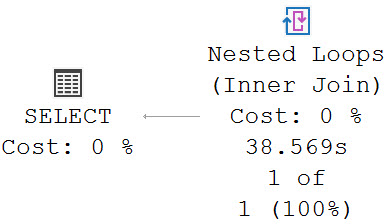If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
When writing queries, sometimes you have the pleasure of being able to pass a literal value, parameter, or scalar expression as a predicate.
With a suitable index in place, any one of them can seek appropriately to the row(s) you care about.
But what about when you need to compare the contents of one column to another?
It gets a little bit more complicated.
All About Algorithms
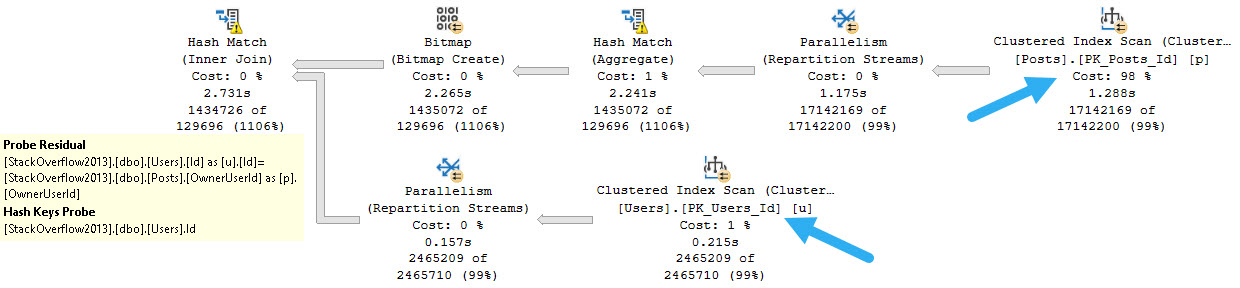
Take this query to start with, joining Users to Posts.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id;
The OwnerUserId column doesn’t have an index on it, but the Id column on Users it the primary key and the clustered index.
But the type of join that’s chosen is Hash, and since there’s no where clause, there’s no predicate to apply to either table for filtering.
jumbo
This is complicated slightly by the Bitmap, which is created on the OwnerUserId column from the Posts table and applied to the Id column from the Users table as an early filter.
The same pattern can generally be observed with Merge Joins. Where things are a bit different is with Nested Loops.
Shoop Da Loop
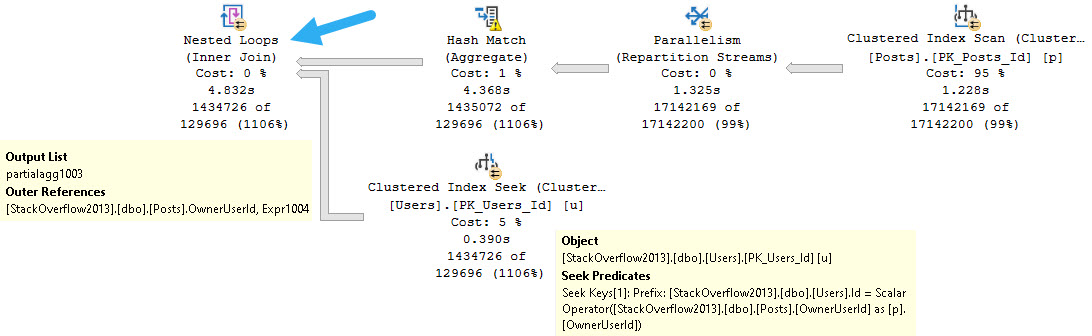
If we use a query hint, we can see what would happen with a Nested Loops Join.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
OPTION(LOOP JOIN);
The plan looks like this now, with a Seek on the Users table.
petting motions
The reason is that this flavor of Nested Loops, known as Apply Nested Loops, takes each row from the outer input and uses it as a scalar operator on the inner input.
