Award Winning
Imagine you have a rather complicated query that you want to abstract into a simple query for your less-than-with-it end users.
A view is probably a pretty good way of doing that, since you can shrink your preposterously-constructed tour through every table in the schema down to a simple select-from-one-object.
The problem is that now everyone expects it to perform well throughout all time, under any circumstances, come what may. It’s sort of like how your parents expect dinner to be $20 and tips to be 20% regardless of where they go or what they order.
- Lobster? $5.
- Steak? $5.
- Bottle of wine? $5.
- Any dessert you can imagine? $5.
- Tip? Gosh, mister, another $5?
I sincerely apologize to anyone who continues to live in, or who moved to Europe to avoid tipping.
If you’d like some roommates, I have some parents you’d get along with.
Viewfinder
Creating a view in SQL Server doesn’t do anything special for you, outside of not making people remember your [reference to joke above] query.
You can put all manner of garbage in your view, make it reference another half dozen views full of garbage, and expect sparkling clean query performance every time.
Guess what happens?
Reality.
When you use views, the only value is abstraction. You still need to be concerned with how the query is written, and if the query has decent indexes to support it. In other words, you can’t just write a view and expect the optimizer to do anything special with it.
SQL Server doesn’t cache results, it only caches raw data. If you want the results of a view to be saved, you need to index it.
Take these two dummy queries, one against a created view, and the other an ad hoc query identical to what’s in the view:
CREATE OR ALTER VIEW
dbo.just_a_query
WITH SCHEMABINDING
AS
SELECT
