In A Row?
When you’re reading query plans, you can be faced with an overwhelming amount of information, and some of it is only circumstantially helpful.
Sometimes when I’m explaining query plans to people, I feel like a mechanic (not a Machanic) who just knows where to go when the engine makes a particular rattling noise.
That’s not the worst thing. If you know what to do when you hear the rattle next time, you learned something.
One particular source of what can be a nasty rattle is query plan operators that execute a lot.
Busy Killer Bees
I’m going to talk about my favorite example, because it can cause a lot of confusion, and can hide a lot of the work it’s doing behind what appears to be a friendly little operator.
Something to keep in mind is that I’m looking at the actual plans. If you’re looking at estimated/cached plans, the information you get back may be inaccurate, or may only be accurate for the cached version of the plan. A query plan reused by with parameters that require a different amount of work may have very different numbers.
Nested Loops
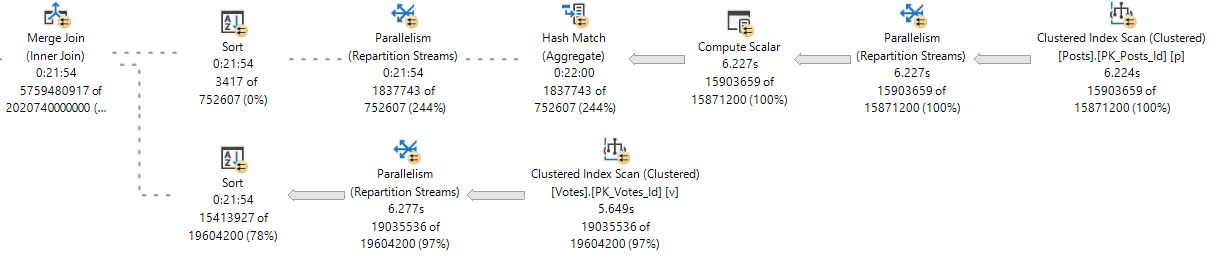
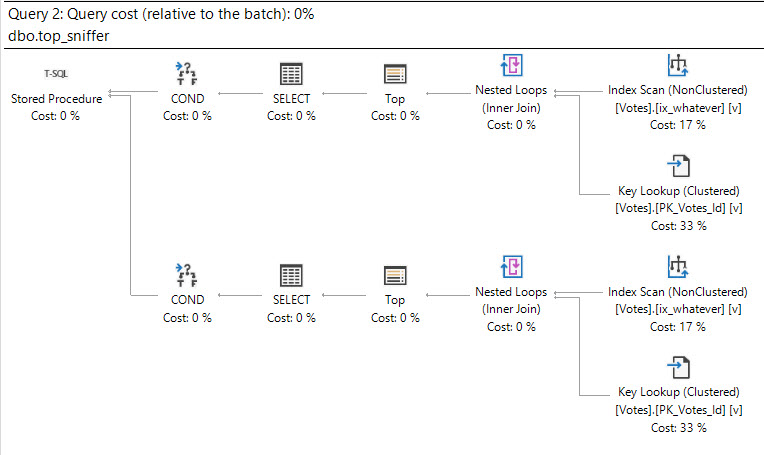
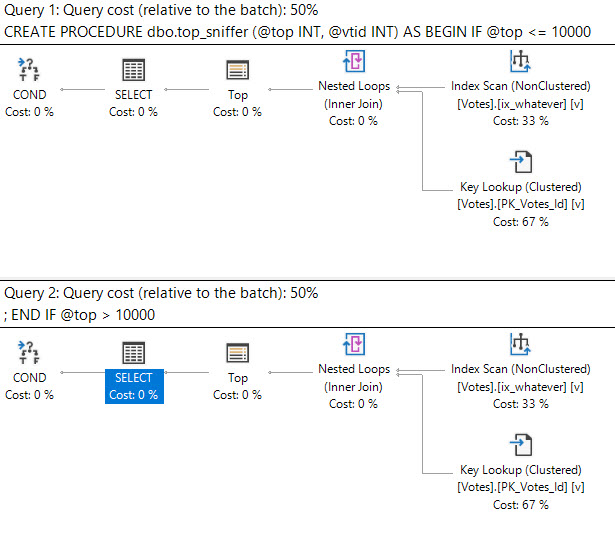
