store defaults to is not what you want to see. There’s way too much jumping around and mousing over things to figure out what’s in front of you.
I like switching to the grid format with additional details view, by clicking the blue button like so:
additional details!
But we’re not done yet! Not by a long shot. The next thing we wanna do is hit the Configure button, and change what we’re looking at. See, the other crappy thing is that Query Store defaults to showing you queries by total duration.
What ends up being in here is a bunch of stuff that runs a lot, but tends to run quickly. You might get lucky and find some quick wins here, but it’s usually not where the real bangers live.
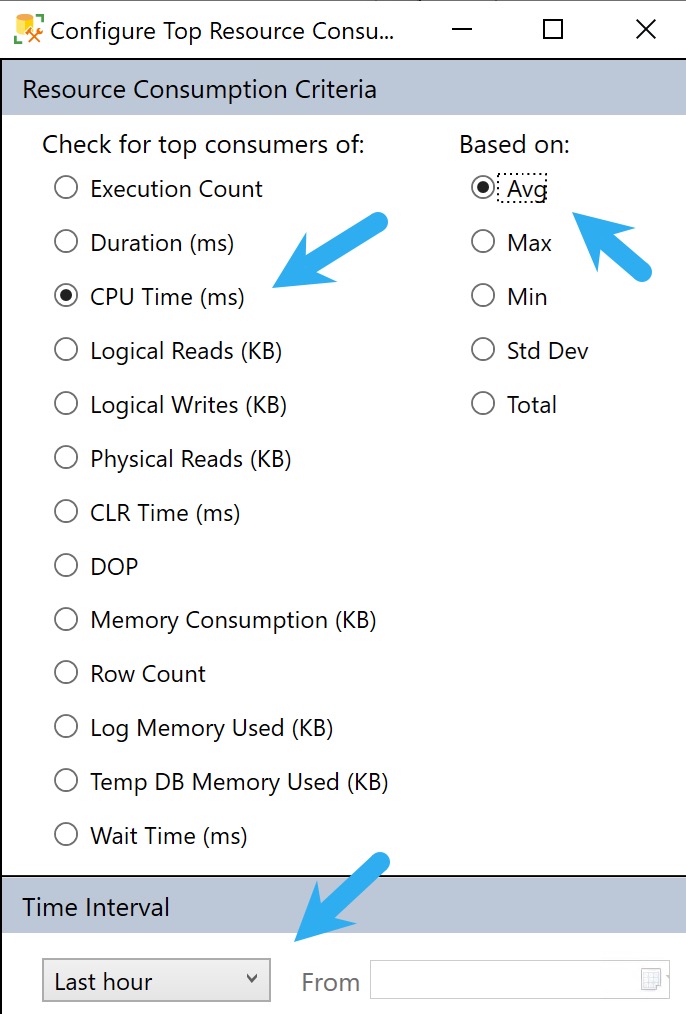
To get to those, we need to hit the Configure button and make a couple tweaks to look at queries that use a lot of CPU on average, and push the time back from only showing the last hour to the last week or so.
You can go back further, but usually the further you go back, the longer it takes to get you results.
configurator
The problem here is that you can often get back quite a bit of noise that you can’t filter out or ignore. Here’s what mine looks like:
noise noise noise
We don’t really need to know that creating indexes took a long time. Substitute those with queries you don’t necessarily care about fixing, and you get the point.
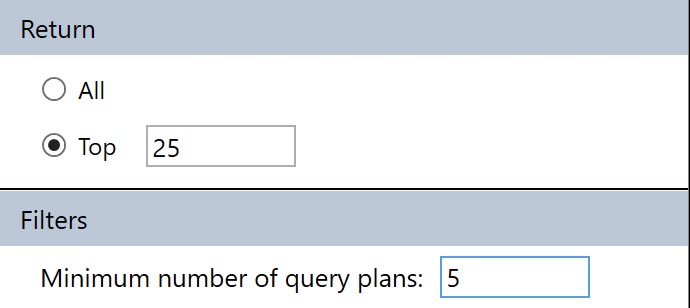
You can sort of control this by only asking for queries with a certain number of plans to come back, but if your queries aren’t parameterized and you have a lot of “single use” execution plans, you’ll miss out on those in the results.
min-maxing
This filter is available under the Configuration settings where we changes the CPU/Average/Dates before.
The major limitation of Query Store’s GUI is that you can’t search through it for specific problems. It totally could and should be in there, but as of this writing, it’s not in there.
The nice thing about sp_QuickieStore is that it gets rid of a lot of the click-clacking around to get things set up. You can’t save your Query Store GUI layout to open up and show you what you want every time, you have to redo it.
