SEMA4
While working with a client, I came up with a query against the SentryOne repository.
The point of it is to find queries that waited more than a second to get a memory grant. I wrote it because this information is logged but not exposed in the GUI yet.
It will show you basic information about the collected query, plus:
- How long it ran in seconds
- How long it waited for memory in seconds
- How long it ran for after it got memory
SELECT HostName,
CPU,
Reads,
Writes,
Duration,
StartTime,
EndTime,
TextData,
TempdbUserKB,
GrantedQueryMemoryKB,
DegreeOfParallelism,
GrantTime,
RequestedMemoryKB,
GrantedMemoryKB,
RequiredMemoryKB,
IdealMemoryKB,
Duration / 1000. AS DurationSeconds,
DATEDIFF(SECOND, StartTime, GrantTime) AS SecondsBetweenQueryStartingAndMemoryGranted,
(Duration - DATEDIFF(MILLISECOND, StartTime, GrantTime)) / 1000. AS HowFastTheQueryRanAfterItGotMemory
FROM PerformanceAnalysisTraceData
WHERE DATEDIFF(SECOND, StartTime, GrantTime) > 1
ORDER BY SecondsBetweenQueryStartingAndMemoryGranted DESC
The results I saw were surprising! Queries that waited 10+ seconds for memory, but finished instantly when they finally got memory.
If you’re a Sentry One user, you may find this helpful. If you find queries waiting a long time for memory, you may want to look at if you’re hitting RESOURCE_SEMAPHORE waits too.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
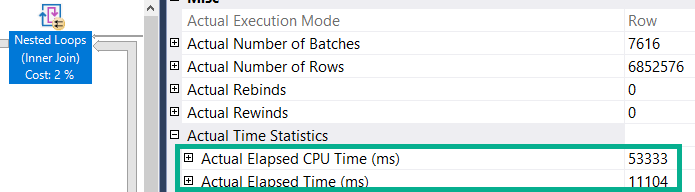




 I set Max Server Memory to 8000 MB and executed two queries with a maximum allowed memory grant of 60% via Resource Governor. The first query finished in about 40 seconds. The second query hasn’t finished after 30 minutes. During those 30 minutes the second query has only used 1184 ms of CPU time. The COLUMNSTORE_BUILD_THROTTLE wait type shows up in
I set Max Server Memory to 8000 MB and executed two queries with a maximum allowed memory grant of 60% via Resource Governor. The first query finished in about 40 seconds. The second query hasn’t finished after 30 minutes. During those 30 minutes the second query has only used 1184 ms of CPU time. The COLUMNSTORE_BUILD_THROTTLE wait type shows up in  Execution context id 2 is waiting on execution context id 1 with a wait type of HTDELETE. Execution context id 1 has a wait type of COLUMNSTORE_BUILD_THROTTLE. I don’t think that this wait is supposed to show up for parallel inserts. It can show up by design when
Execution context id 2 is waiting on execution context id 1 with a wait type of HTDELETE. Execution context id 1 has a wait type of COLUMNSTORE_BUILD_THROTTLE. I don’t think that this wait is supposed to show up for parallel inserts. It can show up by design when