If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If the Gods of post scheduling cooperate, this should publish in October. That means you’ve got a little more than a month to buy tickets and book travel to PASS.
Searching the internet for every problem isn’t cutting it.
You need to be more proactive and efficient when it comes to finding and solving database performance fires. I work with consulting customers around the world to put out SQL Server performance fires.
In this day of learning, I will teach you how to find and fix your worst SQL Server problems using the same modern tools and techniques which I use every week.
You’ll learn tons of new and effective approaches to common performance problems, how to figure out what’s going on in your query plans, and how indexes really work to make your queries faster.
Together, we’ll tackle query rewrites, batch mode, how to design indexes, and how to gather all the information you need to analyze performance.
This day of learning will teach you cutting edge techniques which you can’t find in training by folks who don’t spend time in the real world tuning performance.
Performance tuning mysteries can easily leave you stumbling through your work week, unsure if you’re focusing on the right things.
You’ll walk out of this class confident in your abilities to fix performance issues once and for all.
If you want to put out SQL Server performance fires, this is the precon you need to attend. Anyone can have a plan, it takes a professional to have a blueprint.
In-person attendees will also get a cool t-shirt. Arguably the coolest t-shirt ever made for a SQL Server conference.
big eight
Dates And Times
The PASS Data Community Summit is taking place in Seattle November 15-18, 2022 and online.
You can register here, to attend online or in-person. I’ll be there in all my fleshy goodness, and I hope to see you there too!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I’m still looking into this a bit, but I ran into this issue when helping set up a process to migrate data to a table because the original table was running out of integer identity values.
The process looks something like:
Create a new table with the right definition
Write a loop to backfill existing table data
Create a trigger to keep updated data synchronized
Eventually swap the tables during a short maintenance window
All well and good! Except… You can end up with a really weird execution plan for the backfill process, and some pretty gnarly memory grants for wide tables.
Demonstrating with the Votes table:
CREATE TABLE
dbo.Votes_bigint
(
Id bigint IDENTITY NOT NULL,
PostId int NOT NULL,
UserId int NULL,
BountyAmount int NULL,
VoteTypeId int NOT NULL,
CreationDate datetime NOT NULL,
CONSTRAINT PK_Votes_bigint_Id
PRIMARY KEY CLUSTERED (Id ASC)
)
GO
INSERT
dbo.Votes_bigint
(
Id,
PostId,
UserId,
BountyAmount,
VoteTypeId,
CreationDate
)
SELECT TOP (100000)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
ORDER BY v.Id;
The query plan has a Sort in it, which is weird because… Both tables are primary key/clustered index on the same column. Why re-sort that data?
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
CREATE EVENT SESSION keeper_HumanEvents_query
ON SERVER
ADD EVENT sqlserver.module_end
(SET collect_statement = 1
ACTION (sqlserver.database_name, sqlserver.sql_text, sqlserver.plan_handle, sqlserver.query_hash_signed, sqlserver.query_plan_hash_signed)
WHERE (
sqlserver.is_system = 0
AND duration >= 5000000
AND sqlserver.session_id = 60
)),
ADD EVENT sqlserver.rpc_completed
(SET collect_statement = 1
ACTION(sqlserver.database_name, sqlserver.sql_text, sqlserver.plan_handle, sqlserver.query_hash_signed, sqlserver.query_plan_hash_signed)
WHERE (
sqlserver.is_system = 0
AND duration >= 5000000
AND sqlserver.session_id = 60
)),
ADD EVENT sqlserver.sp_statement_completed
(SET collect_object_name = 1, collect_statement = 1
ACTION(sqlserver.database_name, sqlserver.sql_text, sqlserver.plan_handle, sqlserver.query_hash_signed, sqlserver.query_plan_hash_signed)
WHERE (
sqlserver.is_system = 0
AND duration >= 5000000
AND sqlserver.session_id = 60
)),
ADD EVENT sqlserver.sql_statement_completed
(SET collect_statement = 1
ACTION(sqlserver.database_name, sqlserver.sql_text, sqlserver.plan_handle, sqlserver.query_hash_signed, sqlserver.query_plan_hash_signed)
WHERE (
sqlserver.is_system = 0
AND duration >= 5000000
AND sqlserver.session_id = 60
)),
ADD EVENT sqlserver.query_post_execution_showplan
(
ACTION(sqlserver.database_name, sqlserver.sql_text, sqlserver.plan_handle, sqlserver.query_hash_signed, sqlserver.query_plan_hash_signed)
WHERE (
sqlserver.is_system = 0
AND duration >= 5000000
AND sqlserver.session_id = 60
))
I collect:
module_end
rpc_completed
sp_statement_completed
sql_statement_completed
query_post_execution_showplan
Not all of them are relevant to stored procedure calls, but in larger contexts where I have no idea where long running queries might be coming from, it’s useful to get all these.
