Sing Along
If you have a workload that uses #temp tables to stage intermediate results, and you probably do because you’re smart, it might be worth taking advantage of being able to insert into the #temp table in parallel.
Remember that you can’t insert into @table variables in parallel, unless you’re extra sneaky. Don’t start.
If your code is already using the SELECT ... INTO #some_table pattern, you’re probably already getting parallel inserts. But if you’re following the INSERT ... SELECT ... pattern, you’re probably not, and, well, that could be holding you back.
Pile On
Of course, there are some limitations. If your temp table has indexes, primary keys, or an identity column, you won’t get the parallel insert no matter how hard you try.
The demo code is available here if you’d like to test it out.
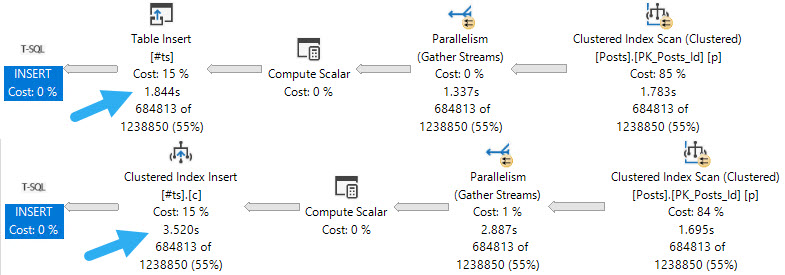
The first thing to note is that inserting into an indexed temp table, parallel or not, does slow things down. If your goal is the fastest possible insert, you may want to create the index later.
No Talent
When it comes to parallel inserts, you do need the TABLOCK, or TABLOCKX hint to get it, e.g. INSERT #tp WITH(TABLOCK) which is sort of annoying.
But you know. It’s the little things we do that often end up making the biggest differences. Another little thing we may need to tinker with is DOP.
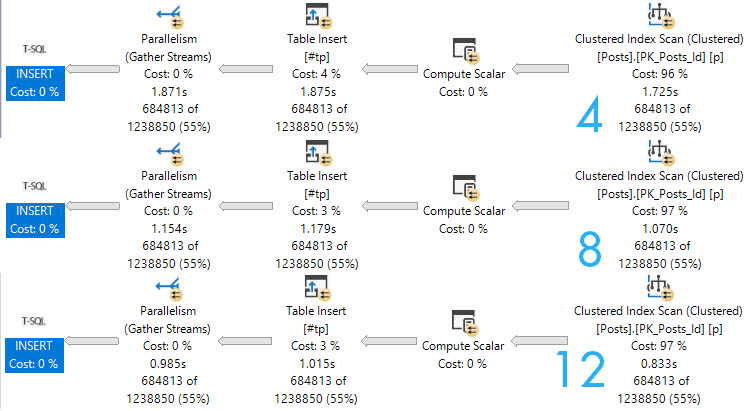
Here are the query plans for 3 fully parallel inserts into an empty, index-less temp #table. Note the execution times dropping as DOP increases. At DOP 4, the insert really isn’t any faster than the serial insert.
If you start experimenting with this trick, and don’t see noticeable improvements at your current DOP, you may need to bump it up to see throughput increases.
Also remember that if you’re doing this with clustered column store indexes, it can definitely make things worse.
Page Supplier
Though the speed ups above at higher DOPs are largely efficiency boosters while reading from the Posts table, the speed does stay consistent through the insert.
If we crank one of the queries that gets a serial insert up to DOP 12, we lose some speed when we hit the table.

Next time you’re tuning a query and want to drop some data into a temp table, you should experiment with this technique.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sounds like something Microsoft could partly optimize partly themselves, right?
If query pattern: “insert into #some_table select from .. ” (and cost > cost threshold for parallellism) then apply the tablock
Or, why is a tablock even required for a #some_table?
To make sure the insert operation is parallel, along with the read portion of the query plan.
Right sorry 😉 what I meant to say was that for regular tables the tablock hint is a concurrency aspect.
Since a #temp table the table is private to the session, the concurrency aspect isn’t there.
So why would I not want the tablock for a #temp table as a default behaviour if that helps with the parallel inserts?
Probably to not change default behavior on people, if I had to guess.
So glad Brent showed me your site, I love your stuff.
Aw thanks! Glad you’re enjoying it.
Hi Erik,
I love your posts. Explained everything in a very simple way.
Thanks,
Ray
Thanks, Ray! Appreciate the kind words.
I tried this recently for a stored procedure. Unexpectedly, simply adding the TABLOCK resulted in deadlocks. This was found by the testing team, so I never saw the deadlock graph, but I assume the parallel threads were deadlocking with themselves. Nothing else would have needed a lock on the temp table and it is Azure SQL database so the SELECTs in the several INSERT…SELECT into the same temp table wouldn’t have caused a lock on the source table either.
“Store proc gives result all the time if we execute it alone, however it gives “deadlocked on lock” error if we execute it in a script This script we are using to compare the stored proc results to ensure there is no mismatch in results before and after the optimization.” The test script inserts the return data from the stored procedure into a temp table using INSERT…SELECT.
Any ideas on how to avoid this?
No, not without a lot more information. It’s probably a better idea to post on dba.se or something, though.
Thanks!