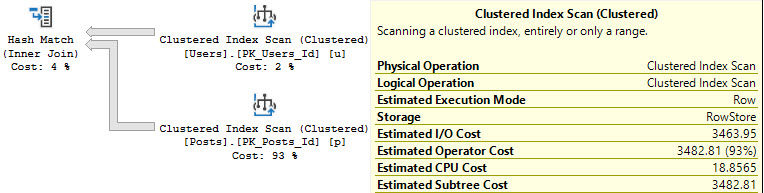
When we write queries that need to filter data, we tend to want to have that filtering happen as far over to the right in a query plan as possible. Ideally, data is filtered when we access the index.
Whether it’s a seek or a scan, or if it has a residual predicate, and if that’s all appropriate isn’t really the question.
In general, those outcomes are preferable to what happens when SQL Server is unable to do any of them for various reasons. The further over to the right in a query plan we can reduce the number of rows we need to contend with, the better.
There are some types of filters that contain something called a “startup expression”, which are usually helpful. This post is not about those.
Ain’t Nothin’ To Do
There are some cases when you have no choice but to rely on a Filter to remove rows, because we need to calculate some expression that we don’t currently store the answer to.
For example, having:
SELECT
p.OwnerUserId,
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
JOIN dbo.Comments AS c
ON c.PostId = p.Id
JOIN dbo.Votes AS v
ON v.PostId = p.Id
GROUP BY p.OwnerUserId
HAVING COUNT_BIG(*) > 2147483647;
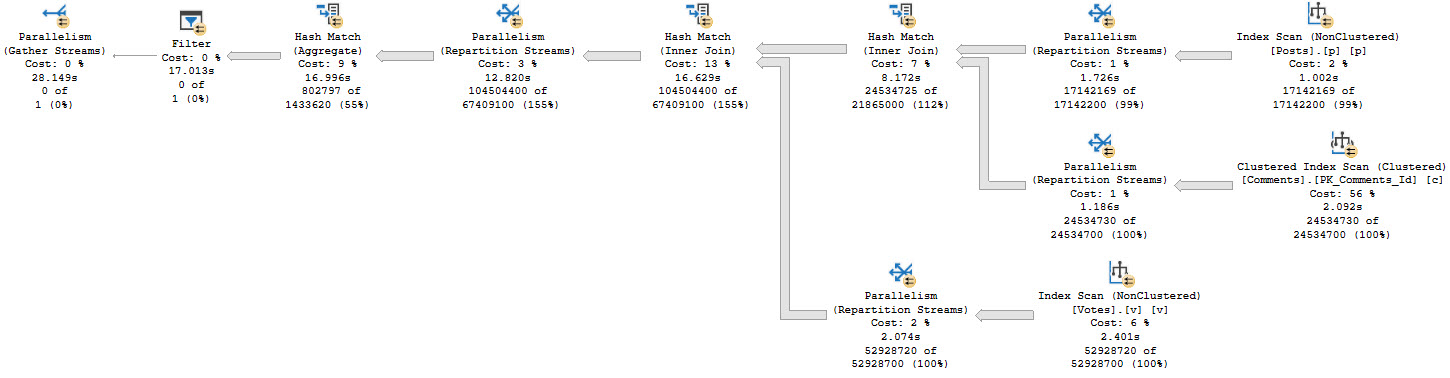
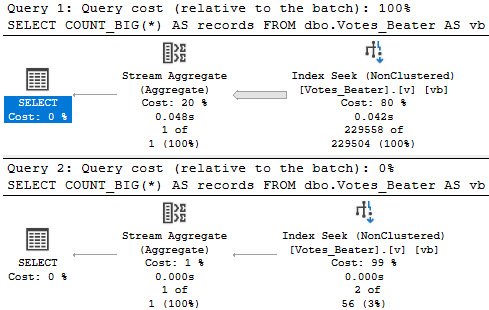
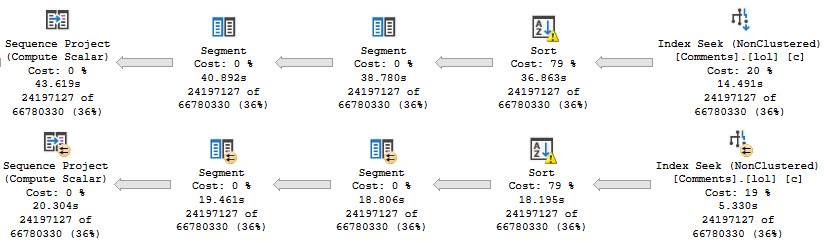
We don’t know which rows might qualify for the count filter up front, so we need to run the entire query before filtering things out:
this cold night
There’s a really big arrow going into that Filter, and then nothing!
