The nice folks at the New England SQL Server User Group (w|t) had me in town a week ago to present my workshop, The Foundations Of SQL Server Performance.
We had about 40 folks show up — which ain’t bad for a random Friday in May — including one attendee from Nigeria.
Not just like, originated in Nigeria. Like, flew from Nigeria for the workshop. That’s probably a new record for me, aside from PASS Precons where folks are already headed in from all corners.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
You and Me might feel like the lower back end of a thing if we’re tuning a query that has other problems. Perhaps it’s running on one of those serverless servers with half a hyper-threaded core and 8kb of RAM, as an example.
When I’m working with clients, I often get put into odd situations that limit what I’m allowed to do to fix query performance. Sometimes code comes from an ORM or vendor binaries that can’t be changed, sometimes adding an index on a sizable table on standard edition in the middle of the day is just an impossibility, and of course other times things are just a spectacle du derrière that I’m allowed to do whatever I want. You can probably guess which one I like best.
This post is about the two other ones, where you’re stuck between derrière and ânesse.
For the duration of reading this, make the wild leap of faith that it takes to embrace the mindset that not everyone who works with SQL Server knows how to write good queries or design good indexes.
I know, I know. Leap with me, friends.
The Query And Execution Plan
Here’s what we’re starting with:
SELECT TOP (10)
DisplayName =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE u.Id = p.OwnerUserId
),
p.AcceptedAnswerId,
p.CreationDate,
p.LastActivityDate,
p.ParentId,
p.PostTypeId,
p.Score,
p.CommentCount,
VoteCount =
(
SELECT
COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
)
FROM dbo.Posts AS p
ORDER BY
p.Score DESC;
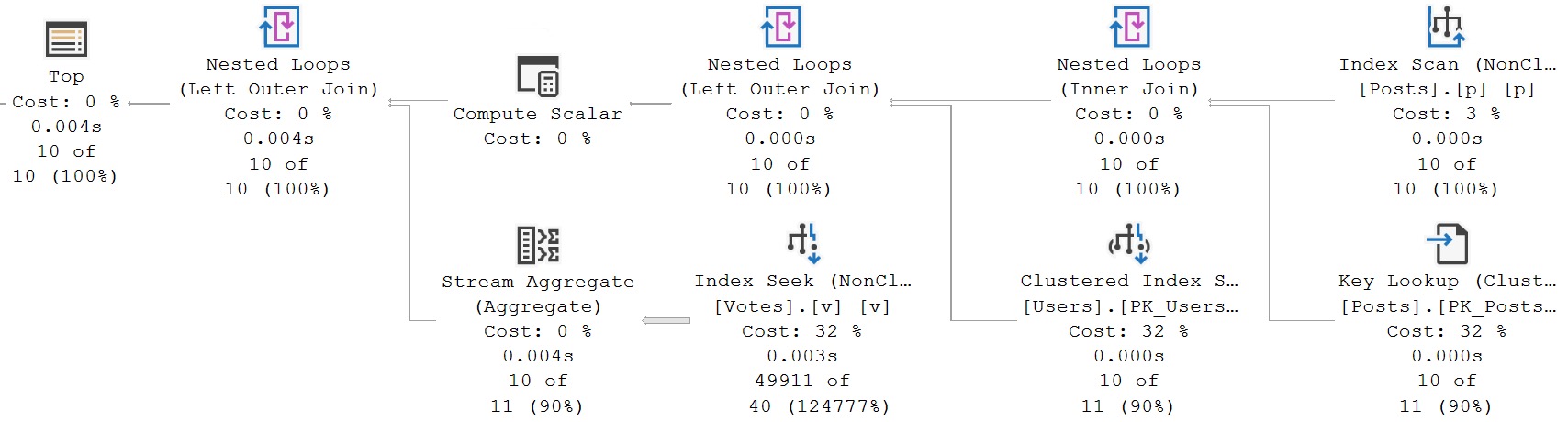
And resulting plan:
bas
We can surmise a few things from this plan:
If there are good indexes, SQL Server isn’t using them
That hash spill is some extra kind of bad news
Spools remain a reliable indicator that something is terribly wrong
Okay, so I’m kidding a bit on the last point. Sorta.
