Rarities
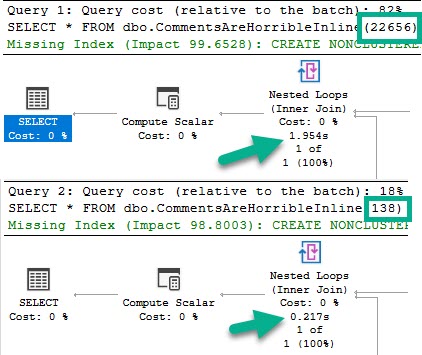
I ran into a very funny situation while working with a client recently. They were using Entity Framework, and a query with around 10 left joins ended up with a compile time of nearly 70 seconds.
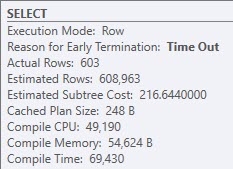
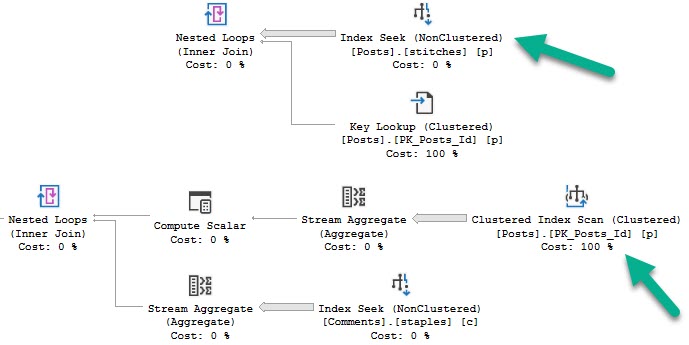
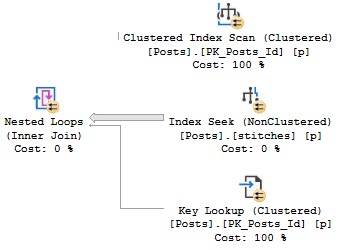
Once the query finished compiling, it ran instantly with a pretty simple plan with all nested loops joins.
So what happened?
Tracing Flags
For science, I broke out a Rocket Science Trace Flag™ that will show optimization phases and how long were spent in them.
What came back looked like this:
end exploration, tasks: 3098 Cost = 242.433 time: 0 net: 0 total: 0.049 net: 0.047 end exploration, tasks: 3099 Cost = 242.433 time: 0 net: 0 total: 0.049 net: 0.047 end exploration, tasks: 3104 Cost = 242.433 time: 0 net: 0 total: 0.049 net: 0.048 end exploration, tasks: 3331 Cost = 242.433 time: 0.002 net: 0.002 total: 0.052 net: 0.05 end exploration, tasks: 3332 Cost = 242.433 time: 0 net: 0 total: 0.052 net: 0.05 end search(1), cost: 210.273 tasks: 3332 time: 0 net: 0 total: 0.052 net: 0.05 *** Optimizer time out abort at task 211100 *** end search(2), cost: 210.273 tasks: 211100 time: 69.214 net: 69.678 total: 69.267 net: 69.729 *** Optimizer time out abort at task 211100 *** End of post optimization rewrite, time: 0.001 net: 0.001 total: 69.268 net: 69.73 End of query plan compilation, time: 0.002 net: 0.002 total: 69.271 net: 69.732
The numbers aren’t quite the same, since the plan is from a different run than when I captured the trace flag (8675) output.
But you can see pretty clearly, in Search 2, we hung out for a while trying different rewrites.
What happens during Search 2? The whole enchilada.
In this case? Probably mostly join reordering.
Tracking Lags
If you don’t have query store enabled, it’s possible to search the plan cache, or get a warning from BlitzCache for long compile times.
If you do have Query Store enabled, compile time is logged in a couple places:
SELECT TOP (10)
qsq.query_id,
qsq.query_text_id,
qsq.initial_compile_start_time,
qsq.last_compile_start_time,
qsq.last_execution_time,
qsq.count_compiles,
qsq.last_compile_duration / 1000000. last_compile_duration,
qsq.avg_compile_duration / 1000000. avg_compile_duration,
qsq.avg_bind_duration / 1000000. avg_bind_duration,
qsq.avg_bind_cpu_time / 1000000. avg_bind_cpu_time,
qsq.avg_optimize_duration / 1000000. avg_optimize_duration,
qsq.avg_optimize_cpu_time / 1000000. avg_optimize_cpu_time,
qsq.avg_compile_memory_kb / 1024. avg_compile_memory_mb,
qsq.max_compile_memory_kb / 1024. max_compile_memory_mb
--INTO #query_store_query
FROM sys.query_store_query AS qsq
WHERE qsq.is_internal_query = 0
AND qsq.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY avg_compile_duration DESC
SELECT TOP (10)
qsp.plan_id,
qsp.query_id,
qsp.engine_version,
qsp.count_compiles,
qsp.initial_compile_start_time,
qsp.last_compile_start_time,
qsp.last_execution_time,
qsp.avg_compile_duration / 1000000. avg_compile_duration,
qsp.last_compile_duration / 1000000. last_compile_duration,
CONVERT(XML, qsp.query_plan) query_plan
--INTO #query_store_plan
FROM sys.query_store_plan AS qsp
WHERE qsp.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY qsp.avg_compile_duration DESC
I’ve seen different numbers show up in these, so I like to look at both. I don’t know why that happens. There’s probably a reasonable explanation.
If you wanted to add in some other metrics, you could do this:
DROP TABLE IF EXISTS #query_store_query;
DROP TABLE IF EXISTS #query_store_plan;
SELECT TOP (10)
qsq.query_id,
qsq.query_text_id,
qsq.initial_compile_start_time,
qsq.last_compile_start_time,
qsq.last_execution_time,
qsq.count_compiles,
qsq.last_compile_duration / 1000000. last_compile_duration,
qsq.avg_compile_duration / 1000000. avg_compile_duration,
qsq.avg_bind_duration / 1000000. avg_bind_duration,
qsq.avg_bind_cpu_time / 1000000. avg_bind_cpu_time,
qsq.avg_optimize_duration / 1000000. avg_optimize_duration,
qsq.avg_optimize_cpu_time / 1000000. avg_optimize_cpu_time,
qsq.avg_compile_memory_kb / 1024. avg_compile_memory_mb,
qsq.max_compile_memory_kb / 1024. max_compile_memory_mb
INTO #query_store_query
FROM sys.query_store_query AS qsq
WHERE qsq.is_internal_query = 0
AND qsq.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY avg_compile_duration DESC;
SELECT TOP (10)
qsp.plan_id,
qsp.query_id,
qsp.engine_version,
qsp.count_compiles,
qsp.initial_compile_start_time,
qsp.last_compile_start_time,
qsp.last_execution_time,
qsp.avg_compile_duration / 1000000. avg_compile_duration,
qsp.last_compile_duration / 1000000. last_compile_duration,
CONVERT(XML, qsp.query_plan) query_plan
INTO #query_store_plan
FROM sys.query_store_plan AS qsp
WHERE qsp.avg_compile_duration >= 1000000. --This is one second in microseconds
ORDER BY qsp.avg_compile_duration DESC;
SELECT (avg_cpu_time - qsq.avg_compile_duration) AS cpu_time_minus_qsq_compile_time,
(avg_cpu_time - qsp.avg_compile_duration) AS cpu_time_minus_qsp_compile_time,
qsrs.avg_cpu_time,
qsrs.avg_duration,
qsq.avg_compile_duration,
qsq.avg_bind_duration,
qsq.avg_bind_cpu_time,
qsq.avg_optimize_duration,
qsq.avg_optimize_cpu_time,
qsq.avg_compile_memory_mb,
qsp.avg_compile_duration,
qsq.count_compiles,
qsrs.count_executions,
qsp.engine_version,
qsp.query_id,
qsp.plan_id,
CONVERT(XML, qsp.query_plan) query_plan,
qsqt.query_sql_text,
qsrs.first_execution_time,
qsrs.last_execution_time,
qsq.initial_compile_start_time,
qsq.last_compile_start_time,
qsq.last_execution_time
FROM #query_store_query AS qsq
JOIN #query_store_plan AS qsp
ON qsq.query_id = qsp.query_id
JOIN sys.query_store_query_text AS qsqt
ON qsqt.query_text_id = qsq.query_text_id
JOIN
(
SELECT qsrs.plan_id,
qsrs.first_execution_time,
qsrs.last_execution_time,
qsrs.count_executions,
qsrs.avg_duration / 1000000. avg_duration,
qsrs.avg_cpu_time / 1000000. avg_cpu_time
FROM sys.query_store_runtime_stats AS qsrs
) AS qsrs
ON qsrs.plan_id = qsp.plan_id
ORDER BY qsq.avg_compile_duration DESC;
--ORDER BY qsp.avg_compile_duration DESC;
Fixes?
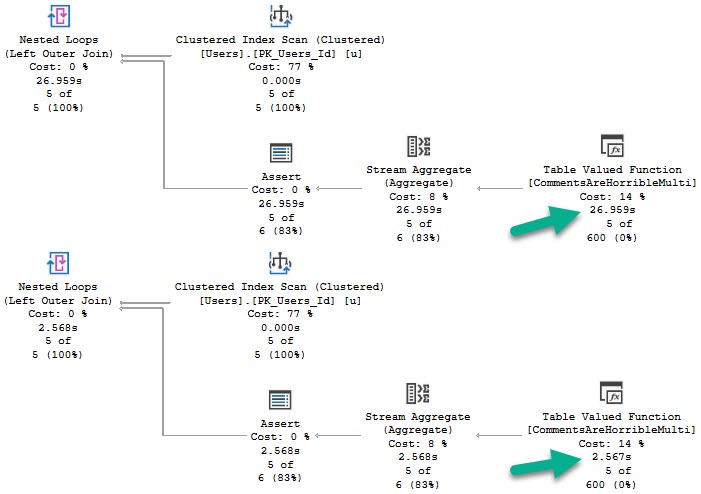
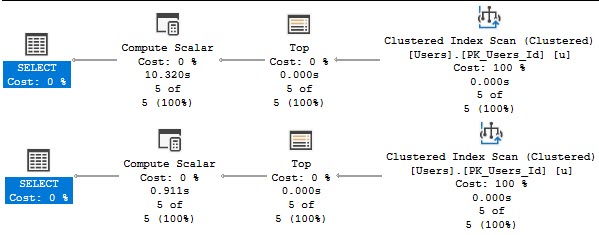
For EF, the only solution was to use a plan guide with a FORCE ORDER hint supplied. This let us arm wrestle the optimizer into just joining the tables in the order that the joins are written in the query. For some reason, forcing the plan with query store did not force the plan that forced the order.
I didn’t dig much into why. I do not get along with query store most of the time.
If you’re finding this happen with queries you have control over, doing your own rewrites to simplify the query and reduce the number of joins that the optimizer has to consider can help.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.