Drop The Verse
Why is IS NULL (not to be confused with ISNULL, the function) considered an equality predicate, and IS NOT NULL considered an inequality (or range) predicate?
It seems like they should be fairly equivalent, though opposite. One tests for a lack of values, and one tests for the presence of values, with no further examination of what those values are.
The trickier thing is that we can seek to either condition, but what happens next WILL SHOCK YOU.
Ze Index
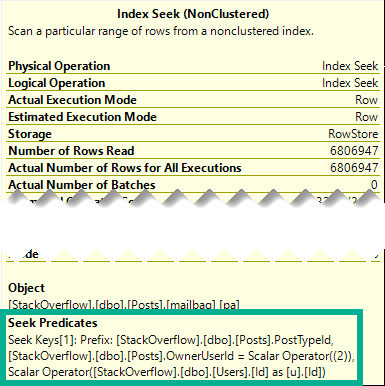
The leading column in this index is NULLable, and has a bunch of NULLs in it.
CREATE INDEX nully_baby
ON dbo.Posts(LastEditDate, Score DESC);
Knowing what we know about what indexes do to data, and since the LastEditDate column is sorted ascending, all of the NULL values will be first, and then within the population of NULLs values for Score will be sorted in descending order.
But once we get to non-NULL values, Score is sorted in descending order only within any duplicate date values. For example, there are 4000 some odd posts with a LastEditDate of “2018-07-09 19:34:03.733”.
Why? I don’t know.
But within that and any other duplicate values in LastEditDate, Score will be in descending order.
Proving It
Let’s take two queries!
SELECT TOP (5000)
p.LastEditDate,
p.Score