To get us to where we were with the settings above, all we have to do is this:
EXEC sp_QuickieStore
@execution_count = 5;
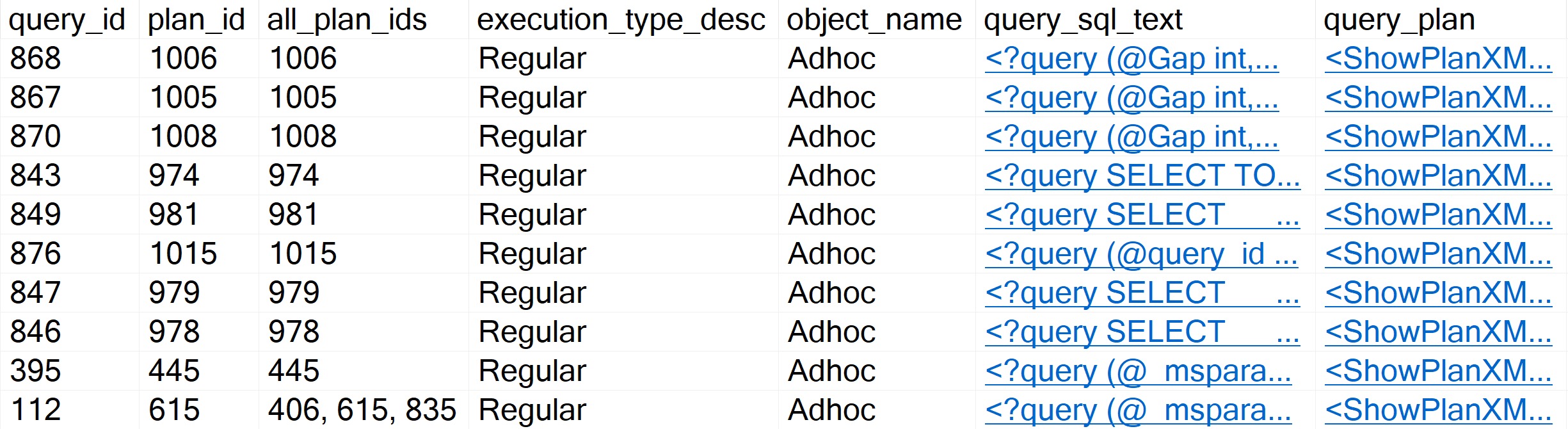
By default, sp_QuickieStore will already sort results by average CPU for queries executed over the last week of Query Store data. It will also filter out plans for stuff we can’t really tune, like creating indexes, updating statistics, and waste of time index maintenance.
You’ll get results that look somewhat like so:
to the rescue!
There are a number of things you can do with to include or ignore only certain information, too:
@execution_count: the minimum number of executions a query must have
@duration_ms: the minimum duration a query must have
@execution_type_desc: the type of execution you want to filter
@procedure_schema: the schema of the procedure you’re searching for
@procedure_name: the name of the programmable object you’re searching for
@include_plan_ids: a list of plan ids to search for
@include_query_ids: a list of query ids to search for
@ignore_plan_ids: a list of plan ids to ignore
@ignore_query_ids: a list of query ids to ignore
@include_query_hashes: a list of query hashes to search for
@include_plan_hashes: a list of query plan hashes to search for
@include_sql_handles: a list of sql handles to search for
@ignore_query_hashes: a list of query hashes to ignore
@ignore_plan_hashes: a list of query plan hashes to ignore
@ignore_sql_handles: a list of sql handles to ignore
@query_text_search: query text to search for
You straight up can’t do any of that with Query Store’s GUI. I love being able to focus in on all the plans for a specific stored procedure.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
When I first read the question, and wrote the answer, I thought for sure that the OP was just misreading things, but no… the documentation was indeed misleading.
And then I had to read more of the documentation, and then I had to write demos to show what I’m talking about.
If you’re on the docs team and you’re reading this, don’t get mad because it’s in a blog post instead of a pull request. I made one of those, too.
Y’all have a lot of work to do, and putting all of this into a pull request or issue would have been dismal for me.
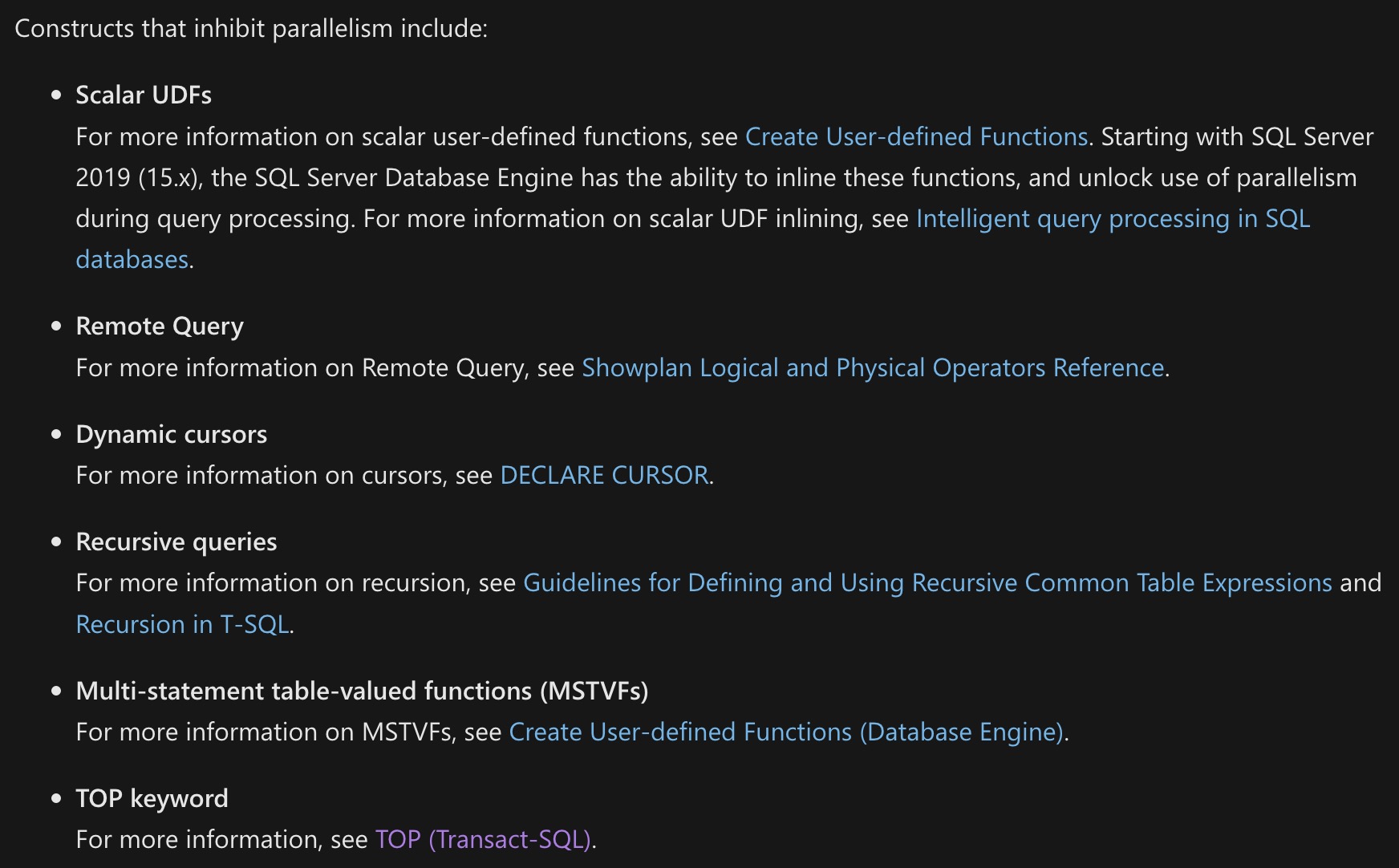
The section with the weirdest errors and omissions is right up at the top. I’m going to post a screenshot of it, because I don’t want the text to appear here in a searchable format.
