Quite a bit, I find myself working with people who are able to change indexes, but unable to change queries.
Even making small, sane changes would nix their support, should they ask for it. I do sometimes have to laugh at the situation: if support were that great, they wouldn’t need me, and if we made the change, they probably wouldn’t need support.
Oh well, though. Keep me employed, ISVs.
When we are allowed to change indexes, sometimes we can fix problems enough to avoid needing to change the code.
Big Time
Let’s start by creating two different indexes. They have the same key columns, just in different order.
CREATE INDEX v ON dbo.Votes
(UserId, CreationDate);
CREATE INDEX vv ON dbo.Votes
(CreationDate, UserId);
The query that we care about it this one:
SELECT
c = COUNT_BIG(*)
FROM dbo.Votes AS v
WHERE ISNULL(v.UserId, 0) > 0
AND v.CreationDate >= '20180601';
I know, you’re smart, you’re savvy, you’d never write a query like this. But I see it constantly.
Daring
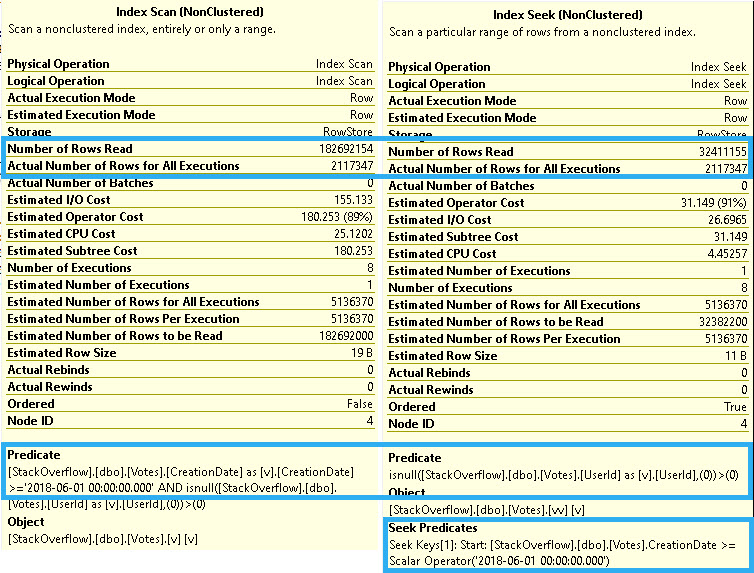
If we compare query performance using the two different nonclustered indexes, the one that leads with CreationDate is the clear winner.
swished up
Bookends
The main advantage of a Seek here is we’re able to seek to a much smaller range of rows first, and then apply the non-SARGable predicate to UserId.
no touching
Obviously, scanning 182,692,000 rows is a bit slower than seeking to 32,411,155 rows and applying the residual predicate.
Tomorrows
If you can rewrite queries like this, you absolutely should. That people still write queries like this is a sad testament to… Well, I’m not sure what.
In tomorrow’s post, we’ll look at how dynamic SQL can help ward off non-SARGable predicates.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This post is especially interesting because it highlights the oddball performance situations you can run into when you write the type of All-In-One™ queries that the optimizer is typically not very good at handling, and also rely on expressions calculated at runtime as predicates.
I mean, it’s especially interesting if you’re into this sort of thing. If you’re not into this sort of thing, you’ll probably find it as interesting as I find posts about financial responsibility or home cooking.
I’ve seen query patterns like this while working with clients, and they’ve always ended poorly.
Anyway, on with the post!
Skeletons
To make sure we have a good starting point, and you can’t tell me that “scanning the clustered index is bad”, let’s create an index:
CREATE INDEX p
ON dbo.Posts
(OwnerUserId, Score DESC)
INCLUDE
(PostTypeId)
WHERE PostTypeId IN (1, 2);
Now let’s take a look at this query, and what gets weird with it.
WITH top_questions AS
(
SELECT
p.OwnerUserId,
QuestionScore =
p.Score,
tq =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.Score > 1
),
top_answers AS
(
SELECT
p.OwnerUserId,
AnswerScore =
p.Score,
ta =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.Score > 1
)
SELECT TOP (1000)
tq.OwnerUserId,
tq.QuestionScore,
ta.AnswerScore
FROM top_questions AS tq
JOIN top_answers AS ta
ON tq.OwnerUserId = ta.OwnerUserId
AND tq.tq = ta.ta
ORDER BY
tq.QuestionScore DESC,
ta.AnswerScore DESC;
The non-SARGable portion is, of course, generating and joining on the row_number function. Since it’s an expression that gets calculated at runtime, we have to do quite a bit of work to execute this query.
