When you have queries that need to process a lot of data, and probably do some aggregations over that lot-of-data, batch mode is usually the thing you want.
Originally introduced to accompany column store indexes, it works by allowing CPUs to apply instructions to up to 900 rows at a time.
It’s a great thing to have in your corner when you’re tuning queries that do a lot of work, especially if you find yourself dealing with pesky parallel exchanges.
Oh, Yeah
One way to get that to happen is to use a temp table with a column store index on it.
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
GROUP BY v.UserId
ORDER BY SumBounty DESC;
CREATE TABLE #t(id INT, INDEX c CLUSTERED COLUMNSTORE);
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
LEFT JOIN #t AS t
ON 1 = 0
GROUP BY v.UserId
ORDER BY SumBounty DESC;
If you end up using this enough, you may just wanna create a real table to use, anyway.
Remarkable!
If we look at the end (or beginning, depending on how you read your query plans) just to see the final times, there’s a pretty solid difference.
you can’t make me
The first query takes around 10 seconds, and the second query takes around 4 seconds. That’s a pretty handsome improvement without touching anything else.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You have too many indexes on too many tables already, and the thought of adding more fills you with a dread that has a first, middle, last, and even a confirmation name.
This is another place where temp tables can save your bacon, because as soon as the query is done they basically disappear.
Forever. Goodbye.
Off to buy a pack of smokes.
That Yesterday
In yesterday’s post, we looked at how a temp table can help you materialize an expression that would otherwise be awkward to join on.
If we take that same query, we can see how using the temp table simplifies indexing.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
CREATE CLUSTERED INDEX c ON #Posts(JoinKey);
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Rather than have to worry about how to handle a bunch of columns across the where and join and select, we can just stick a clustered index on the one column we care about doing anything relational with to get the final result.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A lot of the time when I see queries that are written with all sorts of gymnastics in the join or where clause and I ask some questions about it, people usually start complaining about the design of the table.
That’s fine, but when I ask about changing the design, everyone gets quiet. Normalizing tables, especially for Applications Of A Certain Age™ can be a tremendously painful project. This is why it’s worth it to get things right the first time. Simple!
Rather than make someone re-design their schema in front of me, often times a temp table is a good workaround.
Egg Splat
Let’s say we have a query that looks like this. Before you laugh, and you have every right to laugh, keep in mind that I see queries like this all the time.
They don’t have to be this weird to qualify. You can try this if you have functions like ISNULL, SUBSTRING, REPLACE, or whatever in joins and where clauses, too.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY p.OwnerUserId;
There’s not a great way to index for this, and sure, we could rewrite it as a UNION ALL, but then we’d have two queries to index for.
Sometimes getting people to add indexes is hard, too.
People are weird. All day weird.
Steak Splat
You can replace it with a query like this, which also allows you to index a single column in a temp table to do your correlation.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Remember that temp tables are like a second chance to get schema right. Don’t waste those precious chances.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
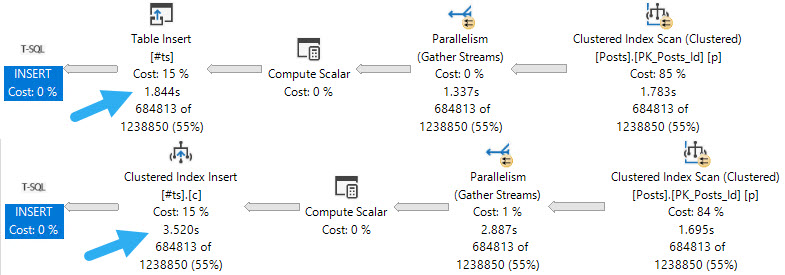
If you have a workload that uses #temp tables to stage intermediate results, and you probably do because you’re smart, it might be worth taking advantage of being able to insert into the #temp table in parallel.
If your code is already using the SELECT ... INTO #some_table pattern, you’re probably already getting parallel inserts. But if you’re following the INSERT ... SELECT ... pattern, you’re probably not, and, well, that could be holding you back.
