Injectables
Dynamic SQL is always a hot topic. I love using it. Got a lot of posts about it.
Recently, while answering a question about it, it got me thinking about safety when accepting table names as user input, among other things.
The code in the answer looks like this:
CREATE OR ALTER PROCEDURE dbo.SelectWhatever (@SchemaName sysname, @TableName sysname)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE @SafeSchema sysname = NULL,
@SafeTable sysname = NULL,
@SQL NVARCHAR(MAX) = N'';
SELECT @SafeSchema = SCHEMA_NAME(t.schema_id),
@SafeTable = t.name
FROM sys.tables AS t
WHERE t.schema_id = SCHEMA_ID(ISNULL(@SchemaName, 'dbo'))
AND t.name = ISNULL(@TableName, 'SomeKnownTable');
IF (@SafeSchema IS NULL)
BEGIN
RAISERROR('Invalid schema: %s', 0, 1, @SchemaName) WITH NOWAIT;
RETURN;
END;
IF (@SafeTable IS NULL)
BEGIN
RAISERROR('Invalid table: %s', 0, 1, @TableName) WITH NOWAIT;
RETURN;
END;
SET @SQL += N'
SELECT TOP (100) *
/*dbo.SelectWhatever*/
FROM ' + QUOTENAME(@SafeSchema)
+ N'.'
+ QUOTENAME(@SafeTable)
+ N';';
RAISERROR('%s', 0, 1, @SQL) WITH NOWAIT;
EXEC sys.sp_executesql @SQL;
END;
Sure, there are other things that I could have done, like used OBJECT_ID() and SCHEMA_ID() functions to validate existence, but I sort of like the idea of hitting the system view, because if you follow that pattern, you could expand on it if you need to accept and validate column names, too.
Expansive
Yeah, I’m using some new-version-centric stuff in here, because I uh… I can. Thanks.
If you need examples of how to split strings and create CSVs, get them from the zillion other examples on the internet.
CREATE OR ALTER PROCEDURE dbo.SelectWhatever (@SchemaName sysname, @TableName sysname, @ColumnNames NVARCHAR(MAX))
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE @SafeSchema sysname = NULL,
@SafeTable sysname = NULL,
@SafeColumns NVARCHAR(MAX) = NULL,
@SQL NVARCHAR(MAX) = N'';
SELECT @SafeSchema = SCHEMA_NAME(t.schema_id),
@SafeTable = t.name
FROM sys.tables AS t
WHERE t.schema_id = SCHEMA_ID(ISNULL(@SchemaName, 'dbo'))
AND t.name = ISNULL(@TableName, 'SomeKnownTable');
SELECT @SafeColumns = STRING_AGG(QUOTENAME(c.name), ',')
FROM sys.columns AS c
WHERE c.object_id = OBJECT_ID(@SafeSchema + N'.' + @SafeTable)
AND c.name IN ( SELECT TRIM(ss.value)
FROM STRING_SPLIT(@ColumnNames, ',') AS ss );
IF (@SafeSchema IS NULL)
BEGIN
RAISERROR('Invalid schema: %s', 0, 1, @SchemaName) WITH NOWAIT;
RETURN;
END;
IF (@SafeTable IS NULL)
BEGIN
RAISERROR('Invalid table: %s', 0, 1, @TableName) WITH NOWAIT;
RETURN;
END;
IF (@SafeColumns IS NULL)
BEGIN
RAISERROR('Invalid column list: %s', 0, 1, @ColumnNames) WITH NOWAIT;
RETURN;
END;
SET @SQL += N'
SELECT TOP (100) '
+ @SafeColumns
+ N'
/*dbo.SelectWhatever*/
FROM ' + QUOTENAME(@SafeSchema)
+ N'.'
+ QUOTENAME(@SafeTable)
+ N';';
RAISERROR('%s', 0, 1, @SQL) WITH NOWAIT;
EXEC sys.sp_executesql @SQL;
END;
Normally I’d raise hell about someone using a function like STRING_SPLIT in a where clause, but for simple DMV queries you’re not likely to see a significant perf hit.
There’s a lot of stuff you’ll see in DMV queries that are not okay in normal queries.
Some explanations
It would be nice if we had a dynamic SQL data type that did some of this stuff for us. Sort of like XML document validation with less obtuse error messages.
Until that time which will never come, we have to do the hard work. One way to make your dynamic SQL a little bit safer is to keep user inputs as far away from the execution as you can.
In the above example, I declare a separate set of variables to hold values, and only use what a user might enter in non-dynamic SQL blocks, where they can’t do any harm.
If there’s anything goofy in them, the “@Safe” variables end up being NULL, and an error is thrown.
Also, I’m using QUOTENAME on every individual object: Schema, Table, and Column, to cut down on any potential risks of naughty object values being stored there. If I had to do this for a database name, that’d be an easy add on, using sys.databases.