FROM dbo.Posts AS p
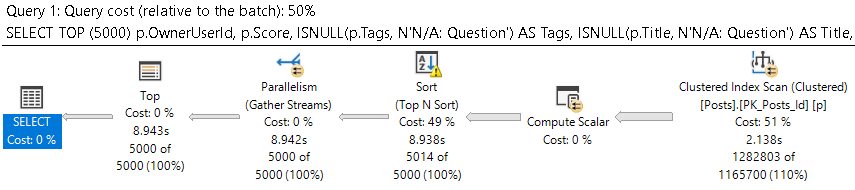
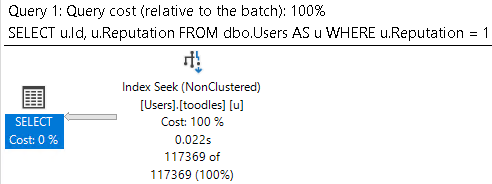
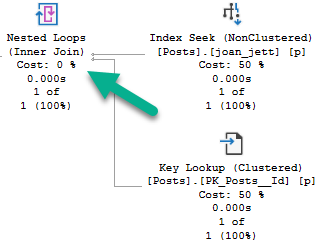
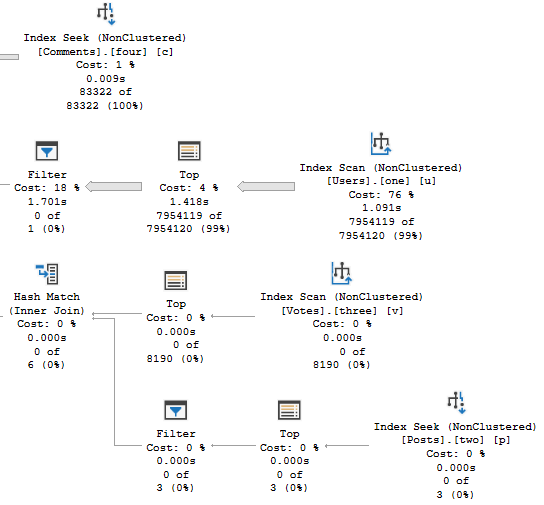
WHERE p.LastEditDate IS NULL
ORDER BY p.Score DESC;
SELECT TOP (5000)
p.LastEditDate,
p.Score
FROM dbo.Posts AS p
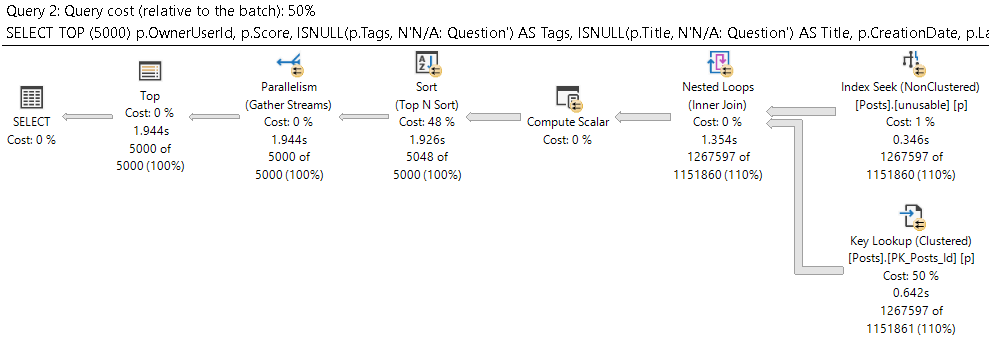
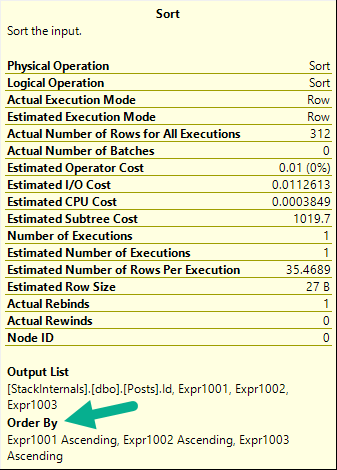
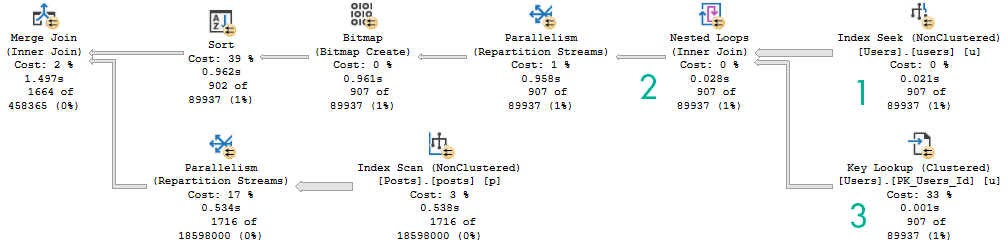
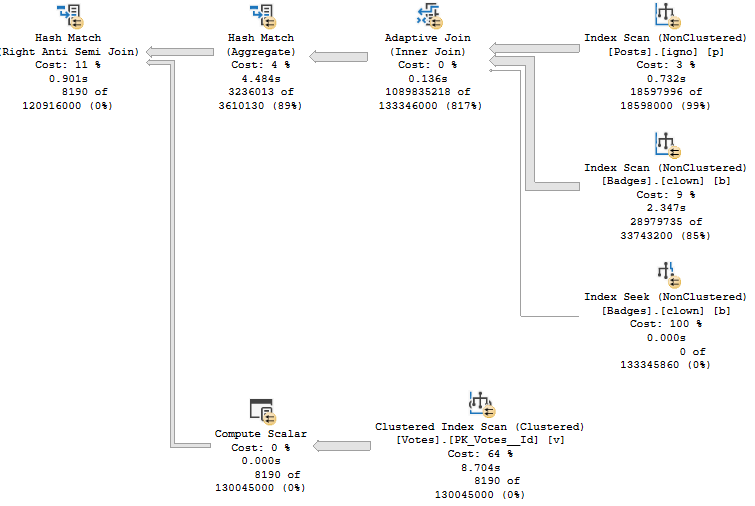
WHERE p.LastEditDate IS NOT NULL
ORDER BY p.Score DESC;
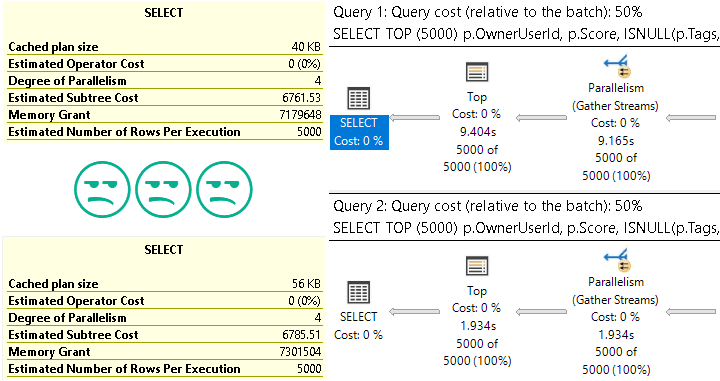
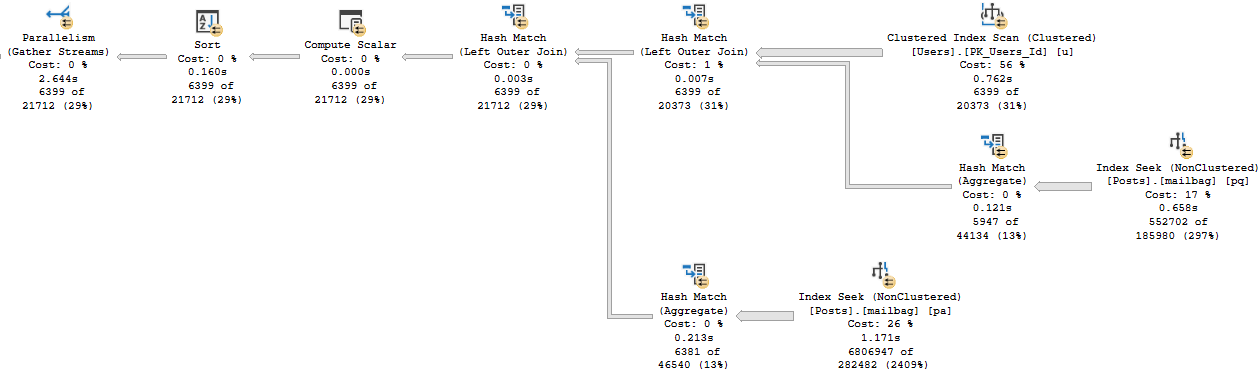
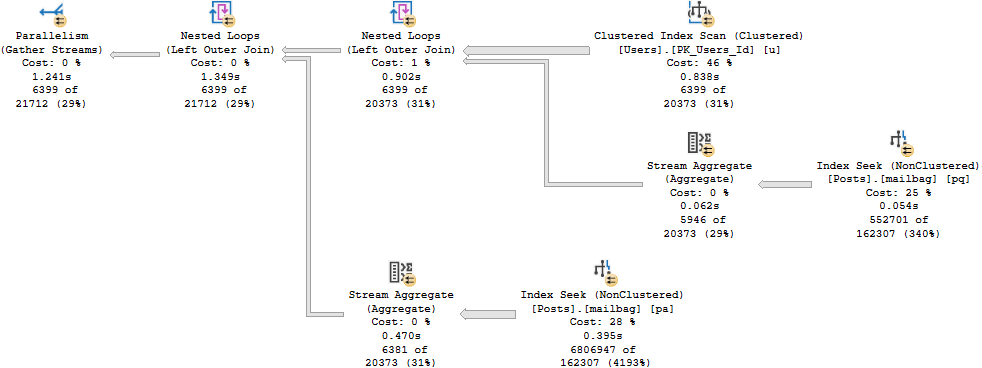
