What This Isn’t
I’m not writing about how if you use NOT IN, and suffer from NULL values in a column you’re comparing, you’ll get an empty result.
That’s easy enough to show:
DECLARE @not_null TABLE ( id INT NOT NULL ); INSERT @not_null ( id ) VALUES ( 1 ); DECLARE @null TABLE ( id INT NULL ); INSERT @null ( id ) VALUES ( 1 ); INSERT @null ( id ) VALUES ( NULL ); SELECT * FROM @not_null AS nn WHERE nn.id NOT IN ( SELECT n.id FROM @null AS n );
What’s sort of more interesting to me is what happens in execution plans when you’re comparing NULL-able columns that don’t contain any NULLs.
Exampled!
Here’s the first query I want to show you. In the Posts table, the OwnerUserId column is NULLable, but doesn’t have any NULLs in it. The Id column in the Users table is not NULLable — it’s the PK/CX on the table.
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.Id NOT IN ( SELECT p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.Score < 0 );
Note that for all these queries, I’ve created these indexes:
CREATE INDEX beavis ON dbo.Users(AccountId); CREATE INDEX butthead ON dbo.Posts(OwnerUserId, Score); CREATE INDEX stewart ON dbo.Posts(Score, OwnerUserId);
The important part of the query looks like this:
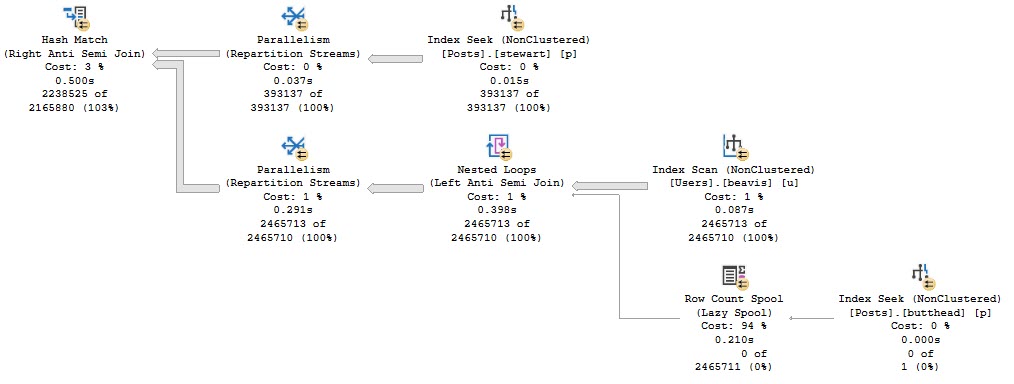
Zooming in to a sorta weird part of the query:
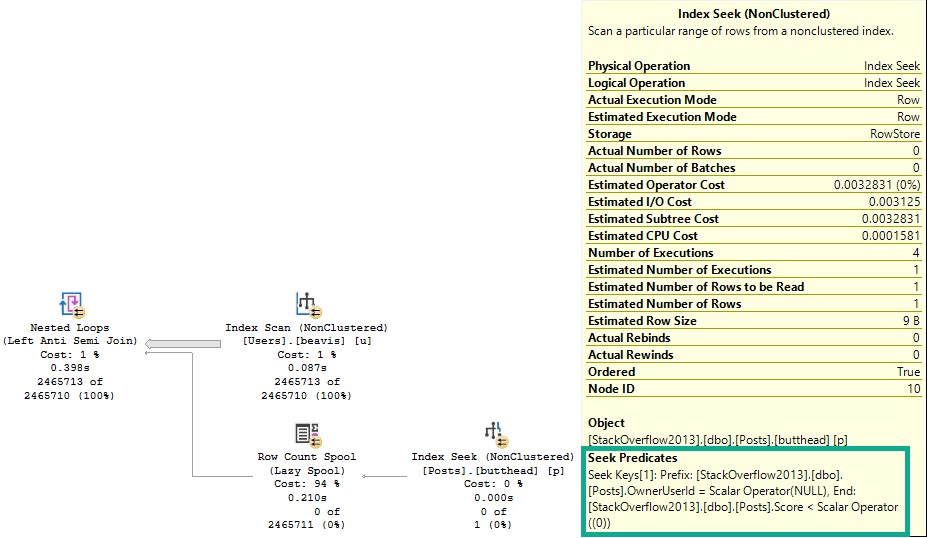
The optimizer spins up a Row Count Spool to make sure it’s right about the lack of NULLs. You can see the seek predicate doing so, and finding 0 rows, but taking ~200ms to do it. This time was much worse without those great indexes.
Explicitly Not NULL
If we change our query slightly, we can get a less exotic query plan:
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE u.Id NOT IN ( SELECT p.OwnerUserId
FROM dbo.Posts AS p
WHERE p.Score < 0
AND p.OwnerUserId IS NOT NULL );
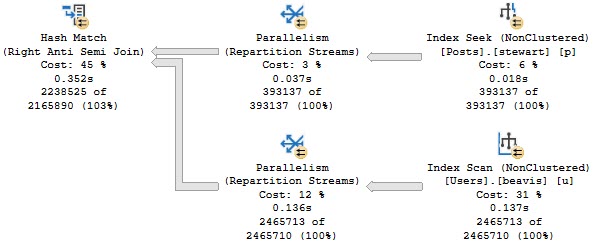
Which is a little bit faster overall, at ~350ms vs 550ms.
This is the equivalent of writing your query the way you should have written it in the first place, using NOT EXISTS.
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
WHERE NOT EXISTS ( SELECT 1 / 0
FROM dbo.Posts AS p
WHERE p.OwnerUserId = u.Id
AND p.Score < 0 )
Recap
The optimizer is a weird place. It’s the ultimate defensive driver. Dealing with NULLs can be quite odd and difficult.
I generally save IN and NOT IN for when I have short lists of literal values. Likely, EXISTS/NOT EXISTS when values are contained in other tables, or dumping values into a #temp table when there’s a lot of values can be more efficient, if only to make better indexing available.
While IN doesn’t have the same side effects as NOT IN with NULLs, I think using EXISTS instead is just a good habit.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.