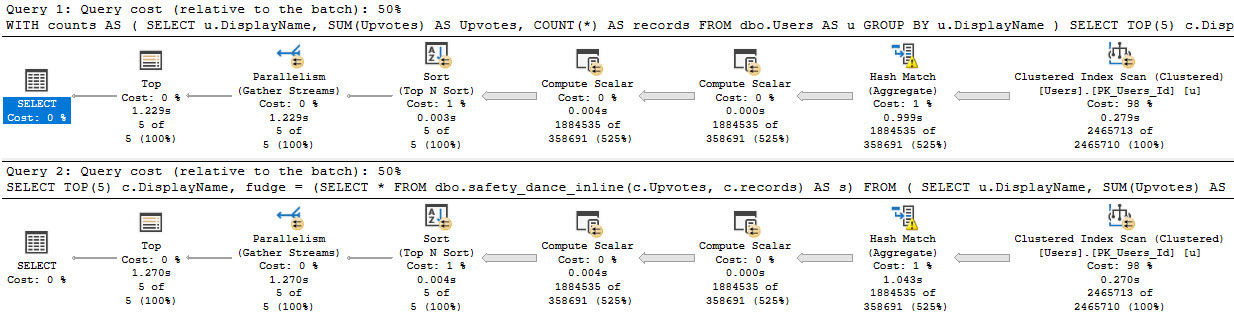
If you’ve got to work with stringy input for dynamic SQL, this is one way to make the ordeal a bit more safe. You can also extend that to easier to locate key values, like so:
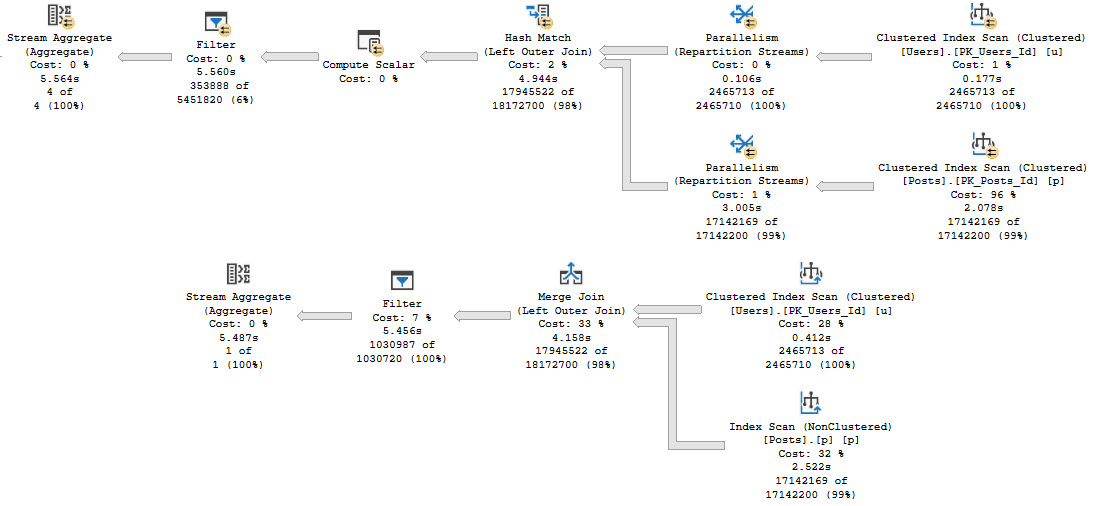
CREATE PROCEDURE dbo.SaferStringSearch (@UserEquals NVARCHAR(40) = NULL, @UserLike NVARCHAR(40))
AS
SET NOCOUNT, XACT_ABORT ON
BEGIN
CREATE TABLE #ids(id INT NOT NULL PRIMARY KEY);
INSERT #ids WITH (TABLOCK) ( id )
SELECT u.Id
FROM dbo.Users AS u
WHERE u.DisplayName = @UserEquals
UNION
SELECT u.Id
FROM dbo.Users AS u
WHERE u.DisplayName LIKE @UserLike;
DECLARE @SQL NVARCHAR(MAX) = N'
SELECT p.*
FROM dbo.Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM #ids AS i
WHERE i.id = p.OwnerUserId
);
';
EXEC sp_executesql @SQL;
END;
I get that this isn’t the most necessary use of dynamic SQL in the world, it’s really just a simple way to illustrate the idea.
Stay Safe
If you’ve got to pass strings to dynamic SQL, these are some ways to make the process a bit safer.
In the normal course of things, you should parameterize as much as you can, of course.
For search arguments, that’s a no-brainer. But for objects, you can’t do that. Why? I don’t know.
I’m not a programmer, after all.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.