If you’re like me, you started your database journey by defining cursors with the default options. This went on until a senior developer or DBA kindly pointed out that you can get better performance by using the FAST_FORWARD option. Or maybe you were a real go-getter and found Aaron Bertrand’s performance benchmarking blog post on different cursor options. I admit that for many years I didn’t care to know why FAST_FORWARD sometimes made my queries faster. It had “FAST” in the name and that was good enough for me.
Recently I saw a production issue where using the right cursor options led to a 1000X performance improvement. I decided that ten years of ignorance was enough and finally did some research on different cursor options. This post contains a reproduction and discussion of the production issue.
A Dramatic Example
The code below creates a 16 GB table. It has a primary key and clustered index on the ID column and a nonclustered index on the ID2 column. You can adjust the TOP value to insert fewer rows if you wish to create a smaller table, but don’t drop it below 200000.
DROP TABLE IF EXISTS tbl_1;
CREATE TABLE tbl_1 (
ID BIGINT NOT NULL,
ID2 BIGINT NOT NULL,
PAGE_FILLER VARCHAR(5000) NOT NULL,
PRIMARY KEY (ID)
);
INSERT INTO tbl_1 WITH (TABLOCK)
SELECT RN, RN % 100000, REPLICATE('Z', 5000)
FROM
(
SELECT TOP (2000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) q
OPTION (MAXDOP 1);
CREATE INDEX IX2 ON tbl_1 (ID2);
Consider the following select query, which is a simplified example of the production query:
Select ID from tbl_1 WHERE ID2 < 1 ORDER BY ID;
There’s an index on ID2 and the filter is highly selective: only 20 rows out of 2 million will match. I would expect the query optimizer to use that index and for the query to finish instantly. The following stored procedure defines a FAST_FORWARD cursor for that SELECT query, fetches the 20 matching rows, and does nothing with them:
CREATE OR ALTER PROCEDURE CURSOR_WITH_FF AS BEGIN SET NOCOUNT ON; Declare @ID BIGINT; Declare FF Cursor FAST_FORWARD for Select ID from tbl_1 WHERE ID2 < 1 ORDER BY ID; Open FF; Fetch Next from FF into @ID; WHILE @@FETCH_STATUS = 0 BEGIN Fetch Next from FF into @ID; END; Close FF; Deallocate FF; END;
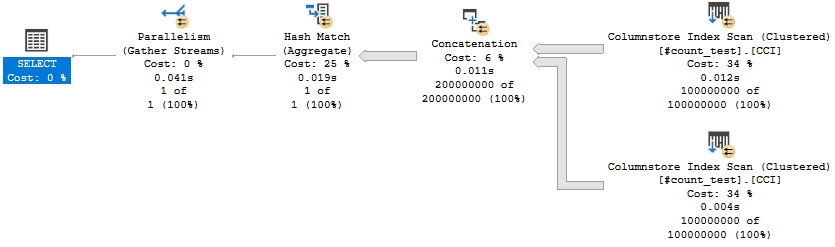
Executing the stored procedure takes about 2 ms on my machine. In this case, I get a query plan that’s very similar to what I’d get by running a simple SELECT query. There’s some additional cursor garbage, but that doesn’t impact performance in this case:
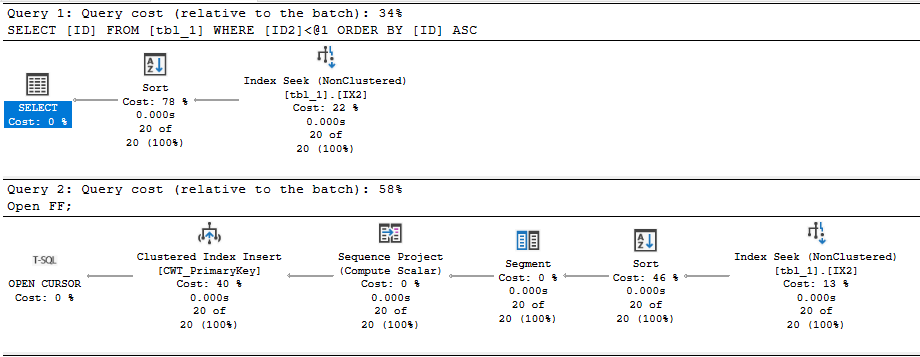
Regrettably, the code takes 50 seconds to execute on my machine if I remove the FAST_FORWARD option. What is responsible for the dramatic difference in runtime?