Community Board
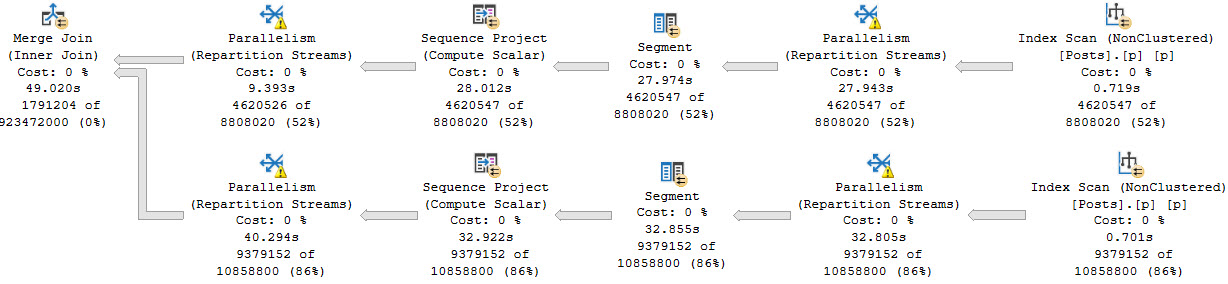
The query plan for this is all over the place, and also bad. Parallel merge joins were a mistake.
planetary
The portions of the query plan that are particularly interesting — again, if you’re into this sort of thing — is that there are four Repartition Streams operators, and all of them spill. Like I said above, this is the sort of thing you open yourself up to when you write queries like this.
In all, the query runs for about 50 seconds. This can be avoided by hinting a hash join, of course, for reasons explained here.
But good luck figuring out why this thing runs for 50 seconds looking at a cached, or estimated execution plan, which doesn’t show you spills or operator times.
Breakup
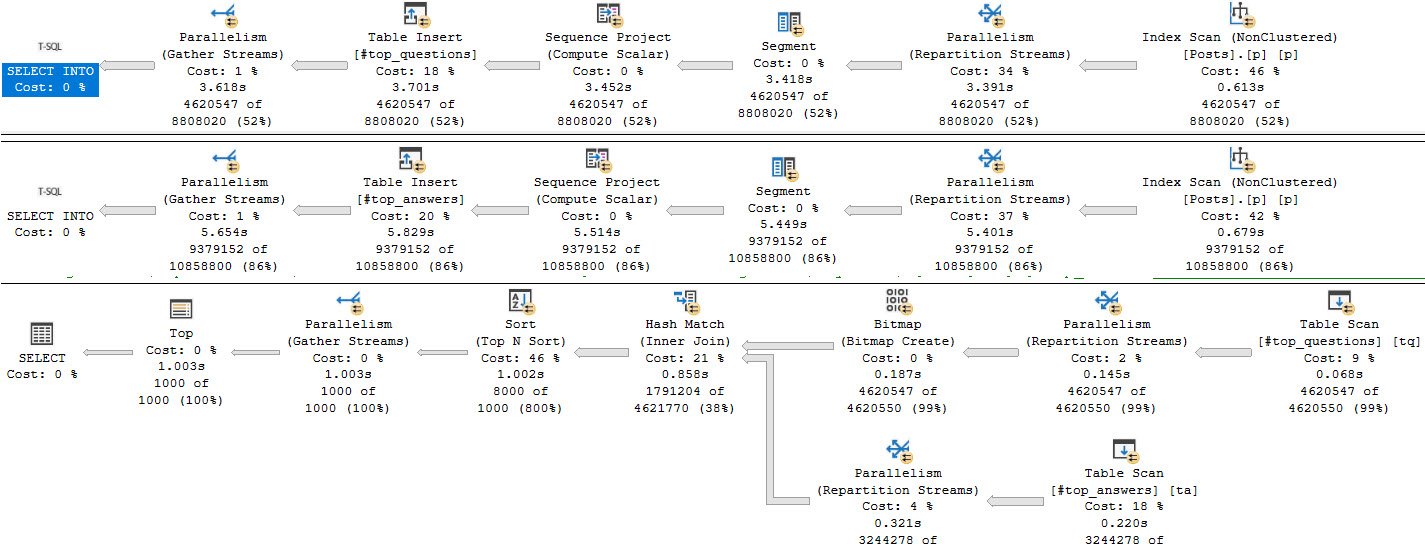
One way to avoid the situation is to materialize the results of each CTE in a #temp table, and join those together.