The Query Plan Details
You might look at all this work that SQL Server is doing and wonder why: With no good, usable indexes, and such big tables, why in the overly-ambitious heck are we doing all these nested loop joins?
And the answer, my friend, is blowing in the row goal.
The TOP has introduced one here, and it has been applied across the all of the operators along the top of the plan.
Normally, a row goal is when the optimizer places a bet on it being very easy to locate a small number of rows and produces an execution plan based on those reduced costs.
In this case, it would be 10 rows in the Posts table that will match the Users table and the Votes table, but since these are joins of the left outer variety they can’t eliminate results from the Posts table.
The row goals do make for some terrible costing and plan choices here, though.
blue = row goal applied orange = no row goal applied
This all comes from cardinality estimation and costing and all the other good stuff that the optimizer does when you throw a query at it.
The Query Rewrite
One way to show the power of TOPs is to increase and then decrease the row goal. For example, this (on my machine, at this very moment in time, given many local factors) will change the query plan entirely:
SELECT TOP (10)
p.*
FROM
(
SELECT TOP (26)
DisplayName =
(
SELECT
u.DisplayName
FROM dbo.Users AS u
WHERE u.Id = p.OwnerUserId
),
p.AcceptedAnswerId,
p.CreationDate,
p.LastActivityDate,
p.ParentId,
p.PostTypeId,
p.Score,
p.CommentCount,
VoteCount =
(
SELECT
COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
)
FROM dbo.Posts AS p
ORDER BY
p.Score DESC
) AS p
ORDER BY
p.Score DESC;
You may need to toggle with the top a bit to see the change on your machine. The resulting plan looks a bit funny. You won’t normally see two TOPs nuzzling up like this.
scientific
But the end result is an improvement by a full minute and several seconds.
Because the inner TOP has a bigger row goal, the optimizer changes its mind about how much effort it will have to expend to fully satisfy it before clenching things down to satisfy the smaller TOP.
If you’re only allowed quick query rewrites, this can be a good way to get a more appropriate plan for the amount of work required to actually locate rows at runtime, when the optimizer is dreadfully wrong about things.
The Index Rewrite
In this case, just indexing the Votes table is enough to buy us all the performance we need, but in my personal row goal for completeness, I’m going to add in two indexes:
CREATE INDEX
v
ON dbo.Votes
(PostId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
p
ON dbo.Posts
(Score DESC, OwnerUserId)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Going back to the original query, we no longer need to play games with the optimizer and pitting TOPs against each other.
wisdom teeth
This is obviously much faster, if you’re in the enlightened and enviable position to create them.
Perhaps you are, but maybe not in the exact moment that you need to fix a performance problem.
In those cases, you may need to use rewrites to get temporary performance improvements until you’re able to.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
This is a short post. I know you’ve been somewhat spoiled by longer posts and videos lately!
Just kidding, y’all don’t pay attention (with the exception of Kevin Feasel), so maybe this will be consumable enough for even the most squirrel brained amongst us.
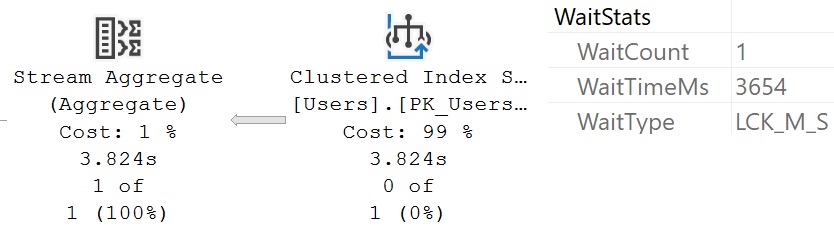
A long time ago, I complained that wait stats logged by actual execution plans don’t show lock waits. That seemed like a pretty big deal, because if you’re running a query and wondering why sometimes it’s fast and sometimes it’s slow, that could be a pretty huge hint.
But now, if you run a query that experienced lock waits, you can see that in the details. Just highlight the root operator, hit F4 or right click and go to Properties, and look under the wait stats node, you’ll see this:
cherry bomb
When did this get added? I have no idea.
How far was it back ported? I have no idea.
I could look on VMs with older versions of SQL Server, but it’s dinner time. Or as they call it in Saskatchewan, “supper”.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Since Kevin is often kind enough to link to my posts via his Curated SQL feed/aggregator, I figured I’d add to the SEO pyramid scheme this month.