That might lead people not reading thoroughly to think that I condone any of it, when I don’t.
0 for 6
Let’s walk through these one by one.
Scalar UDFs
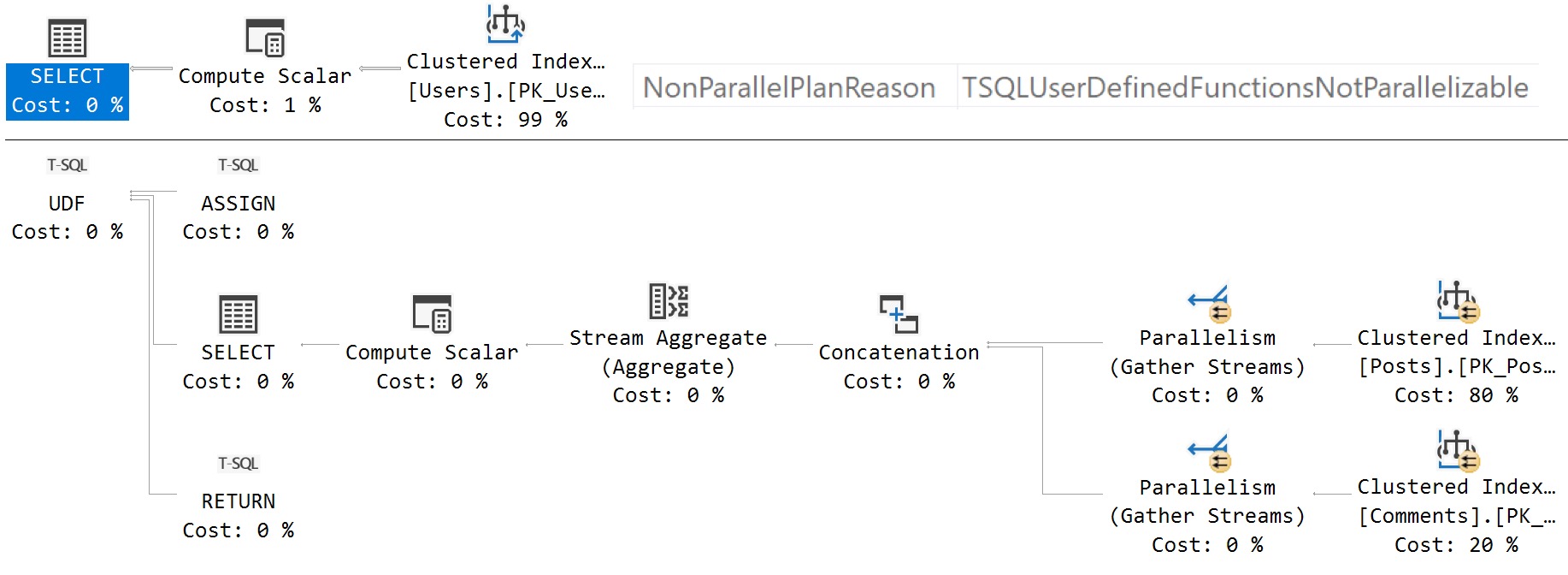
While it’s true that scalar UDFs that can’t be inlined will force the query that calls them to run single-threaded, the work done inside of the scalar UDF is still eligible for parallelism.
This is important, because anyone looking at query wait stats while troubleshooting might see CX* waits for an execution plan that is forced to run single threaded by a UDF.
Here’s a function written with a Common Table Expression, which prevents UDF inlining from taking place.
CREATE OR ALTER FUNCTION
dbo.AnteUp
(
@UserId int
)
RETURNS integer
WITH SCHEMABINDING
AS
BEGIN
DECLARE
@AnteUp bigint = 0;
WITH
x AS
(
SELECT
p.Score
FROM dbo.Posts AS p
WHERE p.OwnerUserId = @UserId
UNION ALL
SELECT
c.Score
FROM dbo.Comments AS c
WHERE c.UserId = @UserId
)
SELECT
@AnteUp =
SUM(CONVERT(bigint, x.Score))
FROM x AS x;
RETURN @AnteUp;
END;
Getting the estimated execution plan for this query will show us a parallel zone within the function body.
SELECT
u.DisplayName,
TotalScore =
dbo.AnteUp(u.AccountId)
FROM dbo.Users AS u
WHERE u.Reputation >= 500000;
If you get an actual execution plan, you can’t see the work done by the scalar UDF. This is sensible, since the function can’t be inlined, and the UDF would run once per row, which would also return a separate query plan per row.
