Darnit
While helping a client out with a performance problem recently, I ran into something kind of funny when creating a computed column.
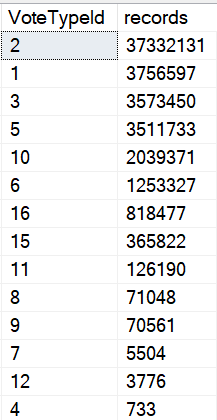
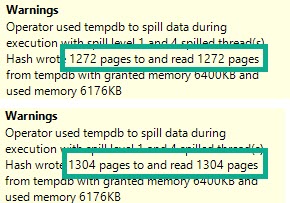
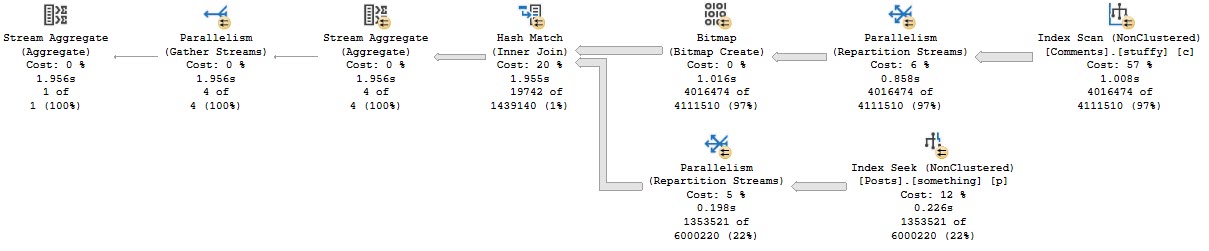
They were experiencing performance problems because of a join involving a substring.
Weird, right? Like, if I tried to show you this in a presentation, you’d chase me out of the room.
But since they were nice enough to hire me, I went about fixing the problem.
Computer Magic
The “obvious” — and I apologize if this isn’t obvious to you, dear reader — was to add a computed column to work around the issue.
Adding a computed column gives you the expression that you’re generating on the fly and trying to join on. Because manipulating column data while you’re joining or filtering on it is generally a bad idea. Sometimes you can get away with it.
But here’s something that messed me up, a uh… seasoned database professional.
The query was doing something like this (not exactly, but it’s good enough to get us moving):
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE SUBSTRING(u.DisplayName, 1, LEN(u.DisplayName) - 4)
= SUBSTRING(u.DisplayName, 1, LEN(u.DisplayName) - 4);
Matching strings from the beginning to the end minus four characters.
I wanted to look smart, so I did this:
ALTER TABLE dbo.Users
ADD DisplayNameComputed
AS SUBSTRING(DisplayName, 1, LEN(DisplayName) - 4);
I didn’t want to persist it right away — that can lock the table and take longer — and because I knew I was going to index it.
The problem is that when I tried to index it:
CREATE INDEX dummy
ON dbo.Users(DisplayNameComputed);
I got this error:
Msg 537, Level 16, State 3, Line 21
Invalid length parameter passed to the LEFT or SUBSTRING function.
And when I tried to select data from the table, the same error.
In the real query, there was a predicate that avoided columns with too few characters, but it was impossible to apply that filter to the index.
There’s also other restrictions on filtered index where clauses, like you can’t like LIKE ‘____%’, or LEN(col) > 4, etc.
Case Of Mace
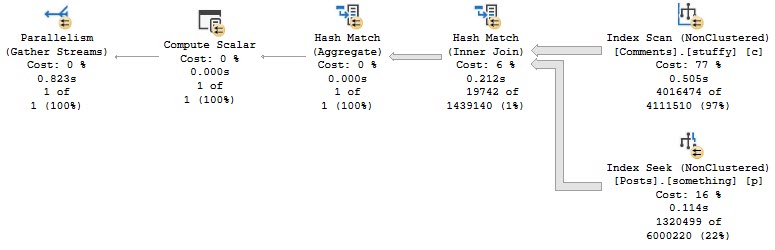
Having done a lot of string splitting in my life, I should have been more defensive in my initial computed column definition.
What I ended up using was this:
ALTER TABLE dbo.Users
ADD DisplayNameComputed
AS SUBSTRING(DisplayName, 1, LEN(DisplayName)
- CASE WHEN LEN(DisplayName) < 4 THEN LEN(DisplayName) ELSE 4 END);
A bit more verbose, but it allowed me to create my computed column, select from the table, and create my index.
AND THEY ALL LIVED HAPPILY EVER AFTER
Just kidding, there was still a lot of work to do.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.