p.OwnerUserId,
TotalScore =
ISNULL
(
SUM(p.Score),
0
),
TotalPosts =
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE
v.PostId = p.Id
)
GROUP BY
p.OwnerUserId;
GO
SELECT
p.OwnerUserId,
TotalScore =
ISNULL
(
SUM(p.Score),
0
),
TotalPosts =
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE EXISTS
(
SELECT
1/0
FROM dbo.Votes AS v
WHERE
v.PostId = p.Id
)
AND
p.OwnerUserId = 22656
GROUP BY
p.OwnerUserId;
GO
SELECT
jaq.*
FROM dbo.just_a_query AS jaq
WHERE
jaq.OwnerUserId = 22656;
GO
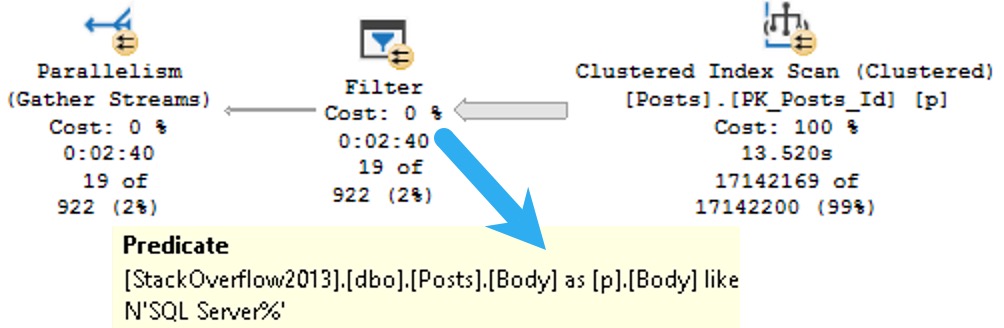
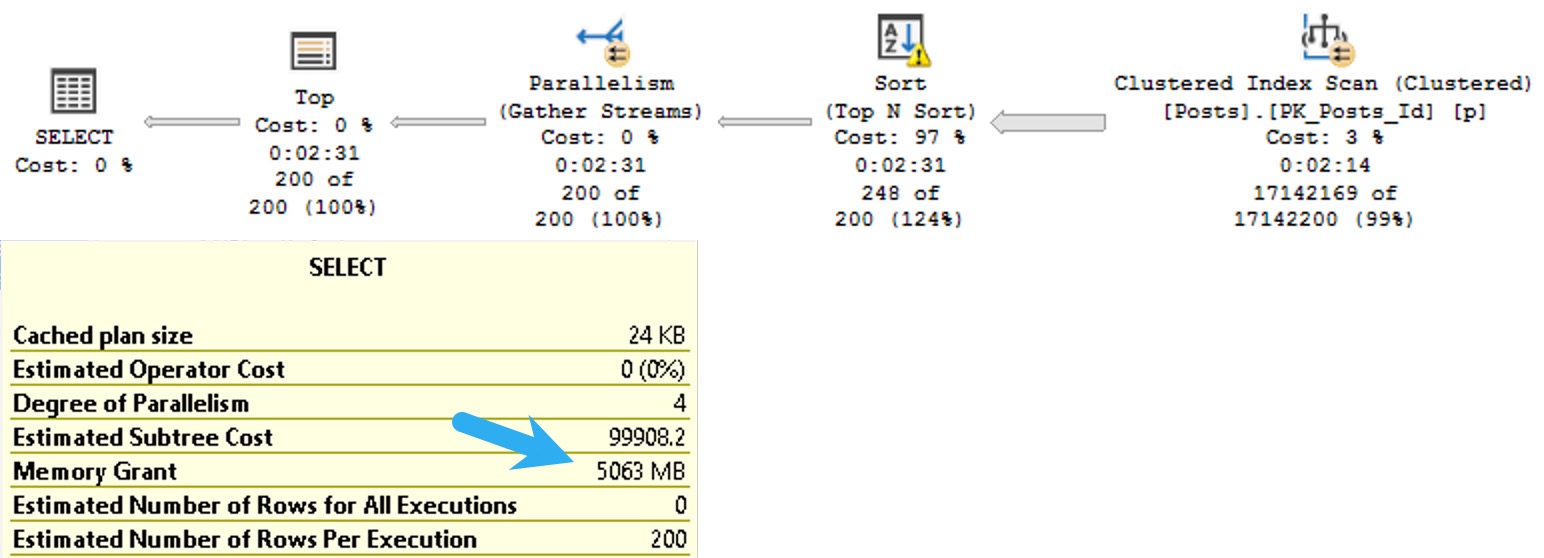
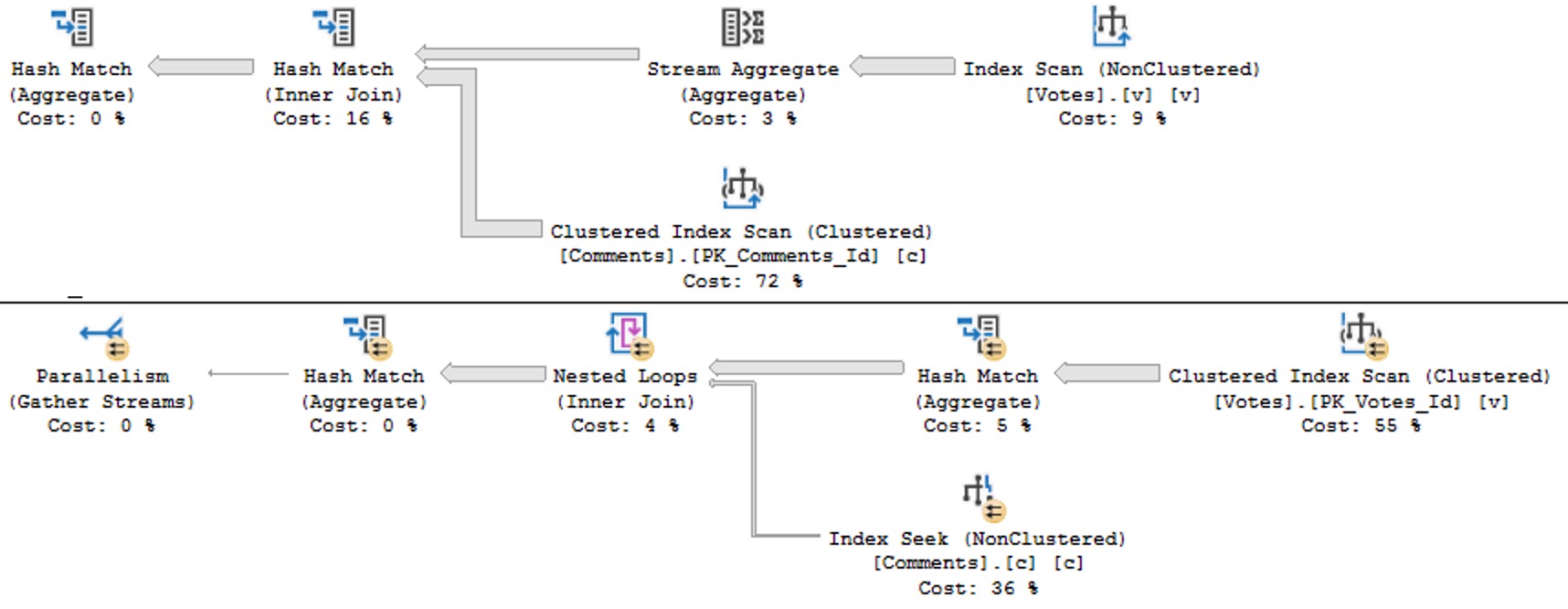
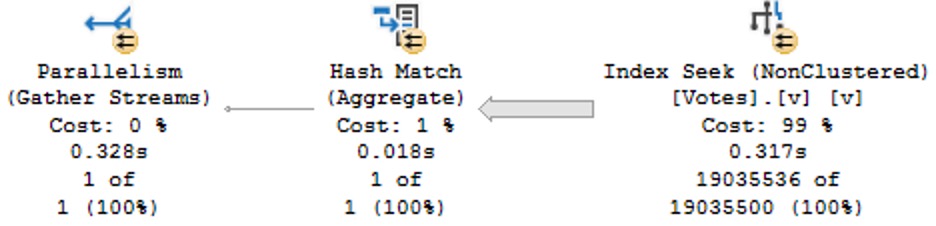
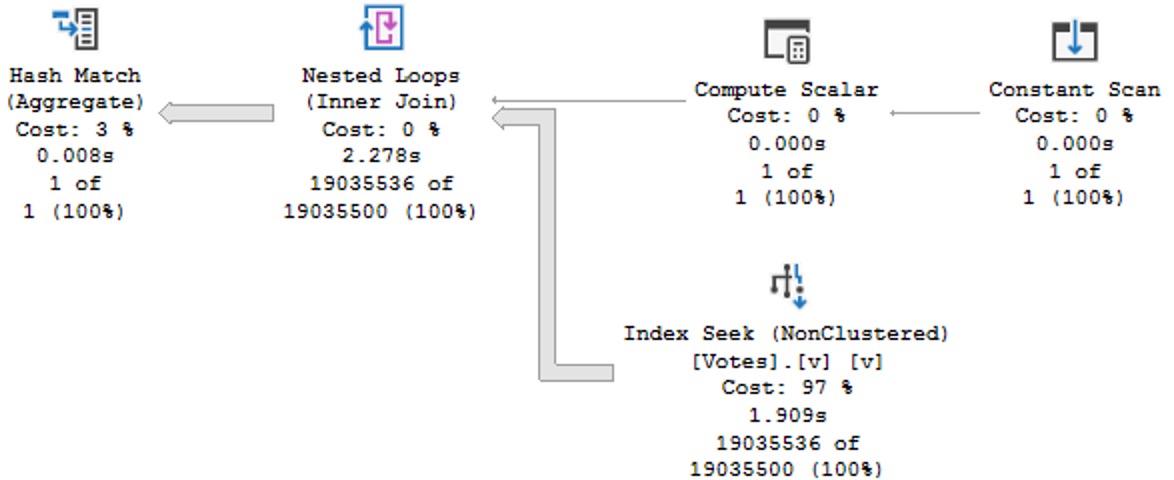
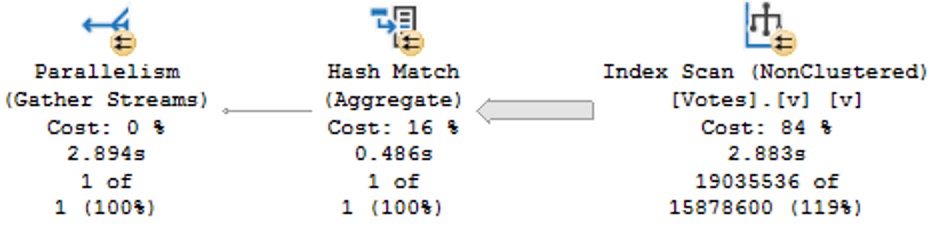
The plans are identical, and identically bad. Why? Because I didn’t try very hard, and there’s no good indexes for them.
Remember when I said that’s important?