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE DATEDIFF(YEAR, p.CreationDate, p.LastActivityDate) > 5;
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
LEFT JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
WHERE p.Id IS NULL;
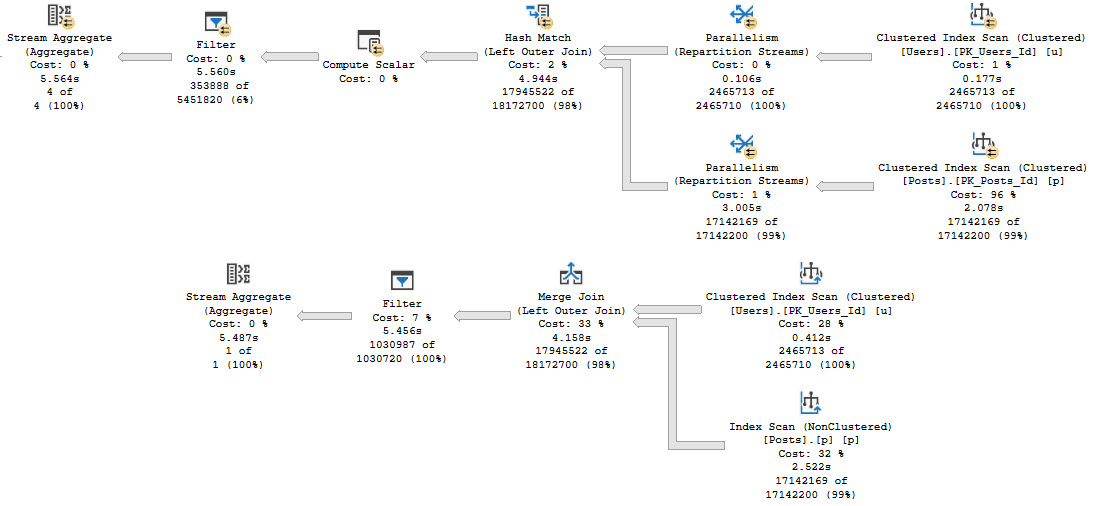
But what you get is disappointing!
not a gif
What we care about here is that, rather than filtering rows out when we touch indexes or join the tables, we have to fully join the tables together, and then eliminate rows afterwards.
This is generally considered “less efficient” than filtering rows earlier. Remember when I said that before? It’s still true.
Click the links above to see some solutions, so you don’t feel left hanging by your left joins.
The Message
If you see Filters in query plans, they might be for a good reason, like calculating things you don’t currently know the answer to.
They might also be for bad reasons, like you writing a query in a silly way.
There are other reasons they might show up too, that we’ll talk about tomorrow.
Why tomorrow? Why not today? Because if I keep writing then I won’t take a shower and run errands for another hour and my wife will be angry.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
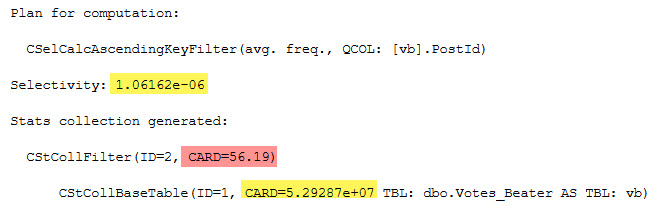
Look, I’m not saying there’s only one thing that the “Default” cardinality estimator does better than the “Legacy” cardinality estimator. All I’m saying is that this is one thing that I think it does better.
What’s that one thing? Ascending keys. In particular, when queries search for values that haven’t quite made it to the histogram yet because a stats update hasn’t occurred since they landed in the mix.
I know what you’re thinking, too! On older versions of SQL Server, I’ve got trace flag 2371, and on 2016+ that became the default behavior.
Sure it did — only if you’re using compat level 130 or better — which a lot of people aren’t because of all the other strings attached.
And that’s before you go and get 2389 and 2390 involved, too. Unless you’re on compatibility level 120 or higher! Then you need 4139.
Changes the fixed update statistics threshold to a linear update statistics threshold. For more information, see this AUTO_UPDATE_STATISTICS Option.
Note: Starting with SQL Server 2016 (13.x) and under the database compatibility level 130 or above, this behavior is controlled by the engine and trace flag 2371 has no effect.
Scope: global only
2389
Enable automatically generated quick statistics for ascending keys (histogram amendment). If trace flag 2389 is set, and a leading statistics column is marked as ascending, then the histogram used to estimate cardinality will be adjusted at query compile time.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment.
Note: This trace flag does not apply to CE version 120 or above. Use trace flag 4139 instead.
Scope: global or session or query (QUERYTRACEON)
2390
Enable automatically generated quick statistics for ascending or unknown keys (histogram amendment). If trace flag 2390 is set, and a leading statistics column is marked as ascending or unknown, then the histogram used to estimate cardinality will be adjusted at query compile time. For more information, see this Microsoft Support article.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment.
Note: This trace flag does not apply to CE version 120 or above. Use trace flag 4139 instead.
Scope: global or session or query (QUERYTRACEON)
4139
Enable automatically generated quick statistics (histogram amendment) regardless of key column status. If trace flag 4139 is set, regardless of the leading statistics column status (ascending, descending, or stationary), the histogram used to estimate cardinality will be adjusted at query compile time. For more information, see this Microsoft Support article.
Starting with SQL Server 2016 (13.x) SP1, to accomplish this at the query level, add the USE HINT ‘ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS’ query hint instead of using this trace flag.
Note: Please ensure that you thoroughly test this option, before rolling it into a production environment.
Note: This trace flag does not apply to CE version 70. Use trace flags 2389 and 2390 instead.
Scope: global or session or query (QUERYTRACEON)
I uh. I guess. ?
Why Not Just Get Cardinality Estimation Right The First Time?
Great question! Hopefully someone knows the answer. In the meantime, let’s look at what I think this new-fangled cardinality estimator does better.
The first thing we need is an index with literally any sort of statistics.
CREATE INDEX v ON dbo.Votes_Beater(PostId);
Next is a query to help us figure out how many rows we can modify before an auto stats update will kick in, specifically for this index, though it’s left as an exercise to the reader to determine which one they’ve got in effect.
There are a lot of possible places this can kick in. Trace Flags, database settings, query hints, and more.
