One Day
I will be able to not care about this sort of thing. But for now, here we are, having to write multiple blogs in a day to cover a potpourri of grievances.
Let’s get right to it!
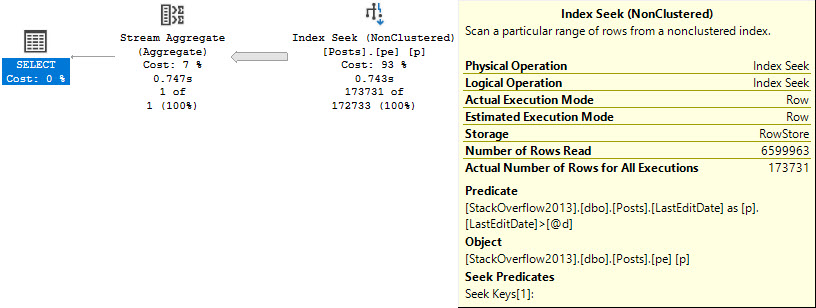
First, without a where clause, the optimizer doesn’t think that an index could improve one single, solitary metric about this query. We humans know better, though.
WITH Votes AS
(
SELECT
v.Id,
ROW_NUMBER()
OVER(PARTITION BY
v.PostId
ORDER BY
v.CreationDate) AS n
FROM dbo.Votes AS v
)
SELECT *
FROM Votes AS v
WHERE v.n = 0;
The tough part of this plan will be putting data in order to suit the Partition By, and then the Order By, in the windowing function.
Without any other clauses against columns in the Votes table, there are no additional considerations.
Two Day
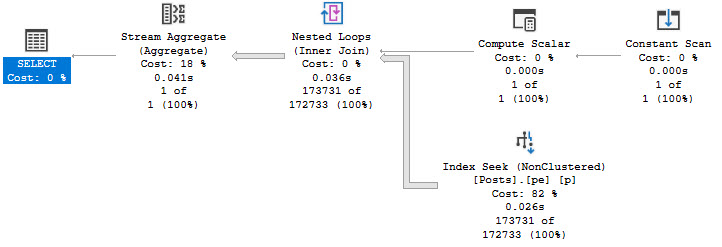
What often happens is that someone wants to add an index to help the windowing function along, so they follow some basic guidelines they found on the internet.
What they end up with is an index on the Partition By, Order By, and then Covering any additional columns. In this case there’s no additional Covering Considerations, so we can just do this:
CREATE INDEX v2 ON dbo.Votes(PostId, CreationDate);
If you’ve been following my blog, you’ll know that indexes put data in order, and that with this index you can avoid needing to physically sort data.
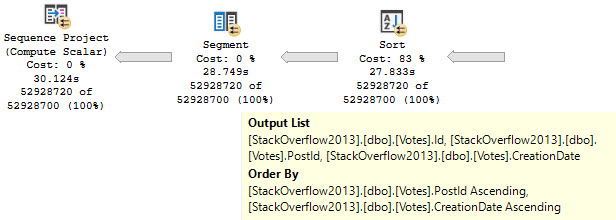
Three Day
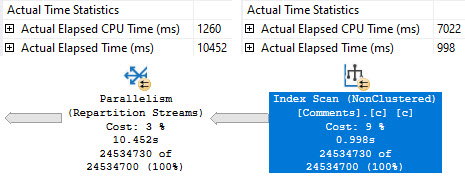
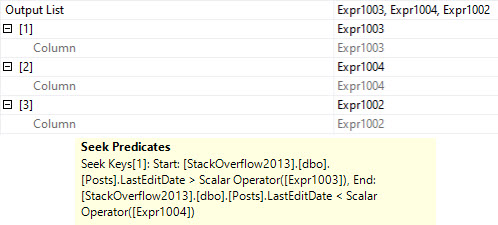
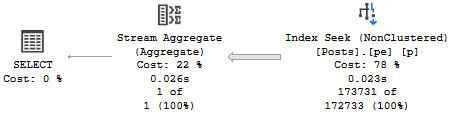
The trouble here is that, even though we have Cost Threshold For Parallelism (CTFP) set to 50, and the plan costs around 195 Query Bucks, it doesn’t go parallel.
Creating the index shaves about 10 seconds off the ordeal, but now we’re stuck with this serial calamity, and… forcing it parallel doesn’t help.
Our old nemesis, repartition streams, is back.
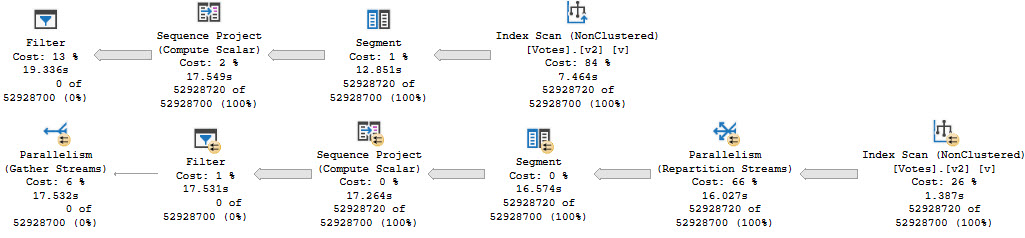
Even at DOP 8, we only end up about 2 seconds faster. That’s not a great use of parallelism, and the whole problem sits in the repartition streams.
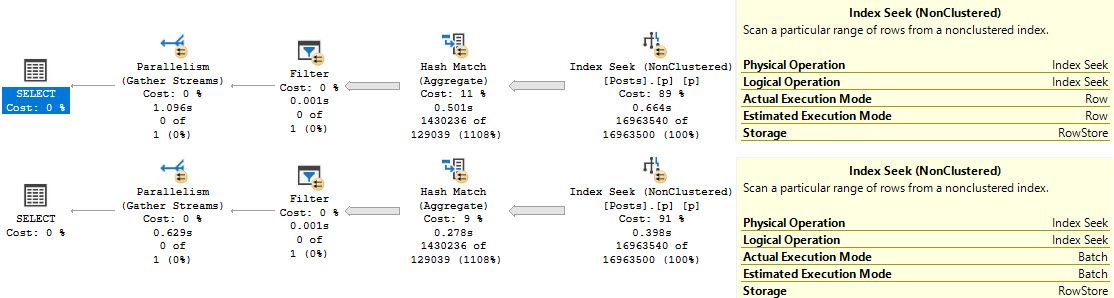
This is, just like we talked about yesterday, a row mode problem. And just like we talked about the day before that, windowing functions generally do benefit from batch mode.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.