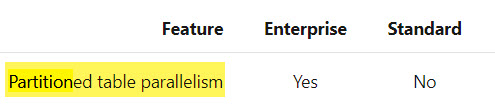
“No, not unless you’re using clustered column store.”
“…”
Burial
Buried deep in that conversation are the two reasons you might want to partition a table:
Data management features
Clustered columnstore indexes
Included in “data management” is the ability to put different partitions in different files/file groups, which you can make read only, and/or allow you do do piecemeal backups and restores.
Outside of those, you’re only introducing a whole mess of complexity to a whole bunch of different places, not to mention some pretty severe pains rebuilding or shadow-copying and switching your current “huge table” as a partitioned on.
Complexity
If you partition a table and plan on using it for data management, all of your other indexes need to be aligned to the partitioning scheme as well.
That adds complexity to index tuning, because if you mess up and don’t do that, your partition swapping will error out. A lot of people add DDL triggers to reject index definitions without the partition alignment.
Add to that, query plans and query writing both get more complicated, too. Not only that, but the query optimizer has to work harder to figure out if partitions can be eliminated or not.
Problems that might have been less problematic against non-partitioned tables and indexes (like some implicit conversions), can be a death spiral against partitioned tables.
There have been a lot of bugs and performance regressions over the years with partitioning, too. Some have been fixed, and others are only “fixed” in higher compatibility levels.
Lonely Road
I’ve seen a lot of people partition tables, expecting performance fireworks and afternoon delights, only to find no joy. In some cases, I’ve had to help people undo partitioning because critical queries slowed down.
It seems like a “free” thing you can do, especially if you’re clueless about how to find and fix real problems in your workload. Like most marquee features in SQL Server, there’s an air of mystery and misunderstanding about partitioning excels at and is best used for.
In most cases, SQL Server users seem to skip basic index tuning and go right to WE NEED TO PARTITION THIS THING.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Consulting gives you a lot of opportunities to talk to a lot of people and deal with interesting issues.
Recently it occurred to me that a lot of people seem to confer magic button status to a lot of things that always seem to be If-I-Could-Only-Do-This features that would solve all their problems, and similarly a Thing-That-Solved-One-Problem-Once turned into something that got used everywhere.
Go figure, right?
Let’s talk about some of them, so maybe I won’t have to talk this over with you someday, dear reader.
Partitioning
How this ended up being everyone’s top unexplored performance feature is beyond me. I always seem to hear that someone really wants to partition dbo.tblSomeBigTable because queries would be faster if they could eliminate partitions.
Maybe if you’re using clustered column store indexes it would, but for the rest of us, you’re no better off with a partitioned table than you are with a table that has decent indexing. In a lot of cases, partitioning can make things worse, or just more confusing.
Few people seem to consider the amount of work that goes into partitioning a really big table, either. It doesn’t matter if you want to do it in place, or use a batch process to copy data over.
Even fewer people talk about Partitioning for what it’s good for, which is managing partitions. Just make sure all those indexes are aligned.
Fill Factor
At this point, I’d expect everyone to understand why Flash and SSD storage is better than old spinning disks. Lack of moving parts, less pushing random I/O patterns, etc.
And yet, without a single page split being measured or compared, fill factor gets dropped down to 80 (or lower) just in case.
I call this Spinning Disk Mentality, and it hurts to see it out in the wild, especially when:
You’re on Standard Edition
You already have way more data than memory
You’re intentionally making data less compact
Your entire workload is stalled out on PAGEIOLATCH_XX waits
I truly appreciate the problem that lowering fill factor used to solve, but let’s join the CURRENT_CENTURY on this one.
Unless you have a good reason to add physical fragmentation to your indexes, how about we skip that?
In-Memory OLTP (Hekaton)
This is a hugely misunderstood feature. Everyone thinks it’s gonna make queries faster because tables will be in memory without reading the fine print.
If you have problems with throughput on very hot data, this might be a good solution for you.
If you’ve got a bunch of run-0f-the-mill queries that get blocked sometimes and performance generally stinks on, this isn’t really what you need to focus on.
