Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
What SQL Server’s Query Optimizer Doesn’t Know About Numbers
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
When I sit down to write any blog post as a series, I do these things first:
List out topics – it’s cool if it’s stuff I’ve covered before, but I want to do it differently
Look at old posts – I don’t want to fully repeat myself, but I write these things down so I don’t forget them
Write demos – some are easier than others, so I’ll jump around the list a little bit
Having said all that, I also give myself some grace in the matter. Sometimes I’ll want to talk about something else that breaks up the flow of the series. Sometimes I’ll want to record a video to keep the editors at Beergut Magazine happy.
And then, like with this post, I change my mind about the original topic. This one was going to be “Fixing Predicate Selectivity”, but the more I looked at it, the more the demo was going to look like the one in my post in this series about SARGability.
That felt kind of lame, like a copout. And while there are plenty of good reasons for copouts when you’re writing stuff for free, even I felt bad about that one. I almost ended the series early, but a lot of the work I’ve been doing has been on particularly complicated messes.
So now we’re going to talk about one of my favorite things I help clients with: big, unpredictable search queries.
First, What You’re (Probably) Not Going To Do
There’s one thing that you should absolutely not do, and one thing that I’ll sometimes be okay with for these kinds of queries.
First, what you should not do: A universal search string:
WHERE (p.OwnerUserId LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.Title LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.CreationDate LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.LastActivityDate LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL)
OR (p.Body LIKE N'%' + @SearchString + N'%' OR @SearchString IS NULL);
The problem here is somewhat obvious if you’ve been hanging around SQL Server long enough. Double wildcard searches, searching with a string type against numbers and dates, strung-together OR predicates that the optimizer will hate you for.
These aren’t problems that other things will solve either. For example, using CHARINDEX or PATINDEX isn’t a better pattern for double wildcard LIKE searching, and different takes on how you handle parameters being NULL don’t buy you much.
So like, ISNULL(@Parameter, Column) will still suck in most cases.
Your other option is something like this, which is only not-sucky with a statement-level OPTION(RECOMPILE) hint at the end of your query.
WHERE (p.OwnerUserId = @OwnerUserId OR @OwnerUserId IS NULL)
AND (p.CreationDate >= @CreationDate OR @CreationDate IS NULL)
AND (p.LastActivityDate < @LastActivityDate OR @LastActivityDate IS NULL)
AND (p.Score >= @Score OR @Score IS NULL)
AND (p.Body LIKE N'%' + @Body + N'%' OR @Body IS NULL)
This departs from the universal search string method, and replaces the one string-typed parameter with parameters specific to each column’s data type.
Sure, it doesn’t allow developers to be lazy sons of so-and-so’s in the front end, but you don’t pay $7000 per core for them, and you won’t need to keep adding expensive cores if they spend a couple hours doing things in a manner that resembles a sane protocol.
The recompile advice is good enough, but when you use it, you really need to pay attention to compile times for your queries. It may not be a good idea past a certain threshold of complexity to come up with a “new” execution plan every single time, minding that that “new” plan might be the same plan over and over again.
Second, What You’re Eventually Going To End Up With
SQL Server doesn’t offer any great programmability or optimizer support for the types of queries we’re talking about. It’s easy to fall into the convenience-hole of one of the above methods.
Writing good queries means extra typing and thinking, and who has time for all that? Not you. You’re busy thinking you need to use some in-memory partitioning, or build your own ORM from scratch, no, migrate to a different relational database, that will surely solve all your problems, no, better, migrate to a NoSQL solution, that’ll do it, just give you 18-24 months to build a working proof of concept, learn seven new systems, and hire some consultants to help you with the migration, yeah, that’s the ticket.
You can’t just spend an hour typing a little extra. Someone on HackerNews says developers who type are the most likely to be replaced by AI.
Might as well buy a pick and a stick to DIY a grave for your career. It’ll be the last useful thing you do.
Rather than put 300 lines of code and comments in a blog post, I’m storing it in a GitHub gist here.
What I am going to post in here is the current list of variables, and what each does:
@Top: How many rows you want to see (optional, but has a default value)
@DisplayName: Search for a user’s display name (optional, can be equality or wildcard)
@Reputation: Search for users over a specific reputation (optional, greater than or equal to)
@OwnerUserId: Search for a specific user id (optional, equality)
@CreationDate: Search for posts created on or after a date (optional, greater than or equal to)
@LastActivityDate: Search for posts created before a date (optional, less than)
@PostTypeId: Search for posts by question, answer, etc. (optional, equality)
@Score: Search for posts over a particular score (optional, greater than or equal to)
@Title: Search for posts with key words in the title (optional, can be equality or wildcard)
@Body: Search for posts with key words in the body (optional, can be equality or wildcard)
@HasBadges: If set to true, get a count of badges for any users returned in the results (optional, true/false)
@HasComments: If set to true, get a count of comments for any users returned in the results (optional, true/false)
@HasVotes: If set to true, get a count of votes for any posts returned in the results (optional, true/false)
@OrderBy: Which column you want the results ordered by (optional, but has a default value)
@OrderDir: Which direction you want the results sorted in, ascending or descending (optional, but has a default value)
To round things up:
There are 9 parameters in there which will drive optional searches
Seven of the nine optional searches are on the Posts table, two are on the Users table
There are 3 parameters that drive how many rows we want, and how we want them sorted
There are 3 parameters that optionally hit other tables for additional information
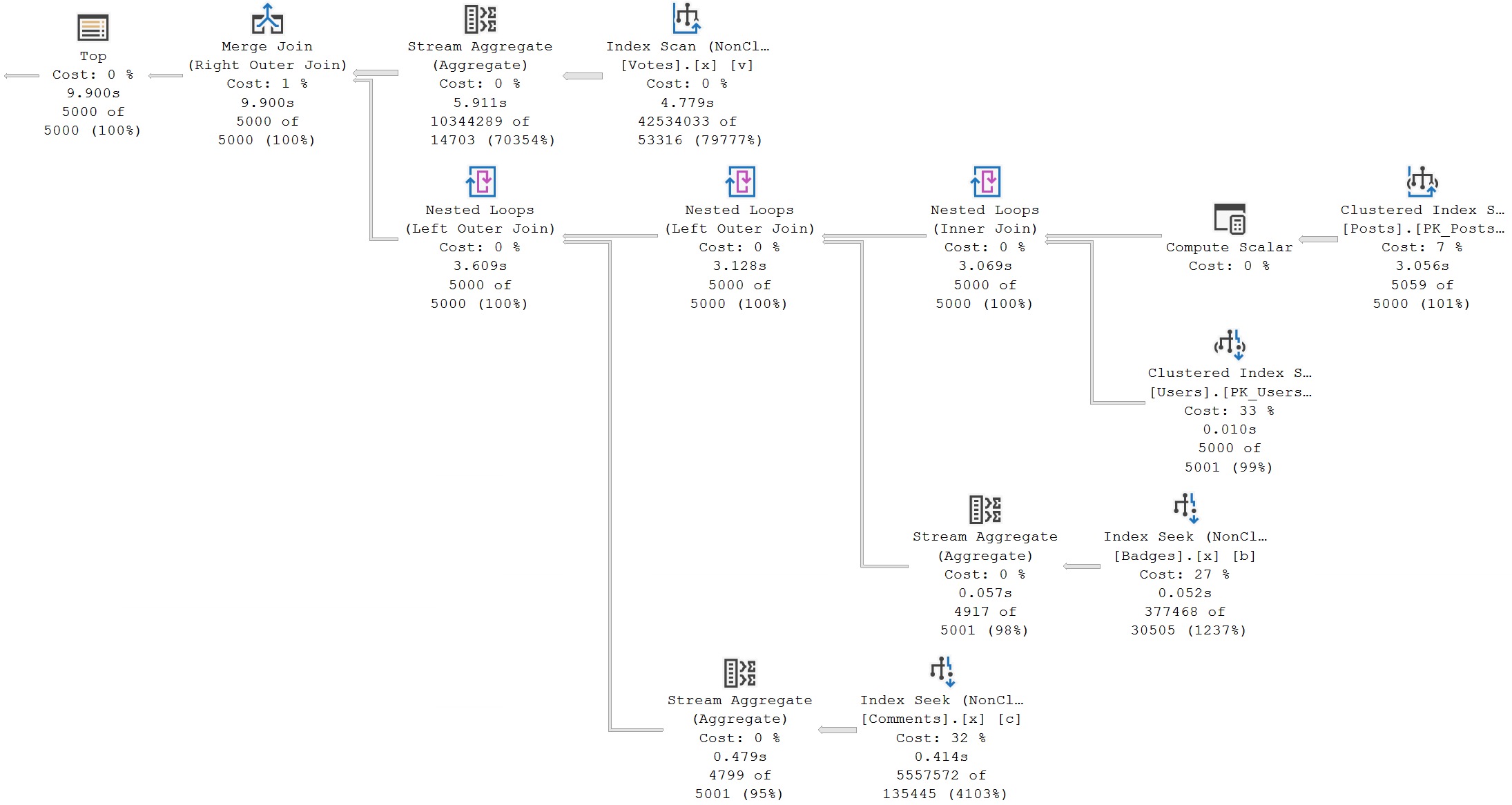
Indexing for the Users side of this is relatively easy, as it’s only two columns. Likewise, indexing for the “Has” parameters is easy, since we just need to correlate to one additional column in Badges, Comments, or Votes.
