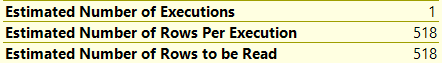Underfoot
There are all sorts of things that might artificially keep the optimizer from suggesting a helpful index while you’re writing or tuning a query.
But go figure, there are also totally sensible things that will make it less likely that you’ll get one, and there are definitely things that the requests don’t consider as heavily.
That doesn’t mean they’re awful and wrong, it just means you should practice looking at the requests that get generated with execution plans to see if there’s anything you can tweak to make things run a little bit more smoothly.
Anyway, let’s learn some important lessons about missing index requests.
Lesson One: Inequalities Are Iffy
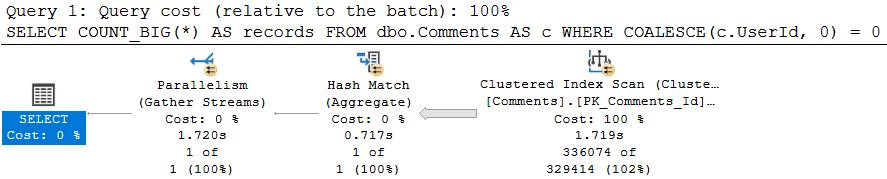
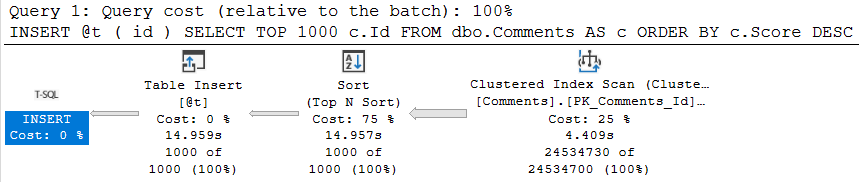
In my copy of the Stack Overflow database, both of these queries return the same single row.
There is only one comment with 1270(!!!) upvotes, so either query works to locate the data.
/*Inequality predicate*/
SELECT c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score >= 1270 --Hello I'm here
AND c.CreationDate >= '20110101'
AND c.CreationDate < '20120101'
ORDER BY c.CreationDate DESC;
/*Equality predicate*/
SELECT c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score = 1270 --Hello I'm here
AND c.CreationDate >= '20110101'
AND c.CreationDate < '20120101'
ORDER BY c.CreationDate DESC;
Strangely, only one query qualifies for a missing index request, and it’s not the first one.
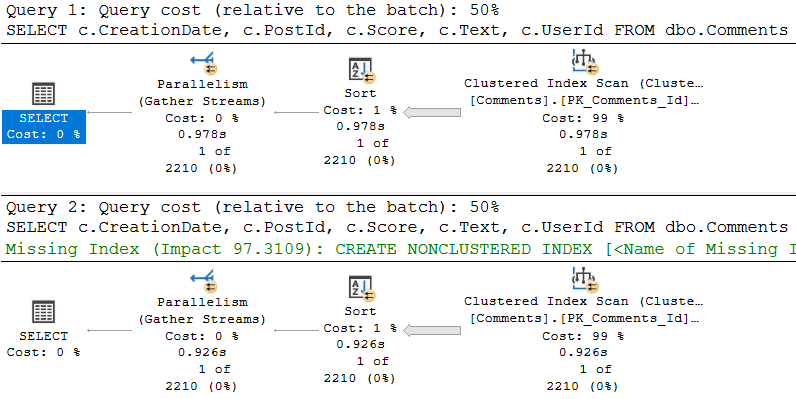
The index request look like this:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[Comments] ([Score],[CreationDate]) INCLUDE ([PostId],[Text],[UserId])
Which is likely fine, as long as you’re okay with the Text column being in there. It’s an NVARCHAR(700), which makes me a little hesitant.
Not adding it, of course, means the optimizer would have to make a choice about Key Lookups vs. Clustered Index Scans, depending on predicates.
Databases are hard.