SELECT TOP (1)
OBJECT_NAME(s.object_id) AS table_name,
s.name AS stats_name,
p.modification_counter,
p.rows,
CONVERT(bigint, SQRT(1000 * p.rows)) AS [new_auto_stats_threshold],
((p.rows * 20) / 100) + CASE WHEN p.rows > 499 THEN 500 ELSE 0 END AS [old_auto_stats_threshold]
FROM sys.stats AS s
CROSS APPLY sys.dm_db_stats_properties(s.object_id, s.stats_id) AS p
WHERE s.name = 'v'
ORDER BY p.modification_counter DESC;
Edge cases aside, those calculations should get you Mostly Accurate™ numbers.
We’re going to need those for what we do next.
Mods Mods Mods
This script will allow us to delete and re-insert a bunch of rows back into a table, without messing up identity values.
--Create a temp table to hold rows we're deleting
DROP TABLE IF EXISTS #Votes;
CREATE TABLE #Votes (Id int, PostId int, UserId int, BountyAmount int, VoteTypeId int, CreationDate datetime);
--Get the current high PostId, for sanity checking
SELECT MAX(vb.PostId) AS BeforeDeleteTopPostId FROM dbo.Votes_Beater AS vb;
--Delete only as many rows as we can to not trigger auto-stats
WITH v AS
(
SELECT TOP (229562 - 1) vb.*
FROM dbo.Votes_Beater AS vb
ORDER BY vb.PostId DESC
)
DELETE v
--Output deleted rows into a temp table
OUTPUT Deleted.Id, Deleted.PostId, Deleted.UserId,
Deleted.BountyAmount, Deleted.VoteTypeId, Deleted.CreationDate
INTO #Votes;
--Get the current max PostId, for safe keeping
SELECT MAX(vb.PostId) AS AfterDeleteTopPostId FROM dbo.Votes_Beater AS vb;
--Update stats here, so we don't trigger auto stats when we re-insert
UPDATE STATISTICS dbo.Votes_Beater;
--Put all the deleted rows back into the rable
SET IDENTITY_INSERT dbo.Votes_Beater ON;
INSERT dbo.Votes_Beater WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id, v.PostId, v.UserId, v.BountyAmount, v.VoteTypeId, v.CreationDate
FROM #Votes AS v;
SET IDENTITY_INSERT dbo.Votes_Beater OFF;
--Make sure this matches with the one before the delete
SELECT MAX(vb.PostId) AS AfterInsertTopPostId FROM dbo.Votes_Beater AS vb;
What we’re left with is a statistics object that’ll be just shy of auto-updating:
WE DID IT
Query Time
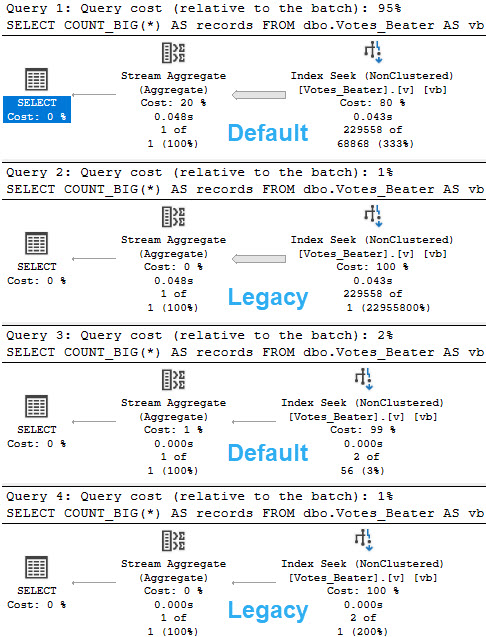
Let’s look at how the optimizer treats queries that touch values! That’ll be fun, eh?
--Inequality, default CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId > 20671101
OPTION(RECOMPILE);
--Inequality, legacy CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId > 20671101
OPTION(RECOMPILE, USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
--Equality, default CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId = 20671101
OPTION(RECOMPILE);
--Equality, legacy CE
SELECT
COUNT_BIG(*) AS records
FROM dbo.Votes_Beater AS vb
WHERE vb.PostId = 20671101
OPTION(RECOMPILE, USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
For the record, > and >= produced the same guesses. Less than wouldn’t make sense here, since it’d hit mostly all values currently in the histogram.
hoodsy
Inside Intel
For the legacy CE, there’s not much of an estimate. You get a stock guess of 1 row, no matter what.
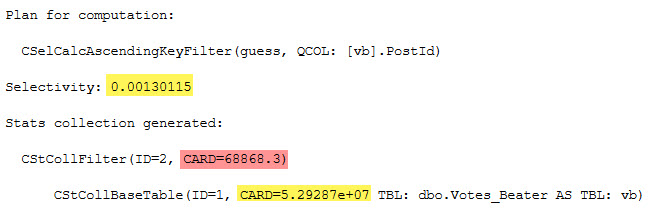
For the default CE, there’s a little more to it.
inequality
SELECT (0.00130115 * 5.29287e+07) AS inequality_computation;
equality
SELECT (1.06162e-06 * 5.29287e+07) AS equality_computation;
And of course, the CARD for both is the number of rows in the table:
SELECT CONVERT(bigint, 5.29287e+07) AS table_rows;
I’m not sure why the scientific notation is preferred, here.
A Little Strange
Adding in the USE HINT mentioned earlier in the post (USE HINT ('ENABLE_HIST_AMENDMENT_FOR_ASC_KEYS')) only seems to help with estimation for the inequality predicate. The guess for the equality predicate remains the same.
well okay
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Class Title: The Beginner’s Guide To Advanced Performance Tuning
Abstract: You’re new to SQL Server, and your job more and more is to fix performance problems, but you don’t know where to start.
You’ve been looking at queries, and query plans, and puzzling over indexes for a year or two, but it’s still not making a lot of sense.