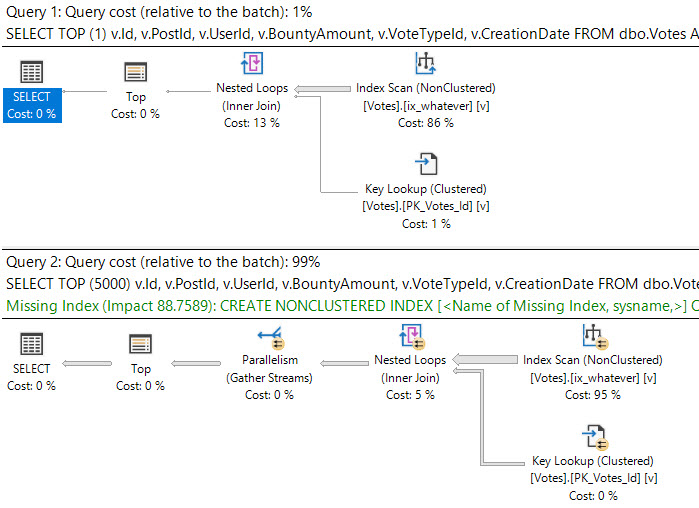
Let’s look at a Key Lookup example, because it’s easy to consume.
CREATE INDEX ix_whatever ON dbo.Votes(VoteTypeId); SELECT v.VoteTypeId, v.BountyAmount FROM dbo.Votes AS v WHERE v.VoteTypeId = 8 AND v.BountyAmount = 100;
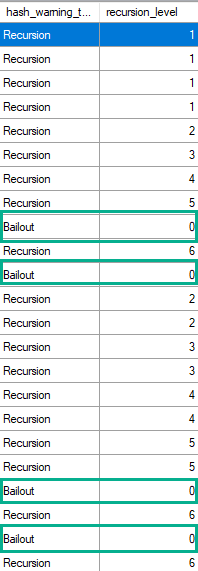
You’d think with “loops” in the name, you’d see the number of executions of the operator be the number of loops SQL Server thinks it’ll perform.
But alas, we don’t see that.
In a parallel plan, you may see the number of executions equal to the number of threads the query uses for the branch that the Nested Loops join executes in.
For instance, the above query runs at MAXDOP four, and coincidentally uses four threads for the parallel nested loops join. That’s because with parallel nested loops, each thread executes a serial version of the join independently. With stuff like a parallel scan, threads work more cooperatively.
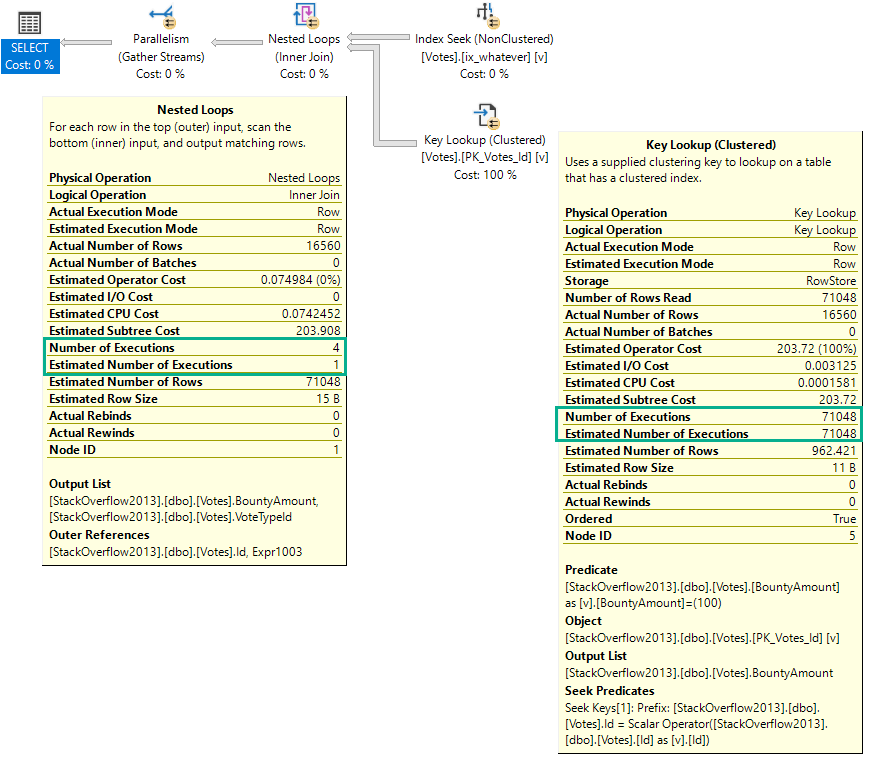
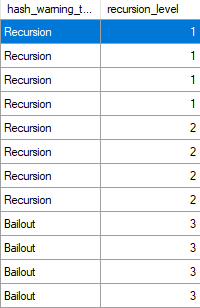
If we re-run the same query at MAXDOP 1, the number of executions drops to 1 for the nested loops operator, but remains at 71,048 for the key lookup.
