Mirror Backwards
When it comes to weird performance problems, I’ve seen this cause all sorts of them. The worst part is that there are much smarter ways to handle this.
While Table Valued Parameters aren’t perfect, I’d argue that they’re far more perfect than the alternative.
The first issue I see is that these clauses aren’t ever parameterized, which brings us to a couple familiar issues: plan cache bloat and purge, and constant query compilation.
Even when they are parameterized, some bad stuff can happen.
Since We’re Here
Let’s say you take steps like in the linked post about above to parameterize those IN clauses, though. Does that fix all your performance problems?
You can probably guess. Hey look, index!
CREATE INDEX u ON dbo.Users(DisplayName, Reputation) WITH(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Now, we’re gonna use a stored procedure I wrote to generate a long parameterized in clause. It’s not pretty, and there’s really no reason to do something like this outside of a demo to show what a bad idea it is.
Here’s how we’re gonna execute it:
EXEC dbo.Longingly
@loops = 50,
@debug = 0;
EXEC dbo.Longingly
@loops = 100,
@debug = 0;
EXEC dbo.Longingly
@loops = 1000,
@debug = 0;
If anyone thinks people sending 1000-long lists to an IN clause isn’t realistic, you should really get into consulting. There’s some stuff out there.
And Wave
Here’s what the query plans for those executions look like:
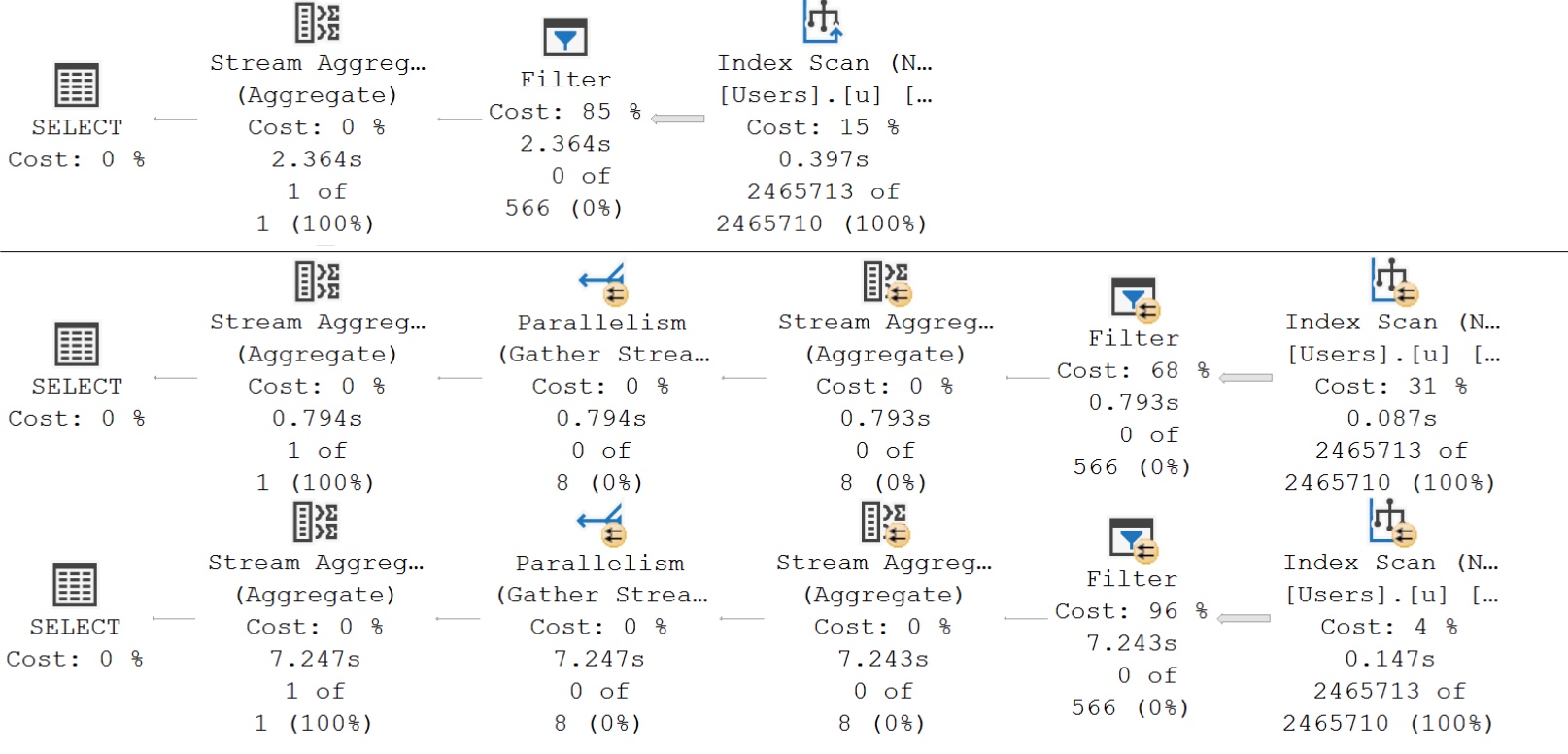
The important detail here is that even with our super duper powered index, the optimizer decides that life would be too difficult to apply our “complicated” predicate. We end up with query plans that scan the index, and then apply the predicate in a Filter operator afterwards.
You’re not misreading, either. The 1000-value filter runs for roughly 7 seconds. Recompile hints do not work here, and, of course, that’d undo all your hard work to parameterize these queries.
Moral of the story: Don’t do this. Pass in a TVP, like the link above shows you how to do. If your ORM doesn’t support that, you might need to switch over to stored procedures.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Using a TVP instead of IN() with a long list of values assumes there is truly a need to pass in a long list of values at all. I’ve found that often this is due to one LINQ query generating the list, which is then referenced in a second LINQ statement when that intermediate set of values is not needed for any other reason. Telltale signs include an IList or a .Contains() method on a List or using a .ToList() method. See this Github issue: https://github.com/dotnet/efcore/issues/13617. Combining the two sets of code instead generates a single database query with no instantiated list of values at all.
There is a potential replacement for .Contains() in EF Core that provides a fix for this at https://gist.github.com/ErikEJ/6ab62e8b9c226ecacf02a5e5713ff7bd although I haven’t seen that tried myself. If the list is of simple values and not of structures then a possible alternative using STRING_SPLIT is described at https://erikej.github.io/efcore/sqlserver/2021/11/22/efcore-sqlserver-cache-pollution.html.
Honestly, I haven’t touched C# code myself in over a decade, but the above is from what I send to our application developers when I find long IN() lists in a plan cache that change with every execution. They usually find that fixing it is a lot easier than finding part of their code that is causing it.
You have some assumptions here that don’t necessarily hold true:
1) People use Entity Framework
2) STRING_SPLIT() is available
In both cases a TVP is the right approach, and in the case of Dapper for example, there is quite an elegant approach with ISqlDataRecord without needing the massive overhead of a DataTable. As for STRING_SPLIT(), it is not available on compatibility levels below 130, and it has its own problems if the incoming string is a) longer than 8000 bytes; or b) incorrectly terminated.
Randolph, your point about SPLIT_STRING having issues with long or incorrectly terminated strings is especially helpful, so thanks for that! I’ve seen IN() lists of as many as 1000 UNIQUEIDENTIFIER values. SPLIT_STRING would choke on those. Our apps use EF Core with Azure SQL Database (compatibility level 150), but of course not everyone is in that situation. When I can (such as for internally developed apps) I get the application developers to modify their code. For third-party applications, we’re often stuck.