It’s somewhat strange to hear people carry on about best practices that are actually worst practices.
One worst practice that has strong staying power is the OPTIMIZE FOR UNKNOWN hint, which we talked about yesterday.
It probably doesn’t help that Microsoft has products (I’m looking at you, Dynamics) which have a setting to add the hint to every query. Shorter: If Microsoft recommends it, it must be good.
Thanks, Microsoft. Dummies.
Using the OPTIMIZE FOR UNKNOWN hint, or declaring variables inside of a code block to be used in a where clause have the same issue, though: they make SQL Server’s query optimizer make bad guesses, which often lead to bad execution plans.
We’re going to create two indexes on the Posts table:
CREATE INDEX
p0
ON dbo.Posts
(
OwnerUserId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
GO
CREATE INDEX
p1
ON dbo.Posts
(
ParentId,
CreationDate,
LastActivityDate
)
INCLUDE
(
PostTypeId
)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
GO
The indexes themselves are not as important as how SQL Server goes about choosing them.
Support Wear
This stored procedure is going to call the same query in three different ways:
One with the OPTIMIZE FOR UNKNOWN hint that uses parameters
One with local variables set to parameter values with no hints
One that accepts parameters and uses no hints
CREATE OR ALTER PROCEDURE
dbo.unknown_soldier
(
@ParentId int,
@OwnerUserId int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC
OPTION(OPTIMIZE FOR UNKNOWN);
DECLARE
@ParentIdInner int = @ParentId,
@OwnerUserIdInner int = @OwnerUserId;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentIdInner
AND p.OwnerUserId = @OwnerUserIdInner
ORDER BY
p.Score DESC,
p.Id DESC;
SELECT TOP (1)
p.*
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId
AND p.OwnerUserId = @OwnerUserId
ORDER BY
p.Score DESC,
p.Id DESC;
END;
GO
Placebo Effect
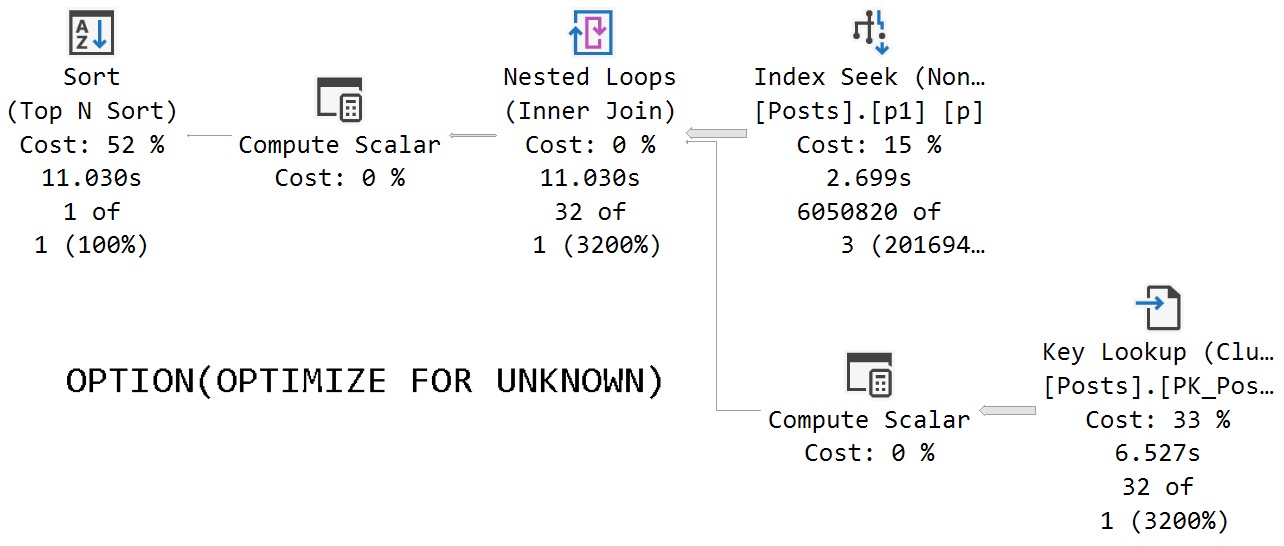
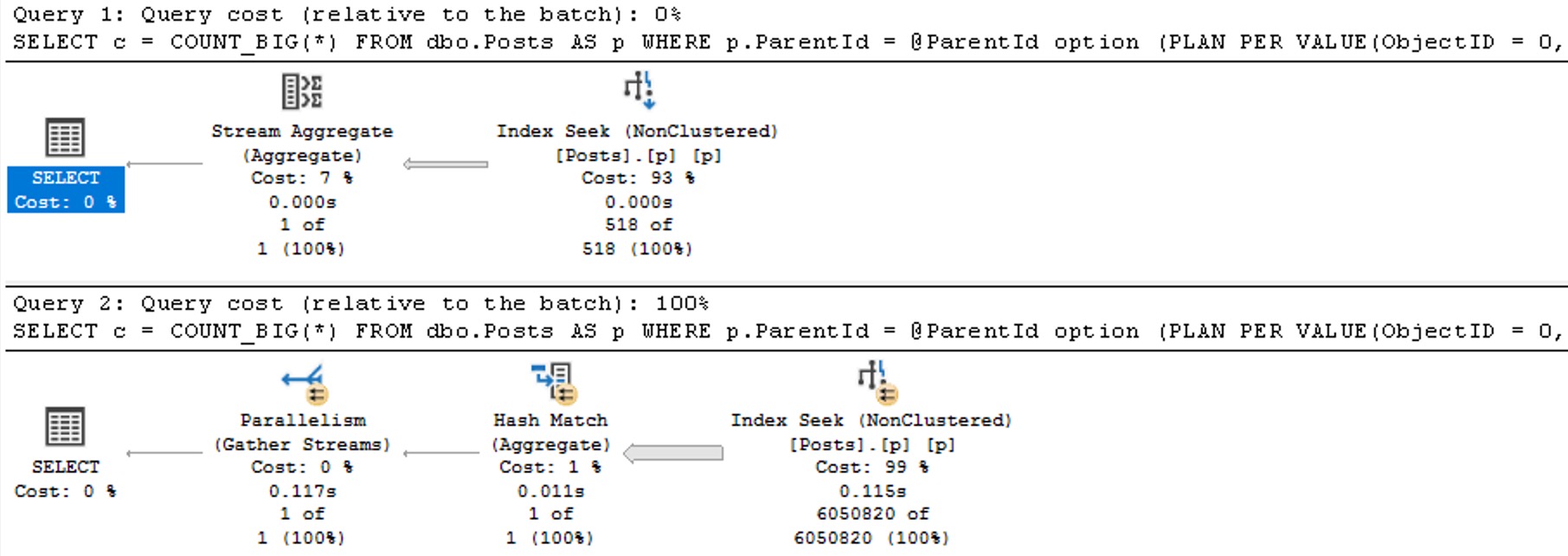
If we call the stored procedure with actual execution plans enabled, we get the following plans back.