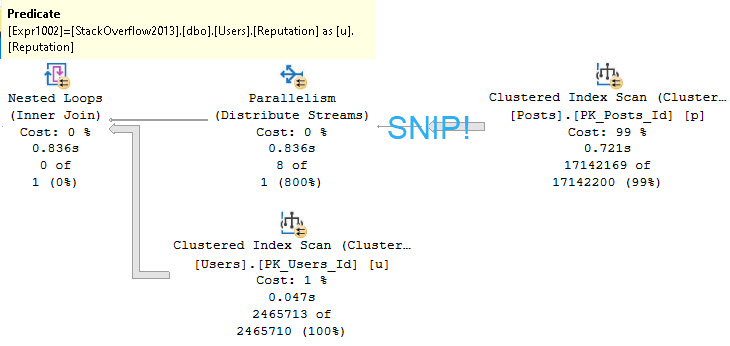
An example of Regular Joe Nested Loops™ looks like this:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.Reputation =
(
SELECT
MIN(p.Score)
FROM dbo.Posts AS p
);
Where the predicate is applied at the Nested Loops operator:
and bert
Like most things, indexing is key, but there are limits.
Innermost
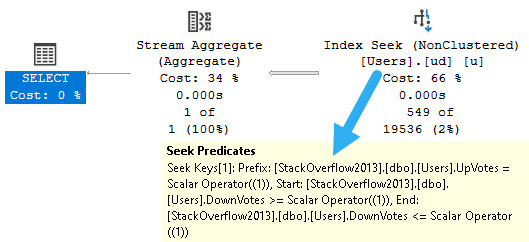
Let’s create this index:
CREATE INDEX ud ON dbo.Users(UpVotes, DownVotes);
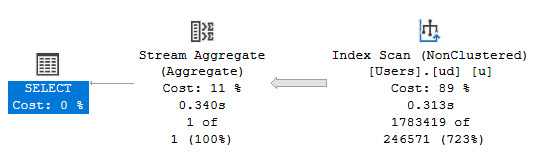
And run this query:
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.UpVotes = u.DownVotes;
The resulting query plan looks like this:
did a cuss
But what other choice is there? If we want a seek, we need a particular thing or things to seek to.
SELECT
c = COUNT_BIG(*)
FROM dbo.Users AS u
WHERE u.UpVotes = u.DownVotes
AND u.UpVotes = 1;
name game
We seek to everyone with an UpVote of 1, and then somewhat awkwardly search the DownVotes column for values >= 1 and <= 1.
But again, these are specific values we can search for.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
“Wow look at all these missing index requests. Where’d they come from?”
So this is neat! And it’s better than nothing, but there are some quirks.
And what’s a quirk, after all, but a twerk that no one enjoys.
Columnar
The first thing to note about this DMV is that there are two columns purporting to have sql_handles in them. No, not thatsql_handle.
One of them can’t be used in the traditional way to retrieve query text. If you try to use last_statement_sql_handle, you’ll get an error.
SELECT
ddmigsq.group_handle,
ddmigsq.query_hash,
ddmigsq.query_plan_hash,
ddmigsq.avg_total_user_cost,
ddmigsq.avg_user_impact,
query_text =
SUBSTRING
(
dest.text,
(ddmigsq.last_statement_start_offset / 2) + 1,
(
(
CASE ddmigsq.last_statement_end_offset
WHEN -1
THEN DATALENGTH(dest.text)
ELSE ddmigsq.last_statement_end_offset
END
- ddmigsq.last_statement_start_offset
) / 2
) + 1
)
FROM sys.dm_db_missing_index_group_stats_query AS ddmigsq
CROSS APPLY sys.dm_exec_sql_text(ddmigsq.last_statement_sql_handle) AS dest;
Msg 12413, Level 16, State 1, Line 27
Cannot process statement SQL handle. Try querying the sys.query_store_query_text view instead.
Is Vic There?
One other “issue” with the view is that entries are evicted from it if they’re evicted from the plan cache. That means that queries with recompile hints may never produce an entry in the table.
Is this the end of the world? No, and it’s not the only index-related DMV that behaves this way: dm_db_index_usage_stats does something similar with regard to cached plans.
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score < 0;
GO
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score < 0
OPTION(RECOMPILE);
GO
grizzly
Italic Stallion
You may have noticed that may was italicized in when talking about whether or not plans with recompile hints would end up in here.
