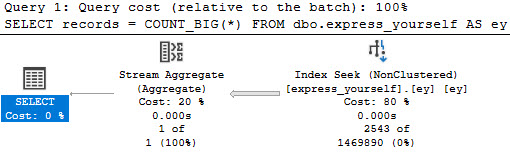
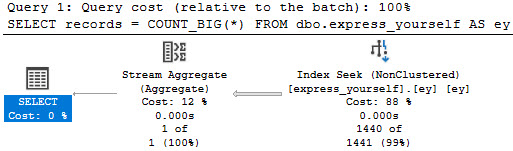
“Best Practice”
It’s somewhat strange to hear people carry on about best practices that are actually worst practices.
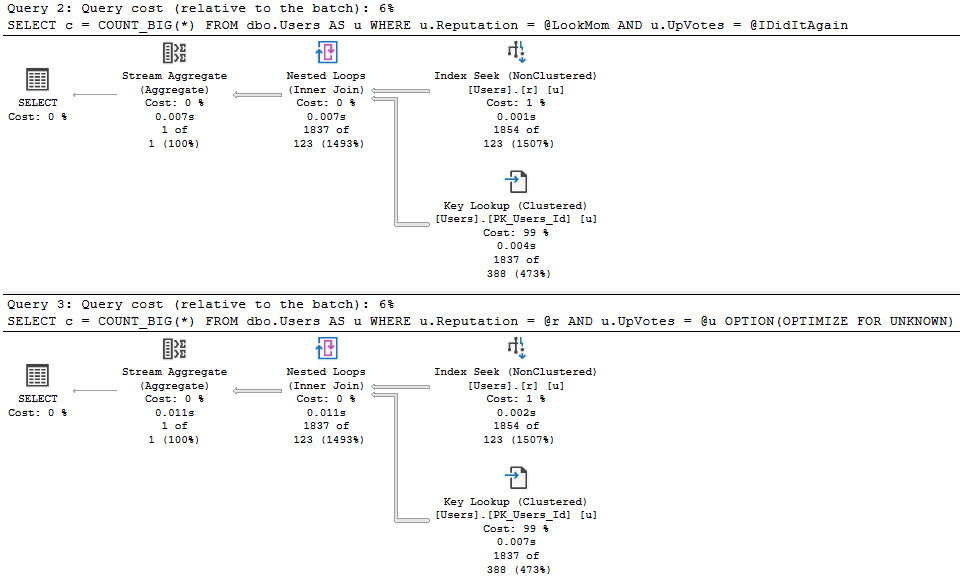
One worst practice that has strong staying power is the OPTIMIZE FOR UNKNOWN hint, which we talked about yesterday.
It probably doesn’t help that Microsoft has products (I’m looking at you, Dynamics) which have a setting to add the hint to every query. Shorter: If Microsoft recommends it, it must be good.
Thanks, Microsoft. Dummies.
Using the OPTIMIZE FOR UNKNOWN hint, or declaring variables inside of a code block to be used in a where clause have the same issue, though: they make SQL Server’s query optimizer make bad guesses, which often lead to bad execution plans.
You can read great detail about that here.
Mistakenly
We’re going to create two indexes on the Posts table:
CREATE INDEX
p0
ON dbo.Posts
(
OwnerUserId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
GO
CREATE INDEX
p1
ON dbo.Posts
(
ParentId,
CreationDate,
LastActivityDate
)
INCLUDE
(
PostTypeId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
GO
The indexes themselves are not as important as how SQL Server goes about choosing them.