Pile On
Of course, there are some limitations. If your temp table has indexes, primary keys, or an identity column, you won’t get the parallel insert no matter how hard you try.
The first thing to note is that inserting into an indexed temp table, parallel or not, does slow things down. If your goal is the fastest possible insert, you may want to create the index later.
No Talent
When it comes to parallel inserts, you do need the TABLOCK, or TABLOCKX hint to get it, e.g. INSERT #tp WITH(TABLOCK) which is sort of annoying.
But you know. It’s the little things we do that often end up making the biggest differences. Another little thing we may need to tinker with is DOP.
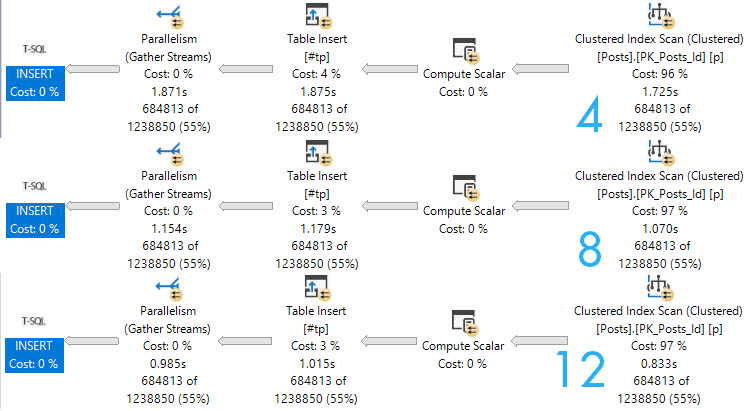
little pigs
Here are the query plans for 3 fully parallel inserts into an empty, index-less temp #table. Note the execution times dropping as DOP increases. At DOP 4, the insert really isn’t any faster than the serial insert.
If you start experimenting with this trick, and don’t see noticeable improvements at your current DOP, you may need to bump it up to see throughput increases.
Though the speed ups above at higher DOPs are largely efficiency boosters while reading from the Posts table, the speed does stay consistent through the insert.
If we crank one of the queries that gets a serial insert up to DOP 12, we lose some speed when we hit the table.
oops
Next time you’re tuning a query and want to drop some data into a temp table, you should experiment with this technique.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Temporary objects are a necessity for just about every workload I’ve ever seen. One cannot trust the optimizer with overly large and complex queries.
At some point, you’ve gotta break things up, down, or sideways, in order to stabilize a result set for better cardinality estimation on one (or both) sides of the query.
But there are some tricks and oddities around how and where you can use temporary objects in dynamic SQL.
It’s important to consider scope, and object type, when dealing with both at once.
Since they’re my least favorite, let’s start with table variables.
Well, It Beats String Splitting
Under normal circumstances, you can’t pass table variables into dynamic SQL, nor can you declare a table variable outside of dynamic SQL and use it inside.
Trying to do either one of these things will result in an error!
DECLARE @crap TABLE(id INT);
DECLARE @sql NVARCHAR(MAX) = N'SELECT COUNT(*) AS records FROM @crap;'
EXEC sp_executesql @sql;
GO
DECLARE @crap TABLE(id INT);
DECLARE @sql NVARCHAR(MAX) = N'SELECT COUNT(*) AS records FROM @crap;'
EXEC sp_executesql @sql, N'@crap TABLE (id INT)', @crap;
GO
A big, stupid, milk-brained error. But you can do it with a User Defined Type:
CREATE TYPE crap AS TABLE(id INT);
GO
DECLARE @crap AS crap;
DECLARE @sql NVARCHAR(MAX) = N'SELECT COUNT(*) AS records FROM @crap;'
EXEC sp_executesql @sql, N'@crap crap READONLY', @crap;
GO
In the same way that you can pass Table Valued Parameters into stored procedures, you can pass them into dynamic SQL, too. That’s pretty handy for various reasons.
But passing one out, no dice.
DECLARE @crap AS crap;
DECLARE @sql NVARCHAR(MAX) = N'DECLARE @crap AS crap;'
EXEC sp_executesql @sql, N'@crap crap OUTPUT', @crap = @crap OUTPUT;
GO
But of course, it might be even easier to use a temp table, so here we go.