The assumed selectivity that the OPTIMIZE FOR UNKNOWN hint produces as a cardinality estimate is way off the rails.
SQL Server thinks three rows are going to come back, but we get 6,050,820 rows back.
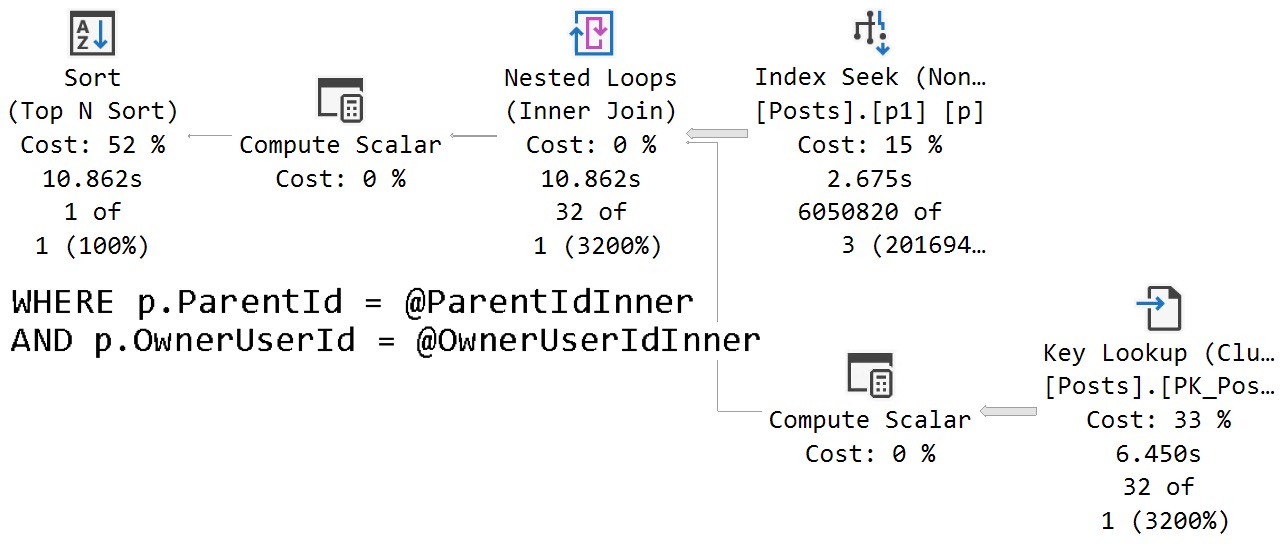
We get identical behavior from the second query that uses variables declared within the stored procedure, and set to the parameter values passed in.
release me
Same poor guesses, same index choices, same long running plan.
Parameter Effect
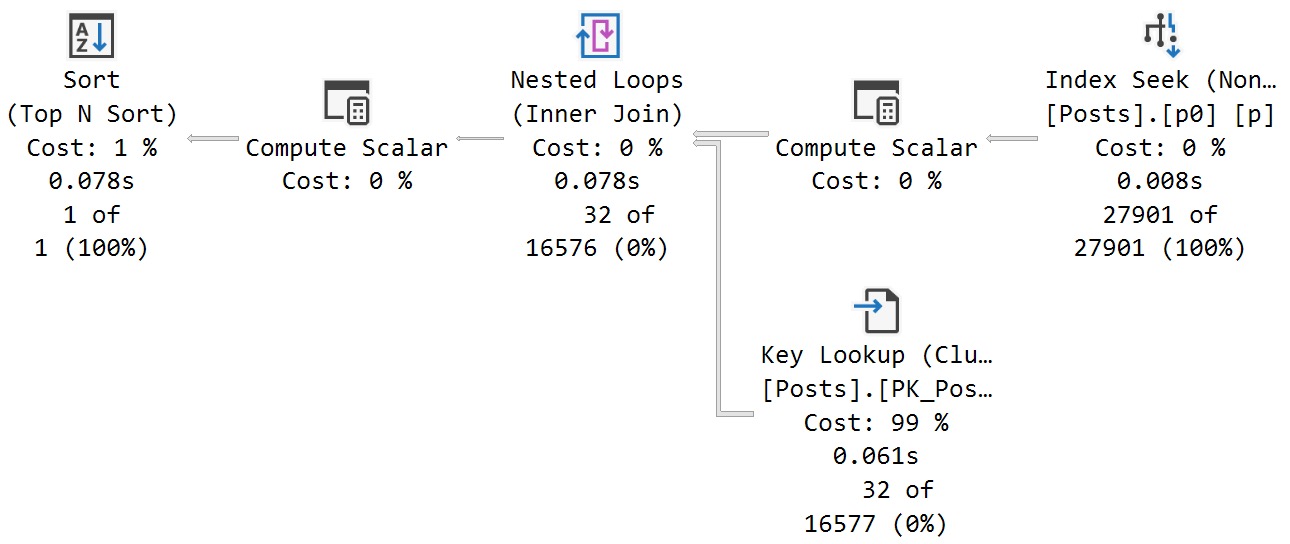
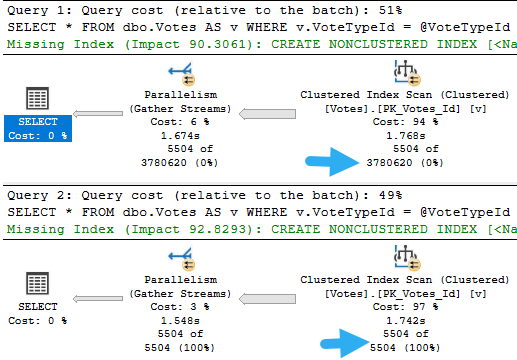
The query that accepts parameters and doesn’t have any hints applied to it fares much better.
transporter
In this case, we get an accurate cardinality estimate, and a more suitable index choice.