But that Posts table.
That Posts table.
Index Keys Open Doors
The struggle you’ll often run into with these kinds of queries is that there’s a “typically expected” thing someone will always search for.
In your case, it may be a customer id, or an order id, or a company id… You get the point. Someone will nearly always need some piece of information for normal search operations.
Where things go off the rails is when someone doesn’t do that. For the stored procedure linked above, the role of the “typically expected” parameter will be OwnerUserId.
The data in that column doesn’t have a very spiky distribution. At the high end, you have about 28k rows, and at the low end, well, 1 row. As long as you can seek in that column, evaluating additional predicates isn’t so tough.
In that case, an index like this would get you going a long way:
CREATE INDEX
p
ON dbo.Posts
(OwnerUserId, Score DESC, CreationDate, LastActivityDate)
INCLUDE
(PostTypeId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
GO
Since our stored procedure “typically expects” users to supply OwnerUserId, has a default sorting of Score, optional Creation and LastActivity Dates can act as residual predicates without a performance tantrum being thrown.
And since PostTypeId is one of the least selective columns in the whole database, it can go live in the basement as an included column.
Using dynamic SQL, we don’t have to worry about SQL Server trying to re-use a query execution plan for when OwnerUserId is passed in. We would have to worry about that using some other implementations.
Here, the problem is that some searches will be slow without supporting indexes, and not every slow query generates a missing index request.
/*NOPE THIS IS FINE NO INDEX COULD HELP*/
EXEC dbo.ReasonableRates
@CreationDate = '20130101',
@LastActivityDate = '20140101',
@HasBadges = 1,
@HasComments = 1,
@HasVotes = 1,
@Debug = 1;
GO
As an example, this takes ~10 seconds, results in a perfectly acceptable where clause for an index to help with, but no direct request is made for an index.
Of course, there’s an indirect request in the form of a scan of the Posts table.
dirty looks
So, back to the struggle, here:
How do you know how often this iteration of the dynamic SQL runs?
Is it important? Did someone important run it?
Is it important enough to add an index to help?
And then… how many other iterations of the dynamic SQL need indexes to help them, along with all the other questions above.
You may quickly find yourself thinking you need to add dozens of indexes to support various search and order schemes.
Data Access Patterns
This is the big failing of Row Store indexes for handling these types of queries.
CREATE INDEX
codependent
ON dbo.Posts
(
OwnerUserId,
/*^Depends On^*/
Score,
/*^Depends On^*/
CreationDate,
/*^Depends On^*/
LastActivityDate,
/*^Depends On^*/
PostTypeId,
/*^Depends On^*/
Id
)
INCLUDE
(Title)
/*^Doesn't depend on anything. It's an Include.^*/
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
In general, if you’re not accessing index key columns starting with the leading-most key column, your queries won’t be as fast (or may not choose to use your index, like in the plan up there), because they’d have to scan the whole thing.
For queries like this, nonclustered column store indexes are a way hotter ticket. Columns can be accessed independently. They may get abused by modification queries, and they may actually need maintenance to keep them compressed and tombstone-free, but quite often these tradeoffs are worth it for improving search queries across the board. Even for Standard Edition users, whom Microsoft goes out of their way to show great disdain for, it can be a better strategy.
Here’s an example:
CREATE NONCLUSTERED COLUMNSTORE INDEX
nodependent
ON dbo.Posts
(OwnerUserId, Score, CreationDate, LastActivityDate, PostTypeId, Id, Title)
WITH(MAXDOP = 1);
With this index in place, we can help lots of search queries all in one shot, rather than having to create a swath of sometimes-helpful, sometimes-not indexes.
Even better, we get a less wooly guarantee that the optimizer will heuristically choose Batch Mode.
Two Things
I hope you take two things away from this post:
How to write robust, readable, repeatable search queries
Nonclustered columnstore indexes can go a lot further for performance with unpredictable predicates
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If you’re the kind of person who needs quick and easy ways to troubleshoot SQL Server performance problems, and you haven’t tried my free scripts yet, you’re probably going to keep having SQL Server performance problems.
I don’t get a lot of visitor contributions to my code (and here I thought it was just because it’s perfect), but I had a couple cool recent additions to sp_QuickieStore, my free tool for searching and analyzing Query Store data.
First, Ben Thul did a great job of simplifying the process of searching for only for queries that run during configurable business hours. I had gone through a whole process of creating a lookup table with times and a bunch of other nonsense. Ben, being smart, converted that over to just using parameters with a time type, so it doesn’t matter if you use 12- or 24-hour time. Thank you, Ben.
Second, Bill Finch dropped a really interesting pull request on me that allows for searching for query text that includes square brackets. I had no idea that didn’t work, but apparently I don’t go searching for Entity Framework created query text all that often. Very cool stuff, and a thank you to Bill as well!
Third, since I keep running into databases where Query Store is in a weird state, I added an initial check to see if it’s read only, if the desired and current state disagree with each other, or if auto-cleanup is disabled. Of course, I haven’t run into that since. Lucky me.
Fourth, Cláudio Silva added a new parameter to search Query Store for only plans that have hints (2022+, probably whatever Azure nonsense). An idea so cool, I expanded on it to also allow searching for queries with feedback and variants (also 2022+, probably whatever Azure nonsense)
Numbers are now nicely formatted with commas, so it’s easy to identify the precise scale of misery you’re experiencing.
A Friend At Microsoft told me that wait durations should already be in milliseconds in the system health extended event, and that I didn’t need to divide those numbers by 1000 to convert them from microseconds. This change is somewhat experimental, because some awfully big numbers show up. If you happen to know better, or feel like testing to verify the change, give the latest version a run.
If you’re searching for warnings only, I added a parameter (@pending_task_threshold) to reduce the number of warnings lines from the cpu task details results. You’ll get a warning here even if there’s one pending task, which isn’t very useful. You usually want to find when LOTS of pending tasks were happening. The default is 10.
Finally, I added a contributing guide. It’s not very extensive (which prevents it from being exhausting); the main point I’m trying to get across is that forks and pull requests must be made from and to the dev branch only. Committing directly to main is verboten. Totes verbotes, as they say in Germany and surrounding German-speaking countries, I’ve been informed by Reliable Sources.
If you have questions, run into bugs, or think adding some code to any of my procedures, open up an issue. I don’t do support via email or blog comments.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
A lot of the time, the answer to performance issues with ranking windowing functions is simply to get Batch Mode involved. Where that’s not possible, you may have to resort to adding indexes.
Sometimes, even with Batch Mode, there is additional work to be done, but it really does get a lot of the job done.
In this post I’m going to cover some of the complexities of indexing for ranking windowing functions when there are additional considerations for indexing, like join and where clause predicates.
I also want to show you the limitations of indexing for solving performance problems for ranking windowing functions in Row Mode. This will be especially painful for developers forced to use Standard Edition, where Batch Mode is hopelessly hobbled into oblivion.
At some point, the amount of data that you’re dealing with becomes a bad fit for ranking windowing functions, and other approaches make more sense.
Of course, there are plenty of things that other variety of windowing functions do, that simple query rewrites don’t cover.