I Don’t See Nothing Wrong
Of course, with temp tables, there is no problem using them with inner dynamic SQL
CREATE TABLE #gold(id INT);
DECLARE @sql NVARCHAR(MAX) = N'SELECT COUNT(*) AS records FROM #gold;'
EXEC sp_executesql @sql;
DROP TABLE #gold;
GO
But we don’t find nearly as much joy doing things in reverse.
DECLARE @sql NVARCHAR(MAX) = N'CREATE TABLE #gold(id INT);'
EXEC sp_executesql @sql;
SELECT COUNT(*) AS records FROM #gold;
DROP TABLE #gold;
GO
That’s why, rather than create a UDT, which gives you another dependency with not a lot of upside, people will just dump the contents of a TVP into a temp table, and use that inside dynamic SQL.
It’s a touch less clunky. Plus, with everything we know about table variables, it might not be such a great idea using them.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
So you’re that odd soul who has been listening to rumors about table variables. Perhaps things about them only being in memory, or that they’re okay to use if you only put less than some arbitrary number of rows in them.
Those things are both wrong. But of course, my favorite rumor is the one about arbitrary numbers of rows being safe.
Ouch! What a terrible performance
Let’s do everything in our power to help SQL Server make a good guess.
We’ll create a couple indexes:
CREATE INDEX free_food ON dbo.Posts(OwnerUserId);
CREATE INDEX sea_food ON dbo.Comments(UserId);
Those stats’ll be so fresh you could make tartare with them.
We’ll create our table variable with a primary key on it, which will also be the clustered index.
DECLARE @t TABLE( id INT PRIMARY KEY );
INSERT @t ( id )
VALUES(22656);
And finally, we’ll run the select query with a recompile hint. Recompile fixes everything, yeah?
SELECT AVG(p.Score * 1.) AS lmao
FROM @t AS t
JOIN dbo.Posts AS p
ON p.OwnerUserId = t.id
JOIN dbo.Comments AS c
ON c.UserId = t.id
OPTION(RECOMPILE);
GO
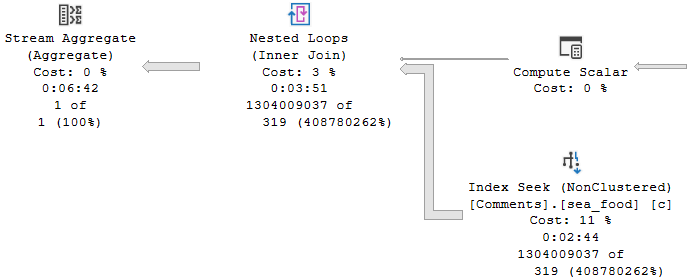
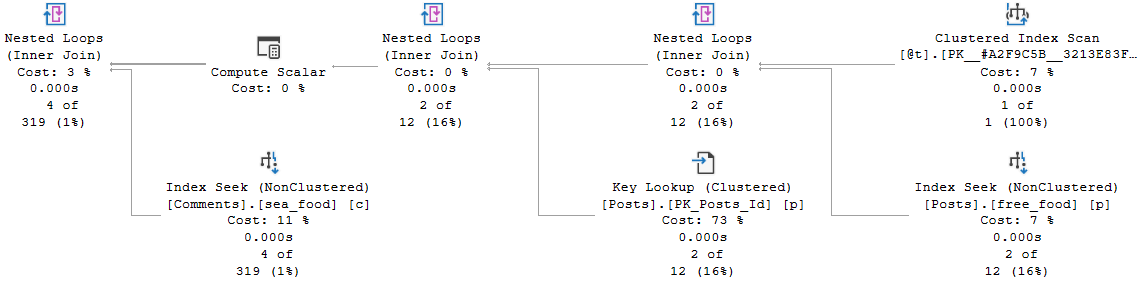
How does the query do for time? Things start off okay, but keep the cardinality estimate in mind.
Get the hook
But quickly go downhill.
Your granny lied!
