Milk Carton
Part of reviewing any server necessarily includes reviewing indexes. When you’re working through things that matter, like unused indexes, duplicative indexes, heaps, etc. it’s pretty clear cut what you should do to fix them.
Missing indexes are a different animal though. You have three general metrics to consider with them:
- Uses: the number of times a query could have used the index
- Impact: how much the optimizer thinks it can reduce the cost of the query by
- Query cost: How much the optimizer estimates the query will cost to run
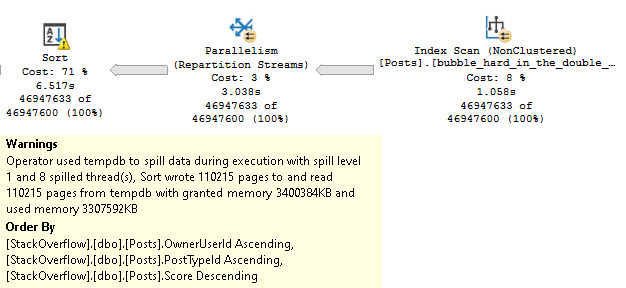
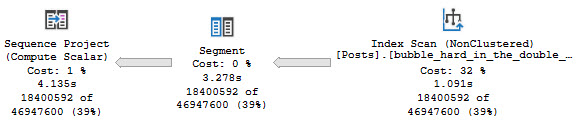
Of those metrics, impact and query cost are entirely theoretical. I’ve written quite a bit about query costing and how it can be misleading. If you really wanna get into it, you can watch the whole series here.
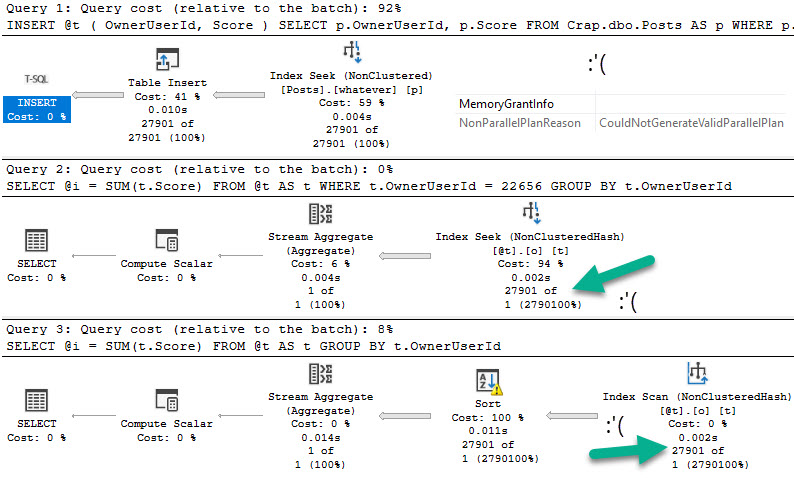
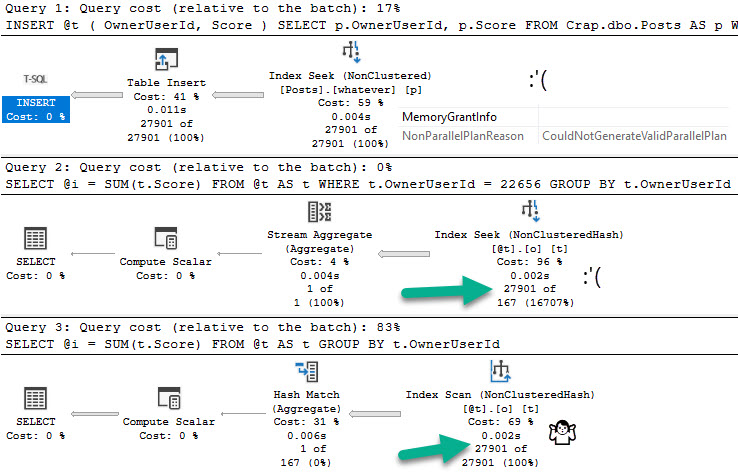
In short: you might have very expensive queries that finish very quickly, and you might have very low cost queries that finish very slowly.
Especially in cases of parameter sniffing, a query plan with a very low cost might get compiled and generate a missing index request. What happens if every other execution of that query re-uses the cheaply-costed plan and runs for a very long time?
You might have a missing index request that looks insignificant.
Likewise, impact is how much the optimizer thinks it can reduce the cost of the current plan by. Often, you’ll create a new index and get a totally different plan. That plan may be more or less expensive that the previous plan. It’s all a duck hunt.
The most reliable of those three metrics is uses. I’m not saying it’s perfect, but there’s a bit less Urkeling there.
When you’re looking at missing index requests, don’t discount those with lots of uses for low cost queries. Often, they’re more important than they look.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.