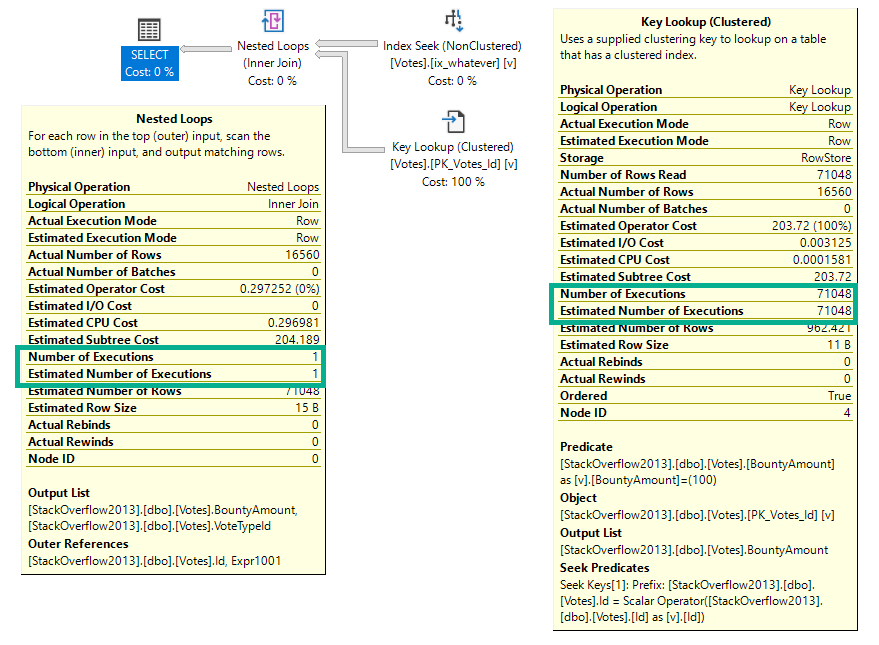
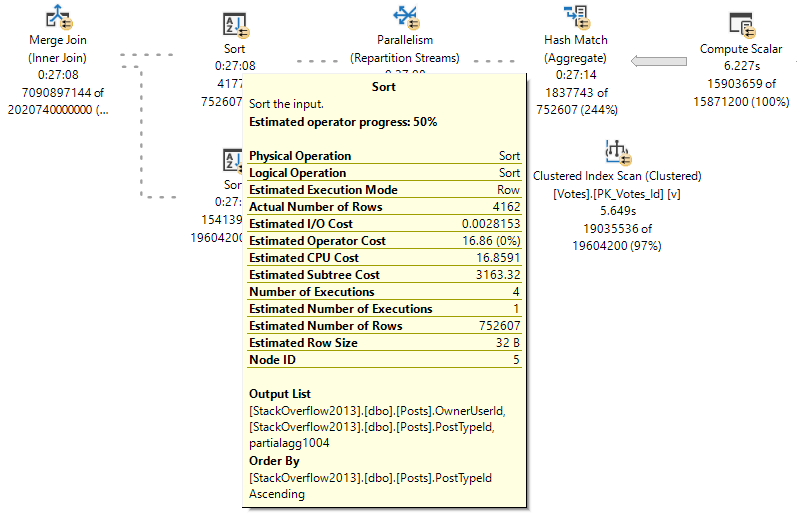
But here we are at the very point! It’s the child operators of the nested loops join that show how many executions there were, not the nested loops join itself.
Weird, right?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.