Here are some examples:
playing favorites
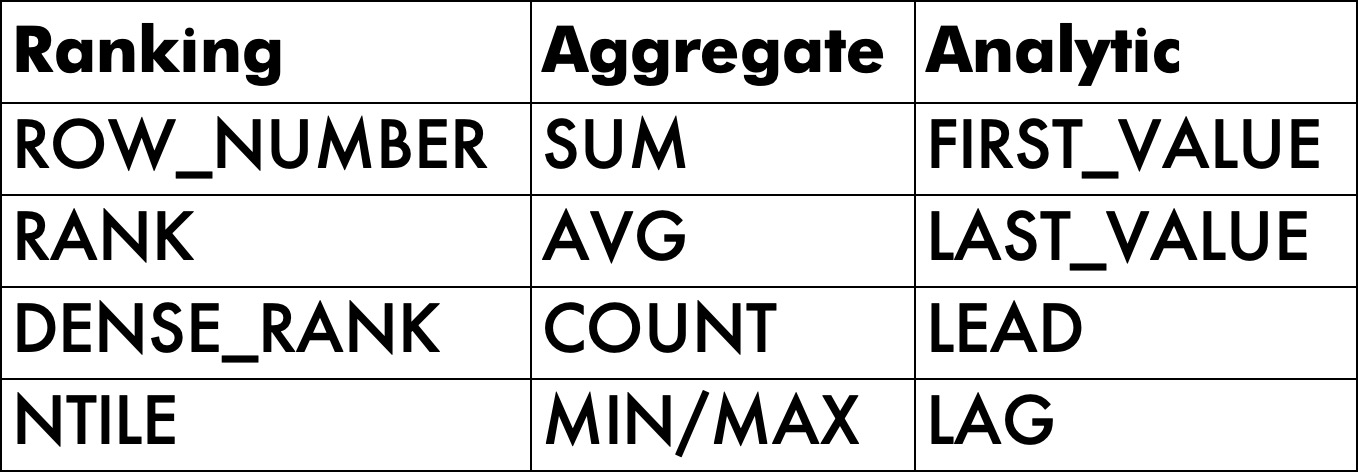
I realize that aggregate and analytic functions have many more options available, but there are only four ranking functions, and here at Darling Data, we strive for symmetry and equality.
It would be difficult to mimic the results of some of those — particularly the analytic functions — without performance suffering quite a bit, complicated self-joins, etc.
But, again, Batch Mode.
Hey Dude
Let’s start with a scenario I run into far too often: tables with crappy supporting indexes.
These aren’t too-too crappy, because I only have so much patience (especially when I know a blog post is going to be on the long side).
The index on Posts gets me to the data I care about fast enough, and the index on Votes allows for easy Apply Nested Loops seeking to support the Cross Apply.
There are some unnecessary includes in the index on Votes, because the demo query itself changed a bit as I was tweaking things.
But you know, if there’s one thing I’ve learned about SQL Server, there are lots of unnecessary includes in nonclustered indexes because of queries changing over the years.
CREATE INDEX
p
ON dbo.Posts
(PostTypeId)
INCLUDE
(Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
v
ON dbo.Votes
(PostId)
INCLUDE
(UserId, BountyAmount, VoteTypeId, CreationDate)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Now, the query I’m using is quite intentionally a bit of a stress test. I’m using two of the larger tables in the database, Posts and Votes.
But it’s a good example, because part of what I want to show you is how larger row counts can really mess with things.
I’m also using my usual trick of filtering to where the generated row number is equal to zero outside the apply.
That forces the query to do all of the window function work, without having to wait for 50 billion rows to render out in SSMS.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
CROSS APPLY
(
SELECT
v.*,
LastVoteByType =
ROW_NUMBER() OVER
(
PARTITION BY
v.VoteTypeId
ORDER BY
v.CreationDate DESC
)
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
AND v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
) AS v
WHERE p.PostTypeId = 2
AND v.LastVoteByType = 0;
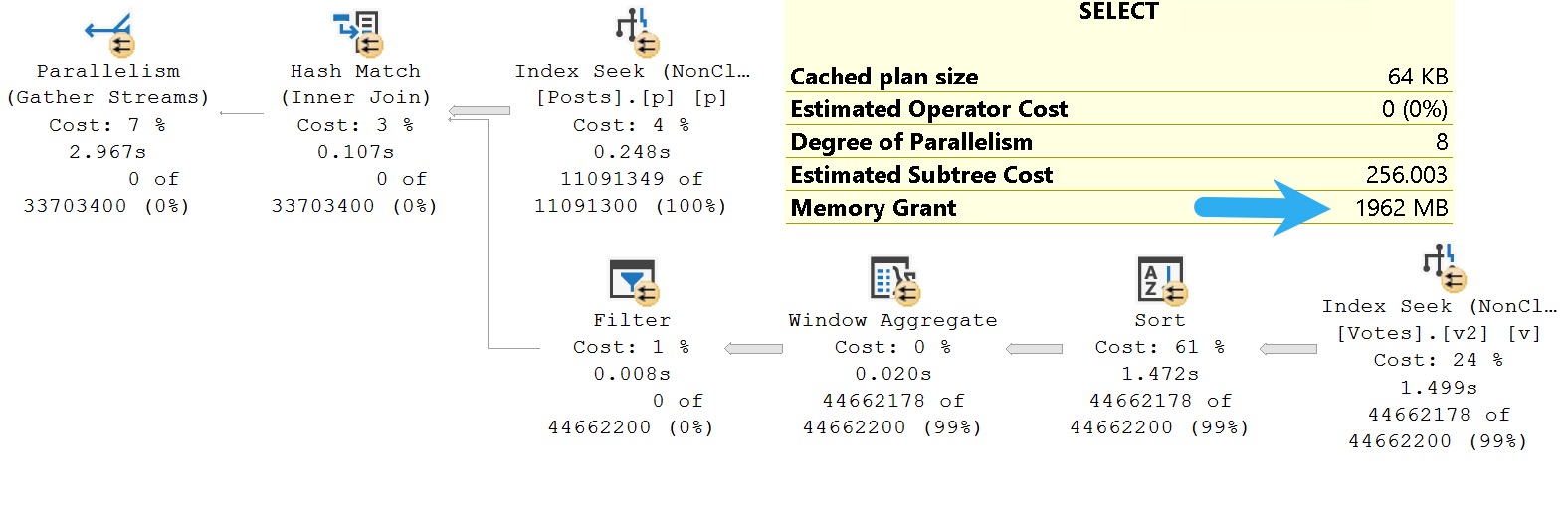
Assume that the initial goal is that we care very much about the ~4.2GB memory grant that this query acquires to Sort data for the windowing function, and to create an index that solves for that.
Dark Therapy
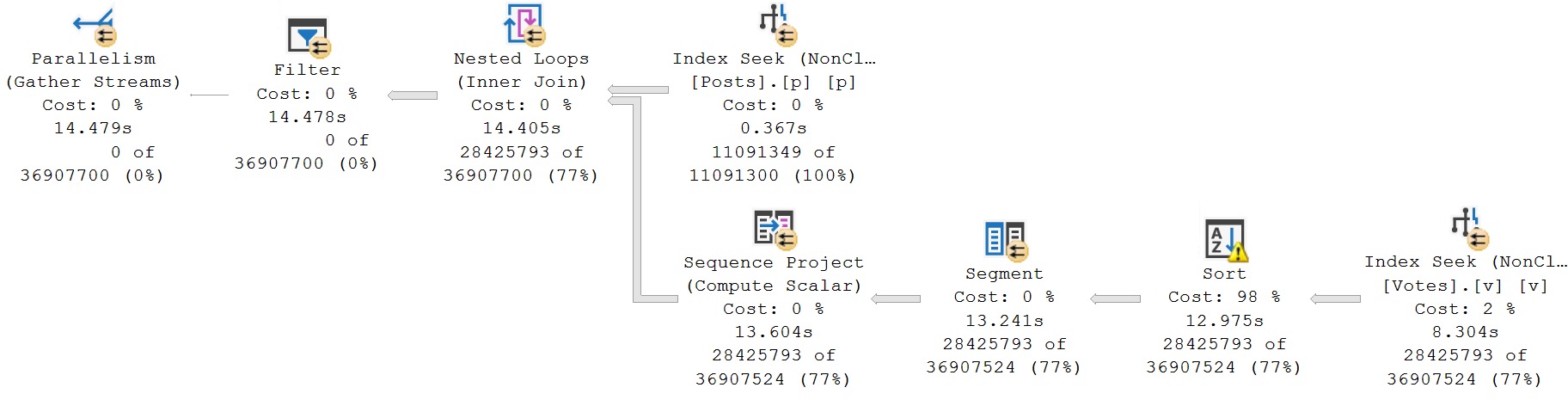
The query plan isn’t too bad, but like we looked at in the post in this series about fixing sorts, there is a bit of a sore spot.
get in line
Now, it has been blogged about many times, so I’m not going to belabor the point too much: the columns that need sorting are the ones in the partition by and order by of the windowing function.
But the index needs to match the sort directions of those columns exactly. For example, if I were to create this index, where the sort direction of the CreationDate column is stored ascending, but the windowing function asks for descending, it won’t work out.