Fish are dumb, dumb, dumb
The whole problem here is that, even with just one row in the table variable, an index on the one column in the table variable, and a recompile hint on the query that selects from the table variable, the optimizer has no idea what the contents of that single row are.
That number remains a mystery, and the guess made ends up being wrong by probably more than one order of magnitude. Maybe even an order of manure.
Table variables don’t gather any statistical information about what’s in the column, and so has no frame of reference to make a better cardinality estimate on the joins.
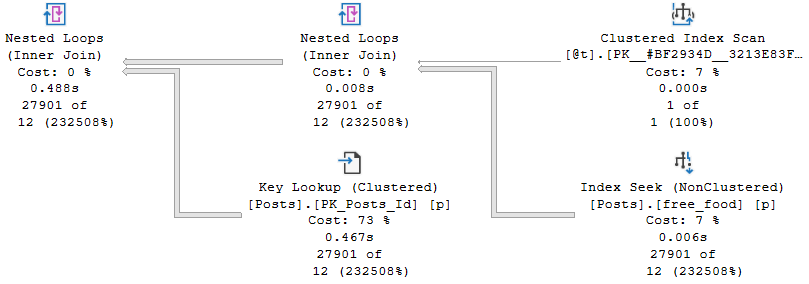
If we insert a value that gets far fewer hits in both the Posts and Comments tables (12550), the estimate doesn’t really hurt. But note that the guesses across all operators are exactly the same.
You don’t swing it like you used to, man
C’est la vie mon ami
You have a database. Data is likely skewed in that database, and there are already lots of ways that you can get bad guesses. Parameter sniffing, out of date stats, poorly written queries, and more.
Databases are hard.
The point is that if you use table variables outside of carefully tested circumstances, you’re just risking another bad guess.
All of this is tested on SQL Server 2019, with table variable deferred compilation enabled. All that allows for is the number of rows guessed to be accurate. It makes no attempt to get the contents of those rows correct.
So next time you’re sitting down to choose between a temp table and a table variable, think long and hard about what you’re going to be doing with it. If cardinality esimation might be important, you’re probably going to want a temp table instead.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
The important thing to understand about parallelism is it’s great when appropriate. Striking a balance between what should go parallel, the CPU usage it’s allowed, and what should stay serial can be tough.
It can be especially difficult when parameter sniffing comes into play. Here are a couple scenarios:
For a small amount of data, a serial query plan runs quickly and uses relatively few resources
For a large amount of data, a query re-uses the serial plan and runs for >20 seconds
For a small amount of data, a re-used parallel plan overloads the server due to many concurrent sessions
For a large amount of data, the re-used parallel plan finishes in 2-3 seconds
What do you do? Which plan do you favor? It’s an interesting scenario. Getting a single query to run faster by going parallel may seem ideal, but you need extra CPU, and potentially many more worker threads to accomplish that.
In isolation, you may think you’ve straightened things out, but under concurrency you run out of worker threads.
There are ways to address this sort of parameter sniffing, which we’ll get to at some point down the line.
Wrecking Crew
One way to artificially slow down a query is to use some construct that will inhibit parallelism when it would be appropriate.
There are some exotic reasons why a query might not go parallel, but quite commonly scalar valued functions and inserts to table variables are the root cause of otherwise parallel-friendly queries staying single-threaded and running for long times.
While yes, some scalar valued functions can be inlined in SQL Server 2019, not all can. The list of ineligible constructs has grown quite a bit, and will likely continue to. It’s a feature I love, but it’s not a feature that will fix everything.
Databases are hard.
XML Fetish
You don’t need to go searching through miles of XML to see it happening, either.
All you have to do is what I’ve been telling you all along: Look at those operator properties. Either hit F4, or right click and choose the properties of a select operator.
nonparallelplanreasonokaybutwhycanyoupleasetellme
Where I see these performance surprises! pop up is often when either:
Developers develop on a far smaller amount of data than production contains
Vendors have clients with high variance in database size and use
In both cases, small implementations likely mask the underlying performance issues, and they only pop up when run against bigger data. The whole “why doesn’t the same code run fast everywhere” question.
Well, not all features are created equally.