The “What”
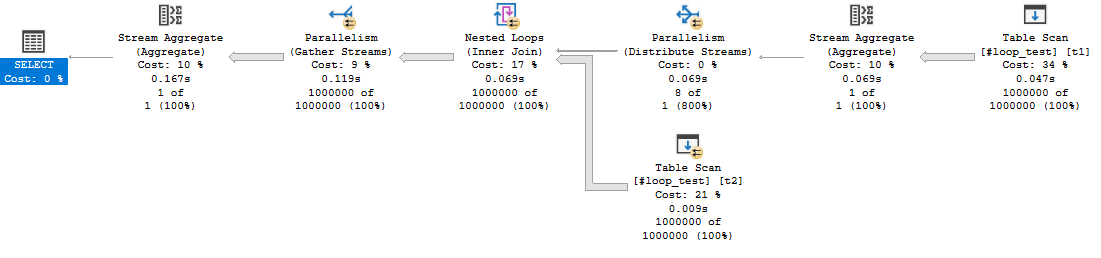
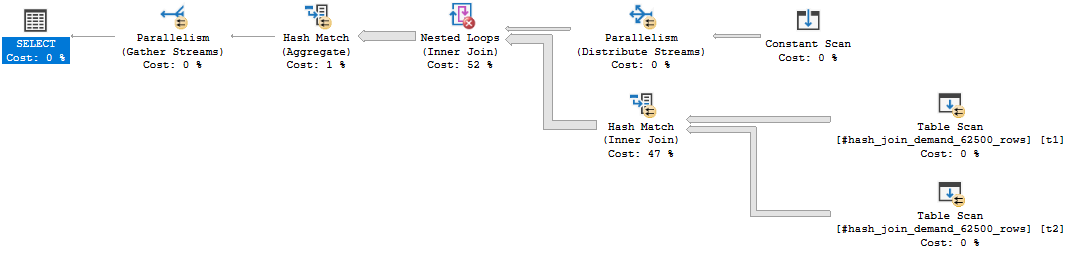
We can start by looking at the query plan for the default cursor:

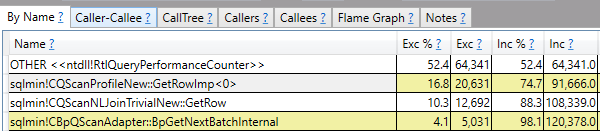
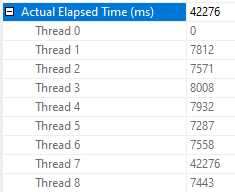
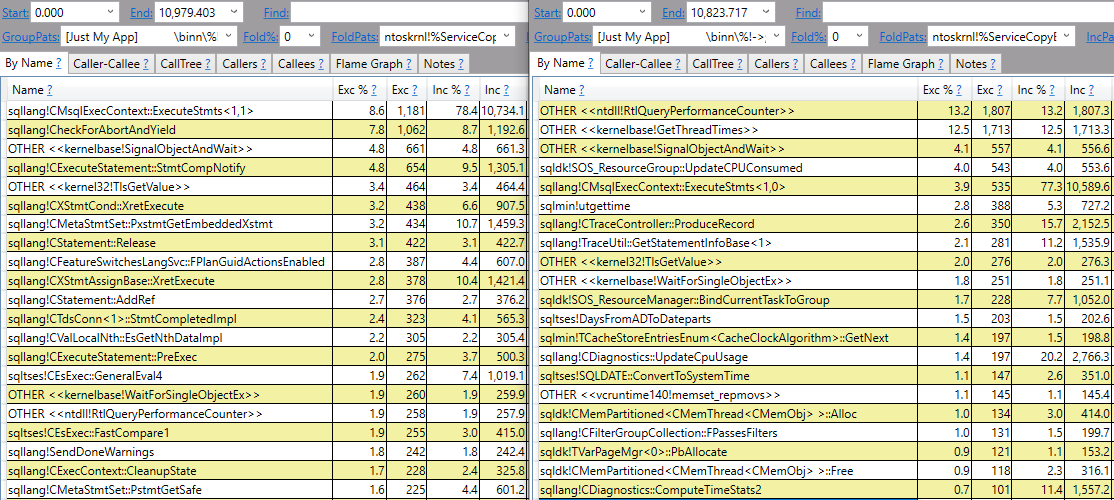
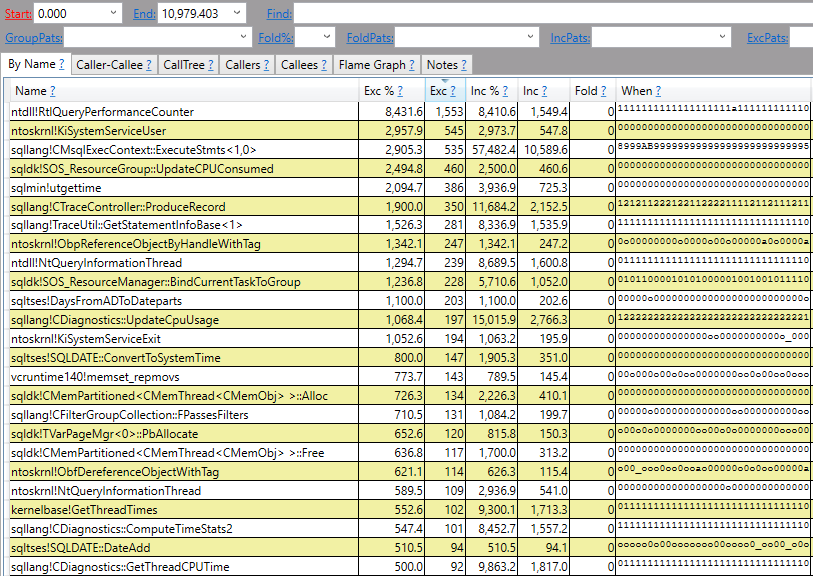
The query optimizer decided to do an ordered clustered index scan instead of using the IX2 index. We’re getting all rows from the cursor so we have to read through the whole table. That’s 20 scans with each scan covering about 5% of the table. We should definitely expect this to be less efficient than the FAST_FORWARD plan, but a 50 second execution time felt too slow based on what I know about my hardware. Looking at the wait stats:

It’s certainly not surprising that I/O is the biggest contributor to wait time (what else would it be?), but why do I have so much I/O wait time when I have fast, locally attached storage with an average latency less than 1 ms? For a comparison test, I