CREATE INDEX
v
ON dbo.Votes
(PostId, VoteTypeId, CreationDate)
INCLUDE
(UserId, BountyAmount)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
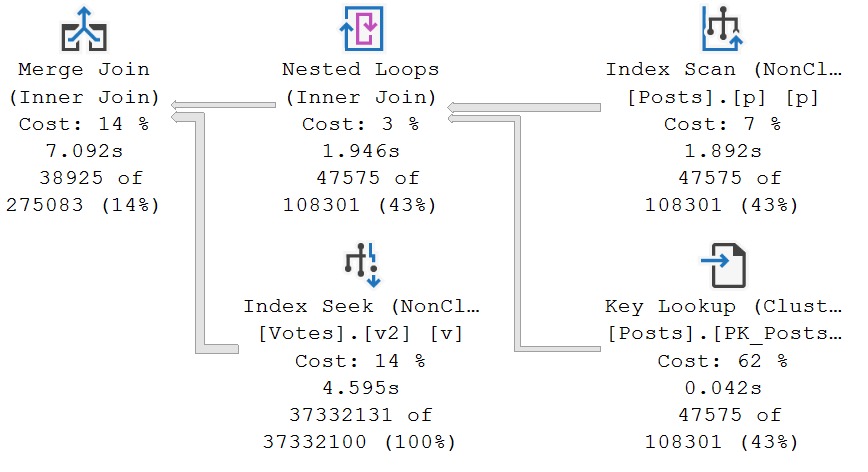
In fact, it’s gonna slow things down a bit. Score another one for crappy indexes, I suppose.
30 love
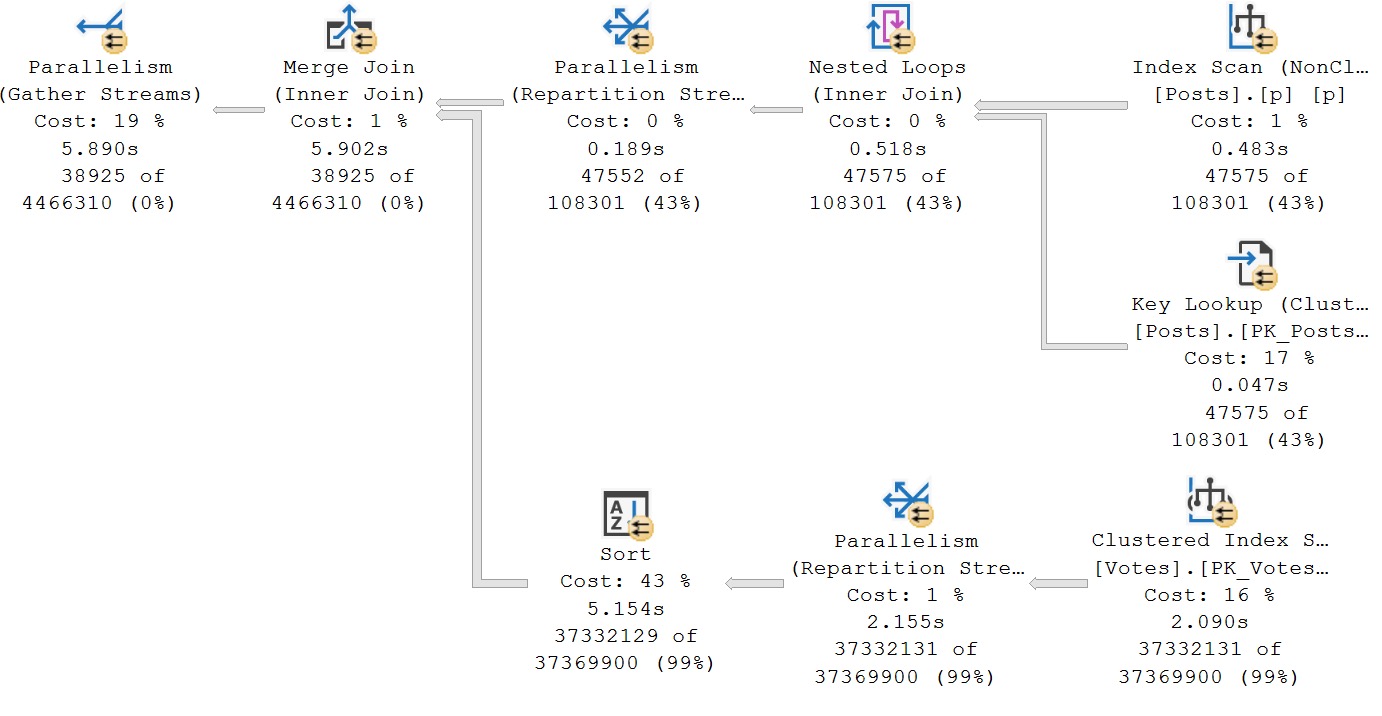
The reason why this one is so much slower is because of the Seek. I know, I know, how could a Seek be bad?! Well, it’s not one seek, it’s three seeks in one.
Time spent in each of the Row Mode operators in both of the plans you’ve seen so far is nearly identical, aside from the Seek into the Votes index. If we compare each tool tip…
one seek vs three seeks
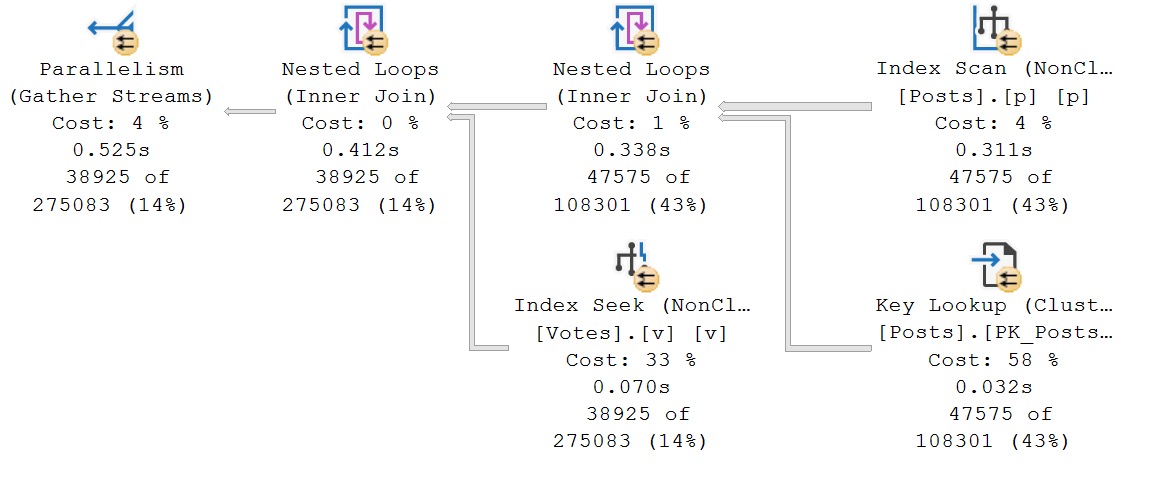
The plan properties for the Seek are only interesting for the second query. It’s not very easy to see from the tool tips above, because Microsoft is notoriously bad at user experience in its products.
threefer
It is somewhat easier to see, quite verbosely, that for each PostId, rather than a single seek and residual predicate evaluation, three seeks are done.
But, anyway, the problem we’re aiming to solve persists — the Sort is still there — and we spend about 4.5 seconds in it.
Your Best Won’t Do
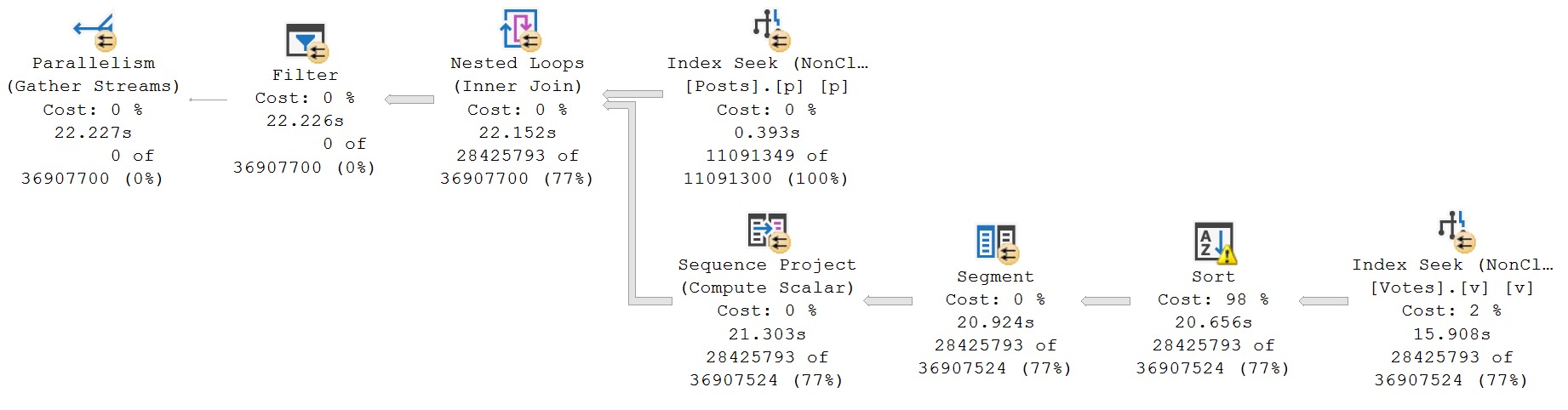
With a similar index, the best we can do is get back to the timing of the original query, minus the sort.