Support Wear
This stored procedure is going to call the same query in three different ways:
- One with the OPTIMIZE FOR UNKNOWN hint that uses parameters
- One with local variables set to parameter values with no hints
- One that accepts parameters and uses no hints
CREATE OR ALTER PROCEDURE
dbo.unknown_soldier
(
@ParentId int,
@OwnerUserId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC
OPTION(OPTIMIZE FOR UNKNOWN);
DECLARE
@ParentIdInner int = @ParentId,
@OwnerUserIdInner int = @OwnerUserId;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentIdInner
AND p.OwnerUserId = @OwnerUserIdInner
ORDER BY
p.Score DESC,
p.Id DESC;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC;
END;
GO
Placebo Effect
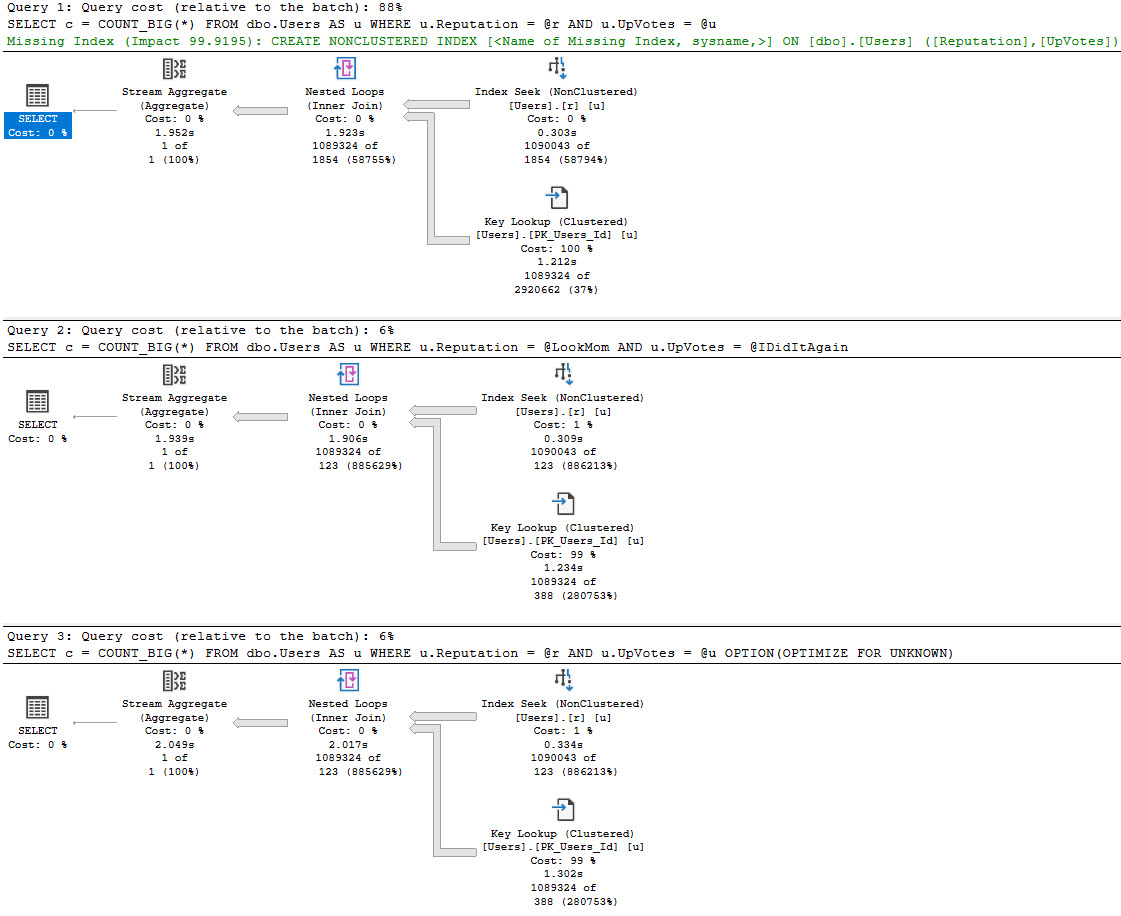
If we call the stored procedure with actual execution plans enabled, we get the following plans back.