Some of them may, if they’re part of a larger batch. Here’s an example:
SELECT
COUNT_BIG(*)
FROM dbo.Posts AS p
WHERE p.OwnerUserId = 22656
AND p.Score < 0
OPTION(RECOMPILE);
SELECT
COUNT_BIG(*)
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON p.OwnerUserId = u.Id
JOIN dbo.Comments AS c
ON c.PostId = p.Id
WHERE u.Reputation = 1
AND p.PostTypeId = 3
AND c.Score = 0;
Most curiously, if I run that batch twice, the missing index request for the recompile plan shows two uses.
computer
Multiplicity
You may have also noticed something odd in the above screenshot, too. One query has produced three entries. That’s because…
The query has three missing index requests. Go ahead and click on that.
lovecraft, baby
Another longstanding gripe with SSMS is that it only shows you the first missing index request in green text, and that it might not even be the “most impactful” one.
That’s the case here, just in case you were wondering. Neither the XML, nor the SSMS presentation of it, attempt to order the missing indexes by potential value.
You can use the properties of the execution plan to view all missing index requests, like I blogged about here, but you can’t script them out easily like you can for the green text request at the top of the query plan.
something else
At least this way, it’s a whole heck of a lot easier for you to order them in a way that may be more beneficial.
EZPZ
Of course, I don’t expect you to write your own queries to handle this. If you’re the type of person who enjoys Blitzing things, you can find the new 2019 goodness in sp_BlitzIndex, and you can find all the missing index requests for a single query in sp_BlitzCache in a handy-dandy clickable column that scripts out the create statements for you.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
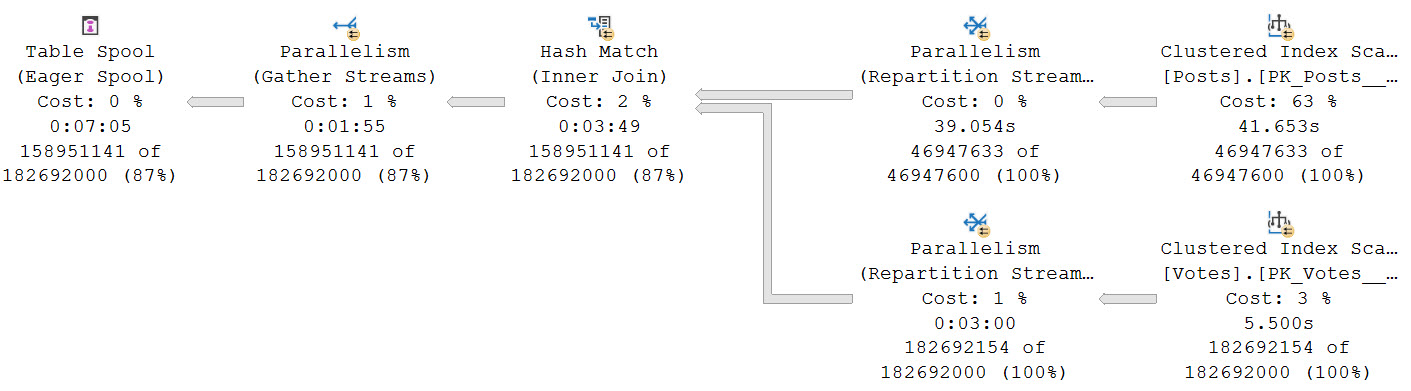
Using the scenario from yesterday’s post as an example of why you might want to think about rewriting queries with Table Spools in them to use temp tables instead, look how the optimizer chooses a plan with an Eager Table Spool.
The “Eager” part means the entire set of rows is loaded into a temporary object at once.
drugas
That’s a lot of rows, innit? Stick some commas in there, and you might just find yourself staring down the barrel of a nine digit number.
Worse, we spend a long time loading data into the spool, and doing so in a serial zone. There’s no good way to know exactly how long the load is because of odd operator times.
If you recall yesterday’s post, the plan never goes back to parallel after that, either. It runs for nearly 30 minutes in total.
