Even on SQL Server 2019, with in-memory tempdb metadata enabled, and an appropriate number of evenly sized data files, you can experience certain types of contention in tempdb.
It’s better. It’s definitely and totally better, but it’s still there. With that in mind, I wrote a stored procedure that you can stick in your favorite stress tool, to see how tempdb handles different numbers of concurrent sessions. You can download it here, on GitHub.
If you need a tool to run a bunch of concurrent sessions against SQL Server, my favorite two free ones are:
If you’re on < SQL Server 2016, you might need trace flags 1117 and 1118
You might have a bunch of other stuff hemming up tempdb, too
Check out this video for some other things that can cause problems too.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When tuning queries, one pattern I see over and over again is people running crazy-long queries. Maybe they worked well-enough at some point, but over the years they just kept getting slower and slower.
Sometimes there are comments, and other times there’s enough domain knowledge on the call to understand how a query ended up in the shape it’s in. One persistent idea is that tempdb is something to be avoided. Either because it was “slow” or to avoid contention.
Granted, if a query has been around long enough, these may have been valid concerns at some point. In general though, temp tables (the # kind, not the @ kind) can be quite useful when query tuning.
You Might Be Using It, Anyway
Even if there’s some rule against directly using temp tables, queries can end up using tempdb by the caseload anyway.
Consider that Spool operators explicitly execute in tempdb, any spills will go to tempdb, and work tables that are used in a number of circumstances occur in tempdb. The bigger and more complicated your queries are, the more likely you are to run into cases where the optimizer Spools, Spills, or use some other workspace area in tempdb in your query plan.
Worse, optimizations available for temp tables aren’t available to on-the-fly operators. You also lose the ability to take further action by indexing your temp tables, etc.
It’s Often Easier Than Other Options
Many times when tuning queries, I’ll be puzzled by the optimizer’s choices. Sometimes it’s join type, other times it’s join order, or something else. Perhaps the most common reason is some misestimation, of course.
Query and index hints are great to experiment with, but are often unsatisfying as permanent fixes. I’m not saying to never use them, but you should explore other options first. In other words, keep temp tables on the table.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When you have queries that need to process a lot of data, and probably do some aggregations over that lot-of-data, batch mode is usually the thing you want.
Originally introduced to accompany column store indexes, it works by allowing CPUs to apply instructions to up to 900 rows at a time.
It’s a great thing to have in your corner when you’re tuning queries that do a lot of work, especially if you find yourself dealing with pesky parallel exchanges.
Oh, Yeah
One way to get that to happen is to use a temp table with a column store index on it.
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
GROUP BY v.UserId
ORDER BY SumBounty DESC;
CREATE TABLE #t(id INT, INDEX c CLUSTERED COLUMNSTORE);
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
LEFT JOIN #t AS t
ON 1 = 0
GROUP BY v.UserId
ORDER BY SumBounty DESC;
If you end up using this enough, you may just wanna create a real table to use, anyway.
Remarkable!
If we look at the end (or beginning, depending on how you read your query plans) just to see the final times, there’s a pretty solid difference.
you can’t make me
The first query takes around 10 seconds, and the second query takes around 4 seconds. That’s a pretty handsome improvement without touching anything else.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You have too many indexes on too many tables already, and the thought of adding more fills you with a dread that has a first, middle, last, and even a confirmation name.
This is another place where temp tables can save your bacon, because as soon as the query is done they basically disappear.
Forever. Goodbye.
Off to buy a pack of smokes.
That Yesterday
In yesterday’s post, we looked at how a temp table can help you materialize an expression that would otherwise be awkward to join on.
If we take that same query, we can see how using the temp table simplifies indexing.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
CREATE CLUSTERED INDEX c ON #Posts(JoinKey);
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Rather than have to worry about how to handle a bunch of columns across the where and join and select, we can just stick a clustered index on the one column we care about doing anything relational with to get the final result.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A lot of the time when I see queries that are written with all sorts of gymnastics in the join or where clause and I ask some questions about it, people usually start complaining about the design of the table.
That’s fine, but when I ask about changing the design, everyone gets quiet. Normalizing tables, especially for Applications Of A Certain Age™ can be a tremendously painful project. This is why it’s worth it to get things right the first time. Simple!