Simple Example
This is where table variables catch people off-guard. Even the “I swear I don’t put a lot of rows in them” crowd may not realize that the process to get down to very few rows is impacted by these @features.
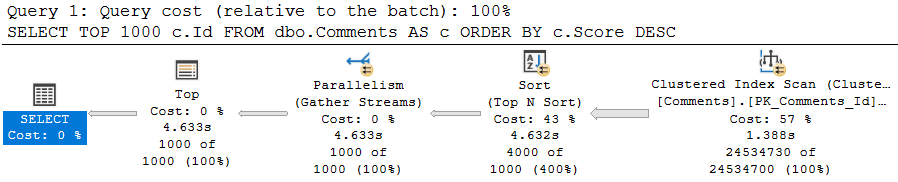
SELECT TOP (1000) c.Id
FROM dbo.Comments AS c
ORDER BY c.Score DESC;
This query, on its own, is free to go parallel — and it does! It takes about 4.5 seconds to do so. It’s intentionally simple.
don’t @ me
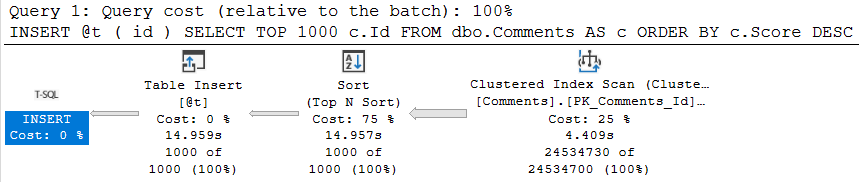
Once we try to involve a @table variable insert, parallelism goes away, time increases 3 fold, and the non-parallel plan reason is present in the plan XML.
DECLARE @t TABLE(id INT);
INSERT @t ( id )
SELECT TOP 1000 c.Id
FROM dbo.Comments AS c
ORDER BY c.Score DESC;
well.
Truesy
This can be quite a disappointing ramification for people who love to hold themselves up as responsible table variable users. The same will occur if you need to update or delete from a @table variable. Though less common, and perhaps less in need of parallelism, I’m including it here for completeness.
This is part of why multi-statement table valued functions, which return @table variables, can make performance worse.
To be clear, this same limitation does not exist for #temp tables.
Anyway, this post went a little longer than I thought it would, so we’ll look at scalar functions in tomorrow’s post to keep things contained.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Rather than just give you that one row estimate, it’ll wait until you’ve loaded data in, and then it will use table cardinality for things like joins to the table variable. Just be careful when you use them in stored procedures.
That can be a lot more helpful than what you currently get, but the guesses aren’t quite as helpful when you start using a where clause, because there still aren’t column-level statistics. You get the unknown guess for those.
How Can You Test It Out Before SQL Server 2019?
You can use #temp tables.
That’s right, regular old #temp tables.
They’ll give you nearly the same results as Table Variable Deferred Compilation in most cases, and you don’t need trace flags, hints, or or SQL Server 2019.
Heck, you might even fall in love with’em and live happily ever after.
The Fine Print
I know, some of you are out there getting all antsy-in-the-pantsy about all the SQL Jeopardy differences between temp tables and table variables.
I also realize that this may seem overly snarky, but hear me out:
Sure, there are some valid reasons to use table variables at times. But to most people, the choice about which one to use is either a coin flip or a copy/paste of what they saw someone else do in other parts of the code.
In other words, there’s not a lot of thought, and probably no adequate testing behind the choice. Sort of like me with tattoos.
Engine enhancements like this that benefit people who can’t change the code (or who refuse to change the code) are pretty good indicators of just how irresponsible developers have been with certain ✌features✌. I say this because I see it week after week after week. The numbers in Azure had to have been profound enough to get this worked on, finally.
I can’t imagine how many Microsoft support tickets have been RCA’d as someone jamming many-many rows in a table variable, with the only reasonable solution being to use a temp table instead.
I wish I could say that people learned the differences a lot faster when they experienced some pain, but time keeps proving that’s not the case. And really, it’s hardly ever the software developers who feel it with these choices: it’s the end users.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.