As part of my consulting services, I often help clients decide if they could keep a full time database person (there are too many potential titles to list, here) busy for 40 hours a week for the foreseeable future.
If the Magic 8-Ball comes back with a Yes, I’ll also help them write or review their job posting, and screen candidates. If a resume makes it past various detectors and doesn’t end up in the randomly generated unlucky pile, I’ll interview them.
Me. Personally.
Not in-person, though.
There’s not enough armed security in the world for me to get that close to HR.
The Production DBA Question
If someone is going to be in charge of production DBA tasks, I’ll of course ask questions about experience with whatever model is in use, or is to be implemented by the company.
So like, if the company has Availability Groups, or wants Availability Groups, we’ll talk about those.
For flavor, I’ll also ask them why anyone would be so insane as to not just use a Failover Cluster with Log Shipping.
But the real question and answer that tells me if someone knows their business is this: When you set up backups, how often do you take log backups?
If anyone says “every 15 minutes” without any further clarification or qualification, they immediately go into the “No” pile.
See, 15 minute log backups are a meme in the same Pantheon as 5% and 30% for index fragmentation. Neither answer shows any deeper understanding of what exactly they’re doing.
Log backup frequency is a business requirement based on RPO goals (Recovery Point Objective). If your RPO goal is less than 15 minutes of data loss, 15 minute log backups don’t meet that goal.
And anyone who says that Availability Groups help meet RPO goals gets their resume burned in front of them.
The Developer DBA Question
For anyone responsible for performance tuning, I need to make sure that they’re staying current with their learning and techniques.
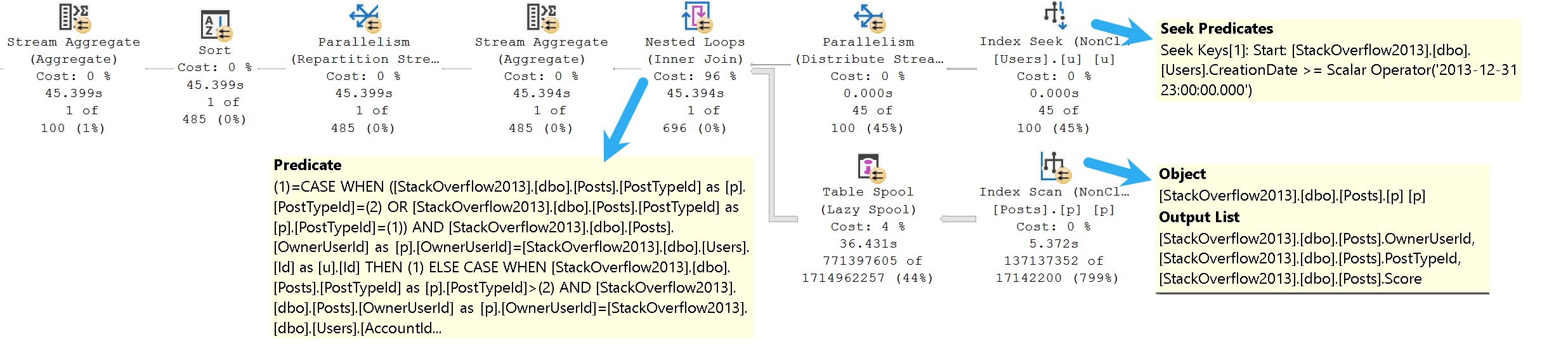
I’ll show a lot of pictures of queries and query plans, ask about various anti-patterns and tuning techniques, but my absolute favorite is to show them pictures of query plans.
Actual execution plans, as it were.
fine mess
Why is this important? Because at least half of the people I show this to will totally ignore the operator times and start talking about costs.
If you’re looking at a plan where this much information is available, and all you can dredge up to troubleshoot things are estimated costs, I’ll probably mail you a copy of this.
And I’m not kidding here — it shows a complete lack of attention and growth — what’s the point of calling yourself a performance tuning expert if your expertise peaked in 2008?
There Are Good People Out There
They may not spend every waking moment writing, recording, speaking, or chasing MVP status.
And that’s fine — I don’t care if you partake in that stuff or not — there are plenty of very smart people out there who don’t file quarterly paperwork or schedule posts months in advance.
What I care about is that you aren’t just an automaton seeking a new place to go through the motions in.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Why Performance Tuners Need To Use The Right Type Of Join In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
User Experience Under Different Isolation Levels In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Loops, Transactions, and Transaction Log Writes In SQL Server
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
ED: I moved up this post’s publication date after Mr. O posted this question. So, Dear Brent, if you’re reading this, you can consider it my humble submission as an answer.
It’s really not up my alley. I love performance tuning SQL Server, but occasionally things like this come up.
Sort of recently, a client really wanted a way to figure out if support staff was manipulating data in a way that they shouldn’t have. Straight away: this method will not track if someone is inserting data, but inserting data wasn’t the problem. Data changing or disappearing was.
The upside of this solution is that not only will it detect who made the change, but also what data was updated and deleted.
It’s sort of like auditing and change data capture or change tracking rolled into one, but without all the pesky stuff that comes along with auditing, change tracking, or change data capture (though change data capture is probably the least guilty of all the parties).
Okay, so here are the steps to follow. I’m creating a table from scratch, but you can add all of these columns to an existing table to get things working too.
Robby Tables
First, we create a history table. We need to do this first because there will be computed columns in the user-facing tables.
/*
Create a history table first
*/
CREATE TABLE
dbo.things_history
(
thing_id int NOT NULL,
first_thing nvarchar(100) NOT NULL,
original_modifier sysname NOT NULL,
/*original_modifier is a computed column below, but not computed here*/
current_modifier sysname NOT NULL,
/*current_modifier is a computed column below, but not computed here*/
valid_from datetime2 NOT NULL,
valid_to datetime2 NOT NULL,
INDEX c_things_history CLUSTERED COLUMNSTORE
);
I’m choosing to store the temporal data in a clustered columnstore index to keep it well-compressed and quick to query.
Next, we’ll create the user-facing table. Again, you’ll probably be altering an existing table to add the computed columns and system versioning columns needed to make this work.
/*Create the base table for the history table*/
CREATE TABLE
dbo.things
(
thing_id int
CONSTRAINT pk_thing_id PRIMARY KEY,
first_thing nvarchar(100) NOT NULL,
original_modifier AS /*a computed column, computed*/
ISNULL
(
CONVERT
(
sysname,
ORIGINAL_LOGIN()
),
N'?'
),
current_modifier AS /*a computed column, computed*/
ISNULL
(
CONVERT
(
sysname,
SUSER_SNAME()
),
N'?'
),
valid_from datetime2
GENERATED ALWAYS AS
ROW START HIDDEN NOT NULL,
valid_to datetime2
GENERATED ALWAYS AS
ROW END HIDDEN NOT NULL,
PERIOD FOR SYSTEM_TIME
(
valid_from,
valid_to
)
)
WITH
(
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = dbo.things_history,
HISTORY_RETENTION_PERIOD = 7 DAYS
)
);
A couple things to note: I’m adding the two computed columns as non-persisted, and I’m adding the system versioning columns as HIDDEN, so they don’t show up in user queries.
The WITH options at the end specify which table we want to use as the history table, and how long we want to keep data around for. You may adjust as necessary.
I’m tracking both the ORIGINAL_LOGIN() and the SUSER_SNAME() details in case anyone tries to change logins after connecting to cover their tracks.
Inserts Are Useless
Let’s stick a few rows in there to see how things look!
SELECT
table_name =
'dbo.things',
t.thing_id,
t.first_thing,
t.original_modifier,
t.current_modifier,
t.valid_from,
t.valid_to
FROM dbo.things AS t;
The results won’t make a lot of sense. Switching back and forth between the sa and ostress users, the original_modifier column will always say sa, and the current_modifier column will always show whichever login I’m currently using.
You can’t persist either of these columns, because the functions are non-deterministic. In this way, SQL Server is protecting you from yourself. Imagine maintaining those every time you run a different query. What a nightmare.
The bottom line here is that you get no useful information about inserts, nor do you get any useful information just by querying the user-facing table.
Updates And Deletes Are Useful
Keeping my current login as ostress, let’s run these queries:
UPDATE
t
SET
t.first_thing =
t.first_thing +
SPACE(1) +
t.first_thing
FROM things AS t
WHERE t.thing_id = 100;
UPDATE
t
SET
t.first_thing =
t.first_thing +
SPACE(3) +
t.first_thing
FROM things AS t
WHERE t.thing_id = 200;
DELETE
t
FROM dbo.things AS t
WHERE t.thing_id = 300;
DELETE
t
FROM dbo.things AS t
WHERE t.thing_id = 400;
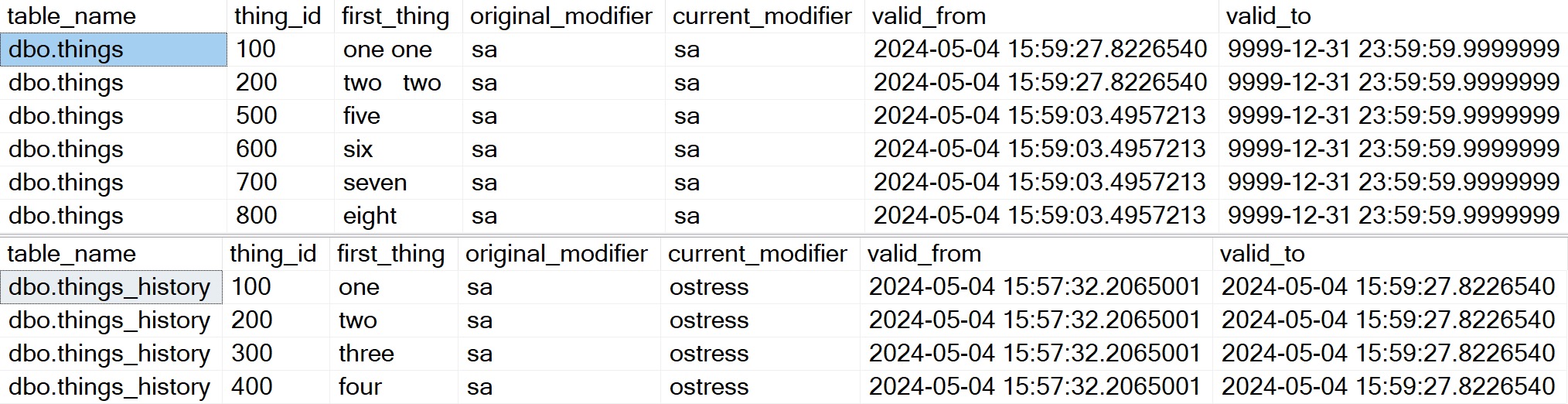
Now, along with looking at the user-facing table, let’s look at the history table as well.
To show that the history table maintains the correct original and current modifier logins, I’m going to switch back to executing this as sa.
peekaboo i see you!
Alright, so here’s what we have now!
In the user-facing table, we see the six remaining rows (we deleted 300 and 400 up above), with the values in first_thing updated a bit.
Remember that the _modifier columns are totally useless here because they’re calculated on the fly every time
We also have the history table with some data in it finally, which shows the four rows that were modified as they existed before, along with the user as they logged in, and the user as the queries were executed.
This is what I would brand “fairly nifty”.
FAQ
Q. Will this work with my very specific login scenario?
A. I don’t know.
Q. Will this work with my very specific set of permissions?
A. I don’t know.
Q. But what about…
A. I don’t know.
I rolled this out for a fairly simple SQL Server on-prem setup with very little insanity as far as login schemes, permissions, etc.
You may find edge cases where this doesn’t work, or it may not even work for you from the outset because it doesn’t track inserts.
With sufficient testing and moxie (the intrinsic spiritual spark, not the sodie pop) you may be able to get it work under you spate of local factors that break the peace of my idyllic demo.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Whether you want to be the next great query tuning wizard, or you just need to learn how to start solving tough business problems at work, you need a solid understanding of not only what makes things fast, but also what makes them slow.
I work with consulting clients worldwide fixing complex SQL Server performance problems. I want to teach you how to do the same thing using the same troubleshooting tools and techniques I do.
I’m going to crack open my bag of tricks and show you exactly how I find which queries to tune, indexes to add, and changes to make. In this day long session, you’re going to learn about hardware, query rewrites that work, effective index design patterns, and more.
Before you get to the cutting edge, you need to have a good foundation. I’m going to teach you how to find and fix performance problems with confidence.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.