Yes Your Tempdb
If you’re gonna be using that hunka chunka tempdb anyway, you might as well use it efficiently. Unless batch mode is an option for you, either as Batch Mode On Rowstore, or tricking the optimizer, this might be your best bet.
Keep in mind that Standard Edition users have an additional limitation where Batch Mode queries are limited to a DOP of 2, and don’t have access to Batch Mode On Rowstore as of this writing. The DOP limitation especially might make the trick unproductive compared to alternatives that allow for MOREDOP.
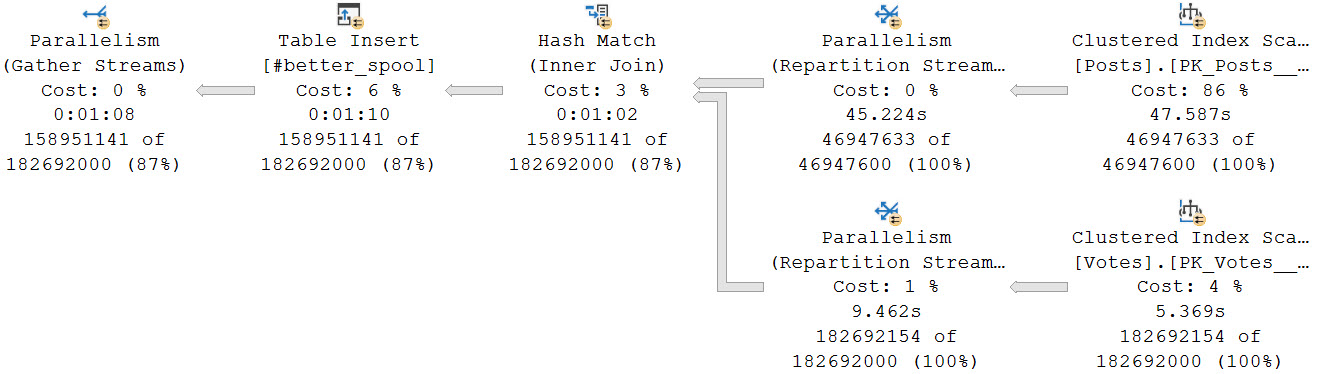
For example, if we dump that initial join into a temp table, it only takes about a minute to get loaded at a DOP of 8. That is faster than loading data into the spool (I mean, probably. Just look at that thing.).
sweet valley high
The final query to do the distinct aggregations takes about 34 seconds.
lellarap
Another benefit is that each branch that does a distinct aggregation is largely in a parallel zone until the global aggregate.
muggers
In total, both queries finish in about a 1:45. A big improvement from nearly 30 minutes relying on the Eager Table Spool and processing all of the distinct aggregates in a serial zone. The temp table here doesn’t have that particular shortcoming.
In the past, I’ve talked a lot about Eager Index Spools. They have a lot of problems too, many of which are worse. Of course, we need indexes to fix those, not temp tables.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
SELECT
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
INTO #better_spool
FROM dbo.Votes AS v
JOIN dbo.Posts AS p
ON p.Id = v.PostId;
SELECT
PostId = COUNT_BIG(DISTINCT s.PostId),
UserId = COUNT_BIG(DISTINCT s.UserId),
BountyAmount = COUNT_BIG(DISTINCT s.BountyAmount),
VoteTypeId = COUNT_BIG(DISTINCT s.VoteTypeId),
CreationDate = COUNT_BIG(DISTINCT s.CreationDate)
FROM #better_spool AS s;
Well over 500 years ago, Paul White wrote an article about distinct aggregates. Considering how often I see it while working with clients, and that Microsoft created column store indexes and batch mode rather than allow for hash join hints on CLR UDFs, the topic feels largely ignored.
But speaking of all that stuff, let’s look at how Batch Mode fixes multiple distinct aggregates.
Jumbo Size
A first consideration is around parallelism, since you don’t pay attention or click links, here’s a quote you won’t read from Paul’s article above:
Another limitation is that this spool does not support parallel scan for reading, so the optimizer is very unlikely to restart parallelism after the spool (or any of its replay streams).