For functions that suffer many invocations, SSMS may crash.
query and function
The calling query runs single threaded with a non-parallel execution plan reason, but the body of the function scans both tables that it touches in a parallel zone.
The documentation is quite imprecise in this instance, and many of the others in similar ways.
Remote Queries
This one is a little tough to prove, and I’ll talk about why, but the parallelism restriction is only on the local side of the query. The portion of the query that executes remotely can use a parallel execution plan.
The reasons why this is hard to prove is that getting the execution plan for the remote side of the query doesn’t seem to be an easy thing to accomplish.
I couldn’t find a cached execution plan for my attempts, nor could I catch the query during execution with a query plan attached to it using the usual methods.
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
GO
SELECT
dows.wait_type,
dows.waiting_tasks_count,
dows.wait_time_ms,
dows.max_wait_time_ms,
dows.signal_wait_time_ms
FROM sys.dm_os_wait_stats AS dows
WHERE dows.wait_type LIKE N'CX%'
ORDER BY dows.wait_time_ms DESC;
GO
SELECT TOP (1000)
u.Id
FROM loop.StackOverflow2013.dbo.Users AS u
ORDER BY
u.Reputation
GO
SELECT
u.*
FROM
OPENQUERY
(
loop,
N'
SELECT TOP (1000)
u.Id,
u.Reputation
FROM loop.StackOverflow2013.dbo.Users AS u
ORDER BY
u.Reputation;
'
) AS u;
GO
SELECT
dows.wait_type,
dows.waiting_tasks_count,
dows.wait_time_ms,
dows.max_wait_time_ms,
dows.signal_wait_time_ms
FROM sys.dm_os_wait_stats AS dows
WHERE dows.wait_type LIKE N'CX%'
ORDER BY dows.wait_time_ms DESC;
You can quote in/out either the linked server or the OPENQUERY version, but each time a consistent amount of parallel query waits were returned by the second wait stats query.
Given that this is a local instance with no other activity, I’m pretty confident that I’m right here.
Dynamic Cursors
It is true that dynamic cursors will prevent a parallel execution plan, but the documentation leaves out that fast forward cursors will also do that.
That does get noted in the table of non-parallel execution plan reasons decoder ring a little further down, but it’s odd here because only one type of cursor is mentioned, and the cursor documentation itself doesn’t say anything about which cursors inhibit parallelism.
Bit odd since there’s a note that tells you that you can learn more by going there.
DECLARE
ff CURSOR FAST_FORWARD
FOR
SELECT TOP (1)
u.Id
FROM dbo.Users AS u
ORDER BY u.Reputation DESC
OPEN ff;
FETCH NEXT
FROM ff;
CLOSE ff;
DEALLOCATE ff;
Anyway, this cursor gives us this execution plan:
out of luck
Which has a non parallel execution plan reason that is wonderfully descriptive.
Recursive Queries
This is only partially true. The “recursive” part of the CTE cannot use a parallel execution plan (blame the Stack Spool or something), but work done outside of the recursive common table expression can.
Consider this query, with a recursive CTE, and then an additional join outside of the portion that achieved maximum recursion.
WITH
p AS
(
SELECT
p.Id,
p.ParentId,
p.OwnerUserId,
p.Score
FROM dbo.Posts AS p
WHERE p.Id = 184618
UNION ALL
SELECT
p2.Id,
p2.ParentId,
p2.OwnerUserId,
p2.Score
FROM p
JOIN dbo.Posts AS p2
ON p.Id = p2.ParentId
)
SELECT
p.*,
u.DisplayName,
u.Reputation
FROM p
JOIN dbo.Users AS u
ON u.Id = p.OwnerUserId
ORDER BY p.Id;
In this execution plan, the join to the Users table is done in a parallel zone after the recursive common table expression “completes”:
that’s a thing.
These do not force a totally serial execution plan, as the documentation suggests.