I think the most common useful pattern I’ve seen for this feature is for “shock absorber” tables, where things like event betting, ticket sales, and online ordering all need to happen very quickly for a very small amount of data, and after the initial rush can be shuffled to regular disk-based tables.
If your table is already cached in memory when queries are hitting it, using this feature isn’t gonna make it any more in memory.
You’ve got other problems to solve.
Dirty Reads
Getting blocked sucks. It doesn’t matter if it’s in a database, at a bar, in traffic, or an artery. Everyone wants their reads instantly and they don’t wanna hear a darn word about it.
I’m not here to trample all over NOLOCK — I’ve defended people using it in the past — but I am here to ask you nicely to please reconsider dousing all your queries with it.
In many cases, READPASTis a better option, so your query can skip over locked rows rather than read a bunch of in-flight changes. This can be the wrong choice too, but it’s worth considering. It can be especially useful for modification queries that are just out looking for some work to do.
We’ll talk about my favorite option in tomorrow’s post.
Recompiling All The Things
Look, you wanna recompile a report or something, fine. I do, too. I love doing it, because then I don’t have one less random issue to think about.
Weirdly sniffed parameter? No mas, mon ami.
Magick.
Especially in cases where bigger code changes are hard/impossible, this can be sensible, like dealing with a million local variables.
Just be really careful using it everywhere, especially in code that executes a ton. You don’t wanna spend all your time constantly coming up with query plans any more than you wanna get parameter sniffed.
Plus, since Query Store captures plans with recompile hints, you can still keep track of performance over time. This can be a great way to figure out a parameter sniffing problem, too.
Gotcha
Basic understanding often is often just camouflage for complete confusion. Often, once you dig past the documentation marketing materials, you’ll find every feature has a whole lot of drawbacks, trade-offs, blind spots, and interoperability issues.
Databases being databases, often just getting your schema to a state where you can test new features is a heroic feat.
No wonder so many millions of hours have been spent trying to replace them.
UPDATE 2021-04-14: Microsoft has updated the documentation for all 2016+ versions of SQL Server to indicate that parallelism is available for partitioned tables in non-Enterprise versions.
For the sake of completeness, I did all my testing across both Standard and Developer Editions of SQL Server and couldn’t detect a meaningful difference.
There may be scenarios outside of the ones I tested that do show a difference, but, uh. I didn’t test those.
Obviously.
Every table is going to test this query at different DOPs.
SELECT
DATEPART(YEAR, vp.CreationDate) AS VoteYear,
DATEPART(MONTH, vp.CreationDate) AS VoteMonth,
COUNT_BIG(DISTINCT vp.PostId) AS UniquePostVotes,
SUM(vp.BountyAmount) AS TotalBounties
FROM dbo.Votes_p AS vp
GROUP BY
DATEPART(YEAR, vp.CreationDate),
DATEPART(MONTH, vp.CreationDate);
Two Partitions
Here’s the setup:
CREATE PARTITION FUNCTION VoteYear2013_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20130101'
);
GO
CREATE PARTITION SCHEME VoteYear2013_ps
AS PARTITION VoteYear2013_pf
ALL TO ([PRIMARY]);
DROP TABLE IF EXISTS dbo.Votes2013_p;
CREATE TABLE dbo.Votes2013_p
(
Id int NOT NULL,
PostId int NOT NULL,
UserId int NULL,
BountyAmount int NULL,
VoteTypeId int NOT NULL,
CreationDate datetime NOT NULL,
CONSTRAINT PK_Votes2013_p_Id
PRIMARY KEY CLUSTERED (CreationDate, Id)
) ON VoteYear2013_ps(CreationDate);
INSERT dbo.Votes2013_p WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v;
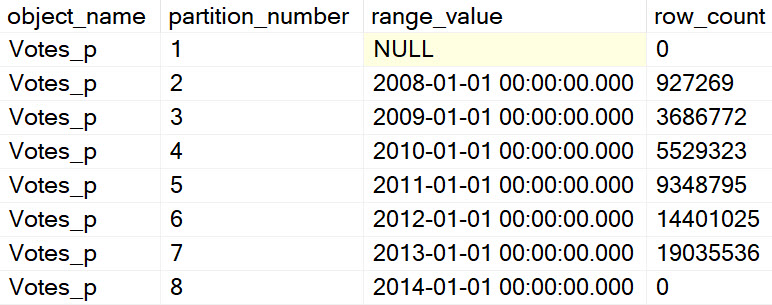
The data split looks like this:
not a good use of partitioning
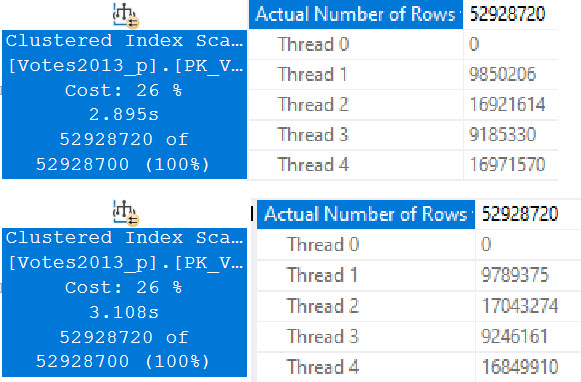
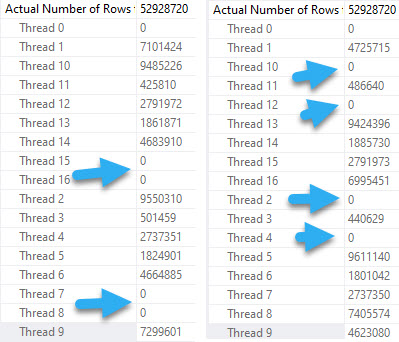
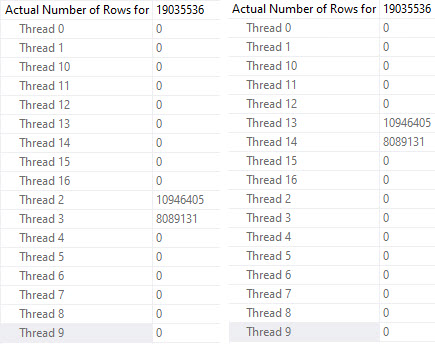
Running our test query at DOP 4, there are slight differences in counts across threads, but slight timing differences can explain that.
bonker
Standard Edition is on top, Developer Edition is at the bottom. There is a ~200ms difference here, but averaged out over multiple runs things end up pretty dead even.
Even looking at the row counts per thread, the distribution is close across both versions. I think it’s decently clear that the four threads work cooperatively across both partitions. A similar pattern continues at higher DOPs, too. I tested 8 and 16, and while there were slight differences in row counts per thread, there was a similar distribution pattern as at DOP 4.
Eight Partitions
Using a different partitioning function:
CREATE PARTITION FUNCTION VoteYear_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20080101',
'20090101',
'20100101',
'20110101',
'20120101',
'20130101',
'20140101'
);
GO
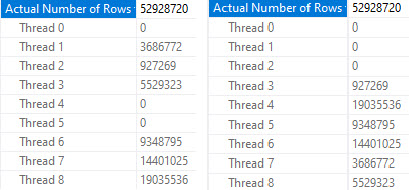
We’re going to jump right to testing the query at DOP 8.
dartford
Again, different threads end up getting assigned the work, but row counts match exactly across threads that did get work, and those numbers line up exactly to the number of rows in each partition.
pattern forming
In both queries, two threads scanned a partition with no rows and did no work. Each thread that did scan a partition scanned only one partition.
At DOP 16, the skew gets a bit worse, because now four threads do no work.
crap
The remaining threads all seem to split the populated partitions evenly, though again there are slight timing differences that result in different row counts per thread, but it’s pretty clear that there is cooperation here.
