I’m The Face
A lot of the time, the answer to performance issues with ranking windowing functions is simply to get Batch Mode involved. Where that’s not possible, you may have to resort to adding indexes.
Sometimes, even with Batch Mode, there is additional work to be done, but it really does get a lot of the job done.
In this post I’m going to cover some of the complexities of indexing for ranking windowing functions when there are additional considerations for indexing, like join and where clause predicates.
I also want to show you the limitations of indexing for solving performance problems for ranking windowing functions in Row Mode. This will be especially painful for developers forced to use Standard Edition, where Batch Mode is hopelessly hobbled into oblivion.
At some point, the amount of data that you’re dealing with becomes a bad fit for ranking windowing functions, and other approaches make more sense.
Of course, there are plenty of things that other variety of windowing functions do, that simple query rewrites don’t cover.
Here are some examples:
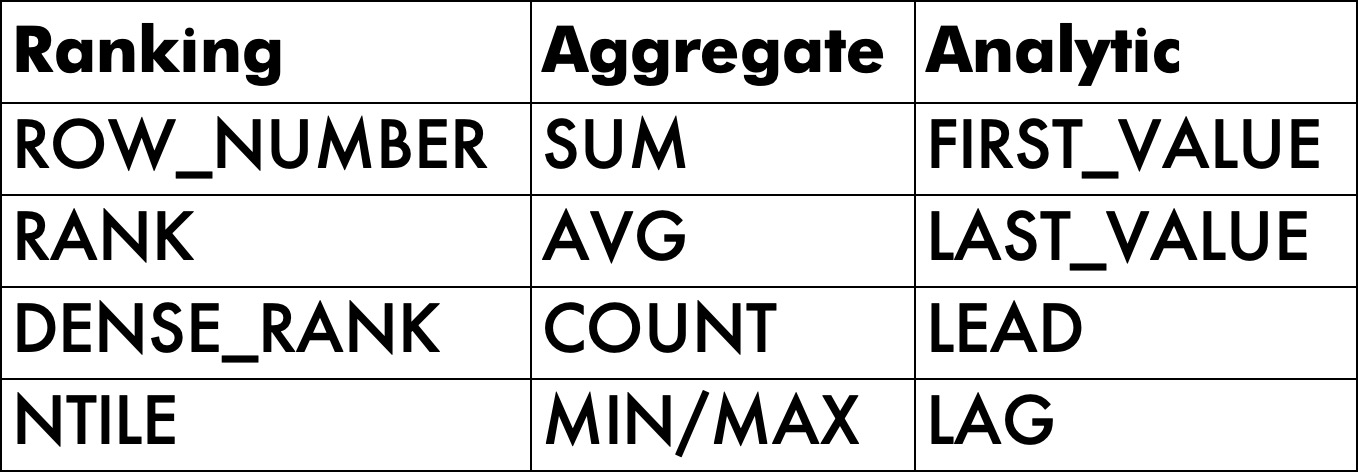
I realize that aggregate and analytic functions have many more options available, but there are only four ranking functions, and here at Darling Data, we strive for symmetry and equality.
It would be difficult to mimic the results of some of those — particularly the analytic functions — without performance suffering quite a bit, complicated self-joins, etc.
But, again, Batch Mode.
Hey Dude
Let’s start with a scenario I run into far too often: tables with crappy supporting indexes.
These aren’t too-too crappy, because I only have so much patience (especially when I know a blog post is going to be on the long side).
The index on Posts gets me to the data I care about fast enough, and the index on Votes allows for easy Apply Nested Loops seeking to support the Cross Apply.
There are some unnecessary includes in the index on Votes, because the demo query itself changed a bit as I was tweaking things.
But you know, if there’s one thing I’ve learned about SQL Server, there are lots of unnecessary includes in nonclustered indexes because of queries changing over the years.
CREATE INDEX
p
ON dbo.Posts
(PostTypeId)
INCLUDE
(Score)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
CREATE INDEX
v
ON dbo.Votes
(PostId)
INCLUDE
(UserId, BountyAmount, VoteTypeId, CreationDate)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
Now, the query I’m using is quite intentionally a bit of a stress test. I’m using two of the larger tables in the database, Posts and Votes.
But it’s a good example, because part of what I want to show you is how larger row counts can really mess with things.
I’m also using my usual trick of filtering to where the generated row number is equal to zero outside the apply.