WITH top_questions AS
(
SELECT
p.OwnerUserId,
QuestionScore =
p.Score,
tq =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.PostTypeId = 1
AND p.Score > 1
)
SELECT
*
INTO #top_questions
FROM top_questions;
WITH top_answers AS
(
SELECT
p.OwnerUserId,
AnswerScore =
p.Score,
ta =
ROW_NUMBER() OVER
(
PARTITION BY
p.OwnerUserId
ORDER BY p.Score DESC
)
FROM dbo.Posts AS p
WHERE p.PostTypeId = 2
AND p.Score > 1
)
SELECT
*
INTO #top_answers
FROM top_answers;
SELECT TOP (1000)
tq.OwnerUserId,
tq.QuestionScore,
ta.AnswerScore
FROM #top_questions AS tq
JOIN #top_answers AS ta
ON tq.OwnerUserId = ta.OwnerUserId
AND tq.tq = ta.ta
ORDER BY
tq.QuestionScore DESC,
ta.AnswerScore DESC;
Breakdown
The end result takes about 10 seconds, and has no exchange spills.
fully
Infinito
For completeness, hinting the query with a hash join results in just about the same execution time as the temp table rewrite at 10 seconds. There are also very strong benefits to using Batch Mode. The query as originally written, and with no hints, finishes in about two seconds with no exchange spills, and I absolutely love that.
In tomorrow’s post, we’ll look at how we can sometimes adjust index key column order to solve SARGability issues.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
We’re going to start this week off by using a computed column to fix a non-SARGable query, because there are a few interesting side quests to the scenario.
Here’s the starting query, which has a few different problems:
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE LEN(p.Body) < 200
AND p.PostTypeId IN (1, 2);
Let’s say we’re doing this to audit short questions and answers for quality.
Since SQL Server doesn’t retain any precise data about string column lengths, we don’t have an effective way to implement this search.
Worse, since the Body column is a max datatype, no expression (SARGable or not) can be pushed to the index scan.
Maxed Out
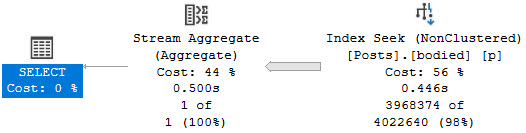
The query plan shows us a full scan of the clustered index where the filters on PostTypeId are applied, and later on a filter operator that applies the len filter:
falter
This is an ugly query, and if it’s one that we were going to make part of a regular review process, we probably don’t want users to sit around waiting 42 seconds on this every single time.
Getaround
To get this query cranking, we need to add a computed column — note that it doesn’t need to be persisted — and index it.
ALTER TABLE dbo.Posts
ADD BodyLen AS
CONVERT
(
bigint,
LEN(Body)
);
CREATE INDEX bodied ON dbo.Posts
(BodyLen, PostTypeId);
Now our query looks like this:
bettered
Prize Money
A lot of people are afraid of computed columns, because they think that they need to be persisted in order to get statistics generated on them, or to index them. You very much do not.
The persisted attribute will write the results of the expression to the clustered index or heap, which can cause lots of locking and logging and trouble.
Indexing the computed column writes the results only to the nonclustered index as it’s created, which is far less painful.
Tomorrow, we’ll look at how we can use temp tables to fix issues with SARGability.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SARGability is the in-club way of saying that a search predicate(s) can be used to seek through the key(s) of an index.
Some things that mess it up are:
function(column) = something
column + column = something
column + value = something
value + column = something
column = @something or @something IS NULL
column like ‘%something’
column = case when …
value = case when column…
Mismatching data types
Yes, this has all been written about quite a bit — here and elsewhere — but it’s a query pattern that I still spend a lot of time fixing.
So here we are. More writing about it.
If you’re sick of hearing about it, stop doing it.
Symptomatic
So let’s say we’ve got this table:
CREATE TABLE
dbo.sargability
(
id int PRIMARY KEY,
start_date date,
end_date date
);
Right now, the only index on this table is on the id column. Since it’s the clustered index (by default, since it’s the primary key), it also “includes” the start_date and end_date columns. Conversely, this also means that any nonclustered indexes we create will have the id column automatically added to them. In the case of a non-unique index, it will be in the key. In the case of a unique index, it will be in the “includes”.
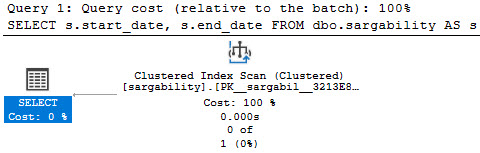
I once had someone go back and forth with me quite a bit about that last point, insisting that the clustered index didn’t have all of the table’s columns in it. But you know, if we run this query, we only touch the clustered index:
SELECT
s.start_date,
s.end_date
FROM dbo.sargability AS s;
2rock
Slippery
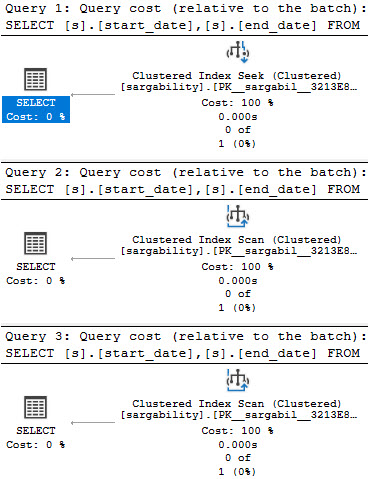
This means two things: as long as we avoid the lapses in judgement listed up above, we can seek to a single value or range of values in the id column. The index has put the data in order (in this case ascending).
It also means that start_date and end_date are not in a searchable order, so any query we write that attempts to search/filter values there will have to scan the index (unless we also search/filter the id column).
SELECT
s.start_date,
s.end_date
FROM dbo.sargability AS s
WHERE id = 1;
SELECT
s.start_date,
s.end_date
FROM dbo.sargability AS s
WHERE s.start_date = '20210808';
SELECT
s.start_date,
s.end_date
FROM dbo.sargability AS s
WHERE s.end_date = '20210808';
three times a lady
Recreation
Even though the equality predicates on start_date and end_date are perfectly SARGable, there’s no index for them to use to seek to those values in. They’re only in the clustered index, which is ordered by the id column. Other columns are not in a helpful order.
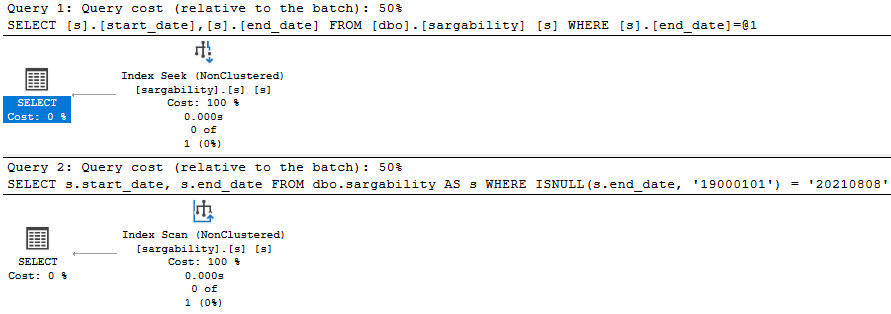
The fact that both of these queries end up scanning the clustered index may leave you under the impression that the isnull version is an acceptable practice.
SELECT
s.start_date,
s.end_date
FROM dbo.sargability AS s
WHERE s.end_date = '20210808';
SELECT
s.start_date,
s.end_date
FROM dbo.sargability AS s
WHERE ISNULL(s.end_date, '19000101') = '20210808';
But with an index on the column the problem becomes more apparent, with the “good” query seeking and the “bad” query scanning.
CREATE INDEX s ON dbo.sargability(end_date) INCLUDE(start_date);
managerial
Evidence
For the rest of the week, we’re going to look at various ways to fix non-SARGable queries with things like computed columns, temp tables, index key column order, and dynamic SQL.
These are the approaches I normally take in my query tuning work, so hopefully others will find them helpful.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I know there are other ORMs in the world, but since my working life is spent performance fixing SQL Server, I end up seeing Entity Framework the most.
This isn’t going to be an Entity Framework bash-fest (that’s what Twitter is for), it’s more a critique of the way developers blindly trust this abstraction layer to always do the smart and sensible thing.
After all, I’ve seen applications using Entity Framework quite successfully. Part of what made it successful was the developers being comfortable with the database, figuring out how what they do with code gets translated into a query, and when that ends up going terribly long.
One of the big lightbulb moments they had was realizing that maybe doing it all in one big query isn’t always the best option.
Until It Doesn’t
On small databases, perhaps with uncomplicated schema and application requirements, you can get by without giving much of a care about these things.
However, as databases grow up, more tables get added, and all that, you need to start paying more attention. I’ve said it before: abstraction isn’t magic, and that holds true for Entity Framework, too.
I totally understand: you might not know anything about databases, might not have any interest in learning more about databases, and your job is to focus on the code to develop new features. Because of that, you put your faith and trust into Entity Framework to do things the best, most correct way.
That isn’t always what happens, though. It might work, but it might not work well. Not being an Entity Framework expert, I’m not always sure if the disconnect is in the way Entity Framework is designed, or in the way the developer used it.
Funny Valentine
For transactional queries, you’ll generally be okay so long as you obey common database decency rules around table and index design.
What is usually overly-ambitious is reporting and dashboard population queries. They’re often interpreted poorly, with dozens of left joins and nested derived tables.
And look, no, I don’t expect someone coding those types of queries in Entity Framework to be able to write better T-SQL queries. They probably have even less training and experience there. I’m basically repeating myself: abstraction isn’t magic.
If you’re going to work heavily with Entity Framework code that hits SQL Server, you need to:
Get into databases
Get someone who’s into databases
You need someone who can get in there, find problem queries, review indexes, and help track down which sections of the code generate them.
Whether some portions of the application need to be replaced with stored procedures, or you write custom SQL that can take advantage of a different approach to accessing the data, you need someone with the skills to write that T-SQL well, or you’ll just end up with the same problem in a different way.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are lots of examples of how to do this with the plan cache, but, well, the plan cache can be an awfully unstable place.
Query store being a bit more historically reliable, we can use some of the same tricks to track them down there too.
SELECT
x.total_query_plans,
qsq.query_hash,
qsp.query_plan_hash,
query_plan =
TRY_CONVERT
(
xml,
qsp.query_plan
)
FROM
(
SELECT
qsq.query_hash,
distinct_query_plans =
COUNT_BIG(DISTINCT qsp.query_plan_hash),
total_query_plans =
COUNT_BIG(qsp.query_plan_hash)
FROM sys.query_store_query AS qsq
JOIN sys.query_store_plan AS qsp
ON qsq.query_id = qsp.query_id
GROUP BY
qsq.query_hash
HAVING COUNT_BIG(DISTINCT qsp.query_plan_hash) > 1
AND COUNT_BIG(DISTINCT qsp.query_plan_hash)
<= COUNT_BIG(qsp.query_plan_hash)
) AS x
CROSS APPLY
(
SELECT TOP (x.total_query_plans)
qsq.*
FROM sys.query_store_query AS qsq
WHERE x.query_hash = qsq.query_hash
) AS qsq
CROSS APPLY
(
SELECT
qsp.*
FROM sys.query_store_plan AS qsp
WHERE qsp.query_id = qsq.query_id
) AS qsp
ORDER BY
x.total_query_plans DESC;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This metric gets looked at a lot in the plan cache to see how effective it is. The main problem is that with high enough churn, you might not catch all the queries involved in the problem. Here are a couple ways to look at this in Query Store.
WITH x AS
(
SELECT
single_use_queries =
SUM
(
CASE
WHEN qsrs.count_executions = 1
THEN 1
ELSE 0
END
),
total_queries =
COUNT_BIG(*)
FROM sys.query_store_runtime_stats AS qsrs
)
SELECT
x.*,
percent_single_use_plans =
CONVERT
(
decimal(5,2),
single_use_queries /
(
1. *
NULLIF
(
x.total_queries,
0
)
) * 100.
)
FROM x;
SELECT
qsqt.query_sql_text
FROM sys.query_store_query_text AS qsqt
WHERE EXISTS
(
SELECT
1/0
FROM sys.query_store_query AS qsq
JOIN sys.query_store_plan AS qsp
ON qsq.query_id = qsp.query_id
JOIN sys.query_store_runtime_stats AS qsrs
ON qsp.plan_id = qsrs.plan_id
WHERE qsqt.query_text_id = qsq.query_text_id
AND qsrs.count_executions = 1
);
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The more I work with Standard Edition, the more frustrated I get, and the more I have to tell people about the cost difference between it and Enterprise Edition, the more people start asking me about Postgres.
I wish that were a joke. Or that I knew Postgres better. Or that I knew the PIVOT syntax
(That was a terrible joke)
Mold And Musted
I’ve written about my Standard Edition annoyances in the past:
In the past I’ve thought that offering something between Standard and Enterprise Edition, or add-ons depending on what you’re after would be a good move.
For example, let’s say you want to unlock the memory limit and performance features, or you want the full Availability Group experience, you could buy them for some SA-like tax. But that just… makes licensing more complicated, and it’s already bad enough.
One install, one code base, one set of features, no documentation bedazzled with asterisks.
Perhaps best of all, everyone can stop complaining that Developer Edition is misleading because you can’t turn off Enterprise Edition features.
And you could better line the bits up with that’s in Azure SQL DB and Managed Instances.
Priceline
I have no idea how to handle the pricing, here. Perhaps that could also better line up with Azure offerings as well.
At any rate, something here has to give. Standard Edition is entirely uncompetitive in too many ways, and the price is too far apart from Enterprise Edition to realistically compare. That $5,000 jump per core is quite a jaw-dropper.
One option might be to make Express Edition the new Standard Edition, keeping it free and giving it the limitations that Standard Edition currently has.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Yes, I’m surprised that a code base that has been around for as long as Entity Framework hasn’t already dealt with this problem. I’ve said it before: someone ought to introduce the Entity Framework team to the SQL Server team.
My friend Josh (b|t) helped me out with some code that works in non-Core versions of Entity Framework too.
using (var context = new StackOverflowContext())
{
context.Database.Log = Console.WriteLine;
// http://www.albahari.com/nutshell/predicatebuilder.aspx
var predicate = PredicateBuilder.False<User>();
for (int i = 0; i < 100; i++)
{
var value = userIds[i >= userIds.Count - 1 ? userIds.Count - 1 : i];
predicate = predicate.Or(u => u.Id == value);
}
var users = context.Users
.AsExpandable() // http://www.albahari.com/nutshell/linqkit.aspx
.Where(predicate)
.ToList();
This is helpful when you have an upper limit to the number of values that could end up in your IN clause. This is cool because you’ll always generate 20 parameters, and pad out the list with the last value. That means you’ll get one query plan regardless of how many parameters actually end up in there.
I do not suggest setting this to an arbitrarily high number as a catch all. You will not be happy.
If you don’t have a known number, you can use this:
using (var context = new StackOverflowContext())
{
// http://www.albahari.com/nutshell/predicatebuilder.aspx
var predicate = PredicateBuilder.False<User>();
foreach (var id in userIds)
{
predicate = predicate.Or(u => u.Id == id);
}
var users = context.Users
.AsExpandable() // http://www.albahari.com/nutshell/linqkit.aspx
.Where(predicate)
.ToList();
And of course, even though it’s probably better than no parameterization at all, you will still get different query plans for different numbers of values.
And did I mention that Josh has a Great Series Of Posts™ on bad EF practices?
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In order to test these limits out, we need a rather large query.
Since I’m lazy, I’m using a bit of dynamic SQL to make the query I want. Along the way figuring out how many joins I could gin up before things went amok, I learned some fun things.
For example, if I used Hash Joins, I’d get an error that the Query Processor ran out of stack space, and if I used Nested Loops joins I wouldn’t get the requisite parallel exchanges necessary to have multiple parallel zones.
And if I don’t use a force order hint, I’ll end up spending a really long time waiting for a query plan to compile. It wasn’t a good time.
There’s also a tipping point with the number of joins, where if I go over a certain number, my query’s DOP gets downgraded to one.
yogurt land
Outcoming
After finding my sweet spot at 316 joins, I still had to toggle with DOP a little.
With my 316 join query, I was able to reserve 634 worker threads.
bile
But that’s where I topped off. After that, the query would get downgraded to DOP 1 and only ask for 1 thread.
Qurious
I’m not sure if there’s some built-in cap on how many threads a query can use, or if the limit is global before downgrades start happening.
What I found more interesting was that even though the query reserves 634 workers, those workers weren’t immediately subtracted from available workers on the server.
Technically, reserved threads don’t exist yet. They haven’t been created or attached to a task. All the reservation does is prevent other queries from reserving threads beyond the configured limit.
For example, if I run two copies of the big query at the same time, one is downgraded to DOP 1, likely because it’s hinted to DOP 2 and that’s the next lowest DOP, and it can’t run at DOP 2 and reserve 634 more threads that the first query has already reserved.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.