Beyond that, you’re not even sure how to measure if your changes are working or even the right thing to do.
In this full day performance tuning extravaganza, you’ll learn about all the most common anti-patterns in T-SQL querying and indexing, and how to spot them using execution plans. You’ll also leave knowing why they cause the problems that they do, and how you can solve them quickly and painlessly.
If you want to gain the knowledge and confidence to tune queries so they’ll never be slow again, this is the training you need.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Let’s say at some point, you just didn’t know any better, and you wrote a scalar function to make some common thing you needed to do all “modular” and “portable” and stuff.
Good on you, not repeating yourself. Apparently I repeat myself for a living.
Anyway, you know what stinks? When you hit divide by zero errors. It’d be cool if math fixed that for us.
Does anyone know how I can get in touch with math?
Uncle Function
Since you’re a top programmer, you know about this sort of stuff. So you write a bang-up function to solve the problem.
Maybe it looks something like this.
CREATE OR ALTER FUNCTION dbo.safety_dance(@n1 INT, @n2 INT)
RETURNS INT
WITH SCHEMABINDING,
RETURNS NULL ON NULL INPUT
AS
BEGIN
RETURN
(
SELECT @n1 / NULLIF(@n2, 0)
);
END
GO
You may even be able to call it in queries about like this.
SELECT TOP (5)
u.DisplayName,
fudge = dbo.safety_dance(SUM(u.UpVotes), COUNT(*))
FROM dbo.Users AS u
GROUP BY u.DisplayName
ORDER BY fudge DESC;
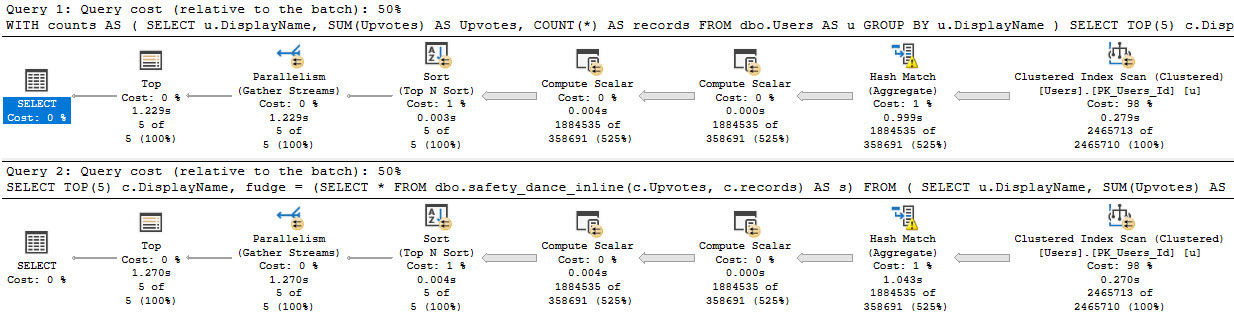
The problem is that it makes this query take a long time.
you compute that scalar, sql server
At 23 seconds, this is probably unacceptable. And this is on SQL Server 2019, too. The function inlining thing doesn’t quite help us, here.
One feature restriction is this, so we uh… Yeah.
The UDF does not contain aggregate functions being passed as parameters to a scalar UDF
But we’re probably good query tuners, and we know we can write inline functions.
Ankle Fraction
This is a simple enough function. Let’s get to it.
CREATE OR ALTER FUNCTION dbo.safety_dance_inline(@n1 INT, @n2 INT)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT @n1 / NULLIF(@n2, 0) AS safety
);
Will it be faster?
SELECT TOP (5)
u.DisplayName,
fudge = (SELECT * FROM dbo.safety_dance_inline(SUM(u.UpVotes), COUNT(*)))
FROM dbo.Users AS u
GROUP BY u.DisplayName
ORDER BY fudge DESC;
Well, yes. Mostly because it throws an error.
Msg 4101, Level 15, State 1, Line 35
Aggregates on the right side of an APPLY cannot reference columns from the left side.
Well that’s weird. Who even knows what that means? There’s no apply, here.
What’s your problem, SQL Server?
Fixing It
To get around this restriction, we need to also rewrite the query. We can either use a CTE, or a derived table.
--A CTE
WITH counts AS
(
SELECT
u.DisplayName,
SUM(Upvotes) AS Upvotes,
COUNT(*) AS records
FROM dbo.Users AS u
GROUP BY u.DisplayName
)
SELECT TOP(5)
c.DisplayName,
fudge = (SELECT * FROM dbo.safety_dance_inline(c.Upvotes, c.records) AS s)
FROM counts AS c
ORDER BY fudge DESC;
--A derived table
SELECT TOP(5)
c.DisplayName,
fudge = (SELECT * FROM dbo.safety_dance_inline(c.Upvotes, c.records) AS s)
FROM
(
SELECT
u.DisplayName,
SUM(Upvotes) AS Upvotes,
COUNT(*) AS records
FROM dbo.Users AS u
GROUP BY u.DisplayName
) AS c
ORDER BY fudge DESC;
Is it faster? Heck yeah it is.
you’re just so parallel, baby
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
None of your stored procedures are a single statement. They’re long. Miles long. Ages long.
If you’re troubleshooting performance for one of those, you could end up really causing yourself some headaches if you turn on actual execution plans and fire away.
Not only is there some overhead to collecting all the information for those plans, but then SSMS has to get all artsy and draw them from the XML.
Good news, though. If you’ve got some idea about which statement(s) are causing you problems, you can use an often-overlooked SET command.
Blitzing
One place I use this technique a lot is with the Blitz procs.