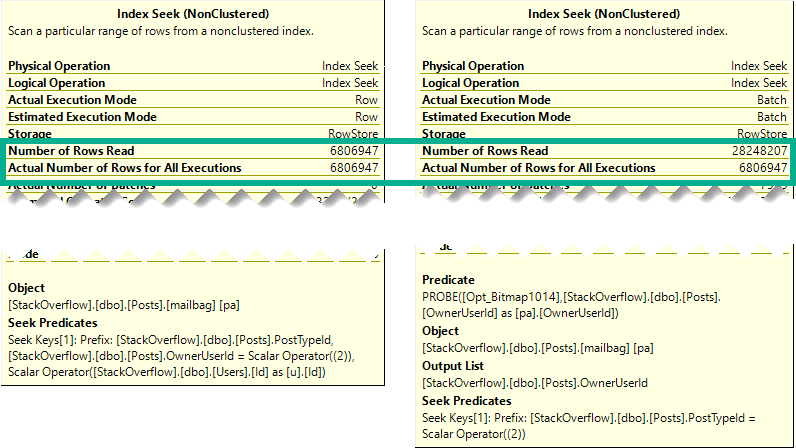
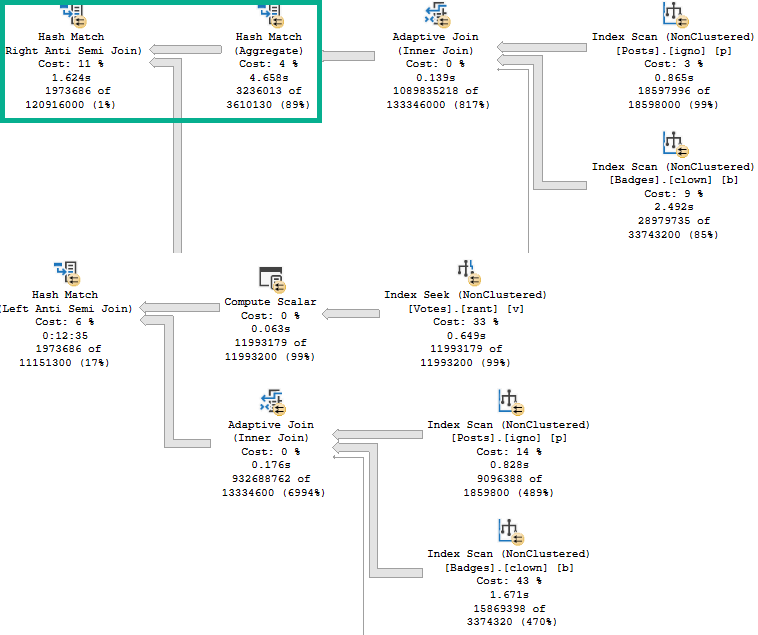
Which get very different execution plans.
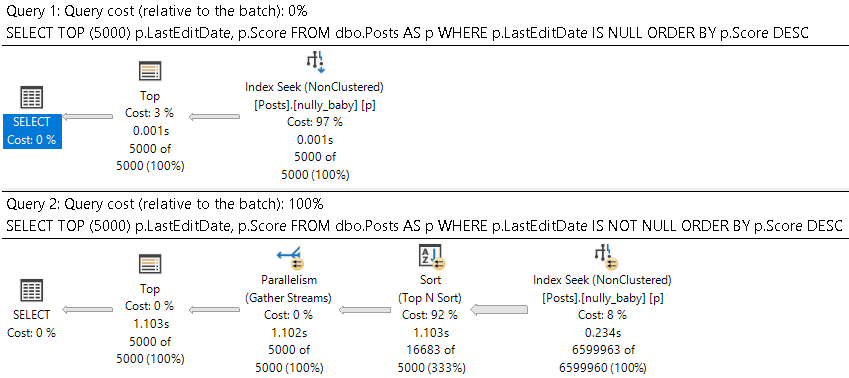
But Why?
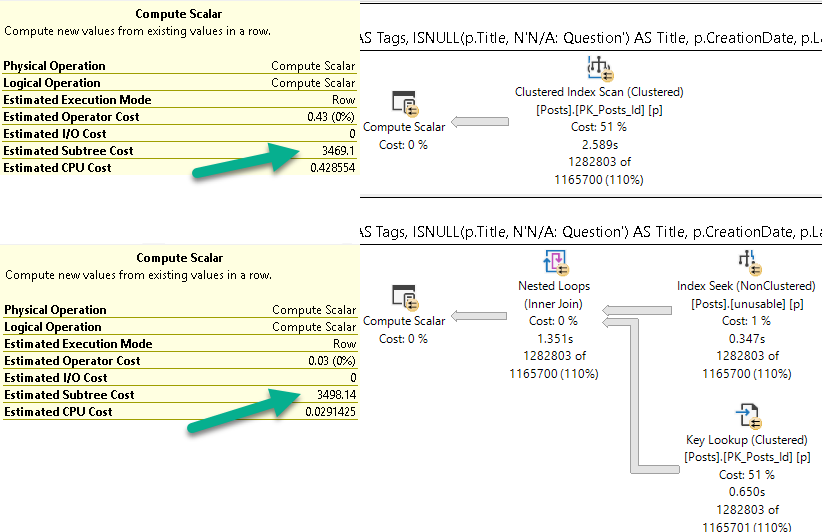
I know, I know. The sort is technically non-deterministic, because Score has duplicates in it. Forget about that for a second.
For the NULL values though, Score is at least persisted in the correct order.
For the NOT NULL values, Score is not guaranteed to be in a consistent order across different date values. The ordering will reset within each group.
We’ll talk about how that works tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.