Rather than make someone re-design their schema in front of me, often times a temp table is a good workaround.
Egg Splat
Let’s say we have a query that looks like this. Before you laugh, and you have every right to laugh, keep in mind that I see queries like this all the time.
They don’t have to be this weird to qualify. You can try this if you have functions like ISNULL, SUBSTRING, REPLACE, or whatever in joins and where clauses, too.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY p.OwnerUserId;
There’s not a great way to index for this, and sure, we could rewrite it as a UNION ALL, but then we’d have two queries to index for.
Sometimes getting people to add indexes is hard, too.
People are weird. All day weird.
Steak Splat
You can replace it with a query like this, which also allows you to index a single column in a temp table to do your correlation.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Remember that temp tables are like a second chance to get schema right. Don’t waste those precious chances.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
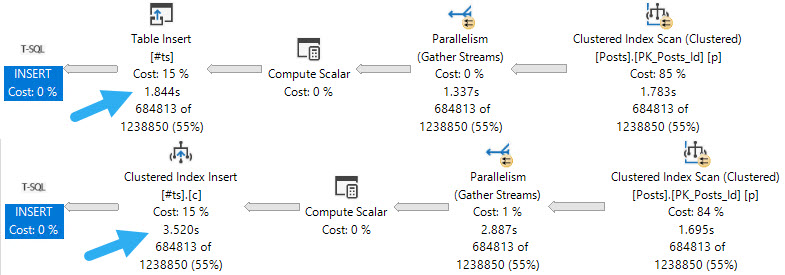
If you have a workload that uses #temp tables to stage intermediate results, and you probably do because you’re smart, it might be worth taking advantage of being able to insert into the #temp table in parallel.
If your code is already using the SELECT ... INTO #some_table pattern, you’re probably already getting parallel inserts. But if you’re following the INSERT ... SELECT ... pattern, you’re probably not, and, well, that could be holding you back.
Pile On
Of course, there are some limitations. If your temp table has indexes, primary keys, or an identity column, you won’t get the parallel insert no matter how hard you try.
The first thing to note is that inserting into an indexed temp table, parallel or not, does slow things down. If your goal is the fastest possible insert, you may want to create the index later.
No Talent
When it comes to parallel inserts, you do need the TABLOCK, or TABLOCKX hint to get it, e.g. INSERT #tp WITH(TABLOCK) which is sort of annoying.
But you know. It’s the little things we do that often end up making the biggest differences. Another little thing we may need to tinker with is DOP.
little pigs
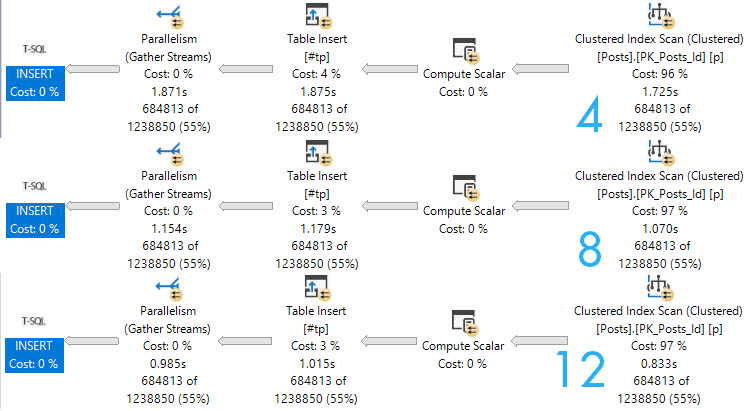
Here are the query plans for 3 fully parallel inserts into an empty, index-less temp #table. Note the execution times dropping as DOP increases. At DOP 4, the insert really isn’t any faster than the serial insert.
If you start experimenting with this trick, and don’t see noticeable improvements at your current DOP, you may need to bump it up to see throughput increases.
Though the speed ups above at higher DOPs are largely efficiency boosters while reading from the Posts table, the speed does stay consistent through the insert.