In queries that operate on large data sets, the parallelism implications of the spool plan can be the most important cause of poor performance.
What does that mean for us? Let’s go look. For this demo, I’m using SQL Server 2019 with the compatibility level set to 140.
SELECT
COUNT_BIG(DISTINCT v.PostId) AS PostId,
COUNT_BIG(DISTINCT v.UserId) AS UserId,
COUNT_BIG(DISTINCT v.BountyAmount) AS BountyAmount,
COUNT_BIG(DISTINCT v.VoteTypeId) AS VoteTypeId,
COUNT_BIG(DISTINCT v.CreationDate) AS CreationDate
FROM dbo.Votes AS v;
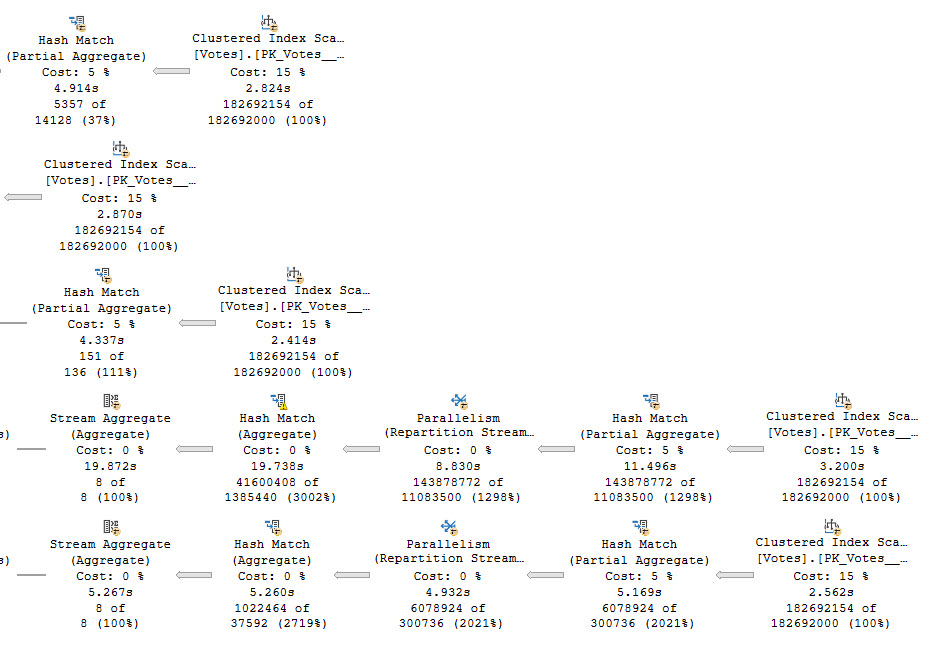
In the plan for this query, we scan the clustered index of the Votes table five times, or once per distinct aggregate.
skim scan
In case you’re wondering, this results in one intent shared object lock on the Votes table.
This query runs for 38.5 seconds, as the crow flies.
push the thing
A Join Appears
Let’s join Votes to Posts for no apparent reason.