The index we created above was useless for that, because we were careless in our specification. We created it with CreationDate sorted in ascending order, and our query uses it in descending order.
CREATE INDEX
v
ON dbo.Votes
(PostId, VoteTypeId, CreationDate DESC)
INCLUDE
(UserId, BountyAmount)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
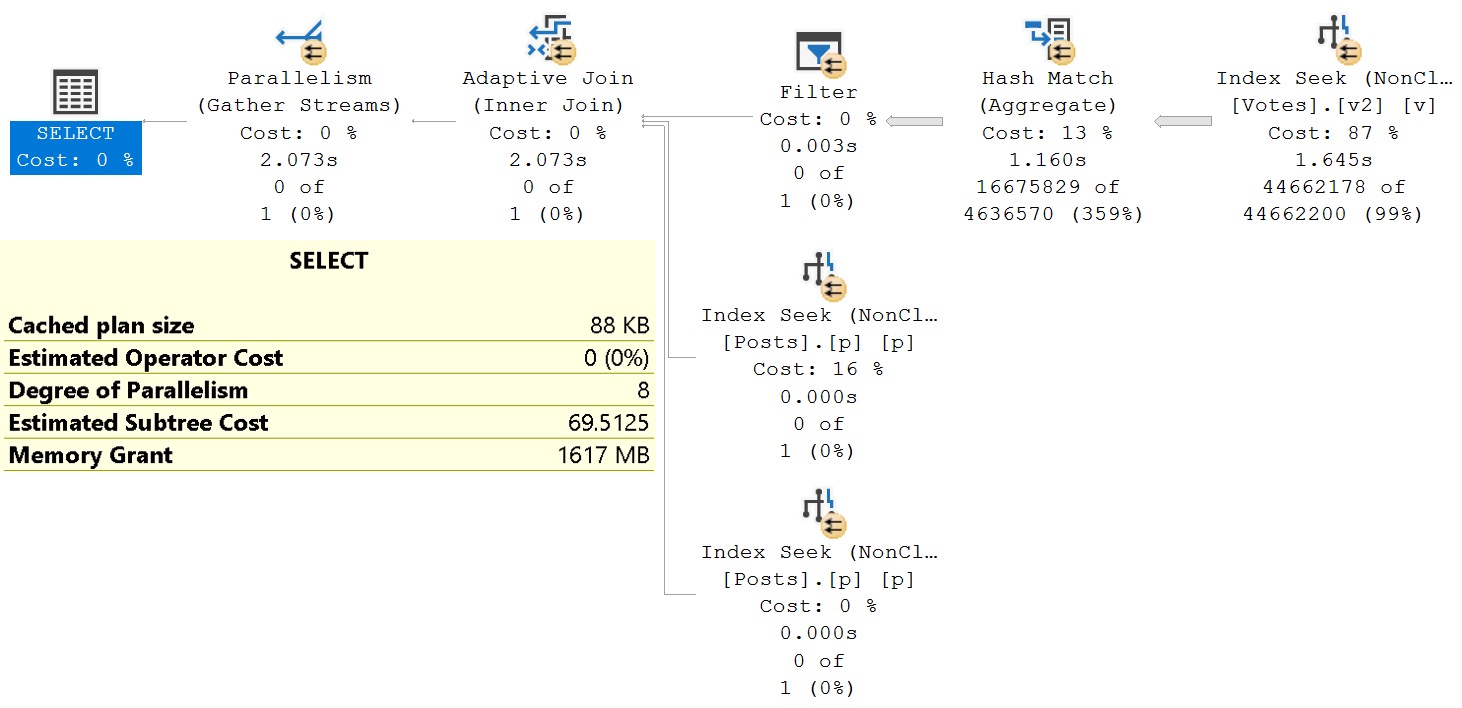
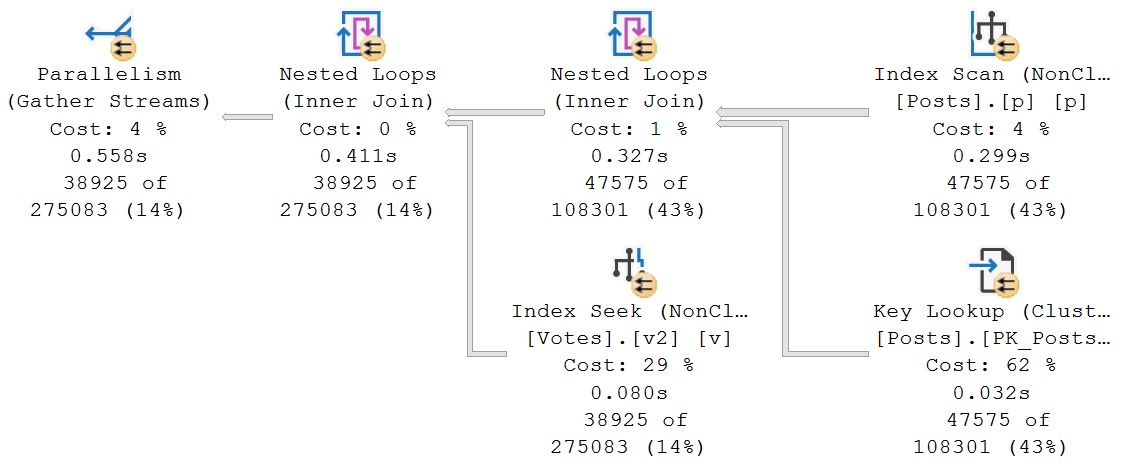
Now, we’ve gotten rid of the sort, so our query is no longer asking for 4.2GB of RAM, but the runtime is only roughly equivalent to the original query.
i see london, i see france
A bit amusing that we were better off with a query plan where the sort spilled to disk, but what can you do? Just marvel at your luck, sometimes.
Improving Runtime
The sort of sad thing is that the cross apply method is purely Row Mode mentality. A bit like when I poke fun at folks who spend a lot of energy on index fragmentation, page splits, and fill factor as having 32bit mentality, modern performance problems often require Batch Mode mentality.
Query tuning is often about trade-offs, and this is no exception. We can reduce runtime dramatically, but we’re going to need memory to do it. We can take this thing from a best of around 15 seconds, to 2-3 seconds, but that Sort is coming back.
Using the normal arsenal tricks, getting Batch Mode on the inner side of a cross apply doesn’t seem to occur easily. A rewrite to get Batch Mode for a cross apply query is not exactly straightforward.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
CROSS APPLY
(
SELECT
v.*
FROM
(
SELECT
v.*,
LastVoteByType =
ROW_NUMBER() OVER
(
PARTITION BY
v.VoteTypeId
ORDER BY
v.CreationDate DESC
)
FROM dbo.Votes AS v
) AS v
WHERE v.PostId = p.Id
AND v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
) AS v
WHERE p.PostTypeId = 2
AND v.LastVoteByType >= '99991231'
OPTION(RECOMPILE);
Let’s change our query to use the method that I normally advise against when working in Row Mode.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
JOIN
(
SELECT
v.*,
LastVoteByType =
ROW_NUMBER() OVER
(
PARTITION BY
v.VoteTypeId
ORDER BY
v.CreationDate DESC
)
FROM dbo.Votes AS v
WHERE v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
) AS v
ON v.PostId = p.Id
WHERE p.PostTypeId = 2
AND v.LastVoteByType = 0;
In Row Mode, this sucks because the entire query in the derived join needs to be executed, producing a full result set of qualifying rows in the Votes table with their associated row number. Watch the video I linked above for additional details on that.
However, if we have our brains in Batch Mode, this approach can be much more useful, but not with the current index we’re using that leads with PostId.
When we used cross apply, having PostId as the leading column allowed for the join condition to be correlated inside the apply. We can’t do that with the derived join, we can only reference it in the outer part of the query.