If we crank one of the queries that gets a serial insert up to DOP 12, we lose some speed when we hit the table.
oops
Next time you’re tuning a query and want to drop some data into a temp table, you should experiment with this technique.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Msg 11442, Level 16, State 1, Line 4
Columnstore index creation is not supported in tempdb when memory-optimized metadata mode is enabled.
There’s no workaround for this, either. You can’t tell it to use a different database, this is just the way it’s built.
Hopefully in the future, there will be more cooperation between these two features.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You already know that your temp table needs an index. Let’s say there’s some query plan ouchie from not adding one. You’ve already realized that you should probably use a clustered index rather than a nonclustered index. Adding a nonclustered index leaves you with a heap and an index, and there are a lot of times when nonclustered indexes won’t be used because they don’t cover the query columns enough.
Do not explicitly drop temp tables at the end of a stored procedure, they will get cleaned up when the session that created them ends.
Do not alter temp tables after they have been created.
Do not truncate temp tables
Move index creation statements on temp tables to the new inline index creation syntax that was introduced in SQL Server 2014.
Where it can be a bad option is:
If you can’t get a parallel insert even with a TABLOCK hint
Sorting the data to match index order on insert could result in some discomfort
After Creation
This is almost always not ideal, unless you want to avoid caching the temp table, and for the recompilation to occur for whatever reason.
It’s not that I’d ever rule this out as an option, but I’d wanna have a good reason for it.
Probably even several.
After Insert
This can sometimes be a good option if the query plan you get from inserting into the index is deficient in some way.
Like I mentioned up above, maybe you lose parallel insert, or maybe the DML Request Sort is a thorn in your side.
This can be awesome! Except on Standard Edition, where you can’t create indexes in parallel. Which picks off one of the reasons for doing this in the first place, and also potentially causes you headaches with not caching temp tables, and statement level recompiles.
One upside here is that if you insert data into a temp table with an index, and then run a query that causes statistics generation, you’ll almost certainly get the default sampling rate. That could potentially cause other annoyances. Creating the index after loading data means you get the full scan stats.
Hooray, I guess.
This may not ever be the end of the world, but here’s a quick example:
DROP TABLE IF EXISTS #t;
GO
--Create a table with an index already on it
CREATE TABLE #t(id INT, INDEX c CLUSTERED(id));
--Load data
INSERT #t WITH(TABLOCK)
SELECT p.OwnerUserId
FROM dbo.Posts AS p;
--Run a query to generate statistics
SELECT COUNT(*)
FROM #t AS t
WHERE t.id BETWEEN 1 AND 10000
GO
--See what's poppin'
SELECT hist.step_number, hist.range_high_key, hist.range_rows,
hist.equal_rows, hist.distinct_range_rows, hist.average_range_rows
