Deedoo
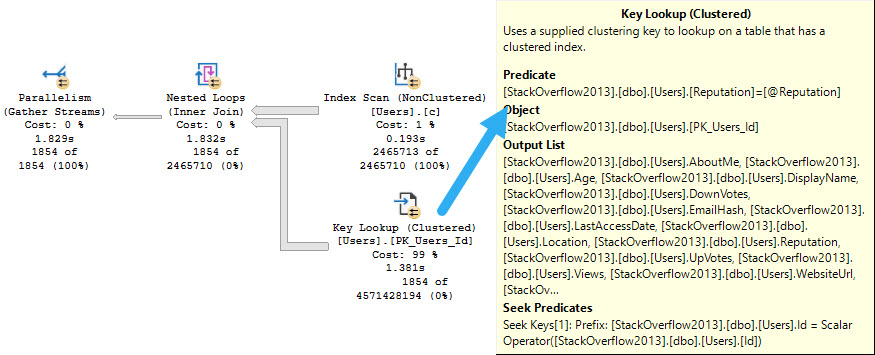
In yesterday’s post, we talked a little about different ways to approach looking at missing index requests, and how their benefit is calculated in sp_BlitzIndex.
If you’re on SQL Server 2019, you may be able to get some idea which queries are generating missing index requests. It’s not documented yet, but that’s never stopped anyone from using anything in production.
Let’s look at the queries asking for them.
Natural Ruckus
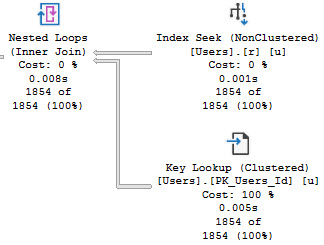
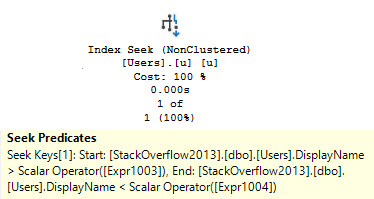
Let’s take a look at what queries are causing those missing index requests.
Since I’m running them, I don’t have to do any work.
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.CreationDate >= '20130101'
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.PostTypeId = 1
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.LastActivityDate >= '20130101'
ORDER BY p.Score DESC;
SELECT TOP (10)
p.*
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score > 0