decided to force the query plan that the cursor picks but to run it outside of the cursor. The following code finished in about 8 seconds on my machine:
CHECKPOINT; DBCC DROPCLEANBUFFERS; Select ID from tbl_1 WITH (INDEX(1)) WHERE ID2 < 1 ORDER BY ID OPTION (MAXDOP 1);
Using sys.dm_io_virtual_file_stats, I found that the cursor was doing about 240000 I/Os with an average I/O size of 66 KB. The single SELECT query did about 10000 I/Os with an average I/O size of 1.7 MB. The key difference is that only the first query execution of the cursor is able to get read-ahead reads:
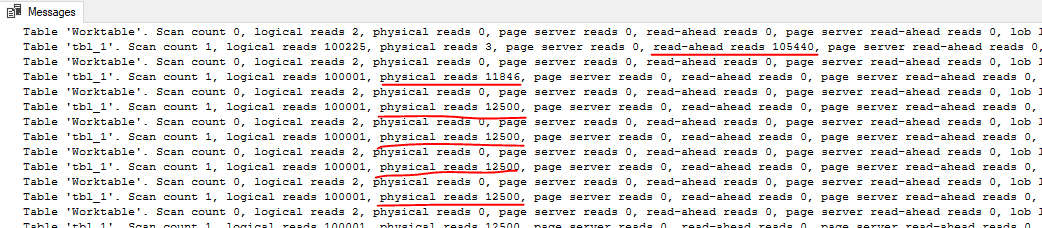
For the cursor execution, we don’t get read ahead reads for 95% of the I/O needed for the query. Even a sub-ms I/O latency can be painful when you have to do 240000 I/Os with a DOP 1 query. In summary, the FAST_FORWARD cursor is able to use an index to efficiently seek to the 20 matching rows. The cursor with default options does about 15 GB of I/O that’s not eligible for read-ahead reads.