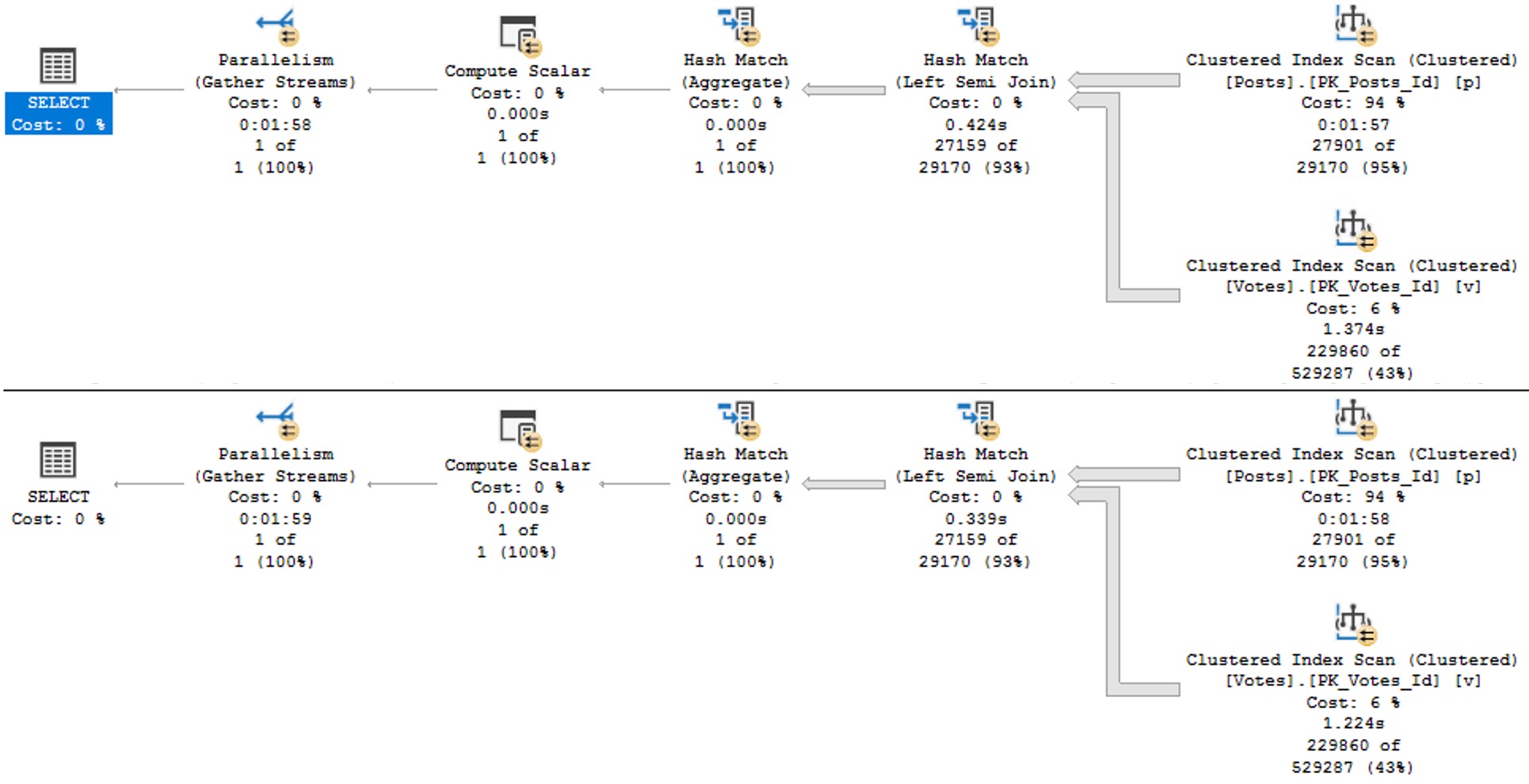
Keep in mind this is a query with some batch mode involved, so it could be a lot worse. But both instances complete within a second or so of each other.
So much for view performance.
Maintainer
The rules around indexed views are pretty strict, and the use cases are fairly narrow. I do find them quite useful on SQL Server Standard Edition where batch mode is terribly hobbled.
The horrible thing is that indexed views are so strict in SQL Server that we can’t even create one on the view in question. That really sucks. We get this error.
CREATE UNIQUE CLUSTERED INDEX
cuqadoodledoo
ON dbo.not_just_a_query
(
OwnerUserId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
Msg 10127, Level 16, State 1, Line 95
Cannot create index on view “StackOverflow2013.dbo.not_just_a_query” because it contains one or more subqueries.
Consider changing the view to use only joins instead of subqueries. Alternatively, consider not indexing this view.
Alternatively, go screw yourself. Allowing joins but not exists is somewhat baffling, since they’re quite different in that joins allow for multiple matches but exists does not. We’d have to do a lot of fancy grouping footwork to get equivalent results with a join, since distinct isn’t allowed in an indexed view in SQL Server either.
We could also pull the exists out of the view, add the Id column to the select list, group by that and OwnerUserId, index both of them, and… yeah nah.
I have no idea who’s in charge of indexed views in the product at this point, but a sufficiently lubricated republic would likely come calling with tar and feathers in the face of this injustice.
This is basic query syntax. It’s not like uh… min, max, sum, avg, except, intersect, union, union all, cross apply, outer apply, outer joins, or um, hey, is it too late for me to change careers?
The Pain In Pain Falls Painly On The Pain
You may have ended up here looking to learn all the minute differences between views and indexed views in SQL Server.
You may be disappointed in reading this post, but I can assure you that you’re not nearly as disappointed in this post as I am with indexed views in SQL Server.
They’re like one of those articles about flying cars where you read the headline and you’re like “woah, I’m living in the future”, but then three paragraphs in you find out the cars don’t really fly or drive and they might actually just be igloos that are only big enough for an Italian Greyhound or a paper plane that the author’s kid glued wheels to.
If you actually have a use case for indexed views, you’ll have to be really careful about making sure their maintenance doesn’t kill performance.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.