For example, if I run sp_BlitzLock without plans turned on, it’s done in about 7 seconds.
If I run it with plans turned on, it runs for a minute and 7 seconds.
Now, a while back I had added a bit of feedback in there to help me understand which statements might be running the longest. You can check out the code I used over in the repo, but it produces some output like this:
Why is it always the XML?
If I’m not patient enough to, let’s say, wait a minute for this to run every time, I can just do something like this:
SET STATISTICS XML ON;
/*Problem queries here*/
SET STATISTICS XML OFF;
That’ll return just the query plans you’re interested in.
Using a screenshot for a slightly different example that I happened to have handy:
click me, click me, yeah
You’ll get back the normal results, plus a clickable line that’ll open up the actual execution plan for a query right before your very eyes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When you run a query, the optimizer has a lot to think about. One of those things is if the plan will benefit from parallelism.
That generally happens as long as:
The plan isn’t trivial — it has to receive full optimization
Nothing is artificially inhibiting parallelism (like scalar functions or table variable modifications)
If the serial plan cost is greater than the Cost Threshold For Parallelism (CTFP)
As long as all those qualifications are met, the optimizer will come up with competing parallel plans. If it locates a parallel plan that’s cheaper than the serial plan, it’ll get chosen.
This is determined at a high level by adding up the CPU and I/O costs of each operator in the serial plan, and doing the same for the parallel plan with the added costs of one or more parallel exchanges added in.
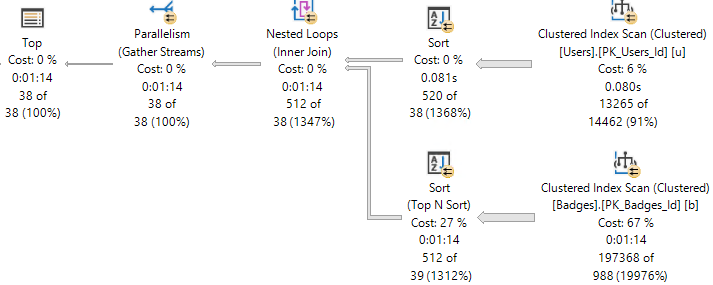
Yesterday we saw a case where the Gather Streams operator was costed quite highly, and it prevented a parallel plan from being chosen, despite the parallel plan in this case being much faster.
It’s important to note that costing for plans is not a direct reflection of actual time or effort, nor is it accurate to your local configuration.
They’re estimates used to come up with a plan. When you get an actual plan, there are no added-in “Actual Cost” metrics.
How Nested Loops Is Different
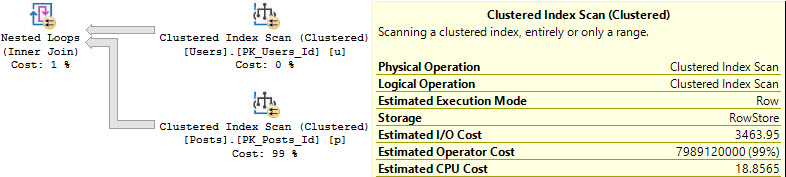
In merge or hash join plans, both sides of the join are part of the costing algorithm to decide if parallelism should be engaged.
An example with a hash join:
parallel: 4.7 CPU query bucks
seriallel: 18.8 CPU query bucks
The estimated CPU cost of scanning the Posts table is reduced by 14 or so query bucks. The I/O cost doesn’t change at all.
In this case, it results in a parallel plan being naturally chosen, because the overall plan cost for the parallel plan is cheaper.
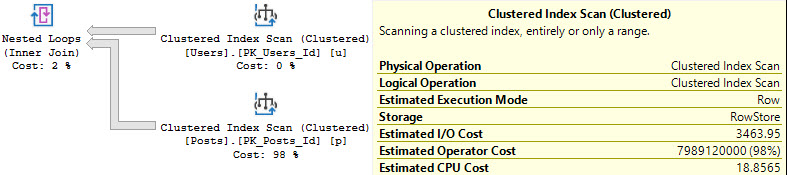
For Nested Loops, it’s different:
parallel: 18.8 CPU query bucks
seriallel: 18.8 CPU query bucks
Slashing Prices
In Nested Loops plans, only the stuff on the outer side of the join experiences a cost reduction by engaging parallelism.
That means that if you’ve got a plan shaped like this that you need to go parallel, you need to figure out how to make the outside as expensive on CPU as possible.
In a lot of cases, you can use ORDER BY to achieve this because it can introduce a Sort operator into the query plan.
Of course, where that Sort operator ends up can change things.
For example, if I ask to order results by Reputation here:
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text --Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0
ORDER BY u.Reputation DESC;
The Sort ends up before the join, and only applies to relatively few rows, and the plan stays serial.
boing
But if I ask for something from inside of the cross apply to be ordered, the number of rows the optimizer expects to have to sort increases dramatically, and so does the cost.
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text --Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0
ORDER BY ca.CreationDate DESC;
beachfront
The additional cost on the outer side tilts the optimizer towards a parallel plan.
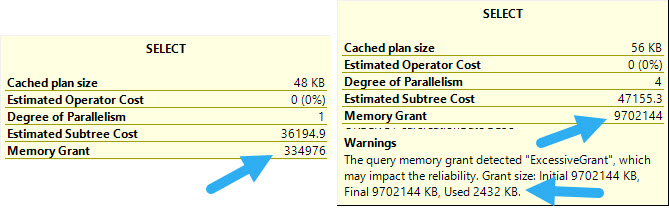
There’s No Such Thing As A Free Cool Trick™
This, of course, comes at a cost. While you do gain efficiency in the query finishing much faster, the Sort operator asks for a nightmare of memory.