SELECT
COUNT_BIG(DISTINCT v.PostId) AS PostId,
COUNT_BIG(DISTINCT v.UserId) AS UserId,
COUNT_BIG(DISTINCT v.BountyAmount) AS BountyAmount,
COUNT_BIG(DISTINCT v.VoteTypeId) AS VoteTypeId,
COUNT_BIG(DISTINCT v.CreationDate) AS CreationDate
FROM dbo.Votes AS v
JOIN dbo.Posts AS p
ON p.Id = v.PostId;
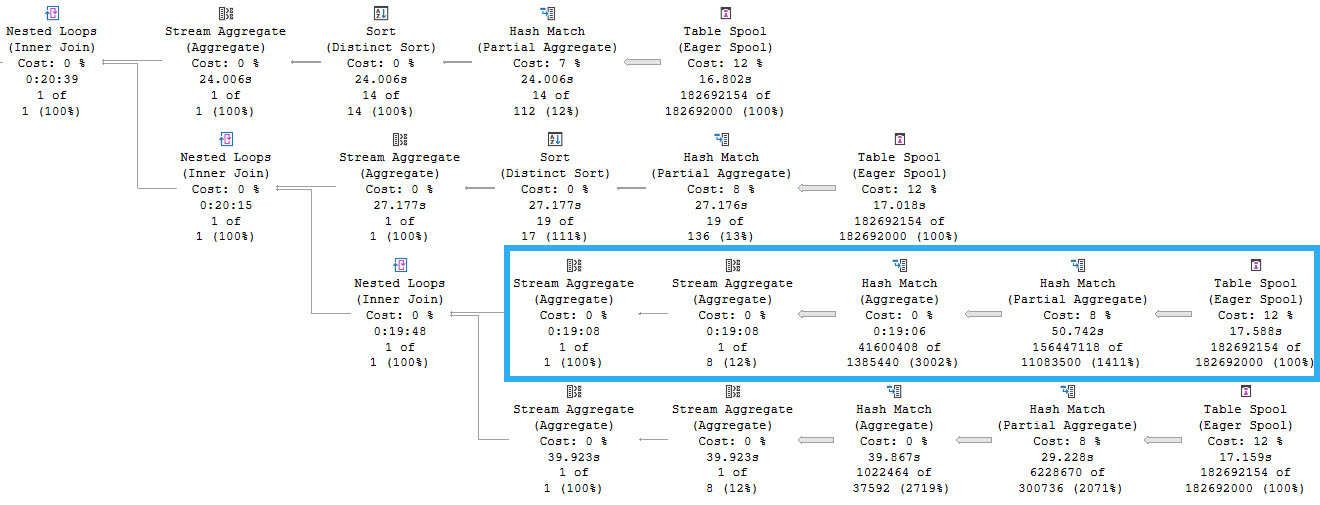
The query plan now has two very distinct (ho ho ho) parts.
problemium
This is part 1. Part 1 is a spoiler. Ignoring that Repartition Streams is bizarre and Spools are indefensible blights, as we meander across the execution plan we find ourselves at a stream aggregate whose child operators have executed for 8 minutes, and then a nested loops join whose child operators have run for 20 minutes and 39 seconds. Let’s go look at that part of the plan.
downstream
Each branch here represents reading from the same spool. We can tell this because the Spool operators do not have any child operators. They are starting points for the flow of data. One thing to note here is that there are four spools instead of five, and that’s because one of the five aggregates was processed in the first part of the query plan we looked at.
The highlighted branch is the one that accounts for the majority of the execution time, at 19 minutes, 8 seconds. This branch is responsible for aggregating the PostId column. Apparently a lack of distinct values is hard to process.
But why is this so much slower? The answer is parallelism, or a lack thereof. So, serialism. Remember the 500 year old quote from above?
Another limitation is that this spool does not support parallel scan for reading, so the optimizer is very unlikely to restart parallelism after the spool (or any of its replay streams).
In queries that operate on large data sets, the parallelism implications of the spool plan can be the most important cause of poor performance.
Processing that many rows on a single thread is painful across all of the operators.