That forces the query to do all of the window function work, without having to wait for 50 billion rows to render out in SSMS.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
CROSS APPLY
(
SELECT
v.*,
LastVoteByType =
ROW_NUMBER() OVER
(
PARTITION BY
v.VoteTypeId
ORDER BY
v.CreationDate DESC
)
FROM dbo.Votes AS v
WHERE v.PostId = p.Id
AND v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
) AS v
WHERE p.PostTypeId = 2
AND v.LastVoteByType = 0;
If you’re curious about why I wrote the query this way, watch this YouTube video of mine. Like and subscribe, etc.
Assume that the initial goal is that we care very much about the ~4.2GB memory grant that this query acquires to Sort data for the windowing function, and to create an index that solves for that.
Dark Therapy
The query plan isn’t too bad, but like we looked at in the post in this series about fixing sorts, there is a bit of a sore spot.
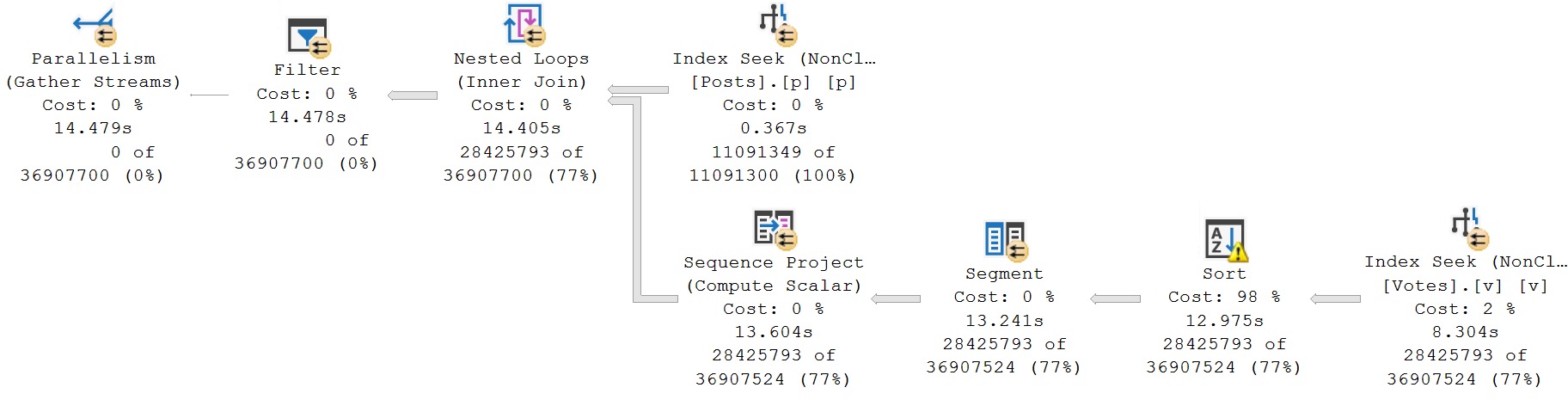
Now, it has been blogged about many times, so I’m not going to belabor the point too much: the columns that need sorting are the ones in the partition by and order by of the windowing function.
But the index needs to match the sort directions of those columns exactly. For example, if I were to create this index, where the sort direction of the CreationDate column is stored ascending, but the windowing function asks for descending, it won’t work out.
CREATE INDEX
v
ON dbo.Votes
(PostId, VoteTypeId, CreationDate)
INCLUDE
(UserId, BountyAmount)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
In fact, it’s gonna slow things down a bit. Score another one for crappy indexes, I suppose.
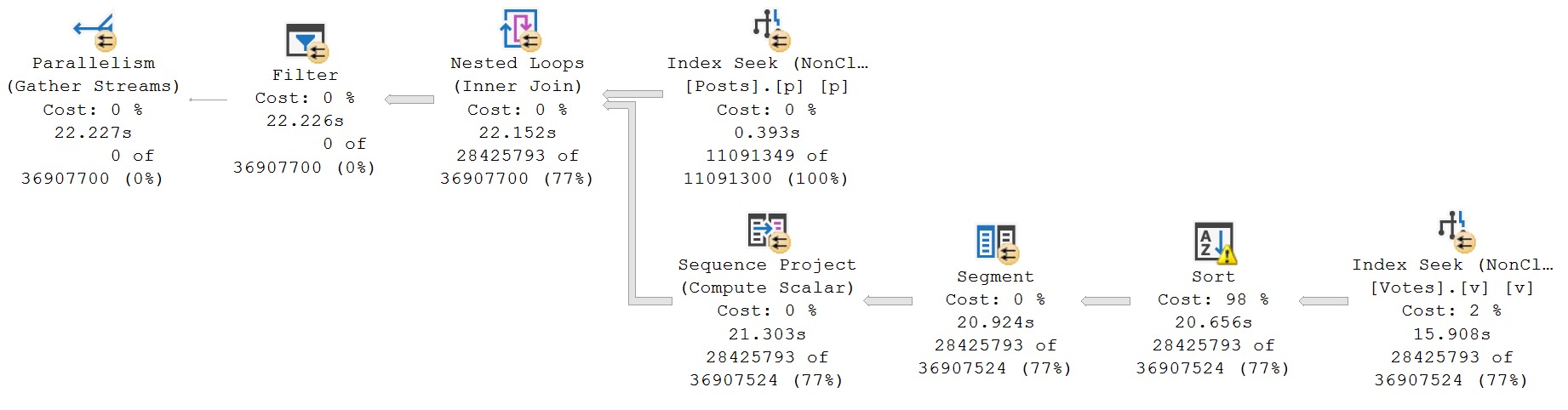
The reason why this one is so much slower is because of the Seek. I know, I know, how could a Seek be bad?! Well, it’s not one seek, it’s three seeks in one.