Tweaking Indexes
An index that looks like this, which allows for finding the rows we care about in the derived join easily makes far more sense.
CREATE INDEX
v2
ON dbo.Votes
(VoteTypeId, CreationDate DESC, PostId)
INCLUDE
(UserId, BountyAmount)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
With all that done, here’s our new query plan. Something to point out here is that this is the same query plan as the more complicated rewrite that I showed you in the last section, with the same memory grant. Some of these memory grant numbers are with memory grant feedback involved, largely shifting numbers downwards, which is what you would expect to see if you were doing this in real life.
daydreamer
It could be far less of a concern for concurrency to grant out ~2GB of memory for 2 seconds, than for 15-20 seconds.
Even in a situation where you’re hitting RESOURCE_SEMAPHORE waits, it’s far less harmful to hit them for 3 seconds on average than 15-20 seconds on average. It’s also hard to imagine that you’re on a server where you truly care about high-end performance if 2GB memory grants lead you to RESOURCE_SEMAPHORE waits. If you have 128GB of RAM, and max server memory set to 116-120GB, you would be able to run ~80 of these queries concurrently before having a chance of a problem hitting RESOURCE_SEMAPHORE waits, assuming that you don’t get Resource Governor involved.
Tweaking The Query
Like I said early on, there’s only so good you can get with queries that use windowing functions where there are no alternatives.
Sticking with our Batch Mode mindset, let’s use this rewrite. It’s not that you can’t cross apply this, it’s just that it doesn’t improve things the way we want. It takes about 5 seconds to run, and uses 1.3GB of RAM for a query memory grant.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
JOIN
(
SELECT
v.PostId,
v.VoteTypeId,
LastVoteByType =
MAX(v.CreationDate)
FROM dbo.Votes AS v
WHERE v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
GROUP BY
v.PostId,
v.VoteTypeId
) AS v
ON v.PostId = p.Id
LEFT JOIN dbo.columnstore_helper AS ch
ON 1 = 0 /*This is important*/
WHERE p.PostTypeId = 2
AND v.LastVoteByType >= '99991231';
Note that I don’t naturally get batch mode via Batch Mode On Row Store. I’m using a table with this definition to force SQL Server’s hand a bit, here:
CREATE TABLE
dbo.columnstore_helper
(
cs_id bigint NOT NULL,
INDEX cs_id CLUSTERED COLUMNSTORE
);
But the result is pretty well worth it. It’s around 1 second faster than our best effort, with a 1.6GB memory grant.
waterfall
There may be even weirder rewrites out there in the world that would be better in some way, but I haven’t come across them yet.
Coverage
We covered a number of topics in this post, involving indexing, query rewrites, and the limitations of Row Mode performance in many situations.
The issues you’ll see in queries like this are quite common in data science, or data analysis type workloads, including those run by common reporting tools like PowerBI. Everyone seems to want a row number.
I departed a bit from what I imagined the post would look like as I went along, as additional interesting details came up. I hope it was an enjoyable, and reasonably meandering exploration for you, dear reader.
There’s one more post planned for this series so far, and I should probably provide some companion material for why the multi-seek query plan is 2x slower than the seek + residual query plan.
Anyway, I’m tired.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Ordered data is good for all sorts kinds of things in databases. The first thing that may come to mind is searching for data, because it’s a whole lot easier to get what you need when you know where it is.
Think of a playlist. Sometimes you want to find a song or artist by name, and that’s the easiest way to find what you want.
Without things sorted the way you’re looking for them, it’s a lot like hitting shuffle until you get to the song you want. Who knows when you’ll find it, or how many clicks it will take to get there.
The longer your playlist is, well, you get the idea. And people get all excited about Skip Scans. Sheesh.
Anyway, let’s look at poor optimizer choices, and save the poor playlist choices for another day.
A Normal Query
This is a query that I know and love.
SELECT
p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
AND v.VoteTypeId = 2
ORDER BY
p.Id;
I love it because it gets a terribly offensive query plan.
ban me
Look at this monstrosity. A parallel merge join that requires a sort to enable its presence. Who would contrive such a thing?
A Sidebar
This is, of course, a matter of costing. For some reason the optimizer considered many other alternatives, and thought this one was the cheapest possible way to retrieve data.
For reference, the above query plan has an estimated cost of 2020.95 query bucks. Let’s add a couple hints to this thing.
SELECT
p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
AND v.VoteTypeId = 2
ORDER BY
p.Id
OPTION
(
HASH JOIN,
USE HINT('DISALLOW_BATCH_MODE')
);
Using this query, I’m telling SQL Server to use a hash join instead of a merge join. I’m also restricting batch mode to keep things a bit more fair, since the initial query doesn’t use it.
Here’s the execution plan:
hard to explain
SQL Server’s cost-based optimizer looks at this plan, and thinks it will cost 13844 query bucks to execute, or nearly 6x the cost of the merge join plan.
Of course, it finishes about 5 seconds faster.
Like I end up having to tell people quite a bit: query cost has nothing to do with query speed. You can have high cost queries that are very fast, and low cost queries that are very slow.
What’s particularly interesting is that on the second run, memory grant feedback kicks in to reduce the memory grant to ~225MB, down from the initial granted memory of nearly 10GB.
The first query retains a 2.5GB memory grant across many executions, because sorting the entire Votes table requires a bit of memory for the effort.
But This Is About Indexes, Not Hints
With that out of the way, let’s think about an index that would help the Votes table not need sorting.
You might be saying to yourself:
SELECT
p.*
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId /*We have to sort by this column for the merge join, let's put it first in the index*/
WHERE p.PostTypeId = 2
AND p.CreationDate >= '20131225'
AND v.VoteTypeId = 2 /*We can put this second in the index so we don't need to do any lookups for it*/
ORDER BY
p.Id; /*It's the clustered primary key, so we can just let the nonclustered index inherit it*/
Which would result in this index:
CREATE INDEX
v
ON dbo.Votes
(PostId, VoteTypeId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
And you’d be right this time, but you wouldn’t be right every time. With that index, this is the plan we get:
job well done
The optimizer chooses apply nested loops, and seeks both to the PostIds and VoteTypeIds that we care about.
That Won’t Always Happen
Sometimes, you’ll need to reverse the columns, and use an index like this:
CREATE INDEX
v2
ON dbo.Votes
(VoteTypeId, PostId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
This can be useful when the where clause predicate is really selective, and the join predicate is less so. We can still get a plan without a sort, and I’ll talk about why in a minute.
For now, let’s marvel at the god awful query plan SQL Server’s optimizer chooses for this index:
daffy duck
I think if I ever got my hands on the SQL Server source code, I’d cost merge joins out of existence.
But anyway, note that there’s no sort operator needed here.
Before I explain, let’s look at what the query plan would look like if SQL Server’s optimizer didn’t drink the hooch and screw the pooch so badly.
how nice of you to join us
It’s equally as efficient, and also requires no additional sorting.
Okay, time to go to index school.
Index 101
Let’s say we have an index that looks like this:
CREATE INDEX
whatever_multi_pass
ON dbo.Users
(
Reputation,
UpVotes,
DownVotes,
CreationDate DESC
)
INCLUDE
(
DisplayName
);
In row store indexes, the key columns are in stored in sorted order to make it easy to navigate the tree to efficiently locate rows, but they are not stored or sorted “individually”, like in column store indexes.
Let’s think about playlists again. Let’s say you have one sorted by artist, release year, album title, and track number. Who knows, maybe someone (like DMX) released two great albums in a single year.
You would have:
The artist name, which would have a bunch of duplicates for each year (if it’s DMX), duplicates for album title, and then unique track ids
The release year, which may have duplicates (if it’s DMX) for each album, and then unique track ids
The album title which would have duplicates for unique track id
But for each of those sets of duplicates, things would be stored in order.