Multi-Statement Table Valued Functions
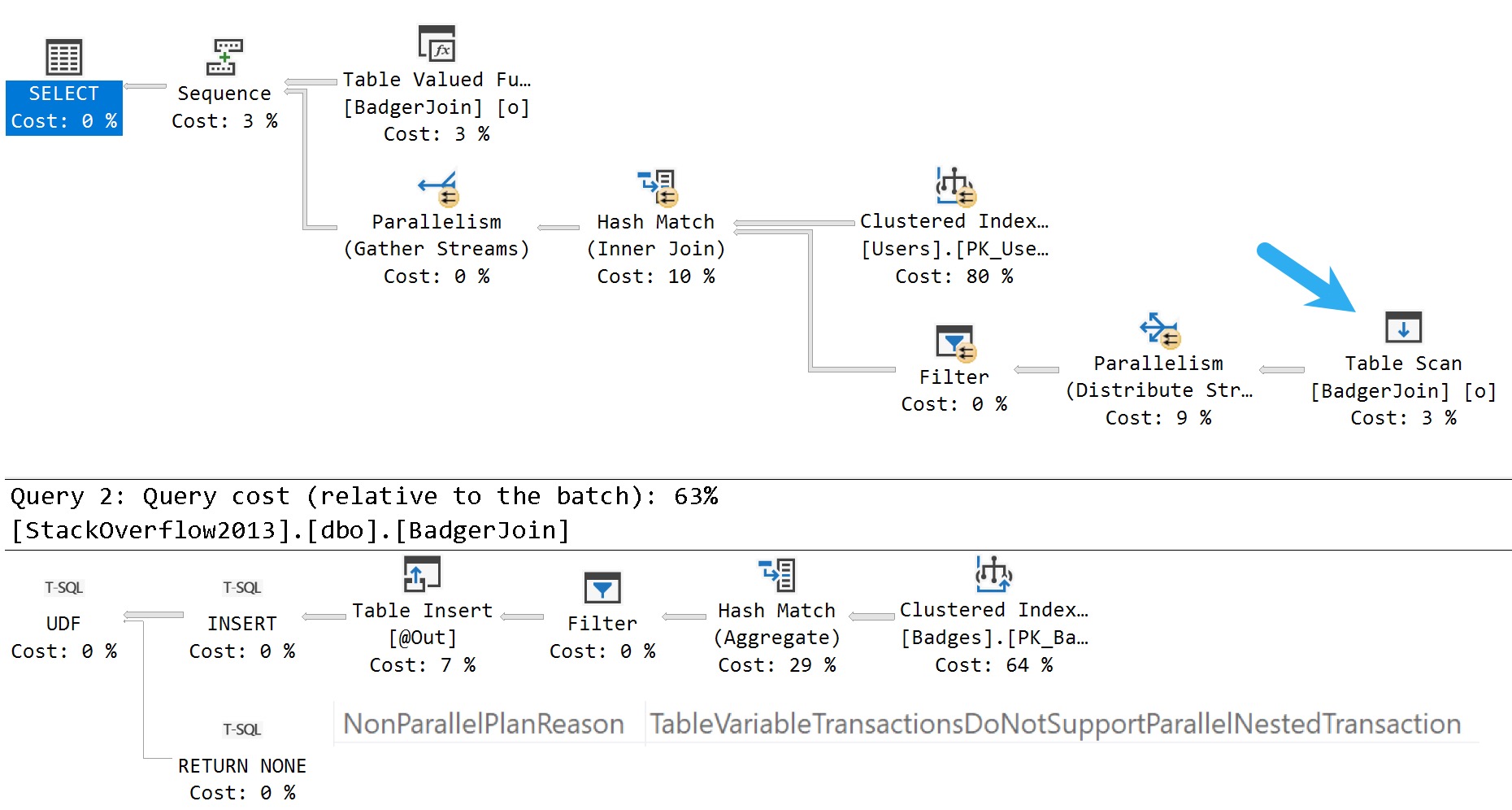
This is another area where the documentation seems to indicate that a completely serial execution plan is forced by invoking a multi-statement table valued function, but they don’t do that either.
They only force a serial zone in the execution plan, both where the table variable is populated, and later returned by the functions. Table variables read from outside of multi-statement table valued functions, and even table variables used elsewhere in the function’s body may be read from in a parallel zone, but the returned table variable does not support that.
Here’s a function:
CREATE OR ALTER FUNCTION
dbo.BadgerJoin
(
@h bigint
)
RETURNS
@Out table
(
UserId int,
BadgeCount bigint
)
AS
BEGIN
INSERT INTO
@Out
(
UserId,
BadgeCount
)
SELECT
b.UserId,
BadgeCount =
COUNT_BIG(*)
FROM dbo.Badges AS b
GROUP BY b.UserId
HAVING COUNT_BIG(*) > @h;
RETURN;
END;
Here’s a query that calls it:
SELECT
u.Id,
o.*
FROM dbo.Users AS u
JOIN dbo.BadgerJoin(0) AS o
ON o.UserId = u.Id
WHERE u.LastAccessDate >= '20180901';
And here’s the query execution plan:
hard knocks life
Again, only a serial zone in the execution plan. The table variable modification does force a serial execution plan, but that is more of a side note and somewhat unrelated to the documentation.
Completion is important.
Top
Finally, the TOP operator is documented as causing a serial execution plan, but it’s only the TOP operator that doesn’t support parallelism.
Consider this query:
SELECT
*
FROM
(
SELECT TOP (1)
u.*
FROM dbo.Users AS u
ORDER BY
u.Reputation DESC,
u.Id
) AS u
INNER JOIN
(
SELECT TOP (1)
u.*
FROM dbo.Users AS u
ORDER BY
u.Reputation DESC,
u.Id
) AS u2
ON u.Id = u2.Id
ORDER BY
u.Reputation,
u2.Reputation;
Both of the derived selects happen fully in parallel zones, but there is a gather streams operator prior to each top operator, to end each parallel zone.
DOUBLE TOP!
It would be a little silly to re-parallelize things after the tops going into the nested loops join, but you probably get the point.
You may see some query execution plans where there is a parallel zone, a gather streams operator, a top operator, and then a distribute streams operator to reinitialize parallelism out in the wild.
This is almost no different than global aggregates which also cause serial zones in query plans. Take this query for example:
SELECT
s = SUM(x.r)
FROM
(
SELECT
r = COUNT(*)
FROM dbo.Users AS u
WHERE u.Age < 18
UNION ALL
SELECT
r = COUNT(*)
FROM dbo.Users AS u
WHERE u.Age IS NULL
) AS x;
Which gives us this query plan, where each count operation (stream aggregate) occurs in a serial zone immediately after gather streams.
vlad
But no one’s getting all riled up and shouting that from the docs pages.
Afterthoughts
There are some other areas where the documentation is off, and it’s a shame that Microsoft didn’t choose to link to the series of index build strategy posts that it has had published locally since ~2006 or so.
But hey. It’s not like the internet is forever, especially when it comes to Microsoft content.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
The really annoying thing about foreign keys is that you can’t do anything to affect the query plans SQL Server uses to enforce them.
My good AND dear friend Forrest ran into an issue with them that I’ve seen played out at dozens of client sites. Sometimes there are actually foreign keys that don’t have indexes to help them, but even when there are, SQL Server’s optimizer doesn’t always listen to reason, or other cardinality estimation issues are at play. Some can be fixed, and some can’t.