O HEK
If you have ~10GB of memory to spare for a memory grant, cool. This might be great.
Of course, there are other ways to control memory grants via hints and resource governor, etc.
In some cases, adding an index helps, but if we do that then we’ll lose the added cost and the parallel plan.
Like most things in life, it’s about tradeoffs.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
And of course, sometimes they can cause plans to be costed strangely.
Strong Tradition
Working with the queries we’ve been tinkering with in all the posts this week, let’s look at a slightly different oddity.
/*Q1*/
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text --Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0;
/*Q2*/
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate
-- No Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0;
The first query has the Text column in the outer select list, and the second query doesn’t. Please read the comments for additional clarity.
Big Plans
The plan without Text in the outer project goes parallel, and the one with it does not.
pain pain
But why?
Forcing The Issue
Let’s add a third query into the mix to force the query to go parallel.
/*Q3*/
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text --Text in the select list
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0
OPTION(USE HINT('ENABLE_PARALLEL_PLAN_PREFERENCE'));
Things are pretty interesting, here.
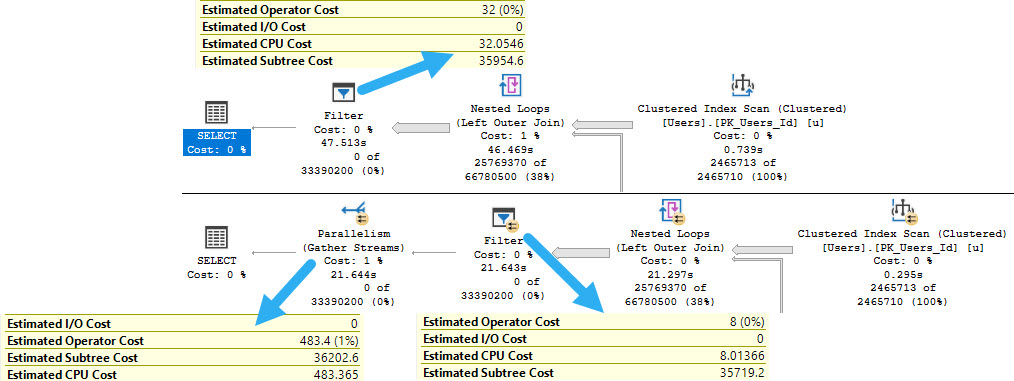
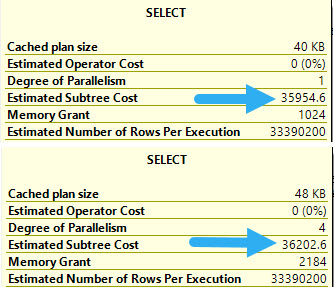
caloric surplus
The parallel plan is actually costed cheaper up through the Filter operator. In the serial plan, the entire subtree costs 35,954. In the parallel plan, it’s at 35,719.
At 200 query bucks cheaper, we’re in good shape! And then… We Gather Streams ☹
creaky french
Mortem
The Gather Streams pushes the final plan cost for the parallel plan up higher than the serial plan.
Even though the parallel plan finishes ~26 seconds faster, the optimizer doesn’t choose it naturally because it is a cheapskate.
Bummer, huh?
An important point to keep in mind is that in nested loops join plans, the inner side of the query doesn’t receive any cost adjustments for parallel vs. serial versions. All of the costing differences will exist on the outside.
That’s why only the last few operators in the plan here are what makes a difference.
And that’s what we’ll finish out the week with!
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Now that we’ve covered what happened with our query, how can we fix it?
Remember when I said that this only happens with literals? I sort of lied.
Sorry.
Pants On Fire
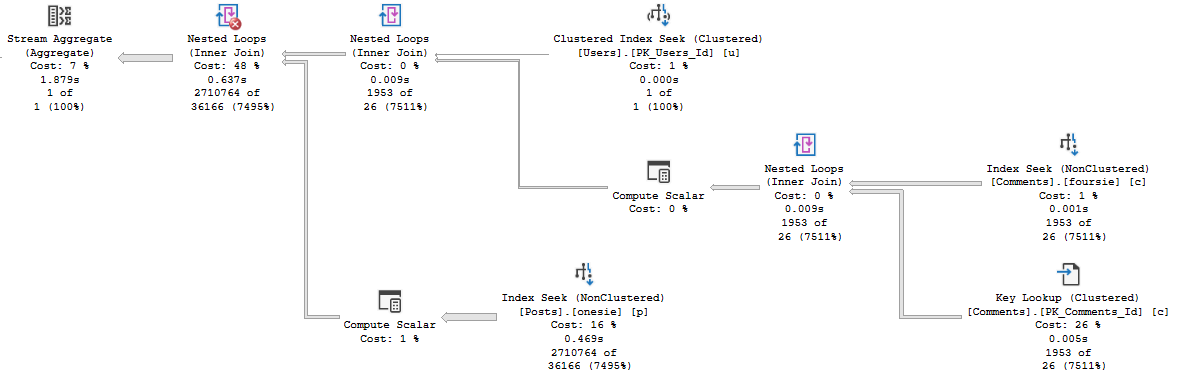
Probably the simplest thing to do would be to set MAXDOP to 1 for the query. Avoiding the parallel exchanges avoids the problem, but the query does run longer than the original with a literal TOP. That being said, it may be the simplest solution in some cases for you if it stabilizes performance.
If you’re feeling as brave as Sir Robin, you can add an OPTIMIZE FOR hint to bring back the early-buffer-send behavior.