EXEC dbo.unknown_soldier
@OwnerUserId = 22656,
@ParentId = 0;
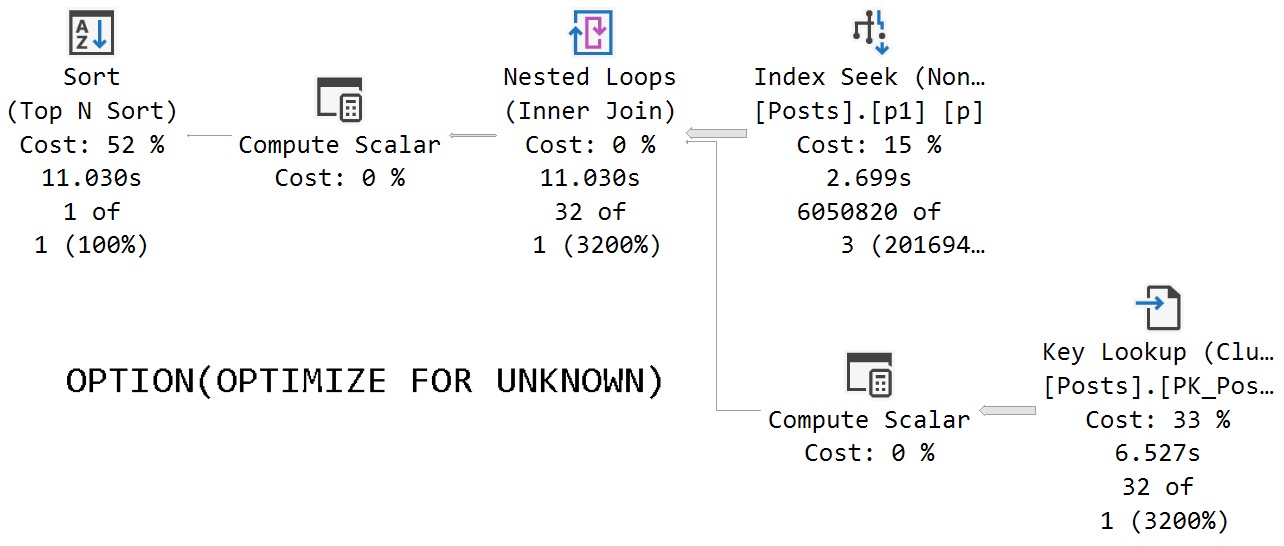
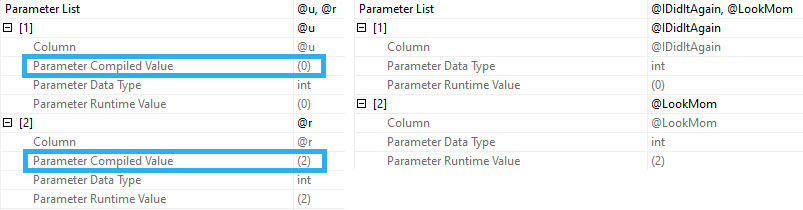
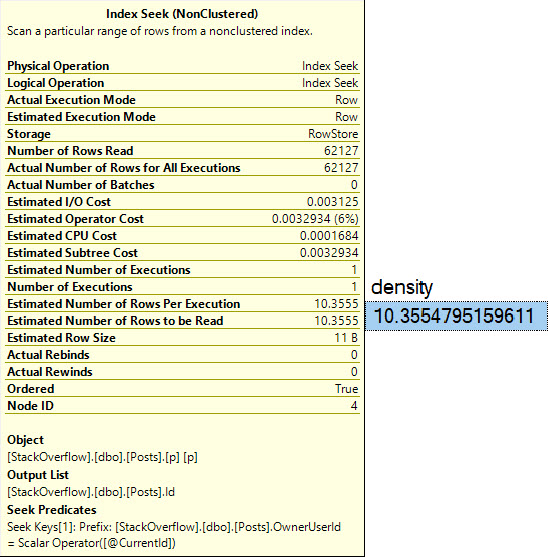
The assumed selectivity that the OPTIMIZE FOR UNKNOWN hint produces as a cardinality estimate is way off the rails.
SQL Server thinks three rows are going to come back, but we get 6,050,820 rows back.
We get identical behavior from the second query that uses variables declared within the stored procedure, and set to the parameter values passed in.
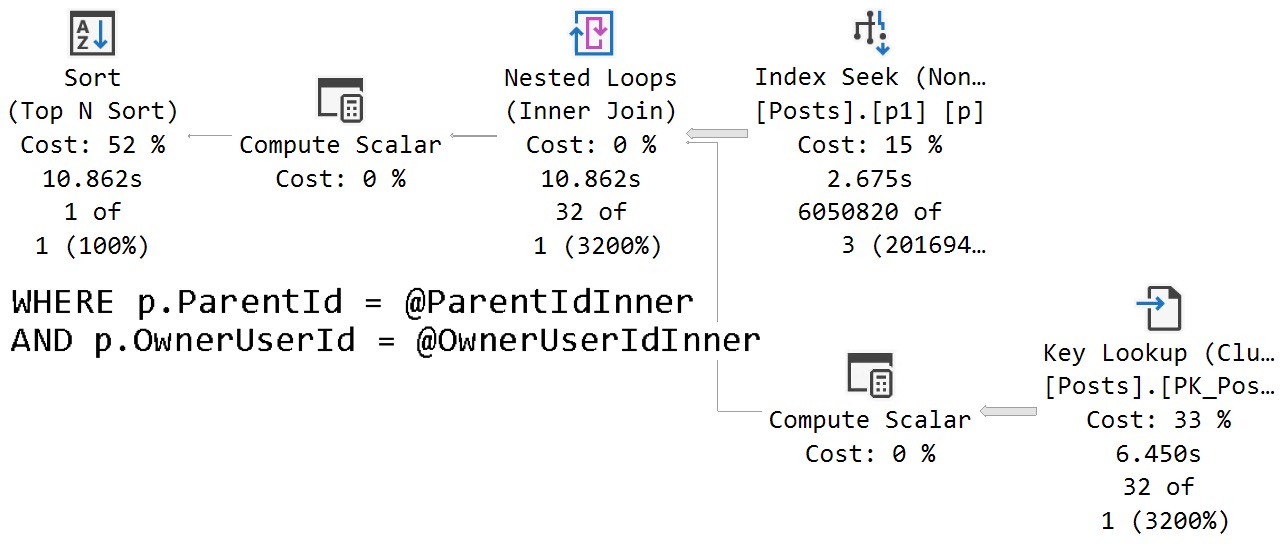
Same poor guesses, same index choices, same long running plan.