When they can’t, sometimes implementing triggers which are more under your control can be used in place of foreign keys.
The following code isn’t totally suitable for production, but is good enough to illustrate examples.
If you need production-ready code, hit the link at the end of the post to schedule a sales call.
Setup
I’m going to use some slightly modified code from Forrest’s post linked above, since that’s what I started with to see if the foreign key issue still presents in SQL Server 2022 under compatibility level 160.
It does! So. Progress, right? Wrong.
CREATE TABLE
dbo.p
(
id int
PRIMARY KEY,
a char(1),
d datetime DEFAULT SYSDATETIME()
);
CREATE TABLE
dbo.c
(
id int
IDENTITY
PRIMARY KEY,
a varchar(5),
d datetime DEFAULT SYSDATETIME(),
pid int,
INDEX nc NONCLUSTERED(pid)
);
INSERT
dbo.p WITH(TABLOCKX)
(
id,
a
)
SELECT TOP (1000000)
ROW_NUMBER() OVER
(
ORDER BY
(SELECT 1/0)
),
CHAR(m.severity + 50)
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2;
INSERT
dbo.c WITH(TABLOCKX)
(
a,
pid
)
SELECT TOP (1100000)
REPLICATE
(
CHAR(m.severity + 50),
5
),
ROW_NUMBER() OVER
(
ORDER BY
(SELECT 1/0)
) % 1000000 + 1
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2;
For Fun
With the boring stuff out of the way, let’s skip to how to set up triggers to replace foreign keys.
For reference, this is the foreign key definition that we want to replicate:
ALTER TABLE
dbo.c
ADD CONSTRAINT
fk_d_up
FOREIGN KEY
(pid)
REFERENCES
dbo.p (id)
ON DELETE CASCADE
ON UPDATE CASCADE;
While it’s a bit contrived to have an update cascade from what would be an identity value for most folks, we’re gonna run with it here for completeness.
Here at Darling Data we care about completion.
Inserts
I’m a big fan of instead of insert triggers for this, because they take a shortcut around all the potential performance ramifications of letting a thing happen and checking it afterwards.
Now, you’re going to notice that this trigger silently discards rows that would have violated the foreign key. And you’re totally right! But it’s up to you to decide how you want to handle that.
Ignore them completely
Log them to a table
Correct mismatches via lookup tables
Anyway, here’s the basic trigger I’d use, with hints included to illustrate the points from above about you getting control of plan choices.
CREATE OR ALTER TRIGGER
dbo.instead_insert
ON
dbo.c
INSTEAD OF INSERT
AS
BEGIN
IF @@ROWCOUNT = 0
BEGIN
RETURN;
END;
SET NOCOUNT ON;
INSERT
dbo.c
(
a,
pid
)
SELECT
i.a,
i.pid
FROM Inserted AS i
WHERE EXISTS
(
SELECT
1/0
FROM dbo.p AS p WITH(FORCESEEK)
WHERE p.id = i.id
)
OPTION(LOOP JOIN);
END;
Updates
To manage updates, here’s the trigger I’d use:
CREATE OR ALTER TRIGGER
dbo.after_update
ON
dbo.p
AFTER UPDATE
AS
BEGIN
IF @@ROWCOUNT = 0
BEGIN
RETURN;
END;
SET NOCOUNT ON;
UPDATE c
SET
c.pid = i.id
FROM dbo.c AS c WITH(FORCESEEK)
JOIN Inserted AS i
ON i.id = c.id
OPTION(LOOP JOIN);
END;
Deletes
To manage deletes, here’s the trigger I’d use:
CREATE OR ALTER TRIGGER
dbo.after_delete
ON
dbo.p
AFTER DELETE
AS
BEGIN
IF @@ROWCOUNT = 0
BEGIN
RETURN;
END;
SET NOCOUNT ON;
DELETE c
FROM dbo.c AS c WITH(FORCESEEK)
JOIN Inserted AS i
ON i.id = c.id
OPTION(LOOP JOIN);
END;
Common Notes
All of these triggers have some things in common:
They start by checking to see if any rows actually changed before moving on
The SET NOCOUNT ON happens after this, because it will interfere with @@ROWCOUNT
You may need to use the serializable isolation level to fully protect things, which cascading foreign keys use implicitly
We don’t need to SET XACT ABORT ON because it’s implicitly used by triggers anyway
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
It’s somewhat strange to hear people carry on about best practices that are actually worst practices.
One worst practice that has strong staying power is the OPTIMIZE FOR UNKNOWN hint, which we talked about yesterday.
It probably doesn’t help that Microsoft has products (I’m looking at you, Dynamics) which have a setting to add the hint to every query. Shorter: If Microsoft recommends it, it must be good.
Thanks, Microsoft. Dummies.
Using the OPTIMIZE FOR UNKNOWN hint, or declaring variables inside of a code block to be used in a where clause have the same issue, though: they make SQL Server’s query optimizer make bad guesses, which often lead to bad execution plans.
We’re going to create two indexes on the Posts table:
CREATE INDEX
p0
ON dbo.Posts
(
OwnerUserId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
GO
CREATE INDEX
p1
ON dbo.Posts
(
ParentId,
CreationDate,
LastActivityDate
)
INCLUDE
(
PostTypeId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
GO
The indexes themselves are not as important as how SQL Server goes about choosing them.