Note that both queries perform lookups, but this one performs far fewer of them because it uses an index that filters way more rows out prior to doing the lookup.
The optimizer is able to choose the correct index because it’s able to evaluate predicate values against the statistics histograms rather than using the assumed selectivity guess.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I admit that sp_prepare is an odd bird, and thankfully one that isn’t used a ton. I still run into applications that are unfortunate enough to have been written by people who hate bloggers and continue to use it, though, so here goes.
When you use sp_prepare, parameterized queries behave differently from normal: the parameters don’t get histogram cardinality estimates, they get density vector cardinality estimates.
Here’s a quick demo to show you that in action:
CREATE INDEX
p
ON dbo.Posts
(ParentId)
WITH
(
SORT_IN_TEMPDB = ON,
DATA_COMPRESSION = PAGE
);
DECLARE
@handle int =
NULL,
@parameters nvarchar(MAX) =
N'@ParentId int',
@sql nvarchar(MAX) =
N'
SELECT
c = COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.ParentId = @ParentId;
';
EXEC sys.sp_prepare
@handle OUTPUT,
@parameters,
@sql;
EXEC sys.sp_execute
@handle,
184618;
EXEC sys.sp_execute
@handle,
0;
EXEC sys.sp_unprepare
@handle;
OldPlan
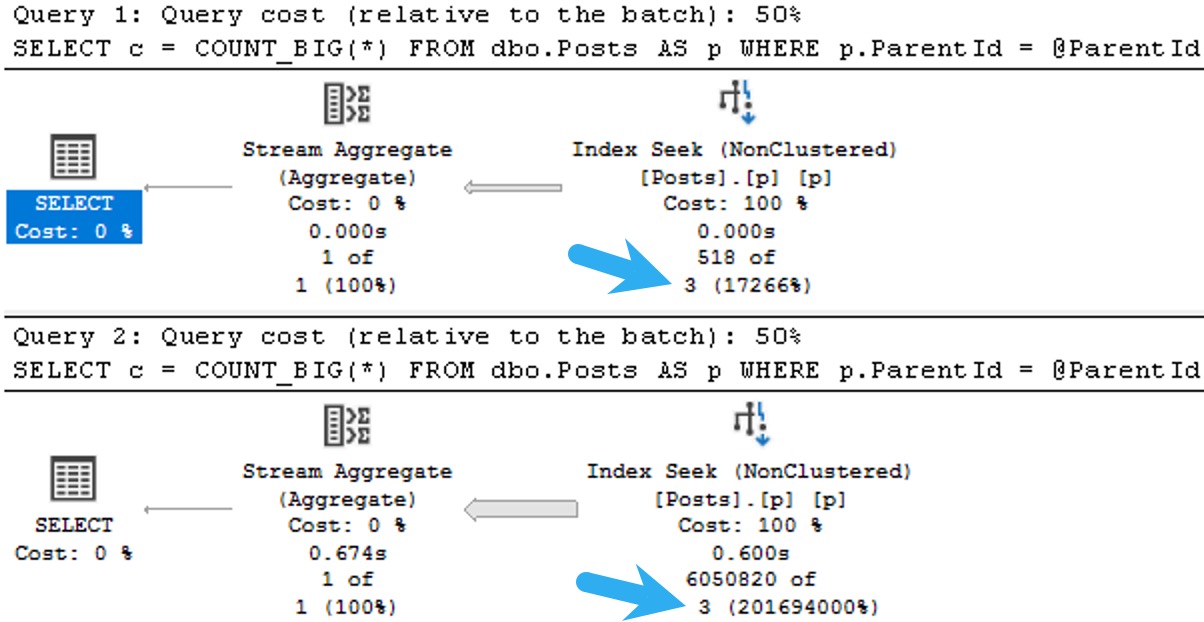
The plans for the two executions have the same poor cardinality estimate. In this case, since we have an ideal index and there’s no real complexity, there’s no performance issue.
But you can probably guess (at least for the second query) how being off by 201,694,000% might cause issues in queries that ask a bit more of the optimizer.
The point here is that both queries get the same incorrect estimate of 3 rows. If you add a recompile hint, or execute the same code using sp_executesql, the first query will get a histogram cardinality estimate, and the second query will reuse it.
one up
Given the historical behavior of sp_prepare, I was a little surprised that the Parameter Sensitive Plan (PSP) optimization available in SQL Server 2022 kicked in.
NewDifferent
If we change the database compatibility level to 160, the plans change a bit.
ALTER DATABASE StackOverflow2013 SET COMPATIBILITY_LEVEL = 160;
Now we see two different plans without a recompilation, as well as the plan per value option text at the end of the queries, indicating the PSP optimization kicked in.
two up
The differences here are fairly obvious, but…
Each plan gets accurate cardinality
The second plan goes parallel to make processing ~6 million rows faster
Different aggregates more suited to the amount of data in play are chosen (the hash match aggregate is eligible for batch mode)
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that, and need to solve database performance problems quickly. You can also get a quick, low cost health check with no phone time required.
I think it was sometime in the last century that I mentioned I often recommend folks turn on Forced Parameterization in order to deal with poorly formed application queries that send literal rather than parameterized values to SQL Server.
And then just like a magickal that, I recommended it to someone who also has a lot of problems with Local Variables in their stored procedures.
They were curious about if Forced Parameterization would fix that, and the answer is no.
But here’s proofs. We love the proofs.
Especially when they’re over 40.
A Poorly Written Stored Procedure
Here’s this thing. Don’t do this thing. Even the index is pretty dumb, because it’s on a single column.
CREATE INDEX
i
ON dbo.Users
(Reputation)
WITH
(SORT_IN_TEMPDB= ON, DATA_COMPRESSION = PAGE);
GO
CREATE PROCEDURE
dbo.humpback
(
@Reputation int
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
/*i mean don't really do this c'mon*/
DECLARE
@ReputationCopy int = ISNULL(@Reputation, 0);
SELECT
u.DisplayName,
u.Reputation,
u.CreationDate,
u.LastAccessDate
FROM dbo.Users AS u
WHERE u.Reputation = @ReputationCopy;
END;
ALTER DATABASE StackOverflow2013 SET PARAMETERIZATION FORCED;
GO
EXEC dbo.humpback
@Reputation = 11;
GO
ALTER DATABASE StackOverflow2013 SET PARAMETERIZATION SIMPLE;
GO
EXEC dbo.humpback
@Reputation = 11;
GO
For now, you’ll have to do a little more work to fix local variable problems.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In most programming languages, it’s quite sensible to create a variable or parameter, use some predefined logic to assign it a value, and then keep reusing it to prevent having to execute the same code over and over again.
But those languages are all procedural, and have a bit of a different set of rules and whatnot. In SQL Server, there are certainly somewhat procedural elements.
Functions
Control-flow logic
Cursors
While loops
Maybe the inner side of Nested Loops joins
You may be able to name some more, if you really get to thinking about it. That should be a common enough list, though.
Reusable Problems
SQL Server has a wonderful optimizer. It’s capable of many things, but it also has some problems.
Many of those problems exist today for “backwards compatibility”. In other words: play legacy games, win legacy performance.
Lots of people have found “workarounds” that rely on exploiting product behavior, and taking that away or changing it would result in… something else.
That’s why so many changes (improvements?) are hidden behind trace flags, compatibility levels, hints, batch mode, and other “fences” that you have to specifically hop to see if the grass is greener.
One of those things is the use of local variables. The linked post details how lousy those can be.
In SQL Server, context is everything. By context, I mean the way different methods of query execution are able to accept arguments from others.
You’ll sometimes hear this referred to as scope, too. Usually people will say inner context/scope and outer context/scope, or something similar.
What that means is something like this, if we’re talking about stored procedures:
CREATE PROCEDURE
dbo.InnerContext
(
@StartDate datetime,
@EndDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
SELECT
C.PostId,
Score =
SUM(C.Score)
FROM dbo.Comments AS C
JOIN dbo.Votes AS V
ON C.PostId = V.PostId
WHERE C.CreationDate >= @StartDate
AND c.CreationDate < @EndDate
GROUP BY c.PostId;
END;
GO
CREATE PROCEDURE
dbo.OuterContext
(
@StartDate datetime,
@EndDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @StartDate IS NULL
BEGIN
SELECT
@StartDate = GETDATE();
END;
IF @EndDate IS NULL
BEGIN
SELECT
@EndDate = DATEADD(DAY, 30, GETDATE());
END;
EXEC dbo.InnerContext
@StartDate = @StartDate,
@EndDate = @EndDate;
END;
CREATE PROCEDURE
dbo.OuterContext
(
@StartDate datetime,
@EndDate datetime
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
IF @StartDate IS NULL
BEGIN
SELECT
@StartDate = GETDATE();
END;
IF @EndDate IS NULL
BEGIN
SELECT
@EndDate = DATEADD(DAY, 30, GETDATE());
END;
DECLARE
@sql nvarchar(MAX) = N'
/*dbo.OuterContext*/
SELECT
C.PostId,
Score =
SUM(C.Score)
FROM dbo.Comments AS C
JOIN dbo.Votes AS V
ON C.PostId = V.PostId
WHERE C.CreationDate >= @StartDate
AND c.CreationDate < @EndDate
GROUP BY c.PostId;
';
EXEC sys.sp_executesql
@sql,
N'@StartDate datetime,
@EndDate datetime',
@StartDate,
@EndDate;
END;
Which will achieve the same thing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ve written at length about what local variables do to queries, so I’m not going to go into it again here.
What I do want to talk about are better alternatives to what you currently have to do to fix issues:
RECOMPILE the query
Pass the local variable to a stored procedure
Pass the local variable to dynamic SQL
It’s not that I hate those options, they’re just tedious. Sometimes I’d like the benefit of recompiling with local variables without all the other strings that come attached to recompiling.
Hint Me Baby One More Time
Since I’m told people rely on this behavior to fix certain problems, you would probably need a few different places to and ways to alter this behavior:
Database level setting
Query Hint
Variable declaration
Database level settings are great for workloads you can’t alter, either because the queries come out of a black box, or you use an ORM and queries… come out of a nuclear disaster area.
Query hints are great if you want all local variables to be treated like parameters. But you may not want that all the time. I mean, look: you all do wacky things and you’re stuck in your ways. I’m not kink shaming here, but facts are facts.
You have to draw the line somewhere and that somewhere is always “furries”.
And then local variables.
It may also be useful to allow local variables to be declared with a special property that will allow the optimizer to treat them like parameters. Something like this would be easy enough:
DECLARE @p int PARAMETER = 1;
Hog Ground
Given that in SQL Server 2019 table variables got deferred compilation, I think this feature is doable.
Of course, it’s doable today if you’ve got a debugger and don’t mind editing memory space.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are many good reasons to parameterize a query, but there are also trade-offs. There’s no such thing as a free parameter, as they say.
In this post, we’re going to discuss what is and isn’t a parameter, and some of the pros and cons.
What’s important to keep in mind is that good indexing can help avoid many of the cons, but not all. Bad indexing, of course, causes endless problems.
There are many good reasons to parameterize your queries, too. Avoiding SQL injection is a very good reason.
But then!
What’s Not A Parameter
It can be confusing to people who are getting started with SQL Server, because parameters and variables look exactly the same.
They both start with @, and feel pretty interchangeable. They behave the same in many ways, too, except when it comes to cardinality estimation.
To generalize a bit, though, something is a parameter if it belongs to an object. An object can be an instance of:
A stored procedure
A function
Dynamic SQL
Things that aren’t parameters are things that come into existence when you DECLARE them. Of course, you can pass things you declare to one of the objects above as parameters. For example, there’s a very big difference between these two blocks of code:
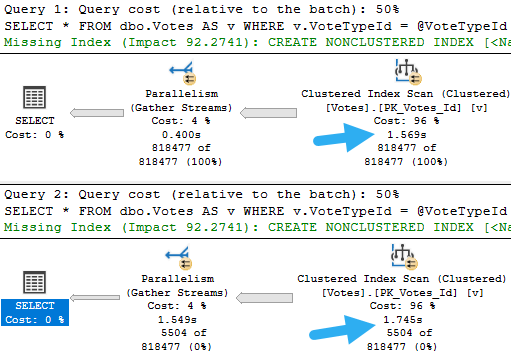
DECLARE @VoteTypeId INT = 7;
SELECT *
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @VoteTypeId;
DECLARE @sql NVARCHAR(MAX) = N'
SELECT *
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @VoteTypeId;
'
EXEC sp_executesql @sql, N'@VoteTypeId INT', @VoteTypeId;
But it’s not obvious until you look at the query plans, where the guess for the declared variable is god awful.
Then again, if you read the post I linked to up there, you already knew that. Nice how that works.
If you’re too lazy to click, I’m too lazy to repeat myself.
thanks
What’s the point? Variables, things you declare, are treated differently from parameters, things that belong to a stored procedure, function, or dynamic SQL.
Parameter Problems
The problem with parameterization is one of familiarity. It not only breeds contempt, but… sometimes data just grows apart.
Really far apart.
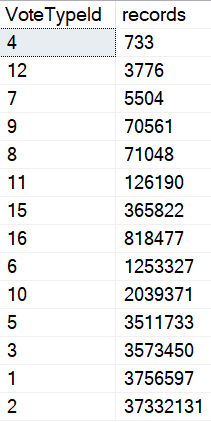
SELECT
v.VoteTypeId,
COUNT_BIG(*) AS records
FROM dbo.Votes AS v
GROUP BY v.VoteTypeId
ORDER BY records;
pattern forming
Natural Selection
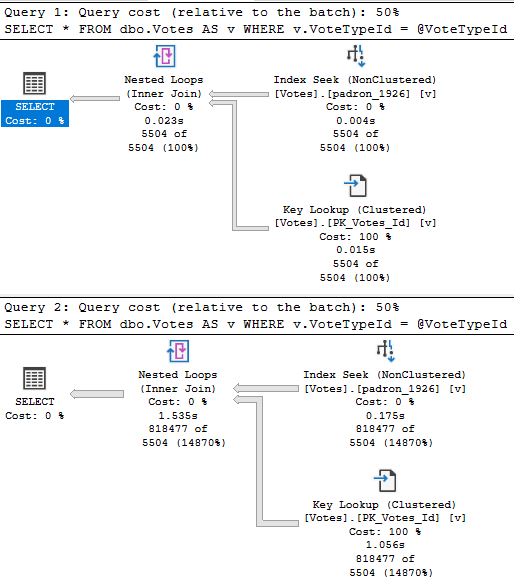
When you parameterize queries, you give SQL Server permission to remember, and more importantly, to re-use.
What it re-uses is the execution plan, and what it remembers are cardinality estimates. If we do something like this, we don’t get two different execution plans, or even two different sets of guesses, even though the values that we’re feeding to each query have quite different distributions in our data.
The result is two query plans that look quite alike, but behave quite differently.
wist
One takes 23 milliseconds. The other takes 1.5 seconds. Would anyone complain about this in real life?
Probably not, but it helps to illustrate the issue.
Leading Miss
Where this can get confusing is when you’re trying to diagnose a performance problem.
If you look in the plan cache, or in query store, you’ll see the plan that gets cached for the very first parameter. It’ll look simple and innocent, sure. But the problem is with a totally different parameter that isn’t logged anywhere.
You might also face a different problem, where the query recompiles because you restarted the server, updated stats, rebuilt indexes, or enough rows in the table changed to trigger an automatic stats update. If any of those things happen, the optimizer will wanna come up with a new plan based on whatever value goes in first.
If the roles get reversed, the plan will change, but they’ll both take the same amount of time now.
DECLARE @VoteTypeId INT;
SET @VoteTypeId = 16
DECLARE @sql NVARCHAR(MAX) = N'
SELECT *
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @VoteTypeId;
';
EXEC sp_executesql @sql, N'@VoteTypeId INT', @VoteTypeId;
SET @VoteTypeId = 7;
SET @sql = N'
SELECT *
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @VoteTypeId;
';
EXEC sp_executesql @sql, N'@VoteTypeId INT', @VoteTypeId;
totin’
Deal With It ?
In the next few posts, we’ll talk about what happens when you don’t parameterize queries, and different ways to deal with parameter sniffing.
A recompile hint can help, it might not always be appropriate depending on execution frequency and plan complexity
Optimize for unknown hints will give you the bad variable guess we saw at the very beginning of this post
We’re going to need more clever and current ways to fix the issue. If you’re stuck on those things recompiling or unknown-ing, you’re stuck not only on bad ideas, but outdated bad ideas.
Like duck l’orange and Canadian whiskey.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I see this kind of pattern a lot in paging queries where people are doing everything in their power to avoid writing dynamic SQL for some reason.
It’s almost as if an entire internet worth of SQL Server knowledge and advice doesn’t exist when they’re writing these queries.
Quite something. Quite something indeed.
First, let’s get what doesn’t work out of the way.
DECLARE @order_by INT = 3
SELECT p.Id
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY CASE WHEN @order_by = 1 THEN p.Score
WHEN @order_by = 2 THEN p.CreationDate
WHEN @order_by = 3 THEN p.Id
ELSE NULL
END;
GO
You can’t write this as a single case expression with mismatched data types.
It’ll work for the first two options, but not the third. We’ll get this error, even with a recompile hint:
Msg 8115, Level 16, State 2, Line 46
Arithmetic overflow error converting expression to data type datetime.
What Works But Still Stinks
Is when you break the options out into separate case expressions, like so:
DECLARE @order_by INT = 1
SELECT p.Id
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY CASE WHEN @order_by = 1 THEN p.Score ELSE NULL END,
CASE WHEN @order_by = 2 THEN p.CreationDate ELSE NULL END,
CASE WHEN @order_by = 3 THEN p.Id ELSE NULL END;
GO
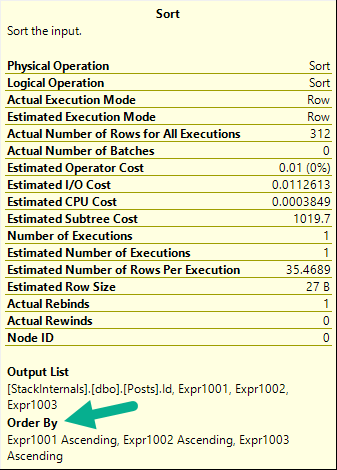
This will work no matter which option we choose, but something rather disappointing happens when we choose option three.
Here’s the query plan. Before you read below, take a second to try to guess what it is.
Sorta Kinda
What Stinks Even Though It Works
My issue with this plan is that we end up with a sort operator, even though we’re ordering by Id, which is the primary key and clustered index key, and we use that very same index. We technically have the data in order, but the index scan has False for the Ordered attribute, and the Sort operator shows a series of expressions.
stunk
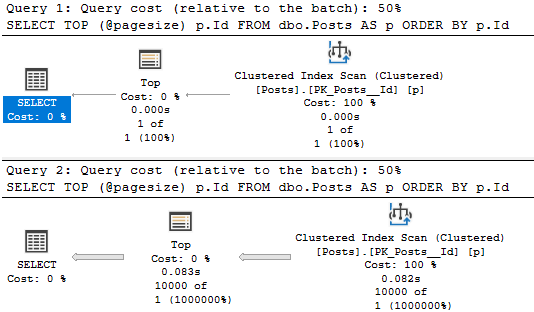
The Sort of course goes away if we add a recompile hint, and the Scan now has True for the Ordered attribute.
DECLARE @order_by INT = 3
SELECT p.Id
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY CASE WHEN @order_by = 1 THEN p.Score ELSE NULL END,
CASE WHEN @order_by = 2 THEN p.CreationDate ELSE NULL END,
CASE WHEN @order_by = 3 THEN p.Id ELSE NULL END
OPTION(RECOMPILE);
GO
no worse
You Shouldn’t Do This
Unless you’re fine with recompile hints, which I don’t blame you if you are.
SQL Server seems to get a whole lot more right when you use one, anyway.
My point though, is that adding uncertainty like this to your queries is more often than not harmful in the long term. Though this post is about local variables, the same thing would happen with parameters, for example:
DECLARE @order_by INT = 3
DECLARE @sql NVARCHAR(MAX) = N'
SELECT p.Id
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY CASE WHEN @order_by = 1 THEN p.Score ELSE NULL END,
CASE WHEN @order_by = 2 THEN p.CreationDate ELSE NULL END,
CASE WHEN @order_by = 3 THEN p.Id ELSE NULL END;
';
EXEC sys.sp_executesql @sql, N'@order_by INT', 1;
EXEC sys.sp_executesql @sql, N'@order_by INT', 3;
GO
The way to address it would be something like this:
DECLARE @order_by INT = 3
DECLARE @sql NVARCHAR(MAX) = N'
SELECT p.Id
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY ';
SET @sql +=
CASE WHEN @order_by = 1 THEN N'p.Score'
WHEN @order_by = 2 THEN N'p.CreationDate'
WHEN @order_by = 3 THEN N'p.Id'
ELSE N''
END;
EXEC sys.sp_executesql @sql
GO
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
In case you missed it for some reason, check out this post of mine about local variables. Though it’s hard to imagine how you missed it, since it’s the single most important blog post ever written, even outside of SQL Server. It might even be more important than SQL Server. Time will tell.
While live streaming recently about paging queries, I thought that it might make an interesting post to see what happens when you use variables in places other than the where clause.
After several seconds of thinking about it, I decided that TOP would be a good enough place to muck around.
Unvariables
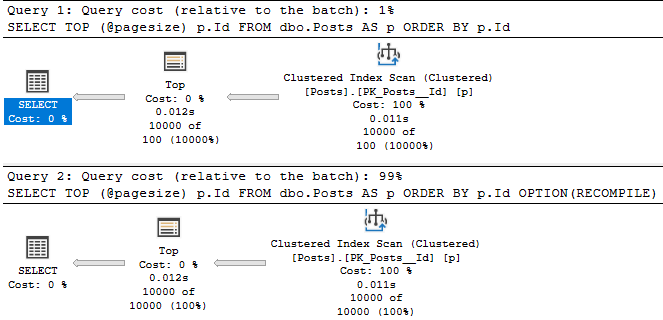
Let’s say you’ve got these two queries.
DECLARE @pagesize INT = 10000;
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id;
GO
DECLARE @pagesize INT = 10000;
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id
OPTION(RECOMPILE);
GO
Without a RECOMPILE hint, you get a 100 row estimate for the local variable in a TOP.
You can manipulate what the optimizer thinks it’ll get with optimizer for hints:
DECLARE @pagesize INT = 10000;
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id
OPTION(OPTIMIZE FOR(@pagesize = 1));
GO
the chump is here
And of course, when used as actual parameters, can be sniffed.
DECLARE @pagesize INT = 10000;
DECLARE @sql NVARCHAR(1000) =
N'
SELECT TOP (@pagesize) p.Id
FROM dbo.Posts AS p
ORDER BY p.Id;
'
EXEC sys.sp_executesql @sql, N'@pagesize INT', 1;
EXEC sys.sp_executesql @sql, N'@pagesize INT', 10000;
GO
boogers
Got More?
In tomorrow’s post, I’ll look at how local variables can be weird in ORDER BY. If you’ve got other ideas, feel free to leave them here.
There’s not much more to say about WHERE or JOIN, I’m looking for more creative applications ?
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Normally, I link people to this post by Kendra and this post by Paul when I need to point them to information about what goes wrong with local variables. They’re both quite good, but I wanted something a little more specific to the situation I normally see with people locally, along with some fixes.
First, some background:
In a stored procedure (and even in ad hoc queries or within dynamic SQL, like in the examples linked above), if you declare a variable within that code block and use it as a predicate later, you will get either a fixed guess for cardinality, or a less-confidence-inspiring estimate than when the histogram is used.
The local variable effect discussed in the rest of this post produces the same behavior as the OPTIMIZE FOR UNKNOWN hint, or executing queries with sp_prepare. I have that emphasized here because I don’t want to keep qualifying it throughout the post.
That estimate will be based on the number of rows in the table, and the “All Density” of the column multiplied together, for single equality predicates. The process for multiple predicates depends on which cardinality estimation model you’re using.
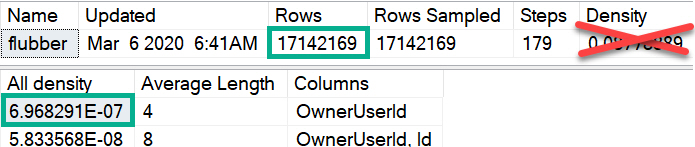
CREATE INDEX flubber
ON dbo.Posts(OwnerUserId);
DBCC SHOW_STATISTICS(Posts, flubber);
Injury
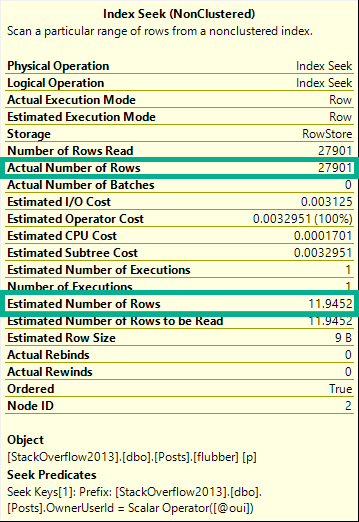
For example, this query using a single local variable with a single equality:
DECLARE @oui INT = 22656;
SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @oui;
Will get an estimate of 11.9-ish, despite 27,901 rows matching over here in reality.
Poo
Which can be replicated like so, using the numbers from the screenshot up yonder.
SELECT (6.968291E-07 * 17142169) AS [?]
Several Different Levels
You can replicate the “All Density” calculation by doing this:
SELECT (1 /
CONVERT(FLOAT, COUNT(DISTINCT p.OwnerUserId))
) AS [All Density]
FROM Posts AS p
GO
Notice I didn’t call the estimate “bad”. Even though it often is quite bad, there are some columns where the distribution of values will be close enough to this estimate for it not to matter terribly for plan shape, index choice, and overall performance.
Don’t take this as carte blanche to use this technique; quite the opposite. If you’re going to use it, it needs careful testing across a variety of inputs.
Why? Because confidence in estimates decreases as they become based on less precise information.
In these estimates we can see a couple optimizer rules in action:
Inclusion: We assume the value is there — the alternative is ghastly
Uniformity: The data will have an even distribution of unique values
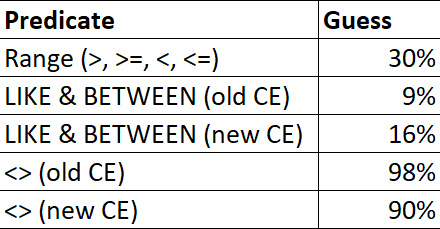
For ranges (>, >=, <, <=), LIKE, BETWEEN, and <>, there are different fixed guesses.
Destined for Lateness
These numbers may change in the future, but up through 2019 this is what my testing resulted in.
Heck, maybe this behavior will be alterable in the future :^)
No Vector, No Estimate
A lot of people (myself included) will freely interchange “estimate” and “guess” when talking about this process. To the optimizer, there’s a big difference.
An estimate represents a process where math formulas with strange fonts that I don’t understand are used to calculate cardinality.
A guess represents a breakdown in that process, where the optimizer gives up, and a fixed number is used.
Say there’s no “density vector” available for the column used in an equality predicate. Maybe you have auto-create stats turned off, or stats created asynchronously is on for the first compilation.
You get a guess, not an estimate.
ALTER DATABASE StackOverflow2013 SET AUTO_CREATE_STATISTICS OFF;
GO
DECLARE @oui INT = 22656;
SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @oui;
SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @oui OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
GO
ALTER DATABASE StackOverflow2013 SET AUTO_CREATE_STATISTICS ON;
GO
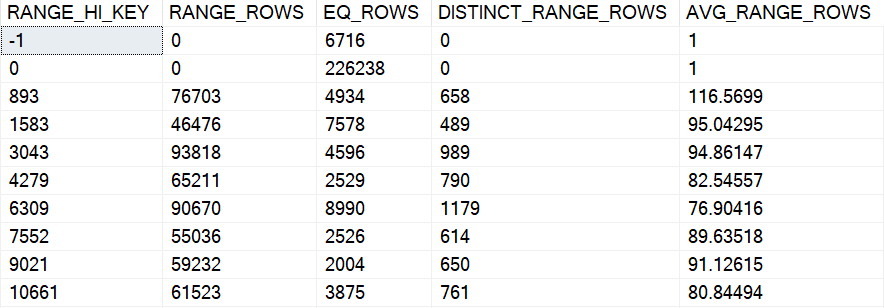
Using the new cardinality estimator (CE), which Microsoft has quite presumptuously started calling the Default CE, I get a guess of 4,140.
Using the legacy CE, which maybe I’ll start referring to as the Best CE, to match the presumptuousness of Microsoft, I get a guess of 266,409.
Though neither one is particularly close to the reality of 27,901 rows, we can’t expect a good guess because we’re effectively poking the optimizer in the eyeball by not allowing it to create statistics, and by using a local variable in our where clause.
These things would be our fault, regardless of the default-ness, or best-ness, of the estimation model.
If you’re keen on calculating these things yourself, you can do the following:
SELECT POWER(CONVERT(FLOAT, 17142169), 0.75) AS BEST_CE;
SELECT SQRT(CONVERT(FLOAT, 17142169)) AS default_ce_blah_whatever;
SELECT COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.CreationDate = p.CommunityOwnedDate;
SELECT COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.CreationDate = p.CommunityOwnedDate
OPTION(USE HINT('FORCE_LEGACY_CARDINALITY_ESTIMATION'));
The so-called “default” CE thinks 1,714,220 rows will match for a column-equals-column comparison, and the “legacy” CE thinks 6.44248 rows will match, assuming that histograms are available for both of these queries.
How many actually match? 59,216.
I never said this was easy, HOWEVER!
Ahem.
The “legacy” CE estimate comes from advanced maths that only people who vape understand, while the so-called “default” CE just guesses ten percent, in true lazybones fashion. “You treat your stepmother with respect, Pantera!“, as a wise man once said.
Second, what we want to happen:
Code that uses literals, parameters, and other sniff-able forms of predicates use the statistics histogram, which typically has far more valuable information about data distribution for a column. No, they’re not always perfect, and sure, estimates can still be off if we use this, but that’s a chance I’m willing to take.
Even if they’re out of date. Maybe. Maybe not.
Look, just update those statistics.
American Histogram X
Like I mentioned before, these estimates typically have higher confidence levels because they’re often based on more precise details about the data.
If I had to rank them:
Direct histogram step hits for an equality
Intra-step hits for an equality
Direct histogram step hits for a range
Intra-step hits for a range
Inequalities (not equals to)
Joins
1000 other things
All the goofy stuff you people do to make this more difficult, like wrapping columns in functions, mismatching data types, using local variables, etc.
Of course, parameterized code does open us up to parameter sniffing issues, which I’m not addressing in this post. My only goal here is to teach people how to get out of performance jams caused by local variables giving you bad-enough estimates. Ha ha ha.