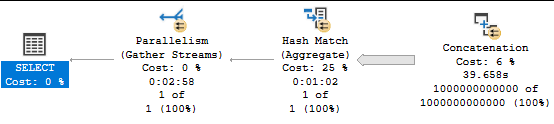
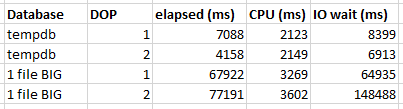
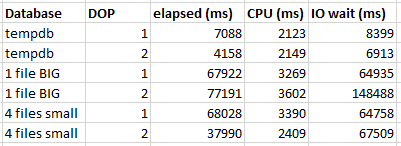
Of course, the situation should be expected to be much worse in the cloud. Using the quoted latency of 5-10 ms for general purpose Managed Instances, one might expect the cursor with default options to take between 20 and 40 minutes. Just for fun, I decided to test it against a 4 vCore Managed Instance. The cursor with the FAST_FORWARD option took about 120 ms. The cursor with default options took about 70 minutes. Here are the wait stats for the execution:

To put a positive spin on it: using the correct cursor options improved performance by 35000X on the Managed Instance.
The “Why”
I’ll start by saying that I don’t want to be a cursor expert. I’d much rather be an expert in not using cursors. I was having a lot of trouble explaining why the default cursor was getting such a bad query plan, but fortunately I was scooped 12 years ago. I’m going to reproduce the entire section on dynamic plans because you never know when a Microsoft hosted blog post will disappear:
A dynamic plan can be processed incrementally. In SQL Server we do this by serializing the state of the query execution into what we call a marker. Later, we can build a new query execution tree, use the marker to reposition each operator. Moreover, a dynamic plan can move forwards and backwards relative to its current position. Dynamic plans are used by both dynamic and some fast_forward cursors.
A dynamic plan consists only of dynamic operators — operators that support markers and moving forwards and backwards. This corresponds closely, but not exactly, to the query processing notion of streaming operators (vs. stop-and-go). But not every streaming operator is dynamic. In SQL Server, dynamic means:
1. The operator can be repositioned to its current position using a marker, or to a relative position (either next or previous) from its current one.
2. The operator’s state has to be small, so the marker can be small. No row data can be stored in the operator. In particular, no sort table, hash table, or work table. Not even one row can be stored, since a single row can be very large.
Without a dynamic plan, the cursor would need temporary storage to keep the query result set (or keyset thereof). A dynamic plan does no such thing! However, certain operators are disqualified — hash join, hash agg, compute sequence, and sort, for example. This leads to sub-optimal plans.