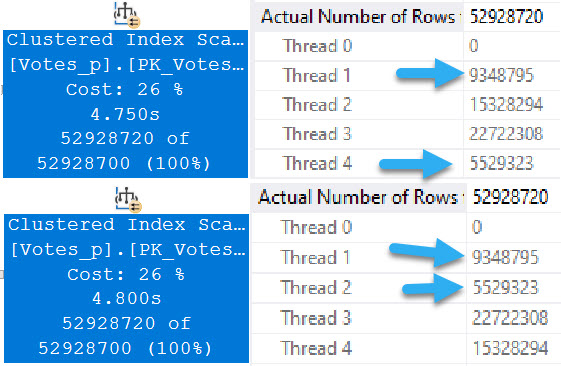
At DOP 4, things get a bit more interesting.
bedhead
In both queries, two threads scan exactly one partition.
The rows with arrows pointing at them represent numbers that exactly match the number of rows in a single partition.
The remaining threads have exactly the same row counts across versions.
Fifteen Partitions
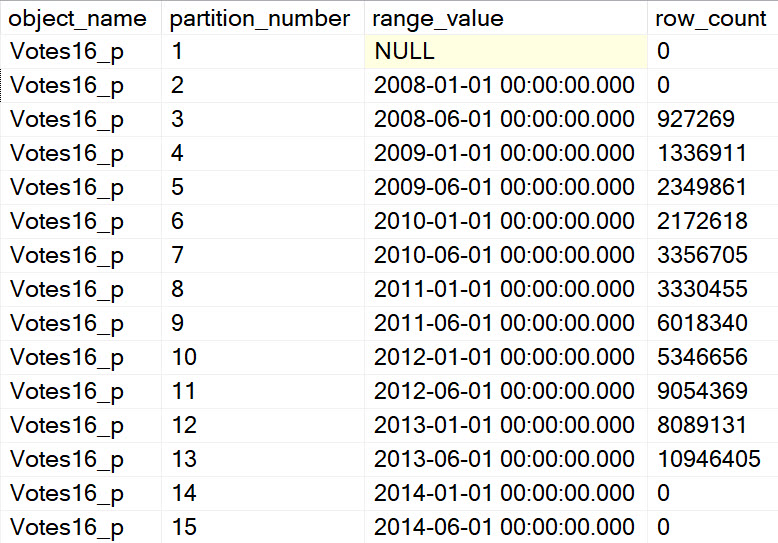
The results here show mostly the same pattern as before, so I’m keeping it short.
CREATE PARTITION FUNCTION VoteYear16_pf(DATETIME)
AS RANGE RIGHT FOR VALUES
(
'20080101',
'20080601',
'20090101',
'20090601',
'20100101',
'20100601',
'20110101',
'20110601',
'20120101',
'20120601',
'20130101',
'20130601',
'20140101',
'20140601'
);
GO
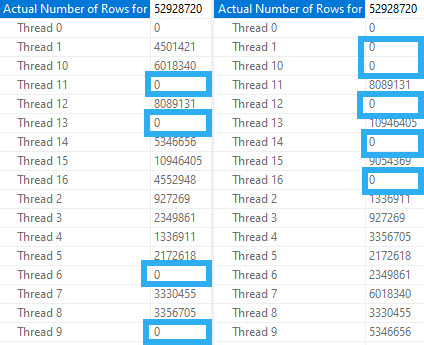
At DOP 4 and 8, threads work cooperatively across partitions. Where things get interesting (sort of) is at DOP 16.
craptastic
The four empty partitions here result in 4 threads doing no work in Developer/Enterprise Edition, and 5 threads doing no work in Standard Edition.
donkey
At first, I thought this might be a crack in the case, so I did things a little bit differently. In a dozen or so runs, the 5 empty threads only seemed to occur in the Standard Edition query. Sometimes it did, sometimes it didn’t. But it was at least something.
Fifteen Partitions, Mostly Empty
I used the same setup as above, but this time I didn’t fully load data from Votes in:
INSERT dbo.Votes16e_p WITH(TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.CreationDate >= '20130101';
And… Scene!
flop
That’s Just Great
Aside from one case where an extra thread got zero rows in Standard Edition, the behavior across the board looks the same.
Most of the behavior is sensible, but cases where multiple threads get no rows and don’t move on to other partitions is a little troubling.
Not that anyone has partitioning set up right anyway.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.