Easy Thinking
To start with, let’s classify functions into two varietals:
- Ones built-in to SQL Server
- Ones that developers write
Of those, built-in functions are pretty much harmless when they’re in the select list. Classifying things a bit further for the ones user writes, we have:
- Scalar User Defined Functions
- Multi-Statement Table Valued Functions
- Inline Table Valued Functions
- CLR Functions
Out of the four up there, only the last one doesn’t have a reference link. Why? Because I don’t write C# — I’m not that smart — if you need someone smart about that, go read my friend Josh’s blog. He’s quite capable.
If you’re too lazy to go read the three reference links:
- Scalar User Defined Functions generally wreck performance
- Multi-Statement Table Valued Functions stand a high chance of generally wrecking performance
- Inline Table Valued Functions are okay as long as you don’t do anything awful in them
Smart Thinking
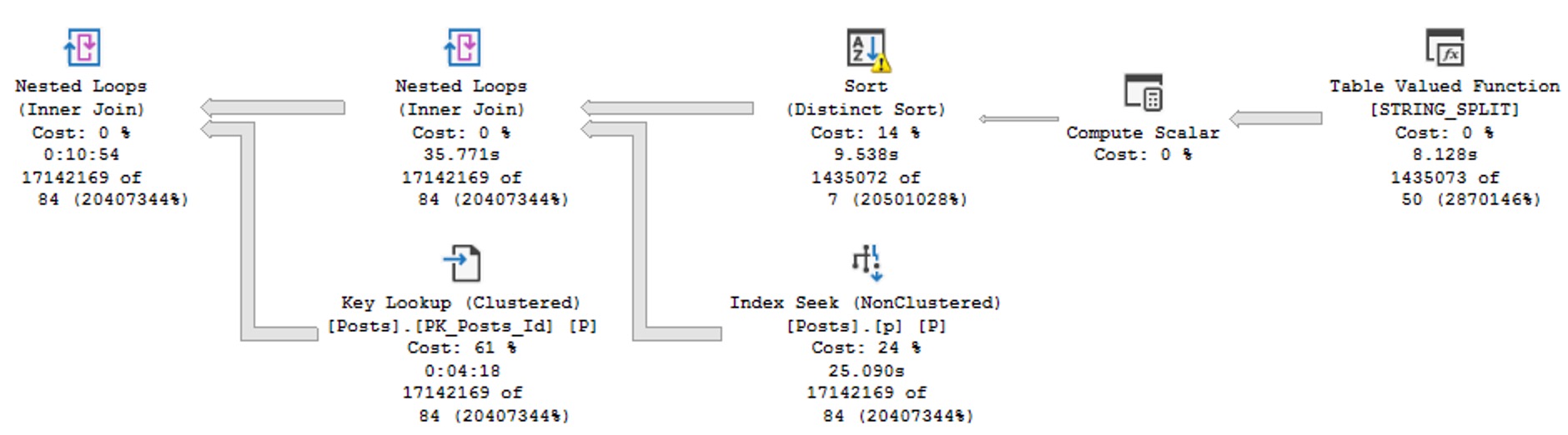
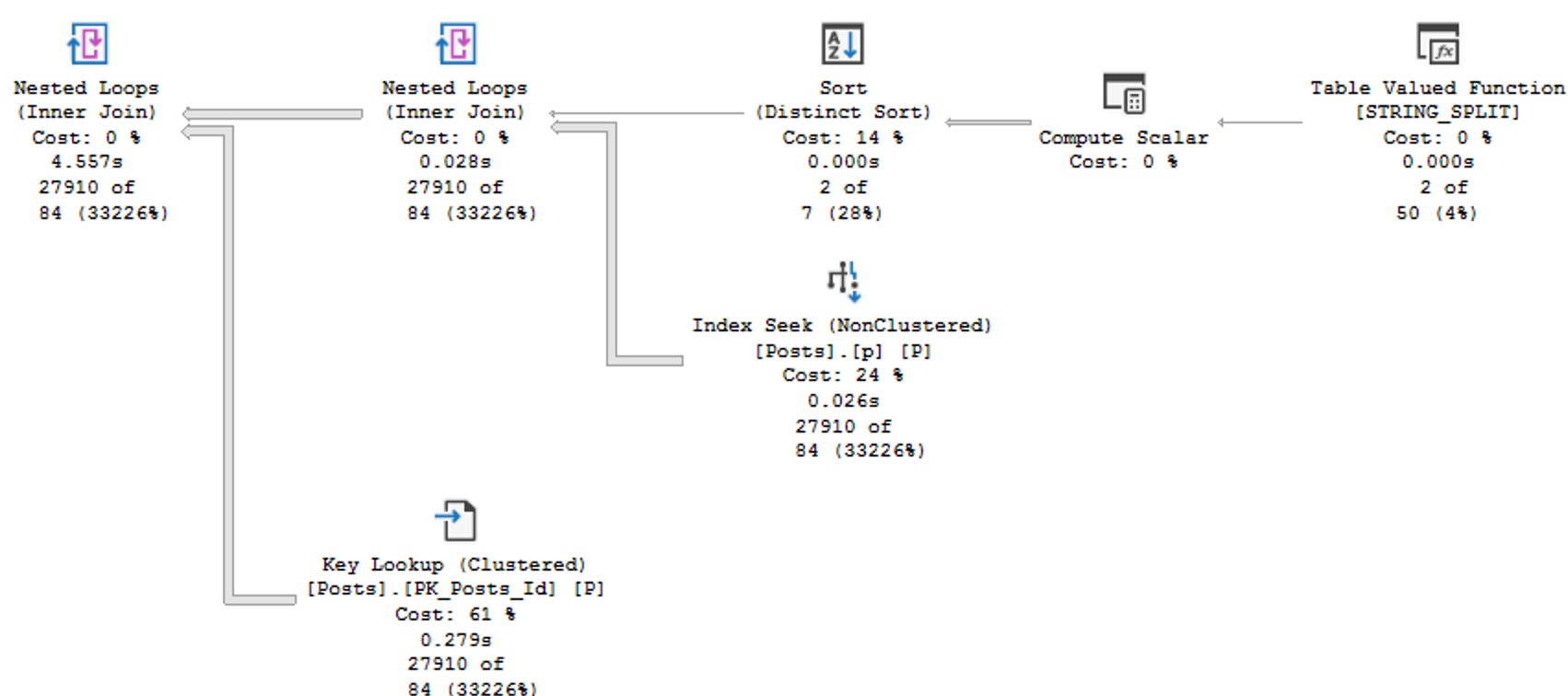
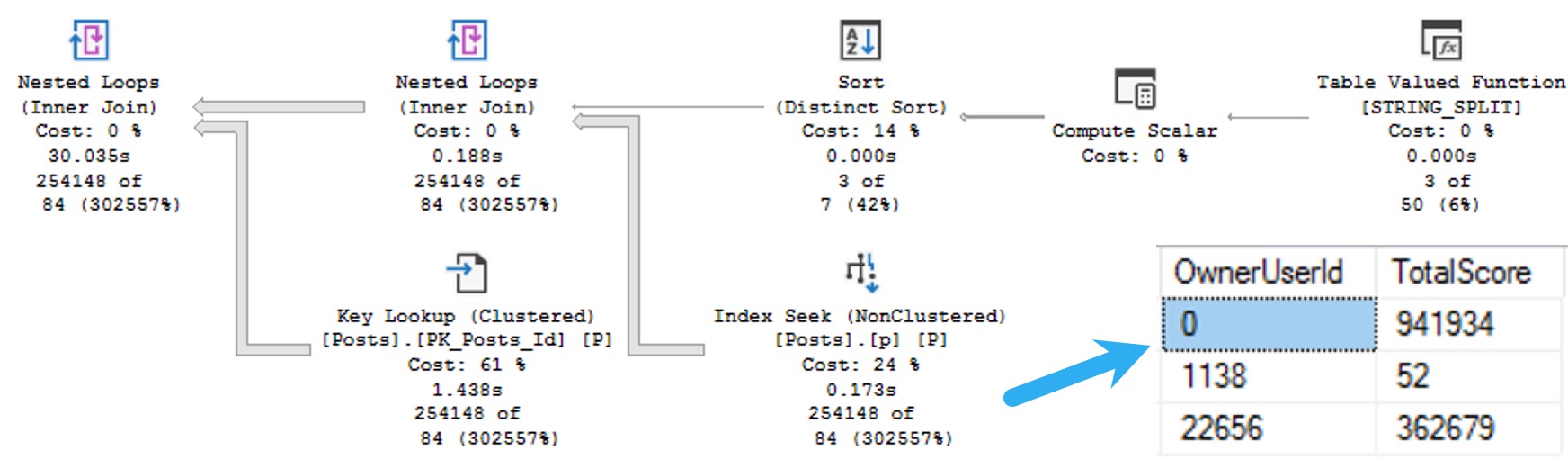
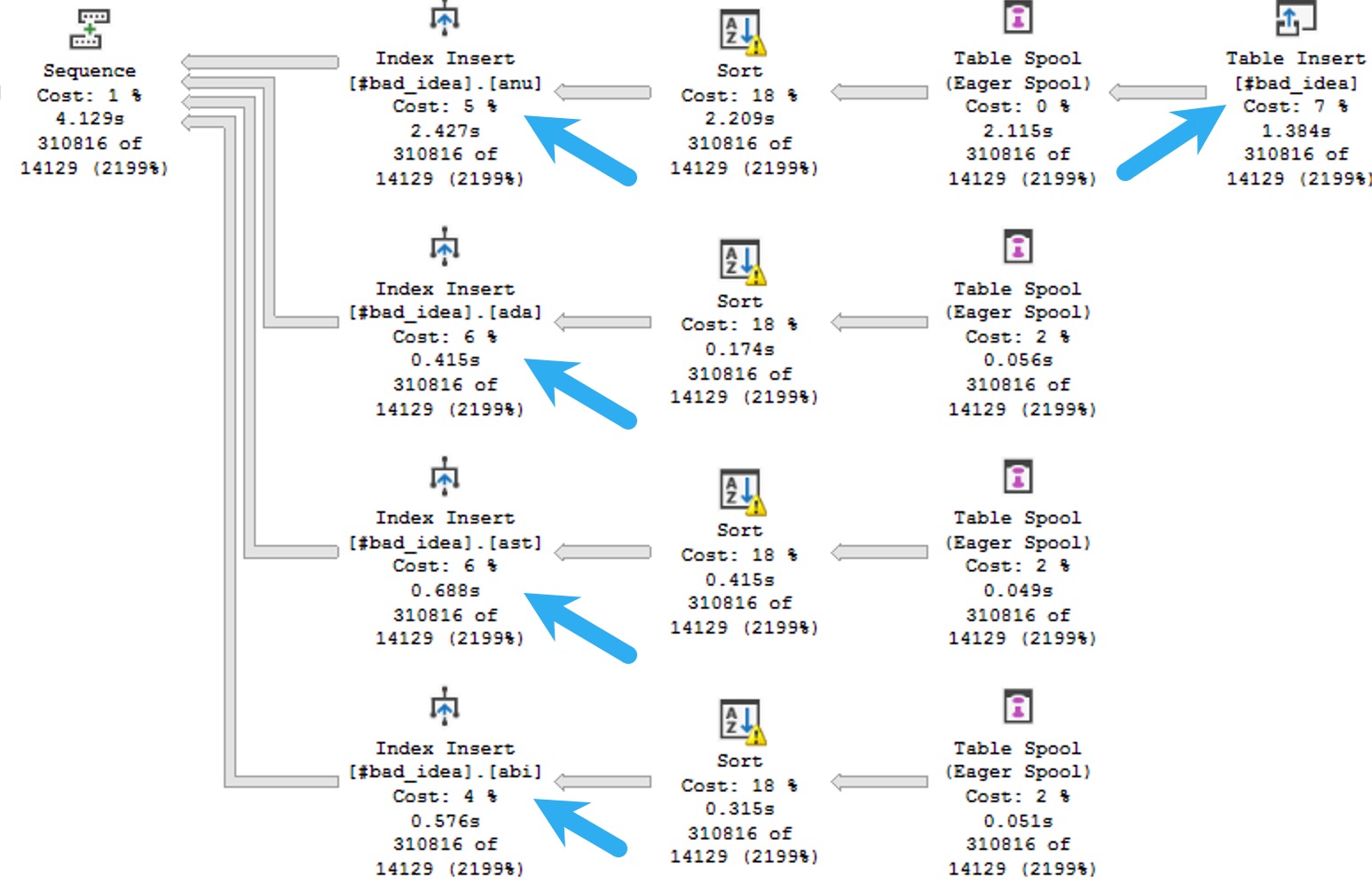