Lesson Two: Joins Don’t Get A Lot Of Love
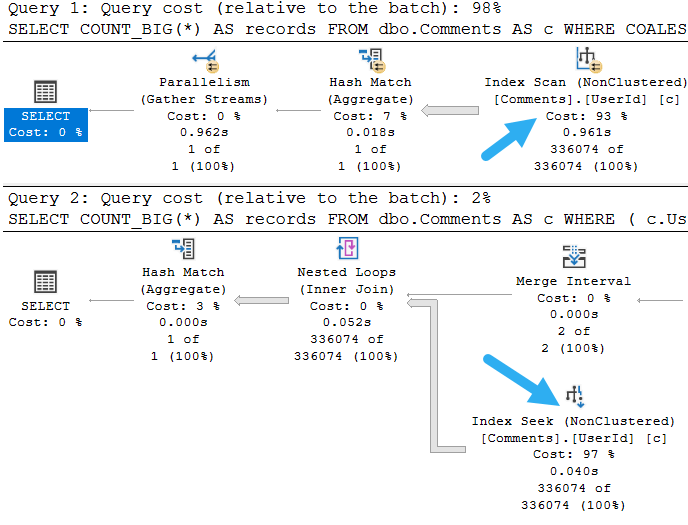
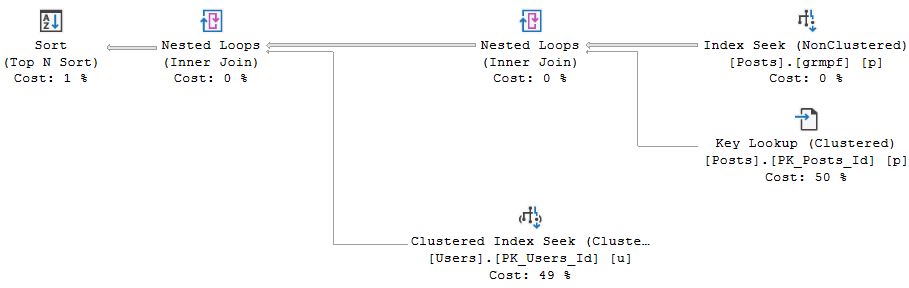
If we add a join to the Posts table, the missing index request doesn’t change.
SELECT c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
JOIN dbo.Posts AS p
ON p.Id = c.PostId
AND p.OwnerUserId = c.UserId
WHERE c.Score = 1270 --Hello I'm here
AND c.CreationDate >= '20110101'
AND c.CreationDate < '20120101'
AND 1 = (SELECT 1)
ORDER BY c.CreationDate DESC;
We get the same missing index request as above, which might strike you as a little odd.

Sometimes it’s nice to have join columns in the key of an index. Orderly data tends to join more easily, and can give the optimizer more efficient ways to do it.
It probably doesn’t matter a ton for Hash Joins, but Merge Joins expect data in order. If it’s not, the optimizer will introduce a Sort to get it in order. Likewise, Nested Loops without indexes can be painful.
Having columns as includes means it’s not stored in an order that might be helpful. In fact, it’s not stored in any order at all.
Lesson Three: Neither Does Order By
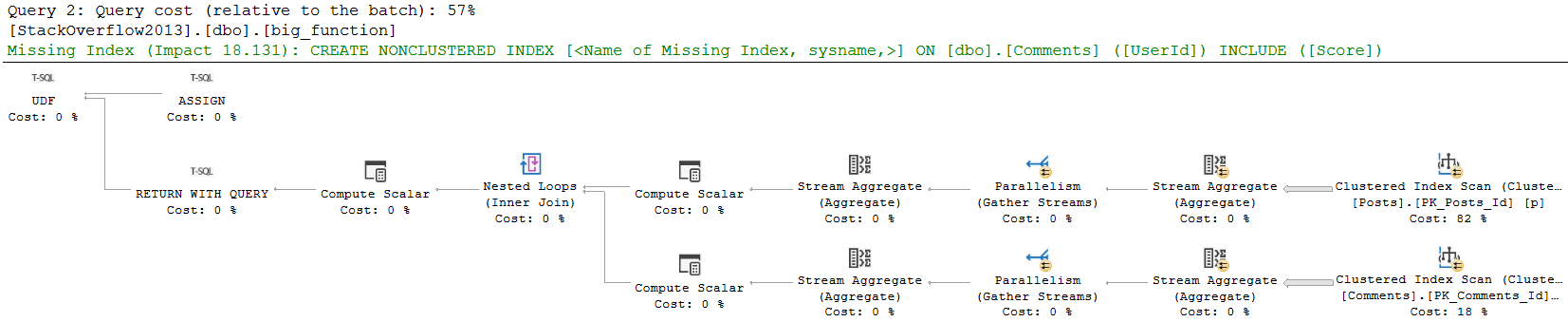
In our original query, the CreationDate column, by coincidence, was both in the WHERE and ORDER BY clauses.
It ended up in the key columns of the index because of the WHERE clause, though. If we remove it from there, it’ll move to the included columns.
SELECT c.CreationDate,
c.PostId,
c.Score,
c.Text,
c.UserId
FROM dbo.Comments AS c
WHERE c.Score = 1270 --Hello I'm here
ORDER BY c.CreationDate DESC;

Why Are We Talking About Indexes Again?
If I do enough drilling, hopefully you’ll understand how important they are to performance.
What I want you to take away from this post is that when you’re looking specifically at missing index requests, whether they’re in query plans or in the missing index DMVs:
- They’re not going to consider columns outside of the WHERE clause to be in the key of the index
- If your where clause doesn’t have an equality predicate, it’s a lot harder to get missing index requests
- Columns that would be helpful to have in index order won’t end up in the key if they’re not in the WHERE
- Even the order of columns suggested for being in the key of the index isn’t scientific
I covered a lot of the “why” in these posts:
Without them, it may look weird to spend time talking about the limitations here. But this is why databases still need humans to care for them.
As much as I look forward to a day where they don’t, little things like which columns should be in the key of an index, and the order they should be in, are still important considerations.
You know. Little things.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.