ORDER BY p.Score DESC;
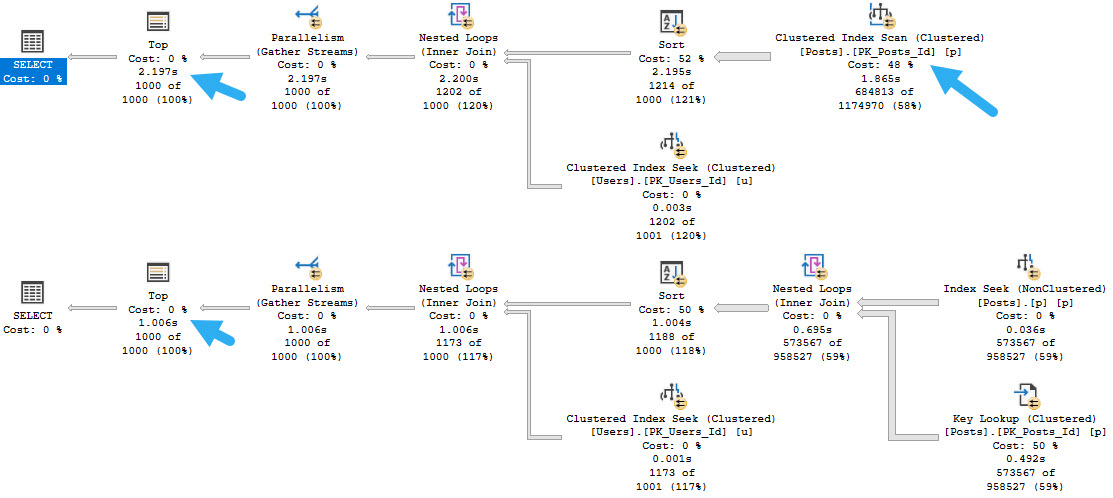
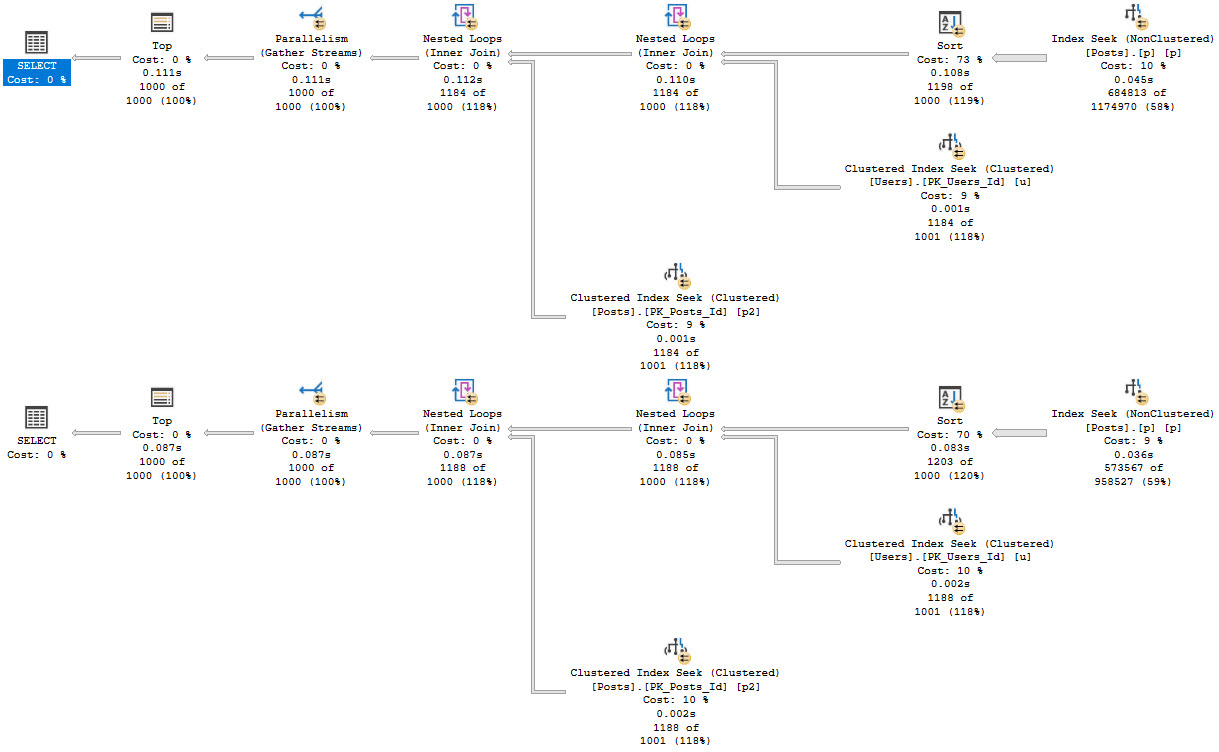
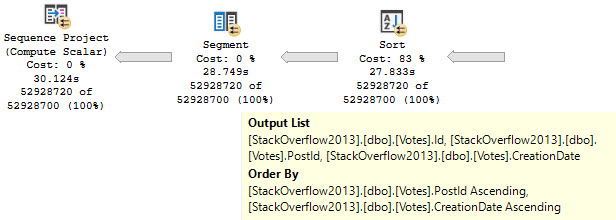
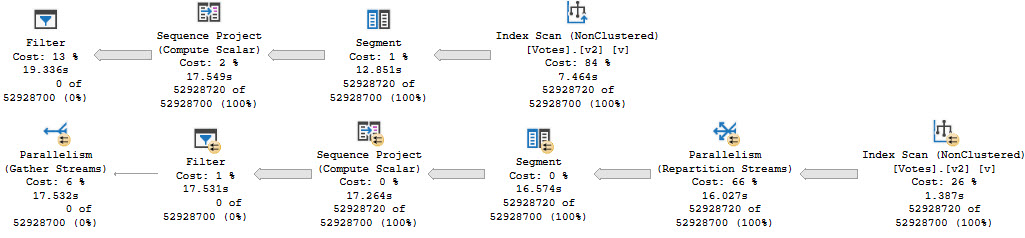
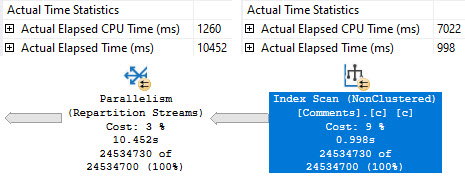
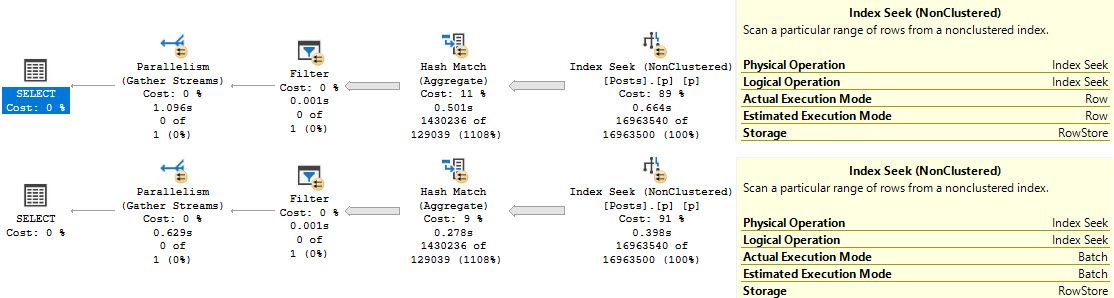
Without any helpful indexes, all of these take about the same amount of time — between 600 and 700ms, and most of the time is spent scanning the clustered index on Posts, which is around 17 million rows, just to return ~27k rows..
That’s Not “Slow”
Usually when people are complaining about slow queries, they’re talking about stuff that drags on for several seconds or longer.
At just about half a second, most people wouldn’t getting a running start to jump through hoops to make these faster.
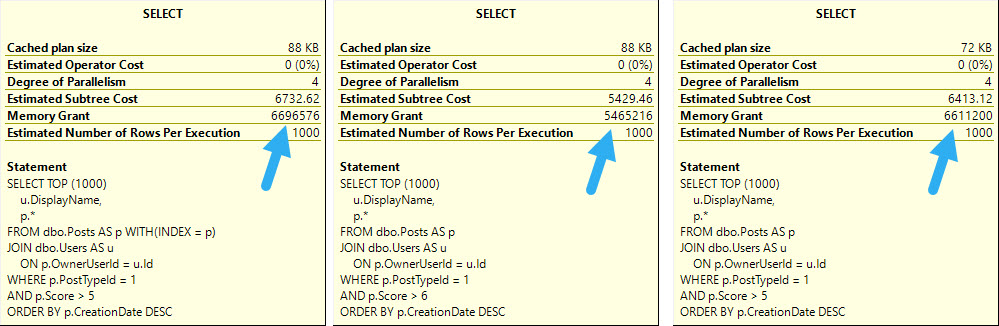
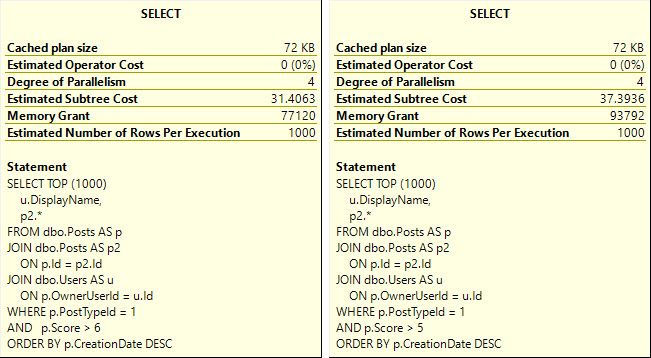
But they all have a “high cost” of a touch over 3000 query bucks. If you’re the type of person who only focuses on one metric, you might be overlooking a whole lot of things that need attention.

If we made this query 99% faster, it would mean a rather miniscule improvement in elapsed time. The flip side of the one-metric thing is using duration alone as a metric. Queries might have a very long duration because they’re blocked, but use minimal resource when they’re finally allowed to run by the gods of ACID compliance.
My favorite queries to find and tune are ones that:
- Unnecessarily run for a long time, using a lot of CPU
- Unnecessarily ask for large memory grants
- Have issues with parameter sniffing
Let’s pretend there might be some value to tuning these, though. Maybe we’re upset that they’re going parallel. Maybe we have something against scanning clustered indexes. Maybe we just don’t have anything else to do.
In tomorrow’s post, we’ll look at how to take all of those requests and come up with one good enough-index for our queries.
Just like how the optimizer comes up with one “good enough” plan for all queries.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.