FROM tempdb.sys.stats AS s
CROSS APPLY tempdb.sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id, 2) LIKE '#t%'
GO
DROP TABLE #t;
--Create a query with no index
CREATE TABLE #t(id INT NOT NULL);
--Load data
INSERT #t WITH(TABLOCK)
SELECT p.OwnerUserId
FROM dbo.Posts AS p;
--Create the index
CREATE CLUSTERED INDEX c ON #t(id);
--Run a query to generate statistics
SELECT COUNT(*)
FROM #t AS t
WHERE t.id BETWEEN 1 AND 10000
--See what's poppin'
SELECT hist.step_number, hist.range_high_key, hist.range_rows,
hist.equal_rows, hist.distinct_range_rows, hist.average_range_rows
FROM tempdb.sys.stats AS s
CROSS APPLY tempdb.sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id, 2) LIKE '#t%'
GO
DROP TABLE #t;
Neckin’ Neck
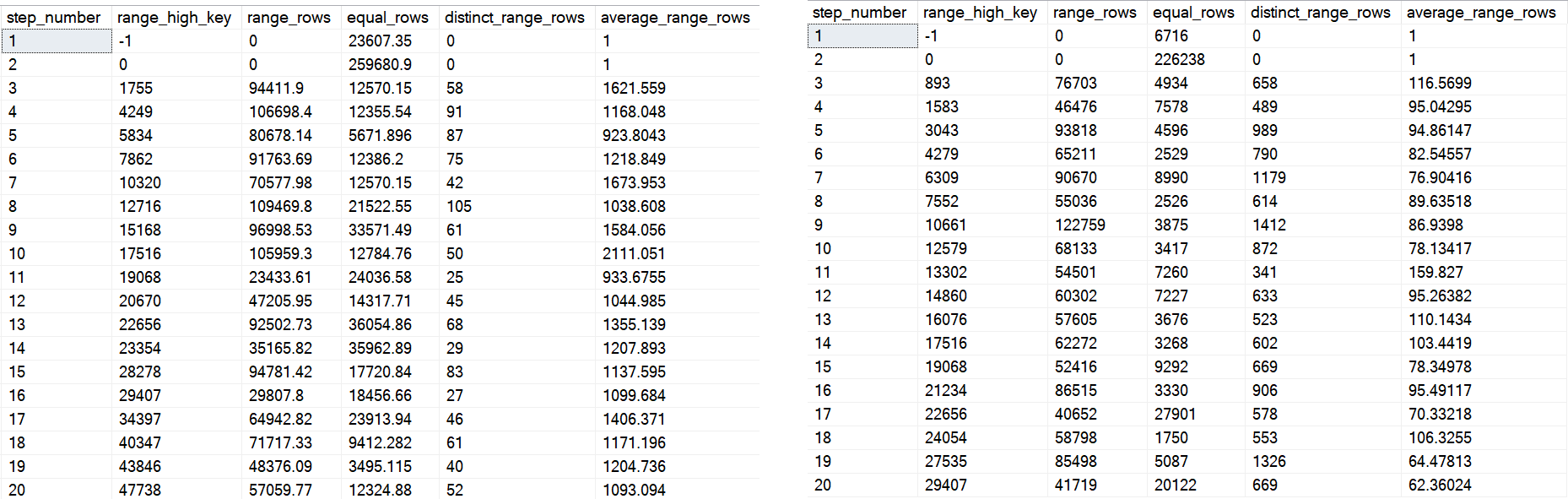
On the left is the first 20 steps from the first histogram, and on the right is the first 20 from the second one.
You can see some big differences — whether or not they end up helping or hurting performance would take a lot of different tests. Quite frankly, it’s probably not where I’d start a performance investigation, but I’d be lying if I told you it never ended up there.
All Things Considerateded
In general, I’d stick to using the inline index creation syntax. If I had to work around issues with that, I’d create the index after loading data, but being on Standard Edition brings some additional considerations around parallel index creation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Intermediate result materialization is one of the most successful tuning methods that I regularly use.
Separating complexity is only second to eliminating complexity. Of course, sometimes those intermediate results need indexing to finish the job.
Not always. But you know. I deal with some weird stuff.
Like anime weird.
Listings!
Regular ol’ #temp tables can have just about any kind of index plopped on them. Clustered, nonclustered, filtered, column store (unless you’re using in-memory tempdb with SQL Server 2019). That’s nice parity with regular tables.
Of course, lots of indexes on temp tables have the same problem as lots of indexes on regular tables. They can slow down loading data in, especially if there’s a lot. That’s why I usually tell people load first, create indexes later.
There are a couple ways to create indexes on #temp tables:
Create, then add
/*Create, then add*/
CREATE TABLE #t (id INT NOT NULL);
/*insert data*/
CREATE CLUSTERED INDEX c ON #t(id);
Create inline
/*Create inline*/
CREATE TABLE #t(id INT NOT NULL,
INDEX c CLUSTERED (id));
It depends on what problem you’re trying to solve:
Recompiles caused by #temp tables: Create Inline
Slow data loads: Create, then add
Another option to help with #temp table recompiles is the KEEPFIXED PLAN hint, but to wit I’ve only ever seen it used in sp_WhoIsActive.
Forgotten
Often forgotten is that table variables can be indexed in many of the same ways (at least post SQL Server 2014, when the inline index create syntax came about). The only kinds of indexes that I care about that you can’t create on a table variable are column store and filtered (column store generally, filtered pre-2019).
Other than that, it’s all fair game.