Time spent in each of the Row Mode operators in both of the plans you’ve seen so far is nearly identical, aside from the Seek into the Votes index. If we compare each tool tip…

The plan properties for the Seek are only interesting for the second query. It’s not very easy to see from the tool tips above, because Microsoft is notoriously bad at user experience in its products.

It is somewhat easier to see, quite verbosely, that for each PostId, rather than a single seek and residual predicate evaluation, three seeks are done.
But, anyway, the problem we’re aiming to solve persists — the Sort is still there — and we spend about 4.5 seconds in it.
Your Best Won’t Do
With a similar index, the best we can do is get back to the timing of the original query, minus the sort.
The index we created above was useless for that, because we were careless in our specification. We created it with CreationDate sorted in ascending order, and our query uses it in descending order.
CREATE INDEX
v
ON dbo.Votes
(PostId, VoteTypeId, CreationDate DESC)
INCLUDE
(UserId, BountyAmount)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE, DROP_EXISTING = ON);
Now, we’ve gotten rid of the sort, so our query is no longer asking for 4.2GB of RAM, but the runtime is only roughly equivalent to the original query.

A bit amusing that we were better off with a query plan where the sort spilled to disk, but what can you do? Just marvel at your luck, sometimes.
Improving Runtime
The sort of sad thing is that the cross apply method is purely Row Mode mentality. A bit like when I poke fun at folks who spend a lot of energy on index fragmentation, page splits, and fill factor as having 32bit mentality, modern performance problems often require Batch Mode mentality.
Query tuning is often about trade-offs, and this is no exception. We can reduce runtime dramatically, but we’re going to need memory to do it. We can take this thing from a best of around 15 seconds, to 2-3 seconds, but that Sort is coming back.
Using the normal arsenal tricks, getting Batch Mode on the inner side of a cross apply doesn’t seem to occur easily. A rewrite to get Batch Mode for a cross apply query is not exactly straightforward.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
CROSS APPLY
(
SELECT
v.*
FROM
(
SELECT
v.*,
LastVoteByType =
ROW_NUMBER() OVER
(
PARTITION BY
v.VoteTypeId
ORDER BY
v.CreationDate DESC
)
FROM dbo.Votes AS v
) AS v
WHERE v.PostId = p.Id
AND v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
) AS v
WHERE p.PostTypeId = 2
AND v.LastVoteByType >= '99991231'
OPTION(RECOMPILE);
Let’s change our query to use the method that I normally advise against when working in Row Mode.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
JOIN
(
SELECT
v.*,
LastVoteByType =
ROW_NUMBER() OVER
(
PARTITION BY
v.VoteTypeId
ORDER BY
v.CreationDate DESC
)
FROM dbo.Votes AS v
WHERE v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
) AS v
ON v.PostId = p.Id
WHERE p.PostTypeId = 2
AND v.LastVoteByType = 0;
In Row Mode, this sucks because the entire query in the derived join needs to be executed, producing a full result set of qualifying rows in the Votes table with their associated row number. Watch the video I linked above for additional details on that.
However, if we have our brains in Batch Mode, this approach can be much more useful, but not with the current index we’re using that leads with PostId.
When we used cross apply, having PostId as the leading column allowed for the join condition to be correlated inside the apply. We can’t do that with the derived join, we can only reference it in the outer part of the query.
Tweaking Indexes
An index that looks like this, which allows for finding the rows we care about in the derived join easily makes far more sense.
CREATE INDEX
v2
ON dbo.Votes
(VoteTypeId, CreationDate DESC, PostId)
INCLUDE
(UserId, BountyAmount)
WITH
(SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE);
With all that done, here’s our new query plan. Something to point out here is that this is the same query plan as the more complicated rewrite that I showed you in the last section, with the same memory grant. Some of these memory grant numbers are with memory grant feedback involved, largely shifting numbers downwards, which is what you would expect to see if you were doing this in real life.