In short, you can consider a dynamic plan to be similar in concept to a plan with no blocking operators, but there are some additional restrictions. Reliable sources tell me that a cursor with default options will always pick a dynamic plan if one is available. For our SELECT query, a dynamic plan is indeed available. The ordering of the clustered index can be used to return sorted rows without doing an explicit sort. The IX2 index cannot be used for ordering because I’m filtering on ID2 with an inequality. Changing the query to do an equality filter instead allows for a dynamic plan that uses the IX2 index:
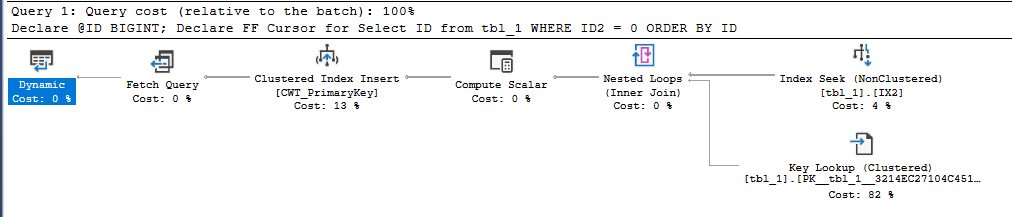
What about cursors without default options? Going back to the original query, specifying the STATIC or KEYSET option avoids the bad query plan and uses the IX2 index to do an index seek. Both of those options write the cursor result set to a table in tempdb, so it makes intuitive sense that there wouldn’t be some kind of restriction that forces a clustered index scan.
Specifying the FAST_FORWARD option allows the query optimizer to pick between a static and dynamic plan. In this case, the static plan is obviously much more efficient, and the query optimizer is aware of that. It picks the static plan that doesn’t do the clustered index scan.
For completeness, specifying the READ_ONLY option also results in the index seek, as long as the DYNAMIC option isn’t also specified.
In general, I would say that FAST_FORWARD is still a good starting point for your cursors as long as your application code allows for the restrictions that come with it. FAST_FORWARD alone isn’t always sufficient to get query performance that is similar to what you’d get with a standard SELECT. As Erik points out, you’ll end up with a MAXDOP 1 query with that option. The query optimizer may also choose a worse dynamic plan instead of a static plan if the estimated query plan costs don’t reflect reality. Using STATIC instead of FAST_FORWARD can be quite helpful in some cases, but you’ll have to test your cursor specifically to know for sure. Of course, you may be able to write your code without using a cursor instead.
Insufficient Permissions
As someone always on the lookout for cool demos, this bit of the documentation caught my eye:
If a DECLARE CURSOR using Transact-SQL syntax does not specify READ_ONLY, OPTIMISTIC, or SCROLL_LOCKS, the default is as follows:
If the SELECT statement does not support updates (insufficient permissions, accessing remote tables that do not support updates, and so on), the cursor is READ_ONLY.
Could I get better performance by running the code as a login with less privileges? Sadly, I couldn’t get this to work. I verified that the lowly ‘erik’ login couldn’t modify data in the table but I got the same query plan as before. There was also no change in the properties column from the sys.dm_exec_cursors DMF.
I don’t know if the documentation was wrong or if I was doing something wrong on my end. I’d be interested in seeing a working repro of this if anyone has one.
Final Thoughts
Some query patterns can experience extremely poor performance with the default cursor options. You may be able to identify these queries by sorting by total logical reads in the standard SSMS query store reports. In our production environment we had a few cursors that were doing far more logical reads than anything else on the database, so they were easy to pick out. We were able to significantly speed up some of those queries just by adding the FAST_FORWARD option.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.