Plus, there’s a lot of negativity out there already about parameter sniffing. A lot of the time it does pretty well, and we want it to happen.
Over-Under
The main issues with the local variable/density vector estimates is that they most often don’t align well with reality, and they’re almost certainly a knee-jerk reaction to a parameter sniffing problem, or done out of ignorance to the repercussions. It would be tedious to walk through all of the potential plan quality issues that could arise from doing this, though I did record a video about one of them here.
Instead of doing all that stuff, I’d rather walk through what works and what doesn’t when it comes to fixing the problem.
But first, what doesn’t work!
Temporary Objects Don’t Usually Work
If you put the value of the local variable in a #temp table, you can fall victim to statistics caching. If you use a @table variable, you don’t get any column-level statistics on what values go in there (even with a recompile hint or trace flag 2453, you only get table cardinality).
There may be some circumstances where a #temp table can help, or can get you a better plan, but they’re probably not my first stop on the list of fixes.
The #temp table will require a uniqueness constraint to work
This becomes more and more difficult if we have multiple local variables to account for
And if they have different data types, we need multiple #temp tables, or wide tables with a column and constraint per parameter
From there, we end up with difficulties linking those values in our query. Extra joins, subqueries, etc. all have potential consequences.
Inline Table Valued Functions Don’t Work
They’re a little too inline here, and they use the density vector estimate. See this gist for a demo.
Recompile Can Work, But Only Do It For Problem Statements
It has to be a statement-level recompile, using OPTION(RECOMPILE). Putting recompile as a stored procedure creation option will not allow for parameter embedding optimizations, i.e. WITH RECOMPILE.
One of these things is not like the other.
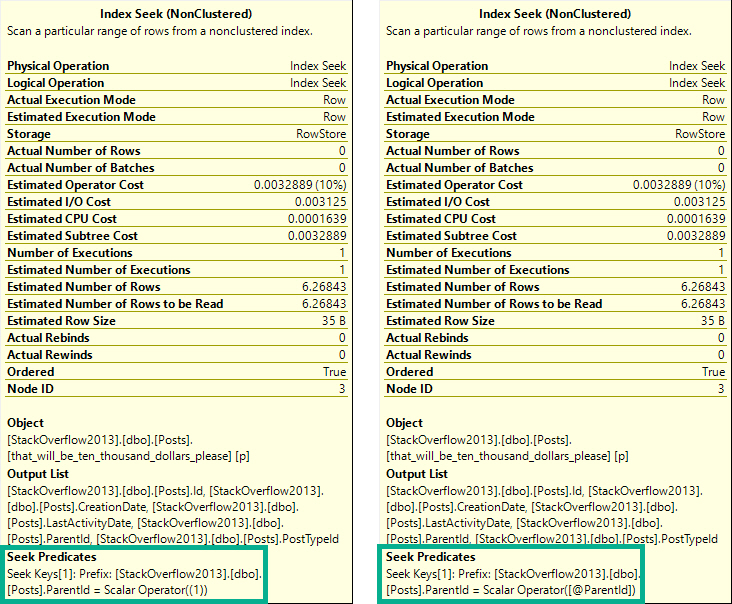
The tool tip on the left is from a plan with a statement-level recompile. On the right is from a plan with a procedure-level recompile. In the statement-level recompile plan, we can see the scalar operator is a literal value. In the procedure-level recompile, we still see @ParentId passed in.
The difference is subtle, but exists. I prefer statement-level recompiles, because it’s unlikely that every statement in a procedure should or needs to be recompiled, unless it’s a monitoring procedure or something else with no value to the plan cache.
Targeting specific statements is smarterer.
Erer.
A more detailed examination of this behavior is at Paul’s post, linked above.
Dynamic SQL Can Work
Depending on complexity, it may be more straight forward to use dynamic SQL as a receptacle for your variables-turned-parameters.
CREATE PROCEDURE dbo.game_time(@id INT)
AS BEGIN
DECLARE @id_fix INT;
SET @id_fix = CASE WHEN @id < 0 THEN 1 ELSE @id END;
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @id;';
EXEC sys.sp_executesql @sql, N'@id INT', @id_fix
END;
Separate Stored Procedures Can Work
If you need to declare variables internally and perform some queries to assign values to them, passing them on to separate stored procedures can avoid the density estimates. The stored procedure occurs in a separate context, so all it sees are the values passed in as parameters, not their origins as variables.
In other words, parameters can be sniffed; variables can’t.
CREATE PROCEDURE dbo.game_time(@id INT)
AS
BEGIN
DECLARE @id_fix INT;
SET @id_fix = CASE WHEN @id < 0 THEN 1 ELSE @id END;
EXEC dbo.some_new_proc @id_fix;
END;
Just pretend the dynamic SQL from above occupies the stored procedure dbo.some_new_proc here.
Optimizing For A Value Can Work
But choosing that value is hard. If one is feeling ambitious, one could take the local parameter value, compare it to the histogram on one’s own, then choose a value on one’s own that, one, on their own, could use to determine if a specific, common, or nearby value would be best to optimize for, using dynamic SQL that one has written on one’s own.
Ahem.
CREATE PROCEDURE dbo.game_time(@id INT)
AS BEGIN
DECLARE @id_fix INT;
SET @id_fix = CASE WHEN @id < 0 THEN 1 ELSE @id END;
DECLARE @a_really_good_choice INT;
SET @a_really_good_choice = 2147483647; --The result of some v. professional code IRL.
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'SELECT COUNT(*) FROM dbo.Posts AS p WHERE p.OwnerUserId = @id OPTION(OPTIMIZE FOR(@id = [a_really_good_choice]));';
SET @sql = REPLACE(@sql, N'[a_really_good_choice]', @a_really_good_choice);
EXEC sys.sp_executesql @sql, N'@id INT', @id_fix;
END;
GO
Wrapping Up
This post aimed to give you some ways to avoid getting bad density vector estimates with local variables. If you’re getting good guesses, well, sorry you had to read all this.
When I see this pattern in client code, it’s often accompanied by comments about fixing parameter sniffing. While technically accurate, it’s more like plugging SQL Server’s nose with cotton balls and Lego heads.
Sometimes there will be several predicate filters that diminish the impact of estimates not using the histogram. Often a fairly selective predicate evaluated first is enough to make this not suck too badly. However, it’s worth learning about, and learning how to fix correctly.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.