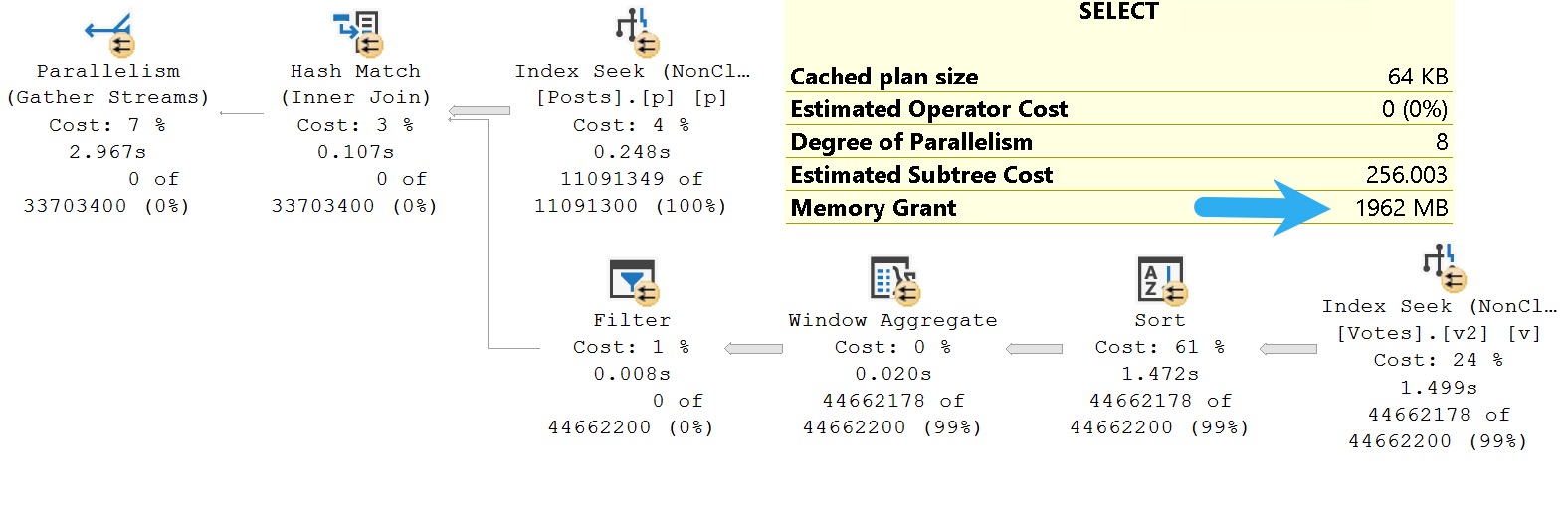
It could be far less of a concern for concurrency to grant out ~2GB of memory for 2 seconds, than for 15-20 seconds.
Even in a situation where you’re hitting RESOURCE_SEMAPHORE waits, it’s far less harmful to hit them for 3 seconds on average than 15-20 seconds on average. It’s also hard to imagine that you’re on a server where you truly care about high-end performance if 2GB memory grants lead you to RESOURCE_SEMAPHORE waits. If you have 128GB of RAM, and max server memory set to 116-120GB, you would be able to run ~80 of these queries concurrently before having a chance of a problem hitting RESOURCE_SEMAPHORE waits, assuming that you don’t get Resource Governor involved.
Tweaking The Query
Like I said early on, there’s only so good you can get with queries that use windowing functions where there are no alternatives.
Sticking with our Batch Mode mindset, let’s use this rewrite. It’s not that you can’t cross apply this, it’s just that it doesn’t improve things the way we want. It takes about 5 seconds to run, and uses 1.3GB of RAM for a query memory grant.
SELECT
p.Id,
p.Score,
v.VoteTypeId,
v.LastVoteByType
FROM dbo.Posts AS p
JOIN
(
SELECT
v.PostId,
v.VoteTypeId,
LastVoteByType =
MAX(v.CreationDate)
FROM dbo.Votes AS v
WHERE v.VoteTypeId IN (1, 2, 3)
AND v.CreationDate >= '20080101'
GROUP BY
v.PostId,
v.VoteTypeId
) AS v
ON v.PostId = p.Id
LEFT JOIN dbo.columnstore_helper AS ch
ON 1 = 0 /*This is important*/
WHERE p.PostTypeId = 2
AND v.LastVoteByType >= '99991231';
Note that I don’t naturally get batch mode via Batch Mode On Row Store. I’m using a table with this definition to force SQL Server’s hand a bit, here:
CREATE TABLE
dbo.columnstore_helper
(
cs_id bigint NOT NULL,
INDEX cs_id CLUSTERED COLUMNSTORE
);
But the result is pretty well worth it. It’s around 1 second faster than our best effort, with a 1.6GB memory grant.
