Big Think
Most people fire off their index and statistics maintenance jobs with the default options and do just fine. Sometimes, though, statistics need a little bit more consideration, and I get a lot of questions about them.
- Do I need to use a sampling rate other than the default?
- Do I need to use FULLSCAN?
- What if auto update stats ruins my good statistics?
- Should I update statistics asynchronously?
- Are there easy ways to tell if my statistics are causing problems?
There are a lot of local factors involved in answering these questions, and I can’t cover all of them in this post, but I can outline some general patterns I see when people have these concerns.
Is The Default Sampling Rate Good Enough?
Look — usually it is — I know you hate to hear it. You want to be that special edge case where it’s not. Moreover, it’s really efficient.
The tradeoff you make between higher sampling rates and better statistics and time it takes to update stats can be significant, especially on larger tables. And a lot of the time, those 201 histogram steps don’t end up a whole lot more informing than before.
I’m not saying never, but in particular the difference between 75% and 100% scans is kinda ?♂️
Do I Need A Full Scan?
If you’re at the point where you’re asking this question, you’re in one of two situations:
- You’re just starting out with stats updates
- You’re unhappy with the way your stats look now
If you’re just starting out, stop right here and just make sure you’re keeping them updated regularly.
If you’re unhappy with the way they look because of the way updates — manual or automatic — are going now, you might want to think about creating filtered statistics on the parts of the data that aren’t well-reflected by them.
Is Auto Update Stats Bad?
No, not usually. It can be quite helpful. Especially on supported versions of SQL Server where trace flag 2371 is the default behavior, it doesn’t take as many modifications for them to happen on large tables.
This can better help you avoid the ascending key problem that used to really hurt query plans, where off-histogram values got some really bad estimates. That’s somewhat addressed in higher compat levels, but I’ve still seen some wonkiness.
If you don’t want auto update stats to ruin your higher sampling rates, you probably wanna use the PERSIST_SAMPLE_PERCENT option, with your chosen value.
But again, you wanna be careful with this on big tables, and this is when you might also wanna use…
Asynchronous Stats Updates
This setting can be really useful for avoiding long running queries while waiting for updated stat histograms to be available. The downside is that you might hit some woof query plans until the background task does its thing and the plans get invalidated.
Make sure you’re solving the right problem by flipping this switch. SQL Server 2019 can help you figure out if this is something you’re hitting regularly, with the WAIT_ON_SYNC_STATISTICS_REFRESH wait type. Keep in mind this only shows up when stats are refreshed. Not when they’re created initially.
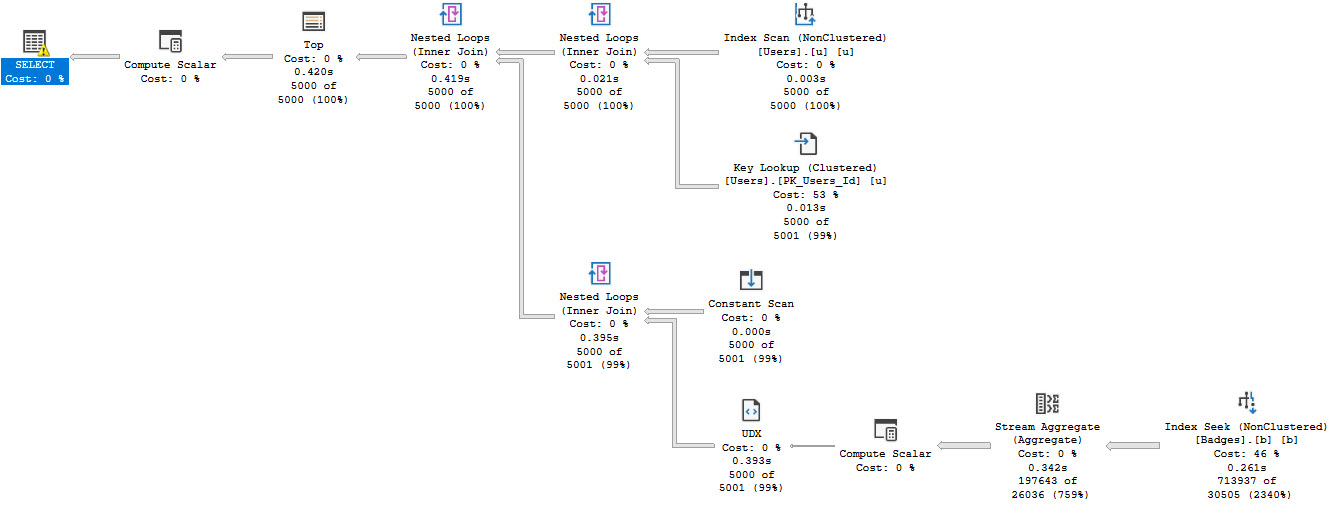
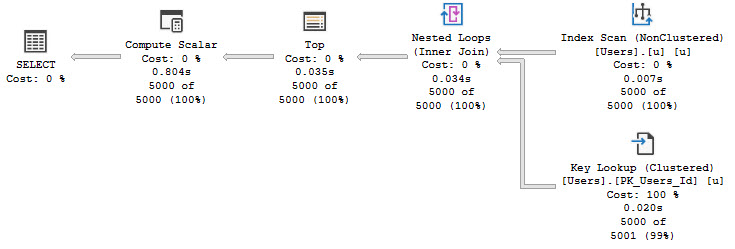
You can also see stuff like this crop up in monitoring tools and query store when queries take a while, but they’re doing stuff like SELECT StatMan.
Are Statistics My Problem?
I see a lot of people blaming statistics, when they’re really doing other stuff wrong.
There are many ways to write a query that are equivalent to the Calvin Peeing™ decal, with cardinality estimation being on the receiving end, like eschewing SARGability, or using local variables or table variables.
Another common issue is around cached plans and parameter sniffing. Those inaccurate guesses might have been really accurate for the compiled parameters, but not for the runtime parameters.
There are a lot of query hints that can help you figure out if statistics are the problem, or if there’s something in the cardinality estimation process that’s yucking things up.
- ASSUME_JOIN_PREDICATE_DEPENDS_ON_FILTERS
- ASSUME_MIN_SELECTIVITY_FOR_FILTER_ESTIMATES
- ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS
- FORCE_LEGACY_CARDINALITY_ESTIMATION
- FORCE_DEFAULT_CARDINALITY_ESTIMATION
I use this pretty regularly to see if they end up giving me a better plan. They don’t always pan out, but it’s worth trying when what you get ain’t what you want.
Just remember that things like query complexity will have a lot to do with how accurate the estimates you get are. Chaining together a bunch of CTEs, derived tables, views, or 20 joins usually isn’t gonna end up well for you, or your query plan.
There are many times when I see people complaining that statistics are bad or out of date, and basic stuff like proper indexes aren’t there.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.