Support Wear
This stored procedure is going to call the same query in three different ways:
One with the OPTIMIZE FOR UNKNOWN hint that uses parameters
One with local variables set to parameter values with no hints
One that accepts parameters and uses no hints
CREATE OR ALTER PROCEDURE
dbo.unknown_soldier
(
@ParentId int,
@OwnerUserId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC
OPTION(OPTIMIZE FOR UNKNOWN);
DECLARE
@ParentIdInner int = @ParentId,
@OwnerUserIdInner int = @OwnerUserId;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentIdInner
AND p.OwnerUserId = @OwnerUserIdInner
ORDER BY
p.Score DESC,
p.Id DESC;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC;
END;
GO
Placebo Effect
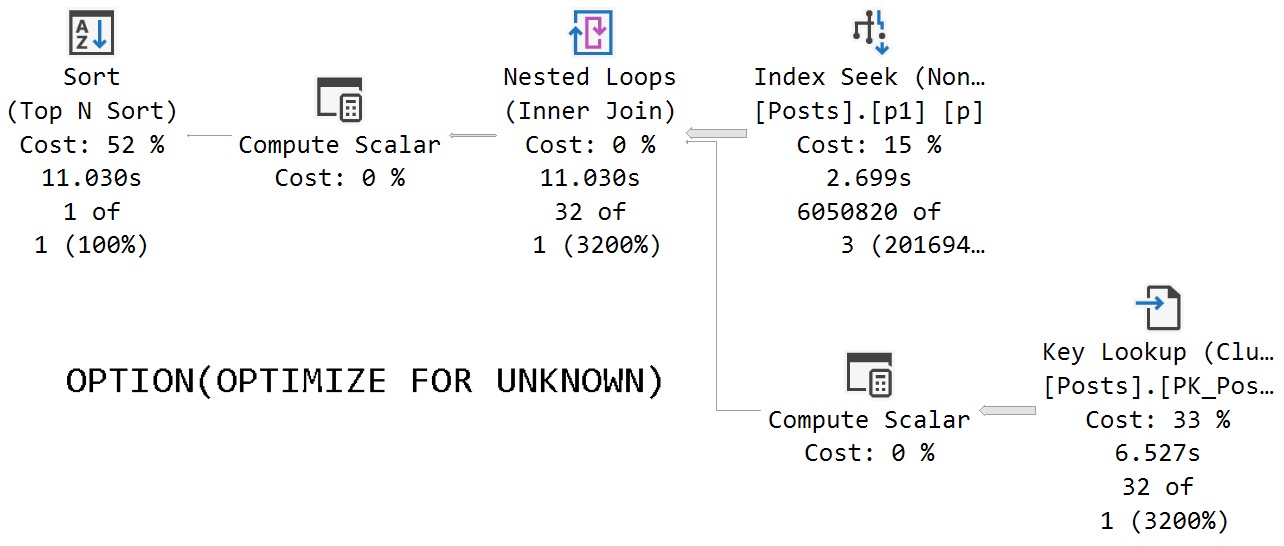
If we call the stored procedure with actual execution plans enabled, we get the following plans back.
The assumed selectivity that the OPTIMIZE FOR UNKNOWN hint produces as a cardinality estimate is way off the rails.
SQL Server thinks three rows are going to come back, but we get 6,050,820 rows back.
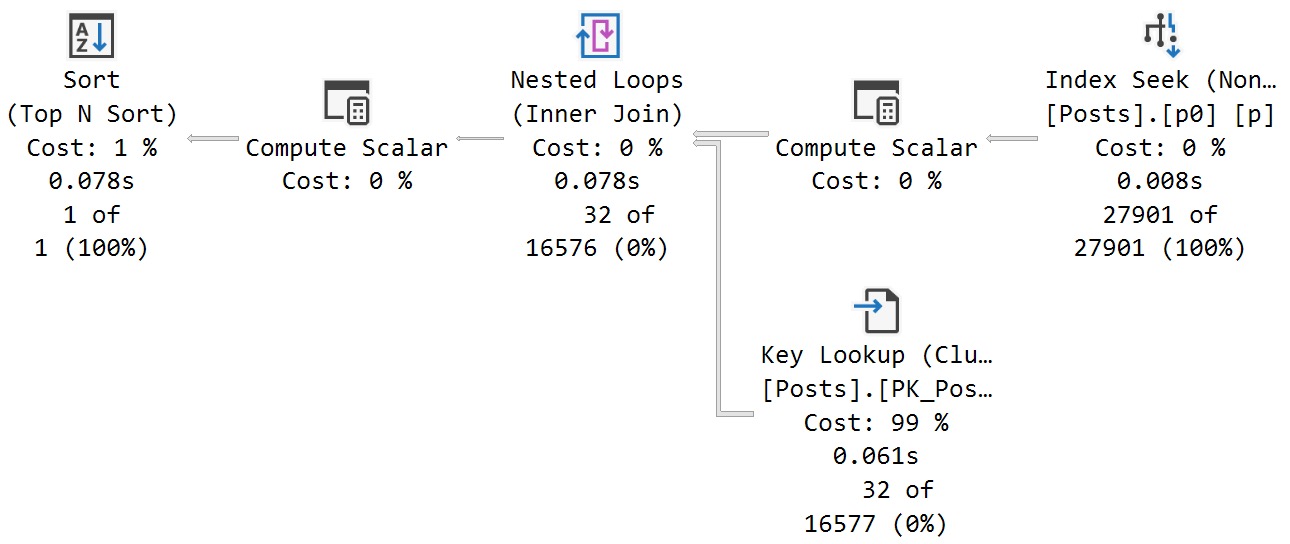
We get identical behavior from the second query that uses variables declared within the stored procedure, and set to the parameter values passed in.
release me
Same poor guesses, same index choices, same long running plan.