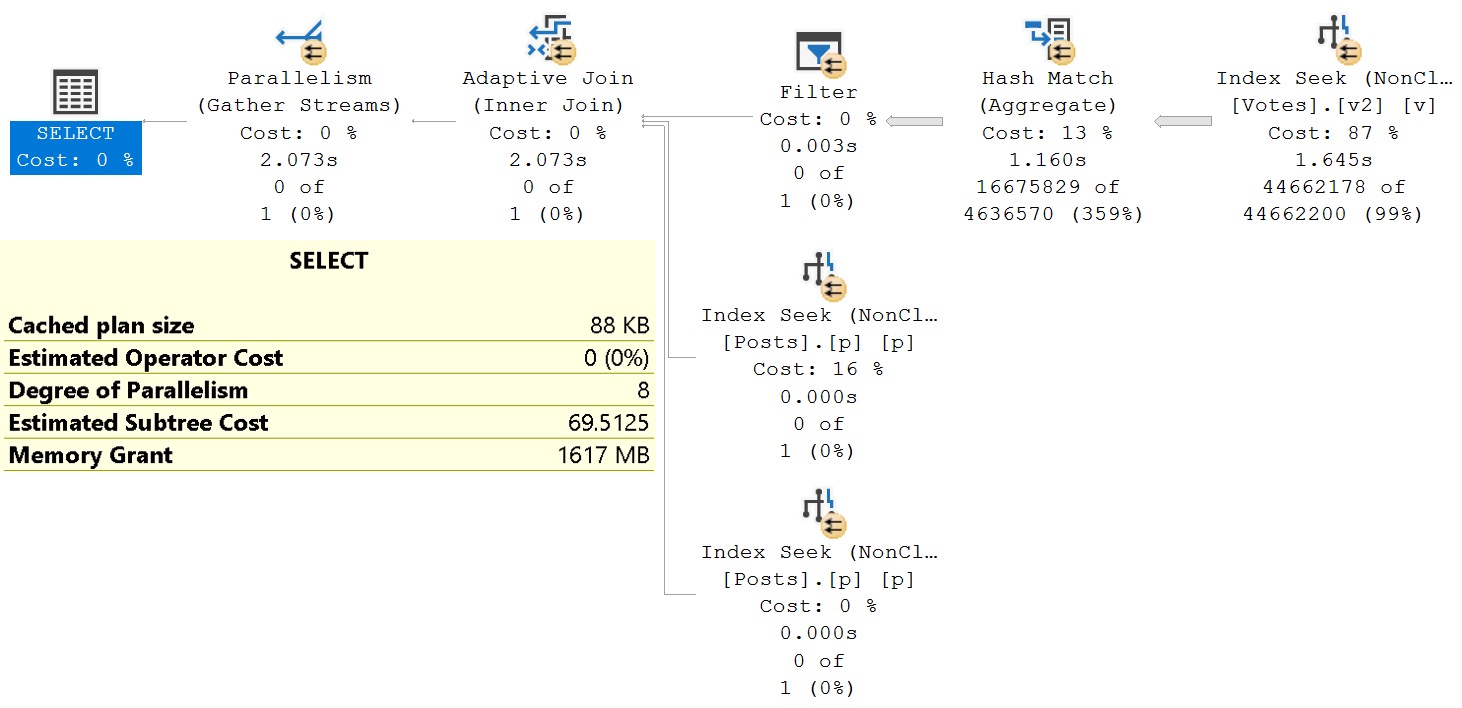
There may be even weirder rewrites out there in the world that would be better in some way, but I haven’t come across them yet.
Coverage
We covered a number of topics in this post, involving indexing, query rewrites, and the limitations of Row Mode performance in many situations.
The issues you’ll see in queries like this are quite common in data science, or data analysis type workloads, including those run by common reporting tools like PowerBI. Everyone seems to want a row number.
I departed a bit from what I imagined the post would look like as I went along, as additional interesting details came up. I hope it was an enjoyable, and reasonably meandering exploration for you, dear reader.
There’s one more post planned for this series so far, and I should probably provide some companion material for why the multi-seek query plan is 2x slower than the seek + residual query plan.
Anyway, I’m tired.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
One thought on “Indexing SQL Server Queries For Performance: Fixing Windowing Functions”
Comments are closed.