CREATE OR ALTER PROCEDURE dbo.SniffedTop (@Top INT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users u
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation >= 10000
ORDER BY u.Reputation DESC
OPTION(OPTIMIZE FOR(@Top = 1));
END;
GO
Are they always better? I have no idea, but if you’ve got long-running queries with a parameterized TOP, this might be something worth experimenting with.
Another rewrite that works is slightly more complicated. Though for maximum benefit, Batch Mode is necessary.
CREATE OR ALTER PROCEDURE dbo.SniffedTop (@Top INT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users u
CROSS APPLY
(
SELECT *
FROM
(
SELECT *,
ROW_NUMBER()
OVER( PARTITION BY b.UserId
ORDER BY b.Date DESC ) AS n
FROM dbo.Badges AS b
) AS b
WHERE b.UserId = u.Id
AND b.n = 1
) AS b
WHERE u.Reputation >= 10000
ORDER BY u.Reputation DESC;
END;
GO
So that’s fun. We’re having fun. I like fun.
I’m gonna make a PowerPoint about fun.
Other Things, And Drawbacks
So like, you could add a recompile hint to allow the TOP parameter to be sniffed, sure. But then you’re sort of undoing the good you did parameterizing in the first place.
You could also write unparameterized dynamic SQL, but see above. Same problem, plus a blown out plan cache if people ask for different values.
Optimize for unknown, and OFFSET/FETCH also don’t work.
Of course, one thing that would help here is a more appropriate index leading with UserId. However, most good demos arise from less than ideal indexing, so you’re just going to have to deal with it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I love when a demo written for one purpose turns into an even better demo for another purpose.
While working with a client recently, they ran into a performance issue when trying to promote plan reuse by parameterizing the user-input number for TOP.
In part 1, I’m going to show you what happened and why, and in part 2 I’ll discuss some workarounds.
Regresso Chicken Face Soup
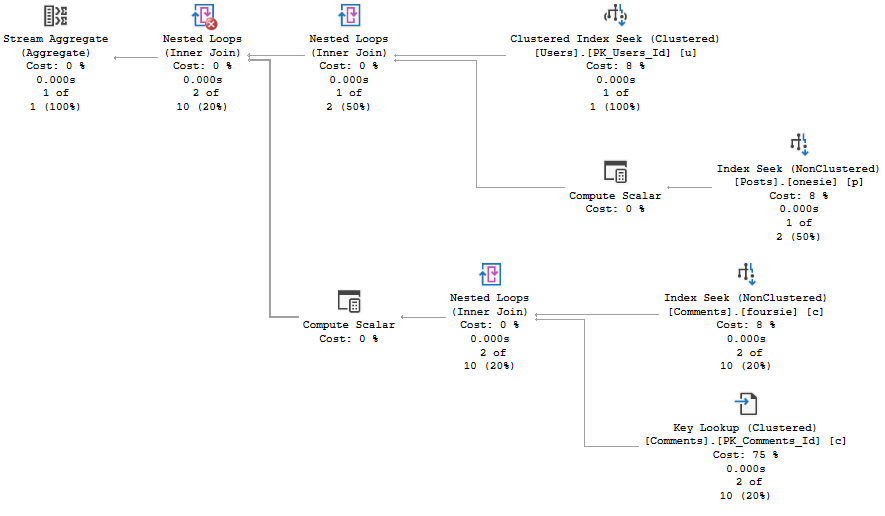
When executed with a literal value in the top, this query runs for around 10 seconds.
I’m not saying that’s great, but it’s a good enough starting place.
SELECT TOP (38)
u.DisplayName,
b.Name
FROM dbo.Users u
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation >= 10000
ORDER BY u.Reputation DESC;
glamping
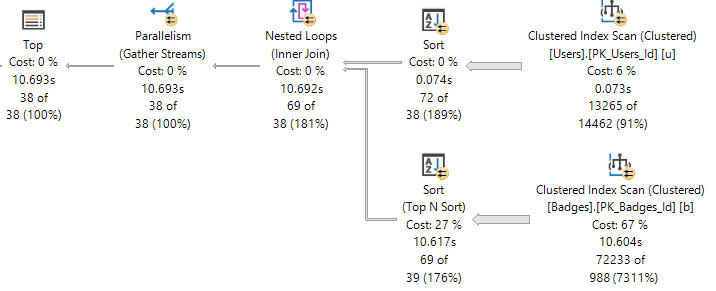
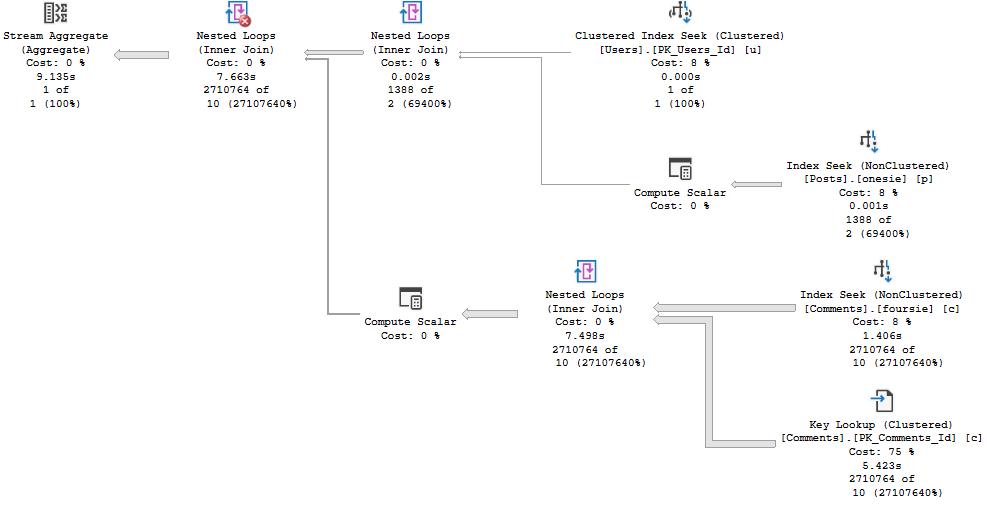
If we take that same query, put it in a proc, and run it with an identical value in the TOP, things will turn out not-so-well.