DECLARE @t TABLE( id INT NOT NULL,
INDEX c CLUSTERED (id),
INDEX n NONCLUSTERED (id) );
You can create clustered and nonclustered indexes on them, they can be unique, you can add primary keys.
It’s a whole thing.
Futuristic
In SQL Server 2019, we can also create indexes with included columns and filtered indexes with the inline syntax.
CREATE TABLE #t( id INT,
more_id INT,
INDEX c CLUSTERED (id),
INDEX n NONCLUSTERED (more_id) INCLUDE(id),
INDEX f NONCLUSTERED (more_id) WHERE more_id > 1 );
DECLARE @t TABLE ( id INT,
more_id INT,
INDEX c CLUSTERED (id),
INDEX n NONCLUSTERED (more_id) INCLUDE(id),
INDEX F NONCLUSTERED (more_id) WHERE more_id > 1 );
Missing Persons
Notice that I’m not talking about CTEs here. You can’t index create indexes on those.
Perhaps that’s why they’re called “common”.
Yes, you can index the underlying tables in your query, but the results of CTEs don’t get physically stored anywhere that would allow you to create an index on them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s say you’re on SQL Server 2019. No, seriously. It’s been out for a couple weeks now.
You could be.
I say that you could be because you’re the kind of brave person who tries new things and experiments with their body server.
You may even do crazy things like this.
Stone Cold
CREATE TABLE #t ( id INT, INDEX c CLUSTERED COLUMNSTORE );
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
JOIN dbo.Comments AS c
ON u.Id = c.UserId
LEFT JOIN #t AS t ON 1 = 0;
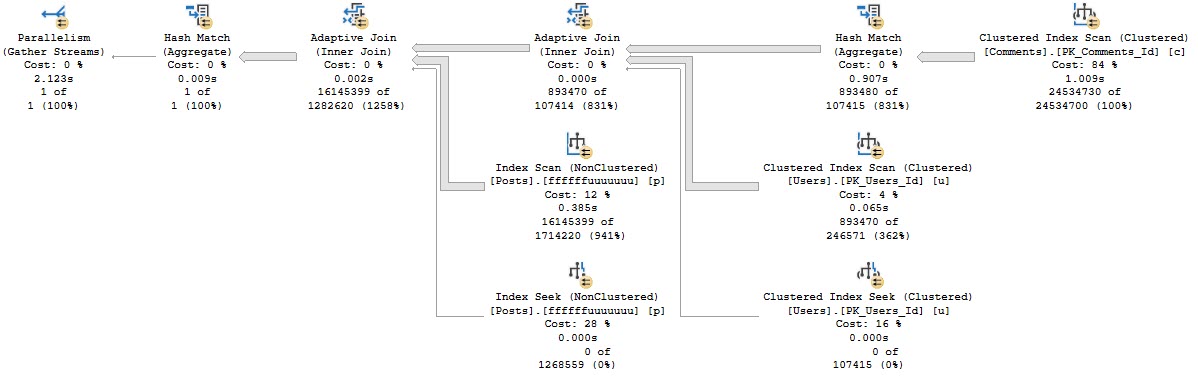
Woah ho ho. What happened there? A #temp table with a clustered column store index on it left joined on 1 = 0?
Yes. People do this.
People do this because it’s getting some batch mode operations “for free”, which have the nasty habit of making big reporting queries run a lot faster.
Yonder Problem
When you enable 2019’s new in memory tempdb, which can really help with stuff tempdb needs help with, you may find yourself hitting errors.
Msg 11442, Level 16, State 1, Line 14
Columnstore index creation is not support in tempdb when memory-optimized metadata mode is enabled.
Msg 1750, Level 16, State 1, Line 14
Could not create constraint or index. See previous errors.
The good news is that this works with *real* tables, too.
CREATE TABLE dbo.t ( id INT, INDEX c CLUSTERED COLUMNSTORE );
SELECT COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = p.OwnerUserId
JOIN dbo.Comments AS c
ON u.Id = c.UserId
LEFT JOIN dbo.t AS t ON 1 = 0;
And you can get plans with all sorts of Batchy goodness in them.
Long way from home
Yeah, you’re gonna have to change some code, but don’t worry.
You’re the kind of person who enjoys that.
Right?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.