I swear It’s Not String Splitting
I have to do this a fair amount, and I always go look at this little cheat sheet that I have.
Then it occurred to me that it might be worth sharing the details here, in case anyone else runs into the same need.
The way I learned to do it is with SUBSTRING and CHARINDEX, which is a pretty common method.
Why CHARINDEX? Because it accepts an optional 3rd parameter that PATINDEX doesn’t, where you can give it a starting position to search. That comes in really handy! Let’s look at how.
The first thing we need for our test case is the starting point, which I’ve arbitrarily chosen as a colon in error messages.
SELECT
m.*,
parsed_string =
SUBSTRING
(
m.text, /*First argument*/
CHARINDEX(':', m.text), /*Second argument*/
LEN(m.text)/*Third argument*/
)
FROM sys.messages AS m
WHERE m.language_id = 1033
AND m.text LIKE N'%:%:%';
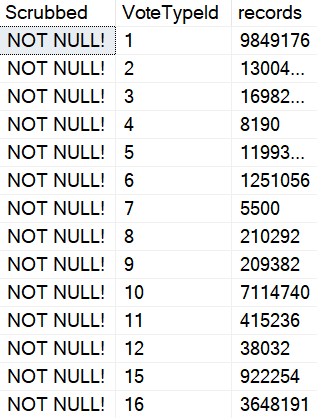
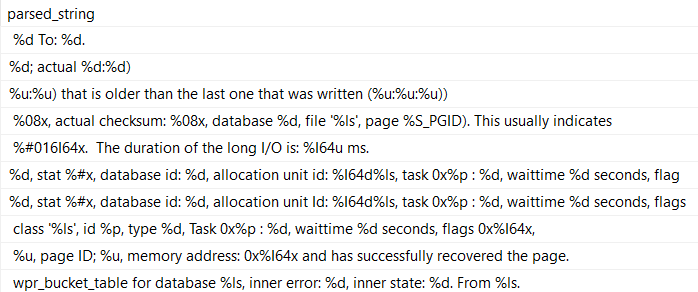
But the results aren’t exactly what we want! We can still see all the colons.
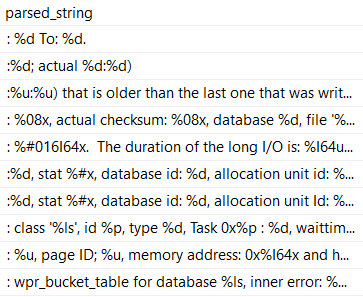
What we really need is to cut out the semi-colon, which means we need to move one character over.
Keep in mind that this will change based on the length of the string you’re searching for. If you were looking for ‘Erik’, you’d need to move over four positions.
Sometimes it’s easier to remember that by calling LEN on the search string.
SELECT
m.*,
SUBSTRING
(
m.text,
CHARINDEX(':', m.text) + LEN(':'),
LEN(m.text)
) AS parsed_string
FROM sys.messages AS m
WHERE m.language_id = 1033
AND m.text LIKE N'%:%:%';
That’ll get us to where we need to be for the first position! Now we need to get the text up to the second colon, which is where things get a little more complicated.
Right now, we’re just getting everything through the end of the error message, using LEN as the 3rd argument to SUBTSTRING.
To start with, let’s establish how we can use the third argument in CHARINDEX.
SELECT
m.*,
SUBSTRING
(
m.text,
CHARINDEX
(
':', m.text
) + LEN(':'),
CHARINDEX
(
':',
m.text, /*!*/
CHARINDEX
(
':',
m.text
) + LEN(':')/*!*/
)
) AS parsed_string
FROM sys.messages AS m
WHERE m.language_id = 1033
AND m.text LIKE N'%:%:%';
The start of the third argument is going to look nearly identical to the first one, except we’re going to start our search in the string after the first colon.
The code in between the exclamation points is the same as the second argument to SUBSTRING.
That’s because it gives us the correct starting position to start looking for the second colon from.
But, you know, this still doesn’t get us what we need, exactly. We need to chop some characters off.
How many?
I’ll save you some delicate CPU brain cycles: we need to subtract the length of the search string, and then subtract the number of positions in that the first search hit was.
SELECT
m.*,
SUBSTRING
(
m.text, /*First argument*/
CHARINDEX /*Begin Second argument*/
(
':',
m.text
) + LEN(':'), /*End Second argument*/
CHARINDEX /*Begin Third argument*/
(
':', /*CHARINDEX of the first : after...*/
m.text,
CHARINDEX /*The CHARINDEX of the first : in the string...*/
(
':',
m.text
) + LEN(':')
)
- LEN(':') /*Minus 1, effectively*/
- CHARINDEX(':', m.text) /*Minus the CHARINDEX of the first : in the string*/
/*End Third argument*/
) AS parsed_string
FROM sys.messages AS m
WHERE m.language_id = 1033
AND m.text LIKE N'%:%:%';
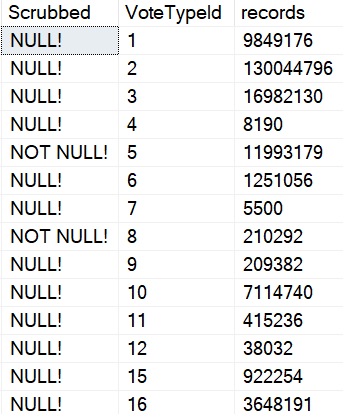
Which finally gives us what we’re asking for:
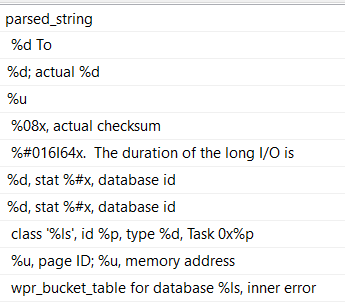
Now, this may not make you totally happy. After all, there are still leading and trailing spaces on each line.
If you want to get rid of those, you can either adjust your LEN functions, or you can call TRIM, LTRIM/RTRIM on the final result. I don’t care, really.
They’re your strings. They shouldn’t even be in the database.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.