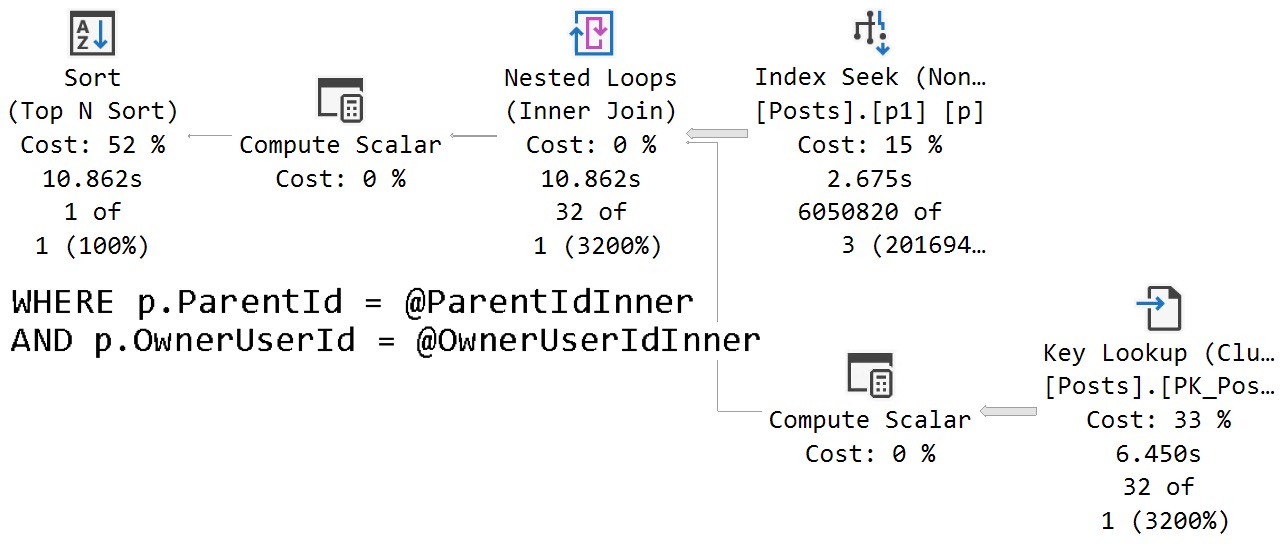
Parameter Effect
The query that accepts parameters and doesn’t have any hints applied to it fares much better.
transporter
In this case, we get an accurate cardinality estimate, and a more suitable index choice.
Note that both queries perform lookups, but this one performs far fewer of them because it uses an index that filters way more rows out prior to doing the lookup.
The optimizer is able to choose the correct index because it’s able to evaluate predicate values against the statistics histograms rather than using the assumed selectivity guess.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
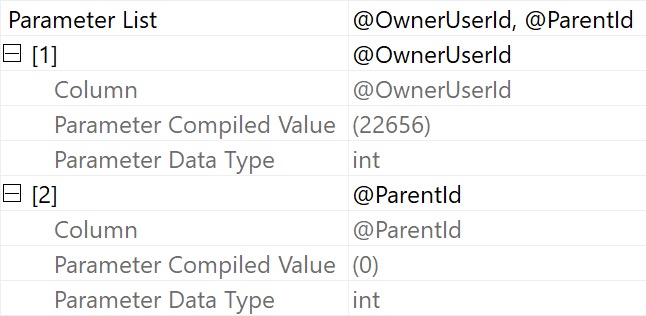
For a long while now, when parameterized queries get executed in SQL Server, whether they’re in stored procedures or from ORMs, execution plans stored in the plan cache or in query store will keep information about what the compile-time parameter values are.
You can see this list in the details of the query plan by going to the properties of whatever the root node is.
compile time, baby!
This is useful for when you want to execute the code to reproduce and address any performance issues.
You know, very professional stuff.
If you use local variables, apply the OPTIMIZE FOR UNKNOWN hint, or disable parameter sniffing using a database scoped configuration, cached and query store-d plans no longer have those parameters lists in them. Likewise, if you have queries where a mix of parameters and local variables are used, the local variable compile time values will be missing from the plan XML.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I see this mistake quite a bit! Golly do I. And then I cry and drink and drink and cry and why do you people insist on ruining my makeup?
Most of the time, it’s some query that looks like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId LIKE '2265%'
The cruddy thing here is that… SQL Server doesn’t handle this well.
tanked
Even with this index on OwnerUserId, bad things happen in the form of a full scan instead of a seek, because of the implicit conversion function.
CREATE INDEX
p0
ON dbo.Posts
(
OwnerUserId
);
Because the OwnerUserId column has to be converted to varchar(12) to accommodate the wildcard search, we’re unable to directly seek to data we care about.
Many Other Wrongs
As if LIKE weren’t bad enough, I often see other patterns that attempt to mimic the behavior with more typing involved:
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE LEFT(p.OwnerUserId, 4) = '2265';
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE SUBSTRING
(
CONVERT(varchar(12),
p.OwnerUserId),
0,
5
) = '2265';
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE PATINDEX
(
'2265%',
CONVERT(varchar(12), p.OwnerUserId)
) > 0;
And even this, which doesn’t even work correctly because it’s more like saying ‘%2265%’.
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE CHARINDEX('2265', p.OwnerUserId) > 0;
These will have all the same problems as the original LIKE search pattern shown above, where we get a scan instead of a seek and a conversion of the OwnerUserId column from an integer to a varchar(12).
Is there a way to fix this? You betcha.
Computered
Adding a computed column does the job for us:
ALTER TABLE
dbo.Posts
ADD OwnerUserId_varchar
AS CONVERT(varchar(12), OwnerUserId);
CREATE INDEX
pv
ON dbo.Posts
(
OwnerUserId_varchar
);
And without changing the original LIKE query, the optimizer will match it with our indexed computed column.
inflammatory
Note that none of the other attempts at rewrites using left, substring, or patindex will automatically match with new indexed computed column.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.