Parameter Effect
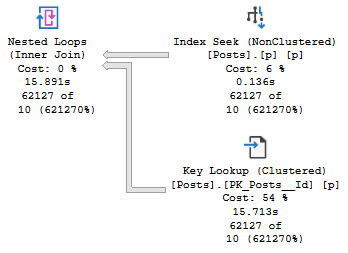
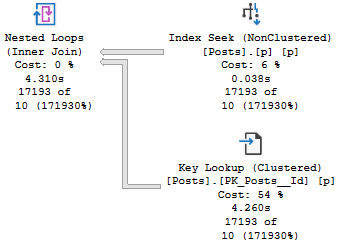
The query that accepts parameters and doesn’t have any hints applied to it fares much better.
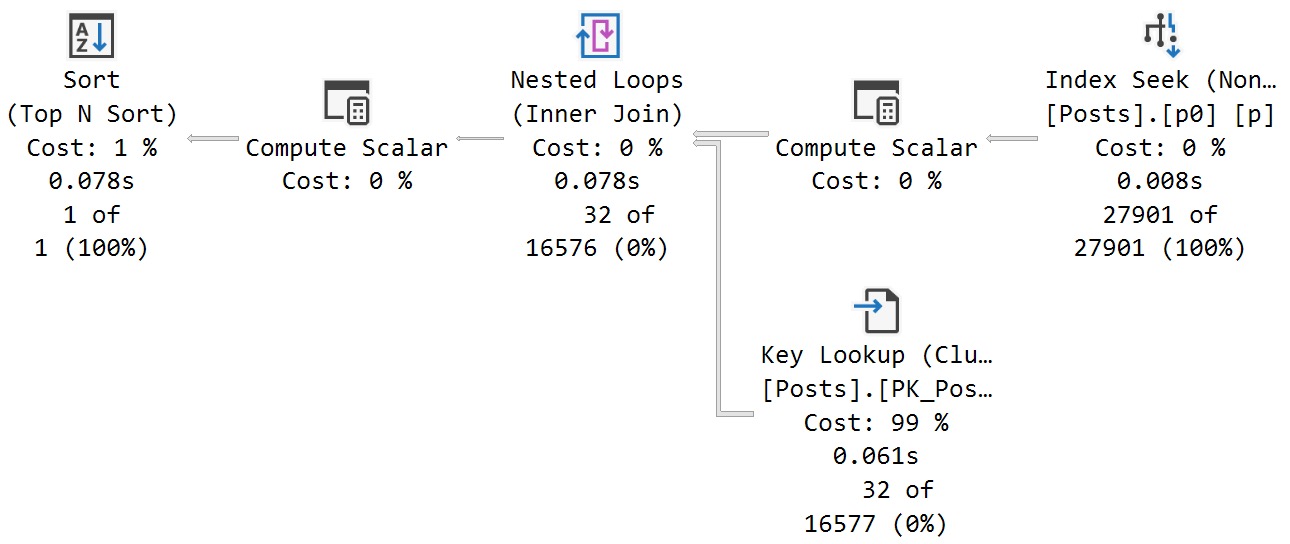
In this case, we get an accurate cardinality estimate, and a more suitable index choice.
Note that both queries perform lookups, but this one performs far fewer of them because it uses an index that filters way more rows out prior to doing the lookup.
The optimizer is able to choose the correct index because it’s able to evaluate predicate values against the statistics histograms rather than using the assumed selectivity guess.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.