CREATE OR ALTER PROCEDURE dbo.SniffedTop (@Top INT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (@Top)
u.DisplayName,
b.Name
FROM dbo.Users u
CROSS APPLY
(
SELECT TOP (1)
b.Name
FROM dbo.Badges AS b
WHERE b.UserId = u.Id
ORDER BY b.Date DESC
) AS b
WHERE u.Reputation >= 10000
ORDER BY u.Reputation DESC;
END
GO
EXEC dbo.SniffedTop @Top = 38;
The query runs for a significantly longer amount of time.
half-day
What Happened?
Unofficially, when TOP uses a constant and the constant is “small” (under 101), the exchange packets are allowed to send earlier than normal, as long as the exchange is below the TOP operator. They’re allowed to send as soon as they have a row, rather than waiting for them to fill up completely.
This can only happen with constants (or…!), and the behavior is true going back to 2005. It may change in the future, so if you’re reading this at some far off date, please don’t be too harsh on me in the comments.
When you parameterize TOP, it’s considered unsafe to send the exchange buffers early. After all, you could stick anything in there, up through the BIGINT max. In cases where you’ve got a BIG TOP, sending, say, 9,223,372,036,854,775,807 rows one at a time would be significantly ickier than sending over a smaller number of full exchange buffers.
If you’re surprised to hear that parallel exchange buffers can send at different times, you’re not alone. I was also surprised.
SQL Server: Full Of Surprises. Horrible surprises.
In the second query, where exchange buffers are sent when full, we spend a lot longer waiting for them to fill up. This isn’t exposed anywhere in the plan, and you’d need either a debugger or this blog post to figure it out.
Yep.
Yep. Yep. Yep. Yep. Yep. Yep.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Okay look, you probably should update stats. At least when you do it, you have some control over the situation.
If you let SQL Server get up to its own devices, you might become quite surprised.
One after-effect of updated stats is, potentially, query plan invalidation. When that happens, SQL Server might get hard to work coming up with a new plan that makes sense based on these new statistics.
And that, dear friends, is where things can go bad.
New Contributor ?
Let’s say we have this query, which returns the average post and comment score for a single user.
CREATE OR ALTER PROCEDURE dbo.AveragePostScore(@UserId INT)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT u.DisplayName,
AVG(p.Score * 1.) AS lmao_p,
AVG(c.Score * 1.) AS lmao_c
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.UserId = u.Id
WHERE u.Id = @UserId
GROUP BY u.DisplayName;
END;
GO
Most of the time, the query runs fast enough for the occasional run to not end too poorly.
But then a recompile happens, and a new contributor decides to look at their profile.
Okay To Worse
What comes next you could fill a textbook with.
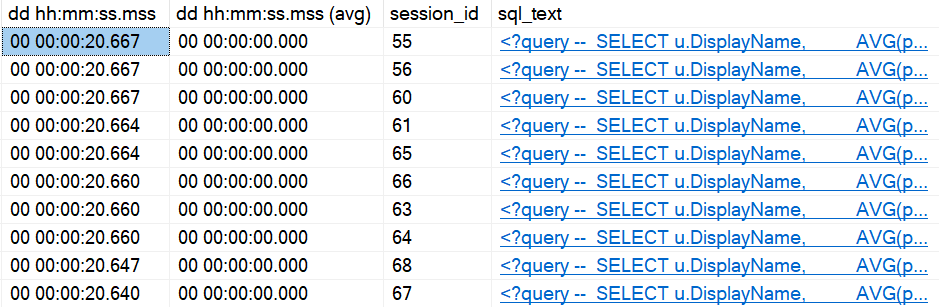
EXEC dbo.AveragePostScore @UserId = 3150367;
A new plan gets compiled:
wouldn’t get far
And you know, it looks great for a new user.
And you know, it looks not so great for a slightly more seasoned user.
you shouldn’t have!
So What Changed?
Running the query first for a user with a bit more site history gives us a plan with a very different shape, that finishes in under 2 seconds. Repeating that plan for less experienced users doesn’t cause any problems. It finishes in very little time at all.
JERN ERDR
The plan itself remains largely more familiar than most parameter sniffing scenarios wind up. There are plenty more similarities than differences. It really does just come down to join order here.
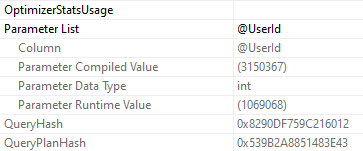
Alright, now we know what happened. How would we figure out if this happened to us IRL?
I Shot The Trouble
We can do what we did yesterday, and run sp_BlitzFirst. That’ll warn us if stats recently got updated.
To use DBCC FREEPROCCACHE to target a specific query, you need the sql handle or plan handle. You don’t wanna jump off and clear the whole cache here, unless you’re desperate. Just make sure you understand that you might fix one query, and break others, if you clear the whole thing.
It’s better to be targeted when possible.
And of course, if you’ve got Query Store up and running, you may do well to look at Regressed or High Variance query views there, and force the faster plan.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.