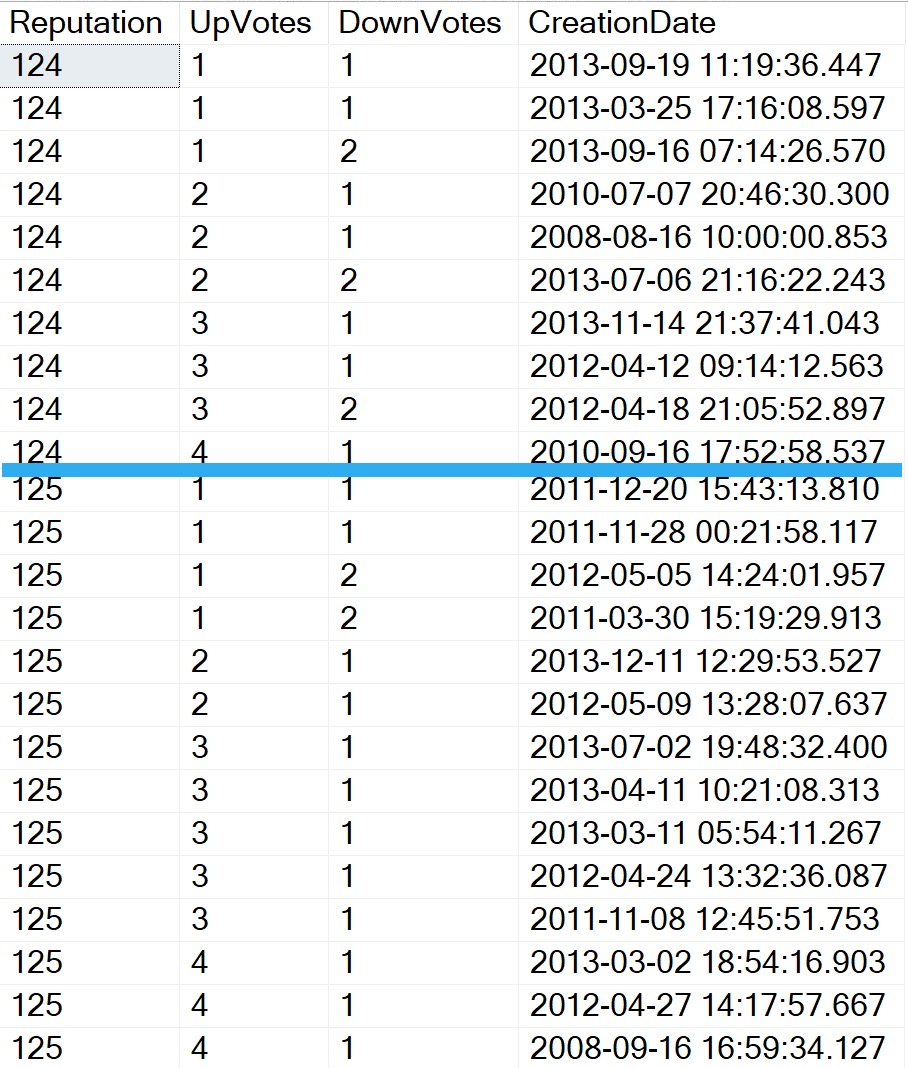
So, going back to our index, conceptually the data would be stored looking like this, if we ran this query:
SELECT TOP (1000)
u.Reputation,
u.UpVotes,
u.DownVotes,
u.CreationDate
FROM dbo.Users AS u
WHERE u.Reputation IN (124, 125)
AND u.UpVotes < 11
AND u.DownVotes > 0
ORDER BY
u.Reputation,
u.UpVotes,
u.DownVotes,
u.CreationDate DESC;
I’ve cut out some rows to make the image a bit more manageable, but here you go:
storage!
For every row where reputation is 124, upvotes are sorted in ascending order, and then for any duplicates in upvotes, downvotes are stored in ascending order, and for any duplicate downvotes, creation dates are stored in descending order.
Then we hit 125, and each of those “reset”. Upvotes starts over again at 1, which means we have new duplicate rows to sort downvotes for, and then new duplicate rows in downvotes to sort creation dates in.
Going back to our query, the reason why we didn’t need to sort data even when PostId was the second column is because we used an equality predicate to find VoteTypeIds with a value of 2. Within that entire range, PostId were stored in ascending order.
Understanding concepts like this is really important when you’re designing indexes, because you probably have a lot of complicated queries, with a lot of complicated needs:
Multiple where clause predicates
Multiple join columns to different tables
Maybe with grouping and ordering
Maybe with a windowing function
Getting indexes right for a single query can be a monumental feat. Getting indexes right for an entire workload can seem quite impossible.
The good news, though, is that not every query can or should have perfect indexes. It’s okay for some queries to be slow; not every one is mission critical.
Making that separation is crucial to your mental health, and the indexing health of your databases.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
CREATE INDEX
p2
ON dbo.Posts
(OwnerUserId, Score)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
c2
ON dbo.Comments
(UserId, Score)
WITH
(MAXDOP = 8, SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
I’ve taken a small bit of artistic license with them.
The crappy thing is… They really do not help and in some cases things get substantially worse.
Original Query
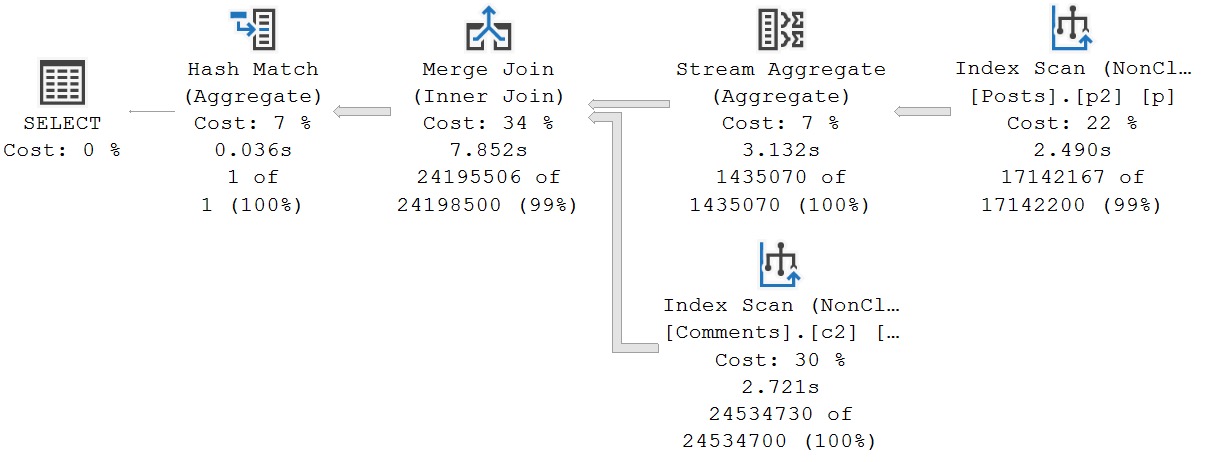
The original query plan is still awful. It is using both of our new indexes.
oh okay
No early aggregation whatsoever. Though yesterday’s takes 23 seconds, and today’s takes 22 seconds, I’d hardly call ourselves indexing victors for the improvement.
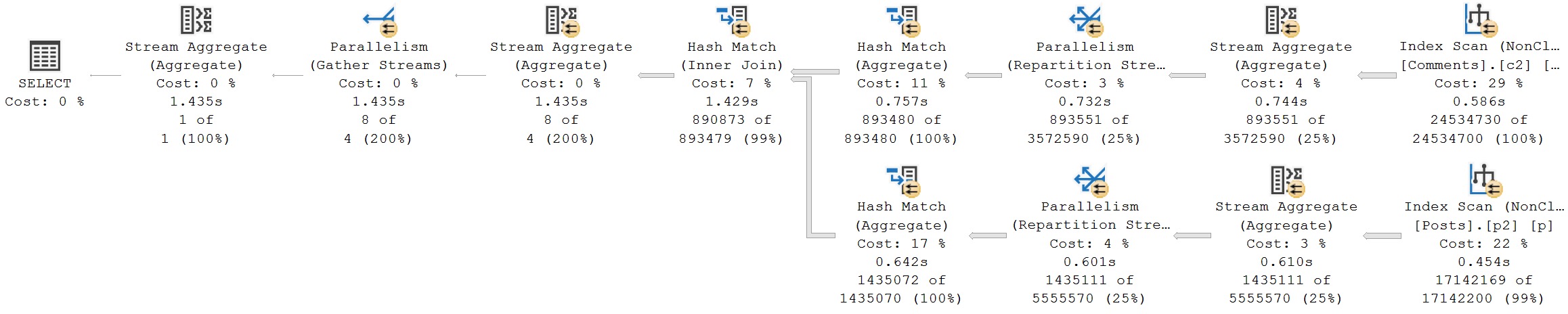
Rewrite #1: Manually Aggregate Posts
This one eats it the hardest, again, using both of our new indexes.
we gotta talk.
If one were to appreciate any aspect of this query plan, it’s that the optimizer didn’t choose a parallel merge join plan. Parallel merge joins were a mistake, and have driven me closer to alcohol induced comas than the Red Sox in the 90s.
The total runtime for this query shoots up to about 8 seconds. The biggest change, aside from a serial execution plan being chosen, is that only the Hash Match operator at the very end runs in Batch Mode. All other operators execute in Row Mode.