The important thing to understand is that using any of these functions, let’s call it below the belt, can really mess things up for query performance in new and profound ways compared to what they can do in just the select list.
To be more specific for you, dear developer reader, let’s frame below the belt as anything underneath the from clause. Things here get particularly troublesome, because much of the activity here is considered relational, whereas stuff up above is mostly just informational.
Why is the relational stuff a much bigger deal than the informational stuff? Because that’s where all the math happens in a query plan, and SQL Server’s optimizer decides on all sorts of things at compile-time, like:
- Which indexes to use
- Join order
- Join types
- Memory grants
- Parallelism
- Seeks and Scans
- Aggregate types
- Much, much more!
Those things are partially based on how well it’s able to estimate the number of rows that join and where conditions will produce.
Sticking functions in the way of those join and where conditions is a bit like putting a blindfold on SQL Server’s optimization and cardinality estimation process and asking it to swing a bowling ball sharp saber at a piece of confetti at 100 paces.
In other words, don’t complain when your query plans suck and your queries run slow. You’re doing the hobbling, you dirty bird.
Future Thinking
If you want your customers, users, or whatever you want to call them, to be reliably happy in the future, even as their database sizes grow beyond your wildest imagination, and your application gets used in ways that would make Caligula blush, you need to start by obeying the first law of database physics: thou shalt not get in the way of the optimizer.
Going back to a couple other laws of database physics that cannot be ignored:
- Anything that makes your job easier makes the optimizer’s job harder
- Store data the way you query it, and query data the way you store it
If it makes you feel better, stick a few thous and shalls or shalt nots or whences or whenceforths in there. It might make you happier.
It will make your customers, users, or whatever you want to call them happier, if you listen to me.
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.