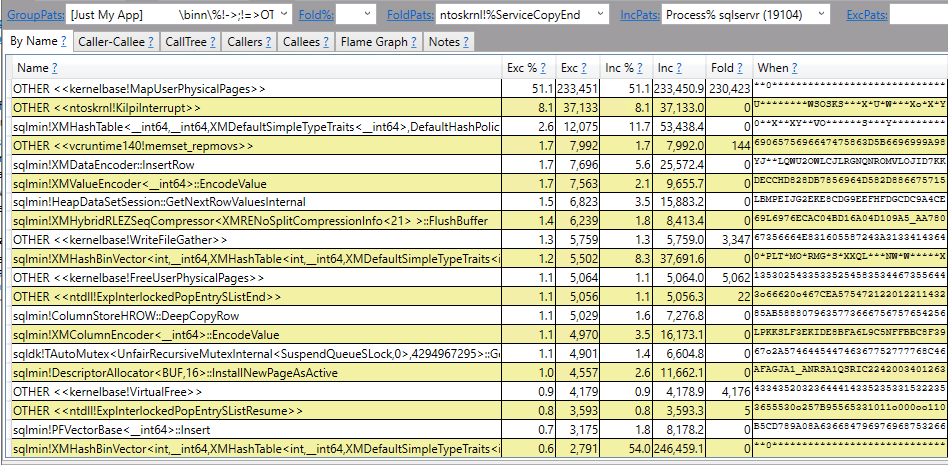
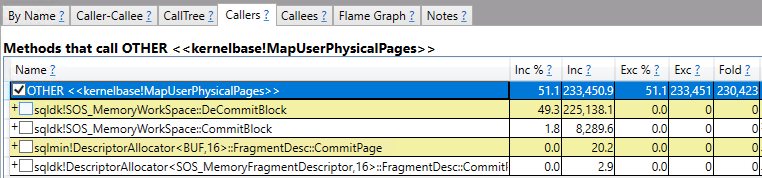
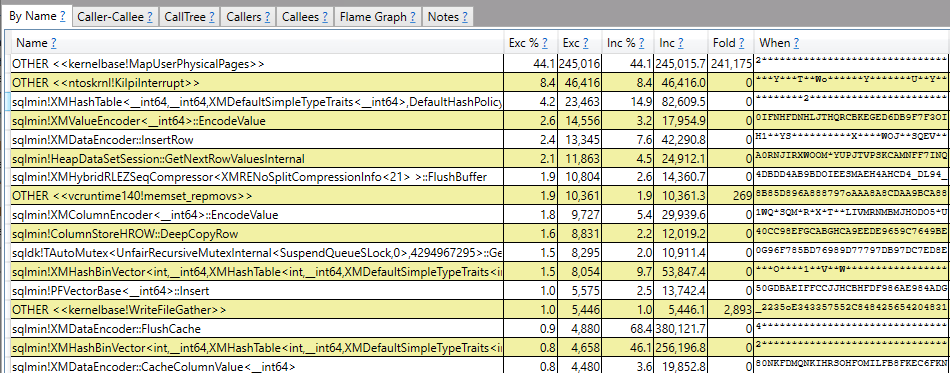
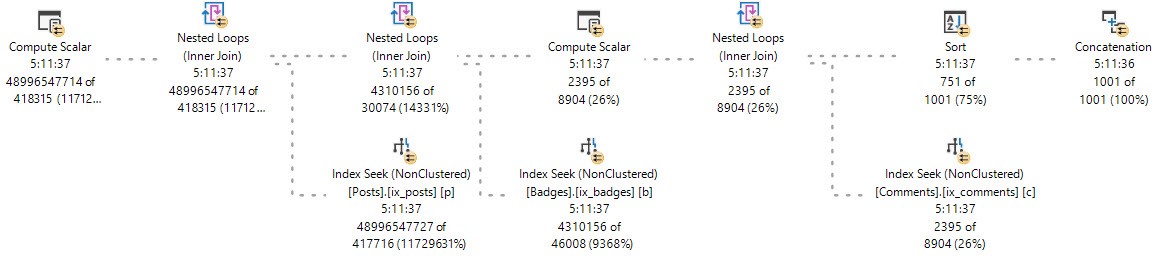 48 billion rows for a single operator is certainly a large number for most workloads. I ended up completely missing the point and started wondering how quickly a query could process a trillion rows through a single operator. Eventually that led to a SQL performance challenge: what is the fastest that you can get an actual plan with at least one operator processing a trillion rows? The following rules are in play:
48 billion rows for a single operator is certainly a large number for most workloads. I ended up completely missing the point and started wondering how quickly a query could process a trillion rows through a single operator. Eventually that led to a SQL performance challenge: what is the fastest that you can get an actual plan with at least one operator processing a trillion rows? The following rules are in play: