Make It Or Not
I’m gonna be honest with you, dear reader, because without honesty we’ve got nothing.
Except lies — which you know — those can be comforting sometimes. Hm. I’ll have to think about that one for a bit.
While digging through to find new stuff in SQL Server 2022, this stored procedure caught my eye.
If you try to get the text of it, you get told off. It’s All Internal© as they say on the tubes.
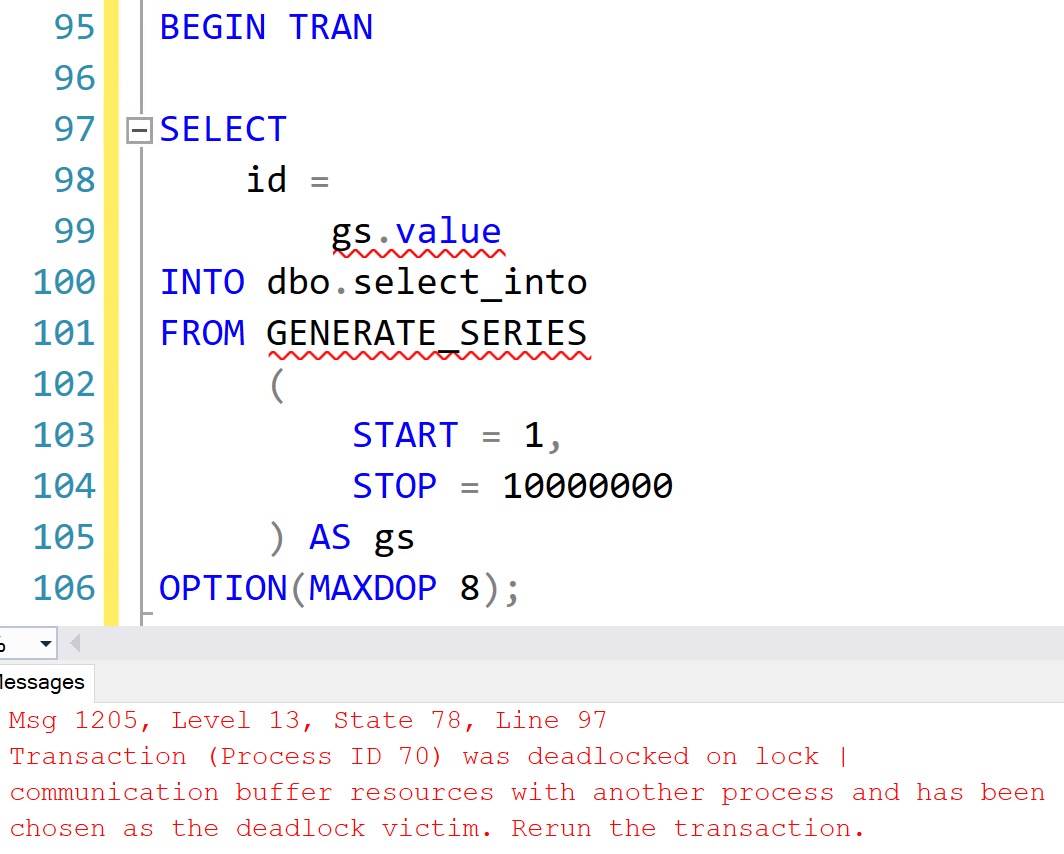
EXEC sp_helptext
'sp_copy_data_in_batches';
Well, okay. But we can try to get it working on our own. Usually I use this method to figure out what parameters a new thing requires to run.
Not this time!
Trial And Error
What I usually do is stick NULL or DEFAULT after the EXEC to to see what comes back. Sometimes using a number or something makes sense too, but whatever.
This at least helps you figure out:
- Number of parameters
- Expected data types
- Parameter NULLability
- Etc. and whenceforth
Eventually, I figured out that sp_copy_data_in_batches requires two strings, and that it expects those strings to exist as tables.
The final command that ended up working was this. Note that there is no third parameter at present to specify a batch size.
sp_copy_data_in_batches
N'dbo.art',
N'dbo.fart';
Path To Existence
This, of course, depends on two tables existing that match those names.
CREATE TABLE dbo.art(id int NOT NULL PRIMARY KEY); CREATE TABLE dbo.fart(id int NOT NULL PRIMARY KEY);
One thing to note here is that you don’t need a primary key to do this, but the table definitions do need to match exactly or else you’ll get this error:
Msg 37486, Level 16, State 2, Procedure sp_copy_data_in_batches, Line 1 [Batch Start Line 63] 'sp_copy_data_in_batches' failed because column 'id' does not have the same collation, nullability, sparse, ANSI_PADDING, vardecimal, identity or generated always attribute, CLR type or schema collection in tables '[dbo].[art]' and '[dbo].[fart]'.
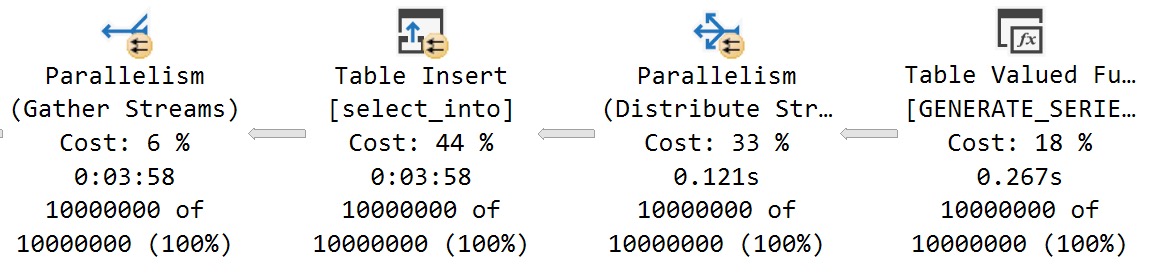
Because GENERATE_SERIES is still a bit rough around the edges, I’m gonna do this the old fashioned way, which turns out a bit faster.
INSERT
dbo.art WITH(TABLOCK)
(
id
)
SELECT TOP (10000000)
id =
ROW_NUMBER() OVER
(
ORDER BY 1/0
)
FROM sys.messages AS m
CROSS JOIN sys.messages AS m2;
Behind The Scenes
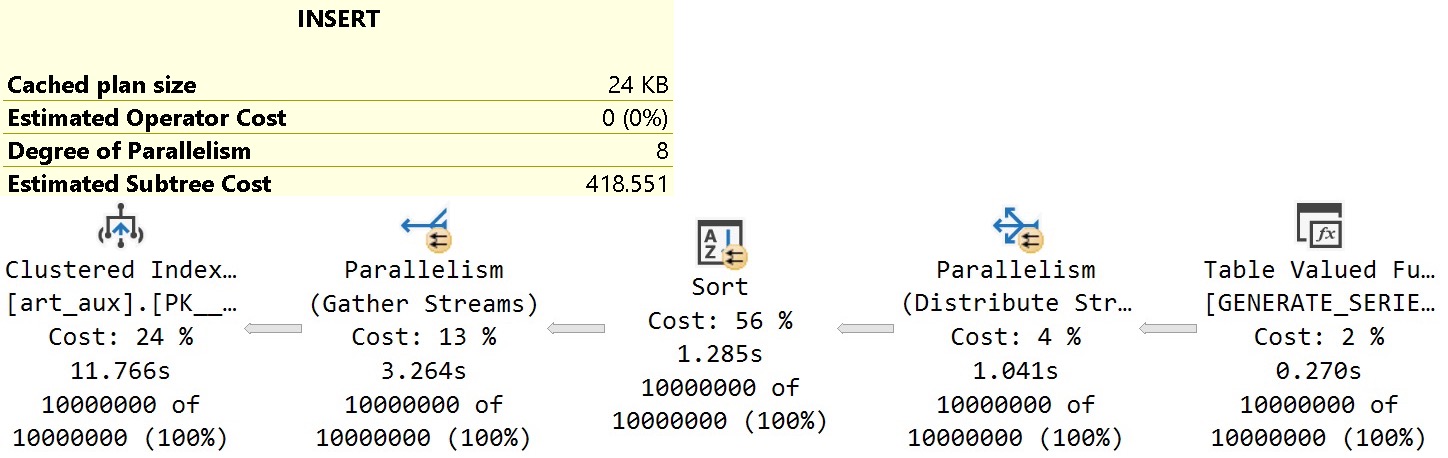
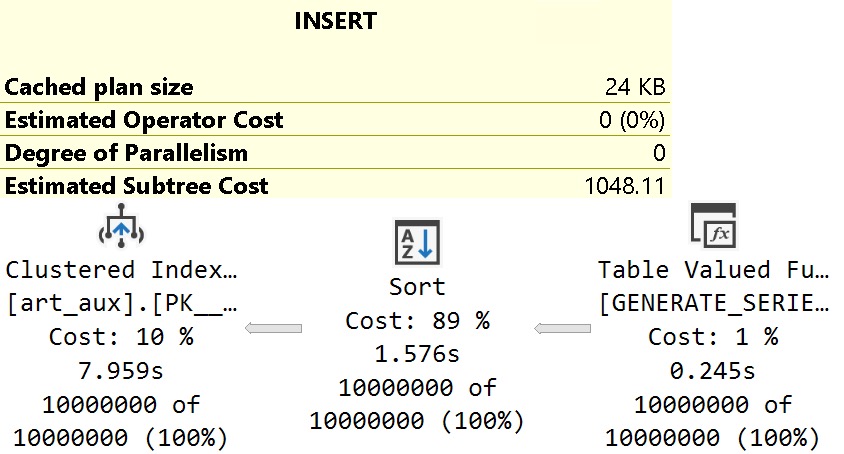
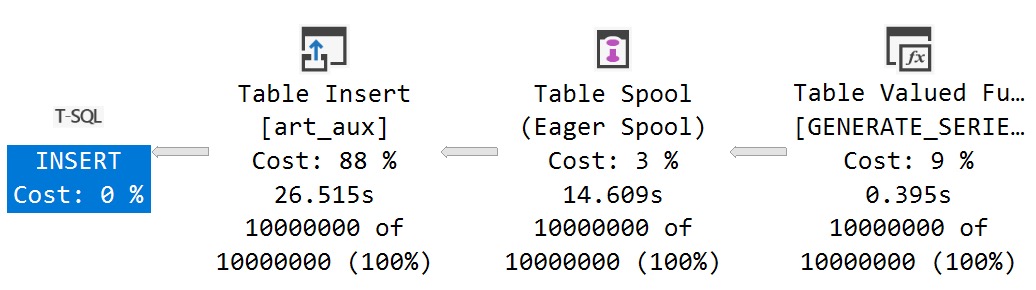
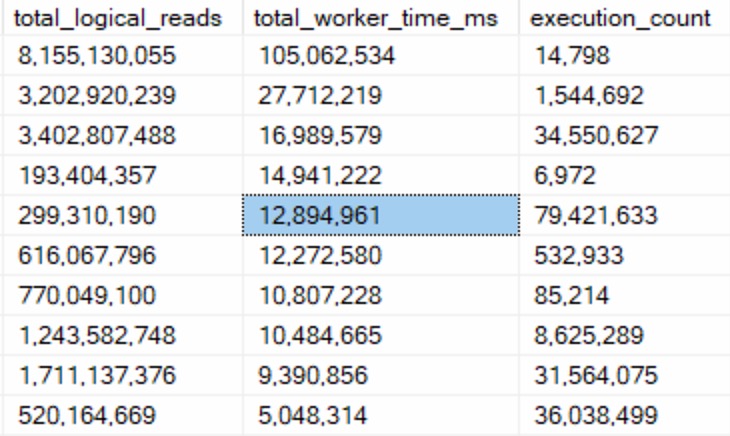
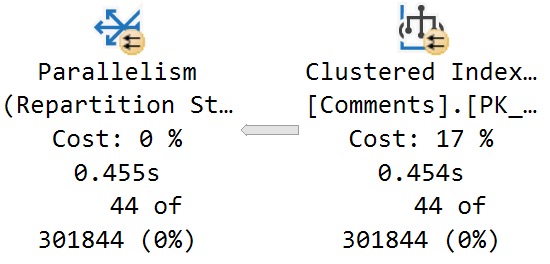
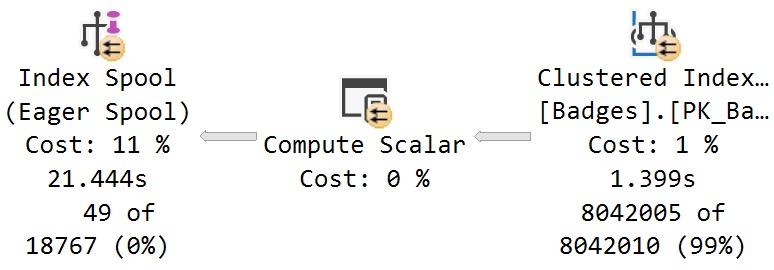
I sort of expected to run some before and after stuff, and see the count slowly increment, but the query plan for sp_copy_data_in_batches just showed this:

I’m not really sure what the batching is here.
Also, this is an online index operation, so perhaps it won’t work in Standard Edition. If there even is a Standard Edition anymore?
Has anyone heard from Standard Edition lately?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.