Weirdness, Weirdness
Where I find things getting somewhat annoying is when things start showing up in there that meet the duration filter, but don’t really give me anything further to go on.
To simulate what I mean, I’m going to use this stored procedure:
CREATE OR ALTER PROCEDURE
dbo.Eventually
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
WAITFOR DELAY '00:00:01.000';
SELECT TOP (1) * FROM dbo.Badges AS b;
WAITFOR DELAY '00:00:01.000';
SELECT TOP (1) * FROM dbo.Comments AS c;
WAITFOR DELAY '00:00:01.000';
SELECT TOP (1) * FROM dbo.Posts AS p;
WAITFOR DELAY '00:00:01.000';
SELECT TOP (1) * FROM dbo.Users AS u;
WAITFOR DELAY '00:00:01.000';
SELECT TOP (1) * FROM dbo.Votes AS v;
WAITFOR DELAY '00:00:01.000';
END;
GO
EXEC dbo.Eventually;
There are six waitfor commands that each pause for 1 second. In between them are queries that finish in milliseconds.
If I watch the event output, eventually, I’ll see this:
lied to me, cried to me
Okay, so the stored procedure took more than 5 seconds, but… no individual query took more than 5 seconds.
To troubleshoot further, I have to set the duration bar even lower, and then figure out what I can meaningfully tune.
Do I have one query that takes four seconds
Do I have ten queries that take 500 milliseconds
Do I have 500 queries that take ten milliseconds
I see this behavior quite a bit with queries that loop/cursor over tons of data. They might take a whole bunch of rows and do a lot of really fast queries over them, but the time adds up.
There’s not really a good solution for this, either. The closer you look, by reducing the duration filter to lower and lower values, the more you return, the more overhead you cause, and the longer you have to wait for things to finish.
Sure, you can wring someone’s neck about not “thinking in sets”, but that doesn’t help when the processing takes place by passing looped values to stored procedures, unless you have the freedom to make significant app changes by using table valued parameters or something instead.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Far and away, some of the trickiest situations I run into when helping clients is rewriting scalar functions that have WHILE loops in them.
This sort of procedural code is often difficult, but not impossible, to replace with set-based logic.
Sure, lots of IF/THEN/ELSE stuff can be tough too, though that’s often easier to manage with CASE expressions in stacked CTEs or derived tables.
I ran across a really interesting function recently that I had to rewrite that had a couple WHILE loops in it, and I’ve simplified the example here to show my approach to fixing it.
Table Face
The original intent of the function was to do some string manipulation and return a cleaned version of it.
There were several loops that looked for “illegal” characters, add in formatting characters (like dashes), etc.
The bad way of doing this is like so. If you write functions like this, feel bad. Let it burn a little.
Ten years ago, I’d understand. These days, there’s a billion blog posts about why this is bad.
CREATE OR ALTER FUNCTION
dbo.CountLetters_Bad
(
@String varchar(20)
)
RETURNS bigint
AS
BEGIN
DECLARE
@CountLetters bigint = 0,
@Counter int = 0;
WHILE
LEN(@String) >= @Counter
BEGIN
IF PATINDEX
(
'%[^0-9]%',
SUBSTRING
(
@String,
LEN(@String) - @Counter,
1
)
) > 0
BEGIN
SET @CountLetters += 1;
SET @Counter += 1;
END;
ELSE
BEGIN
SET @Counter += 1;
END;
END;
RETURN @CountLetters;
END;
GO
SELECT
CountLetters =
dbo.CountLetters_Bad('1A1A1A1A1A');
Better Way
This is a better way to write this specific function. It doesn’t come with all the baggage that the other function has.
But the thing is, if you just test them with the example calls at the end, you wouldn’t nearly be able to tell the difference.
CREATE OR ALTER FUNCTION
dbo.CountLetters
(
@String AS varchar(20)
)
RETURNS table
AS
RETURN
WITH
t AS
(
SELECT TOP(LEN(@String))
*,
s =
SUBSTRING
(
@String,
n.Number +1,
1
)
FROM dbo.Numbers AS n
)
SELECT
NumLetters =
COUNT_BIG(*)
FROM t
WHERE PATINDEX('%[^0-9]%', t.s) > 0;
GO
SELECT
cl.*
FROM dbo.CountLetters('1A1A1A1A1A') AS cl;
Pop Quiz Tomorrow
This is a problem I run into a lot: developers don’t really test SQL code in ways that are realistic to how it’ll be used.
Look, this scalar UDF runs fine for a single value
Look, this view runs fine on its own
Look, this table variable is great when I pass a test value to it
But this is hardly the methodology you should be using, because:
You’re gonna stick UDFs all over huge queries
You’re gonna join that view to 75,000 other views
You’re gonna let users pass real values to table variables that match lots of data
In tomorrow’s post, I’m gonna show you an example of how to better test code that calls functions, and what to look for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
SetOptions = SUBSTRING(
CASE WHEN (CAST(pa.value AS INT) & 1 = 1) THEN ', ANSI_PADDING' ELSE '' END +
CASE WHEN (CAST(pa.value AS INT) & 8 = 8) THEN ', CONCAT_NULL_YIELDS_NULL' ELSE '' END +
CASE WHEN (CAST(pa.value AS INT) & 16 = 16) THEN ', ANSI_WARNINGS' ELSE '' END +
CASE WHEN (CAST(pa.value AS INT) & 32 = 32) THEN ', ANSI_NULLS' ELSE '' END +
CASE WHEN (CAST(pa.value AS INT) & 64 = 64) THEN ', QUOTED_IDENTIFIER' ELSE '' END +
CASE WHEN (CAST(pa.value AS INT) & 4096 = 4096) THEN ', ARITH_ABORT' ELSE '' END +
CASE WHEN (CAST(pa.value AS INT) & 8192 = 8191) THEN ', NUMERIC_ROUNDABORT' ELSE '' END
, 2, 200000)
Based on that, I was hopeful that I could use a combination of SSMS and session settings to figure out where bits flip in client options.
I don’t think I got all of them, but this simple demo shows off the ones that were accessible. Some caveats here:
No one at Microsoft has validated these
They might change in the future
There are probably ones I missed
Ring Toss
Here’s what I came up with, using my own experimenting, and also some test data from deadlock XML files I had sitting around.
CREATE TABLE
#temptable
(
clientoption1 bigint,
clientoption2 bigint
);
INSERT INTO
#temptable
(
clientoption1,
clientoption2
)
VALUES
(536870944, 128056),
(671088672, 128056),
(671088672, 128058),
(673185824, 128056),
(673316896, 128056);
SELECT
q.clientoption1,
q.clientoption2,
clientoption1 =
SUBSTRING
(
CASE WHEN q.clientoption1 & 0x20 = 0x20 THEN ', QUOTED IDENTIFIER ON' ELSE '' END +
CASE WHEN q.clientoption1 & 0x40 = 0x40 THEN ', ARITHABORT' ELSE '' END +
CASE WHEN q.clientoption1 & 0x800 = 0x800 THEN ', USER SET ARITHABORT' ELSE '' END +
CASE WHEN q.clientoption1 & 0x8000 = 0x8000 THEN ', NUMERIC ROUNDABORT ON' ELSE '' END +
CASE WHEN q.clientoption1 & 0x10000 = 0x10000 THEN ', USER SET NUMERIC ROUNDABORT ON' ELSE '' END +
CASE WHEN q.clientoption1 & 0x20000 = 0x20000 THEN ', SET XACT ABORT ON' ELSE '' END +
CASE WHEN q.clientoption1 & 0x80000 = 0x80000 THEN ', NOCOUNT OFF' ELSE '' END +
CASE WHEN q.clientoption1 & 0x200000 = 0x200000 THEN ', NOCOUNT ON' ELSE '' END +
CASE WHEN q.clientoption1 & 0x8000000 = 8000000 THEN ', USER SET QUOTED IDENTIFIER' ELSE '' END +
CASE WHEN q.clientoption1 & 0x20000000 = 0x20000000 THEN ', ANSI NULL DEFAULT ON' ELSE '' END +
CASE WHEN q.clientoption1 & 0x40000000 = 0x40000000 THEN ', ANSI NULL DEFAULT OFF' ELSE '' END,
3,
8000
),
clientoption2 =
SUBSTRING
(
CASE WHEN q.clientoption2 & 2 = 2 THEN ', IMPLICIT TRANSACTION' ELSE '' END +
CASE WHEN q.clientoption2 & 8 = 8 THEN ', ANSI WARNINGS' ELSE '' END +
CASE WHEN q.clientoption2 & 0x10 = 0x10 THEN ', ANSI PADDING' ELSE '' END +
CASE WHEN q.clientoption2 & 0x20 = 0x20 THEN ', ANSI NULLS' ELSE '' END +
CASE WHEN q.clientoption2 & 0x1000 = 0x1000 THEN ', USER CONCAT NULL YIELDS NULL' ELSE '' END +
CASE WHEN q.clientoption2 & 0x2000 = 0x2000 THEN ', CONCAT NULL YIELDS NULL' ELSE '' END +
CASE WHEN q.clientoption2 & 0x4000 = 0x4000 THEN ', USER ANSI NULLS' ELSE '' END +
CASE WHEN q.clientoption2 & 0x8000 = 0x8000 THEN ', USER ANSI WARNINGS' ELSE '' END,
3,
8000
)
FROM #temptable AS q;
I may work on getting these into some deadlock analysis tooling after I have a little more validation that the results are correct.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
If the Gods of post scheduling cooperate, this should publish on October 3rd. That means you’ve got a little more than a month to buy tickets and book travel to PASS.
Searching the internet for every problem isn’t cutting it.
You need to be more proactive and efficient when it comes to finding and solving database performance fires. I work with consulting customers around the world to put out SQL Server performance fires.
In this day of learning, I will teach you how to find and fix your worst SQL Server problems using the same modern tools and techniques which I use every week.
You’ll learn tons of new and effective approaches to common performance problems, how to figure out what’s going on in your query plans, and how indexes really work to make your queries faster.
Together, we’ll tackle query rewrites, batch mode, how to design indexes, and how to gather all the information you need to analyze performance.
This day of learning will teach you cutting edge techniques which you can’t find in training by folks who don’t spend time in the real world tuning performance.
Performance tuning mysteries can easily leave you stumbling through your work week, unsure if you’re focusing on the right things.
You’ll walk out of this class confident in your abilities to fix performance issues once and for all.
If you want to put out SQL Server performance fires, this is the precon you need to attend. Anyone can have a plan, it takes a professional to have a blueprint.
In-person attendees will also get a cool t-shirt. Arguably the coolest t-shirt ever made for a SQL Server conference.
big eight
Dates And Times
The PASS Data Community Summit is taking place in Seattle November 15-18, 2022 and online.
You can register here, to attend online or in-person. I’ll be there in all my fleshy goodness, and I hope to see you there too!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
Defining things scares people. Pause for a moment to think about how many scripts have been written where some roustabout has a mental breakdown when someone refers to them as a boyfriend or girlfriend.
Table definitions have a similar effect on developers. In today’s post, I’m going to use temp tables as an example, but the same thing can happen with regular tables, too.
The issue isn’t with NULL values themselves, of course. The table definition we’re going to use will allow NULLs, but no NULLs will be present in the data.
The issue is with how you query NULLable columns, even when no NULLs are present.
Let’s take a look!
Insecure
Let’s create a temporary table that allows for NULLs, and fill it with all non-NULL values.
CREATE TABLE
#comment_sil_vous_plait
(
UserId int NULL
);
INSERT
#comment_sil_vous_plait WITH(TABLOCK)
(
UserId
)
SELECT
c.UserId
FROM dbo.Comments AS c
WHERE c.UserId IS NOT NULL;
Unfortunately, this is insufficient for SQL Server’s optimizer down the line when we query the table.
But we need one more table to round things out.
Brilliant
This temporary table will give SQL Server’s optimizer all the confidence, temerity, and tenacity that it needs.
CREATE TABLE
#post_sil_vous_plait
(
OwnerUserId int NOT NULL
);
INSERT
#post_sil_vous_plait WITH(TABLOCK)
(
OwnerUserId
)
SELECT
p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.OwnerUserId IS NOT NULL;
Just three tiny letters. N-O-T.
That’s all it takes.
The Queries
If you’ve been hanging around SQL Server for long enough, you’re probably aware of what happens when you use NOT IN and encounter NULL values in your tables.
It says “nope” and gives you an empty result (or a NULL result!) because you can’t match values to NULLs that way.
SELECT
c = COUNT_BIG(*)
FROM #post_sil_vous_plait AS psvp
WHERE psvp.OwnerUserId NOT IN
(
SELECT
csvp.UserId
FROM #comment_sil_vous_plait AS csvp
);
SELECT
c = COUNT_BIG(*)
FROM #post_sil_vous_plait AS psvp
WHERE NOT EXISTS
(
SELECT
1/0
FROM #comment_sil_vous_plait AS csvp
WHERE csvp.UserId = psvp.OwnerUserId
);
But since we have no NULLs, well, we don’t have to worry about that.
But we do have to worry about all the stuff SQL Server has to do to see if any NULLs come up.
The Plans
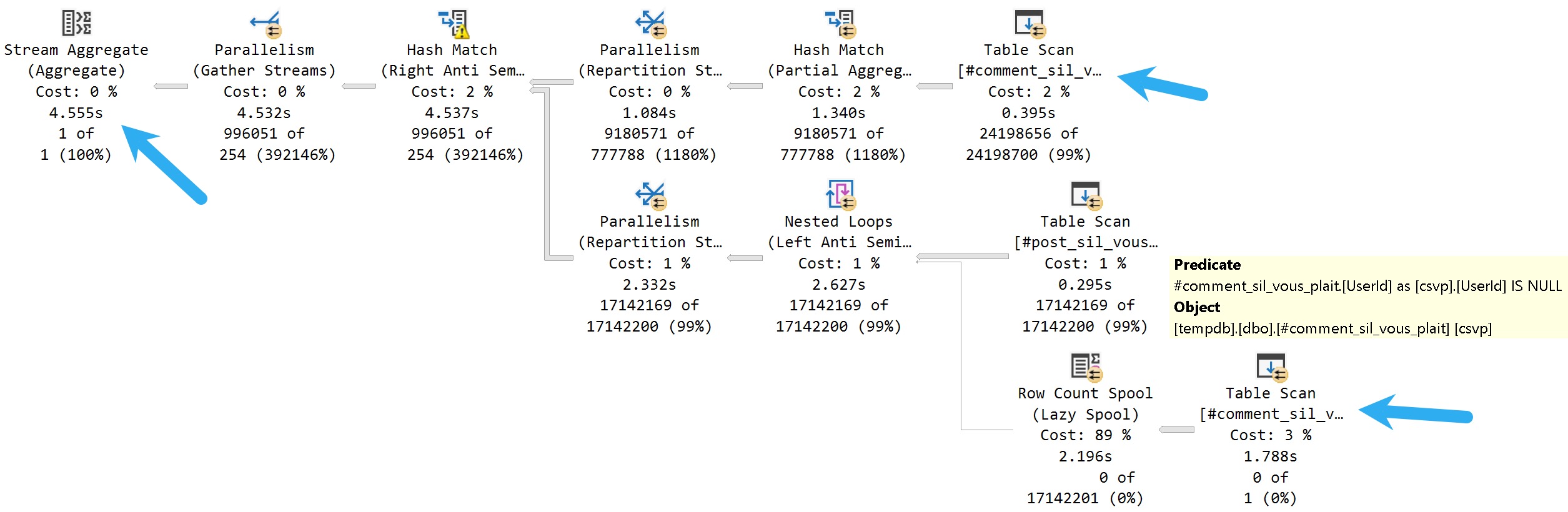
For the NOT IN query, which runs about 4.5 seconds, there are two separate scans of the #comments table.
yuck
Most of this query plan is expected. There’s a scan of #comments, a scan of #posts, and a hash join to bring them together.
But down below, there’s an additional branch with a row count spool, and a predicate applied to the scan looking for NULL values. The spool doesn’t return data, it’s just there to look for a NULL value and bail the query out if it finds one.
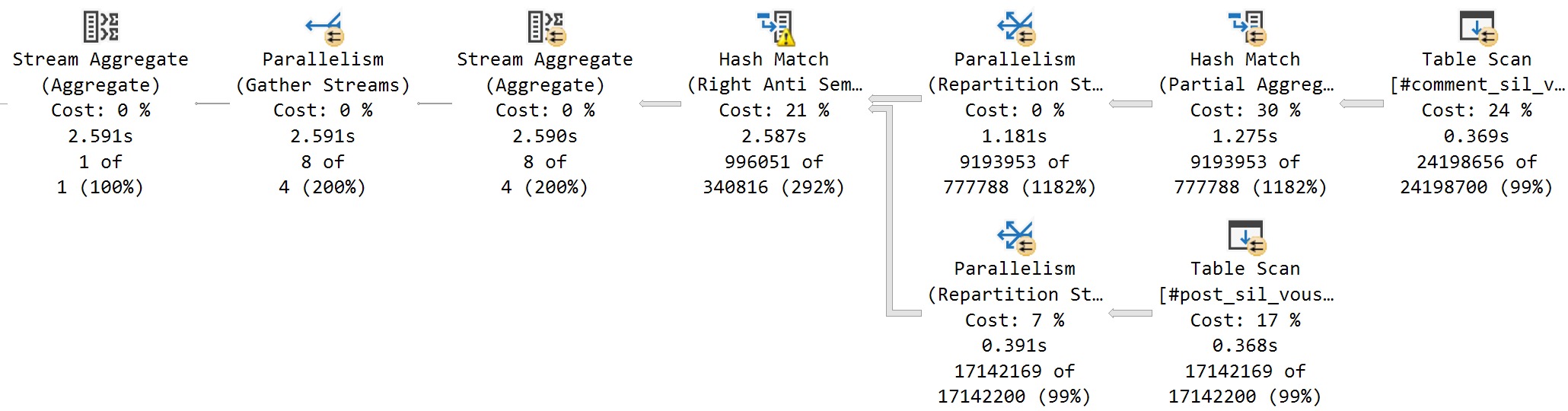
For the NOT EXISTS query, which finishes in 2.5 seconds, we have all the expected parts of the above query plan, but without the spool.
flawless
You could partially solve performance issues in both queries by sticking a clustered index on both tables.
If you’re into that sort of thing (I am).
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.