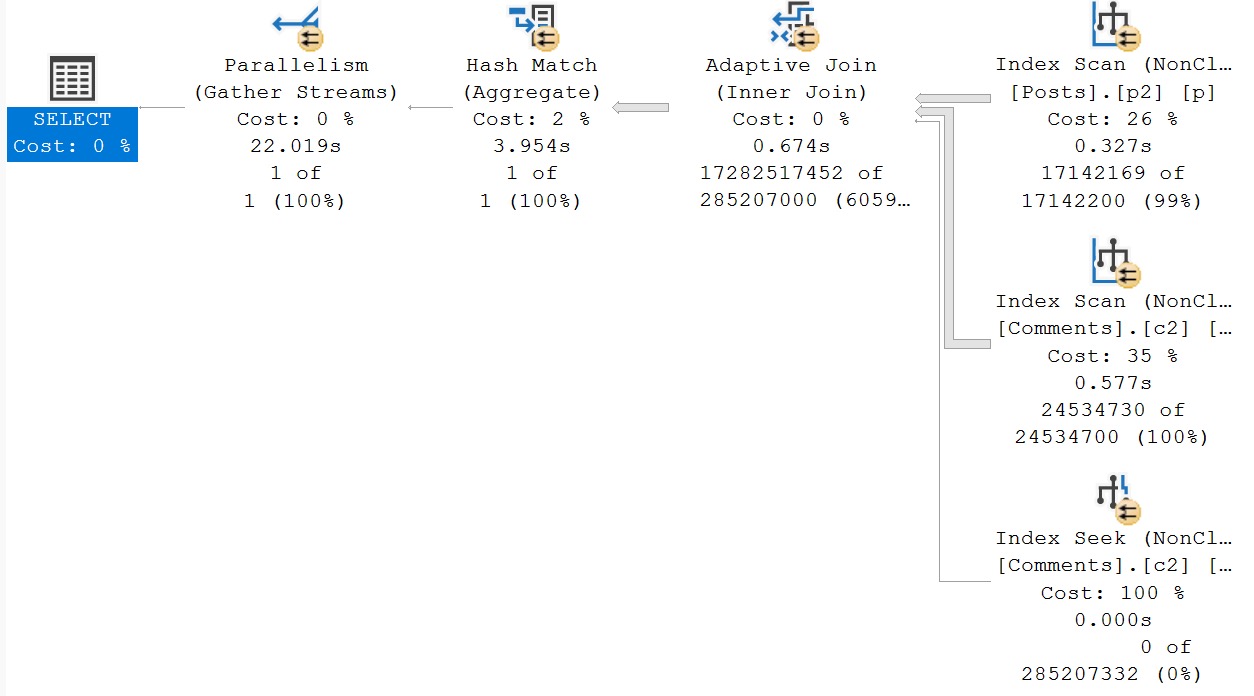
Rewrite #2: Manually Aggregate Comments
We go back to a parallel plan, but again, in Row Mode. This query now takes 2x as long as yesterday’s Batch Mode plan.
try, try again
Again, both new indexes are in use here. This one is the most disappointing.
Rewrite #3: Manually Aggregate Both
The fun thing about all of these plans is that, aside from the things I’ve been talking about, they all have the same problem as yesterday’s plans: Unless we tell SQL Server to aggregate things, it’s not trying to do that before the joins happen.
wrongo boyo
Again, the entire plan runs in Row Mode, using both new indexes. Though most of the operators are ineligible for Batch Mode, the hash operations are, but… Just don’t use it
It’s not the end of the world for this query. It runs within a few milliseconds of yesterday’s with the old indexes. It’s just disappointing generally.
Rewrite #4: Manually Aggregate Both, Force Join Order
I’m going through the motions a touch with this one, because unlike yesterday’s plan, this one uses the forced join order naturally. It ends up in a similar situation as the above query plan though.
e-mo-shuns
Again, both indexes are in use, but just not helping.
It Seems Strange
Why would SQL Server’s query optimizer decide that, with opportune indexes, Batch Mode just wouldn’t be useful?
Regardless of key column order, the same number of rows are still in play in all of my examples, with or without aggregations. In many cases, the new indexes are also scanned to acquire all of the rows, but also even the seek operators need to acquire all the rows!
There’s no where clause to help things, and only a single one of the Row Mode queries uses a Bit Map operator that can be used to filter some rows out of the joined table early.
Quite a strange brew of things to consider here. But the bottom line is, additional indexes are not always helpful for aggregation queries like this, and may result in really weird plan choices.
If you’re dealing with queries that aggregate a lot of data, and SQL Server isn’t choosing early partial or full aggregations before joining tables together, you’re probably going to have to roll up your sleeves and do it yourself.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I didn’t have a chance to write this post yesterday, because I was in the midst of closing the ticket.
Here’s a short synopsis from the client emergency:
Third party vendor
Merge statement compiled in a DLL file
Called frequently
Uses a Table-Valued Parameter
Merges into one small table…
Which has an indexed foreign key to a huge table
Constantly deadlocking with other calls to the same merge query
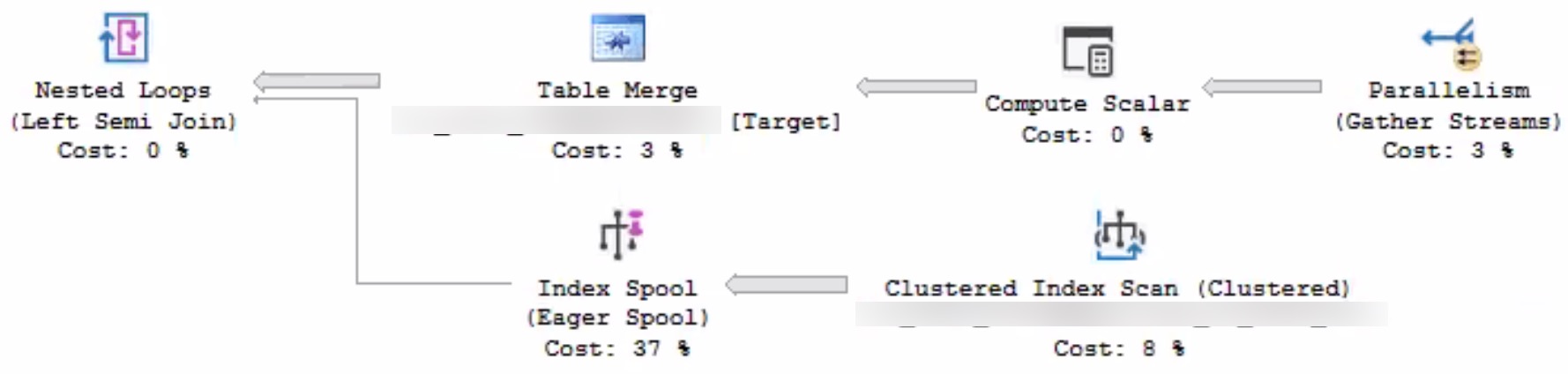
To evaluate the foreign key, SQL Server was choosing this execution plan:
suck
I hate the optimizer, some days. I really do.
Whatever year it’s stuck in is an unfortunate one.
Eager Index Spools Suck
Why in the name of Babe the blue-balled Ox would SQL Server’s advanced, intelligent, hyper-awesome, $7k a core query optimizer choose to build an index spool here, on 7 million rows?
Here are some things we tried to get rid of it:
Add a clustered index to the target table
Add a single-column index on the already-indexed clustered index key
Add primary keys to the Table Types
If I had access to the merge statement, I would have torn it to shreds separate insert, update, and delete statements.
But would that have helped with SQL Server’s dumb execution plan choice in evaluating the foreign key? Would a FORCESEEK hint even be followed into this portion of the execution plan?
RCSI wouldn’t help here, because foreign key evaluation is done under Read Committed Locking isolation.
I don’t know. We can’t just recompile DLLs. All I know is that building the eager index spool is slowing this query down just enough to cause it to deadlock.
So, I took a page out of the Ugly Pragmatism handbook. I disabled the foreign key, and set up a job to look for rogue rows periodically.
Under non-Merge circumstances, I may have written a trigger to replace the foreign key. In that very moment, I had some doubts about writing a trigger quickly that would have worked correctly with:
All of Merge’s weirdness
Under concurrency
In reality, the foreign key wasn’t contributing much. The application only ever allows users to put rows in the parent table, and additional information only gets added to the child table by a system process after the original “document” is processed.
So, goodbye foreign key, goodbye eager index spool, goodbye deadlocks.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.