Flounder Edition
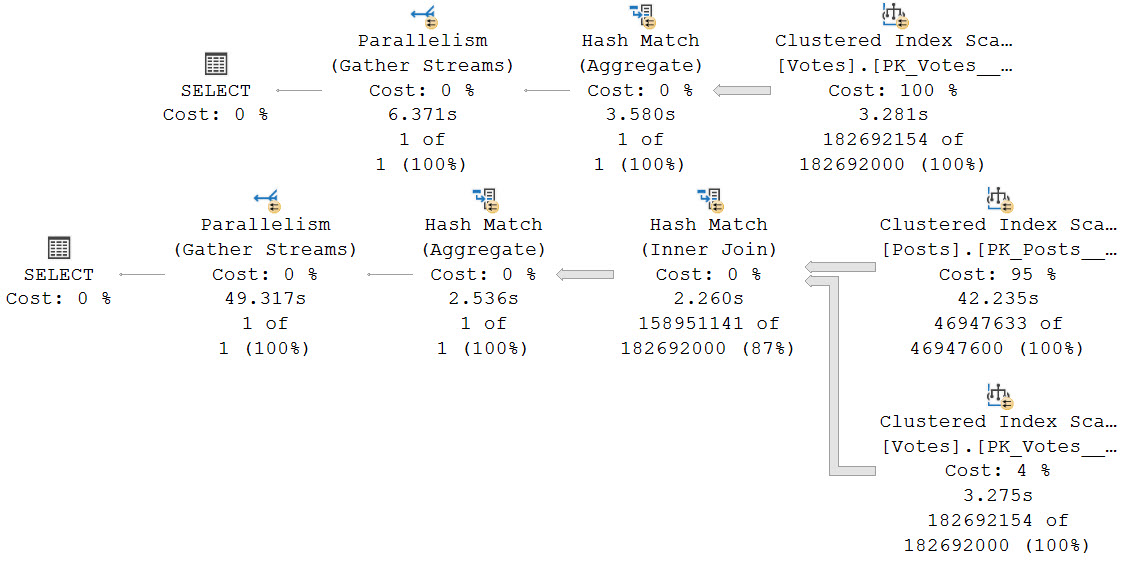
With SQL Server 2019, we get Batch Mode On Row store when compatibility level gets bumped up to 150.
The result is just swell.
yes you can
The second query with the join still runs for nearly a minute, but 42 seconds of the process is scanning that big ol’ Posts table.
Grumpy face.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
After my smash hit double diamond post about index tuning, I got a question questioning my assertion that compressed indexes are also compressed in the buffer pool.
Well, this should be quick. A quick question. Eighty hours later.
First, two indexes with no compression:
CREATE INDEX o
ON dbo.Posts
(OwnerUserId);
CREATE INDEX l
ON dbo.Posts
(LastEditorDisplayName);
Now let’s create a couple indexes with compression:
CREATE INDEX o
ON dbo.Posts
(OwnerUserId)
WITH(DATA_COMPRESSION = ROW);
CREATE INDEX l
ON dbo.Posts
(LastEditorDisplayName)
WITH(DATA_COMPRESSION = PAGE);
I’m choosing compression based on what I think would be sensible for the datatypes involved.
For the integer column, I’m using row compression, and for the string column I’m using page compression.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You need to design indexes so that you can support your queries by making it easy for them to locate data. That’s your where clause, and guess what?
Your modification queries have where clauses, too.
How You Can Make Indexing Better
Make sure you’re reviewing your indexes regularly. Things that you need to keep an eye on:
Duplicative indexes
Under-utilized indexes
Even when indexes are defined on the same columns, they’re separate sets of pages within your data files.
If you have indexes that are on very similar sets of columns, or supersets/subsets of columns, it’s probably time to start merging them
If you have indexes that just aren’t being read, or aren’t being read anywhere near as much as they’re written to, you should think about ditching them
Cleaning up indexes like this gives you more breathing room to add in other indexes later.
It also gives you far fewer objects competing for space in memory.
That means the ones you have left stand a better chance of staying there, and your queries not having to go to disk for them.
How You Can Make Indexes Better
There are all sorts of things you can do to make indexes better, too. I don’t mean rebuilding them, either!
I mean getting smarter about what you’re indexing.
Things like filtered indexes and index compression can net you big wins when it comes to reducing the overall size of indexes.
My friend Andy Mallon has some Great Posts™ about compression over on his blog:
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It’s likely also obvious that your join clauses should also be SARGable. Doing something like this is surely just covering up for some daft data quality issues.
SELECT
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON ISNULL(p.OwnerUserId, 0) = u.Id;
If 0 has any real meaning here, replace the NULLs with zeroes already. Doing it at runtime is a chore for everyone.
But other things can be thought of as “SARGable” too. But perhaps we need a better word for it.
I don’t have one, but let’s define it as the ability for a query to take advantage of index ordering.
World War Three
There are no Search ARGuments here. There’s no argument at all.
But we can plainly see queries invoking functions on columns going all off the rails.
Here’s an index. Please enjoy.
CREATE INDEX c ON dbo.Comments(Score);
Now, let’s write a query. Once well, once poorly. Second verse, same as the first.
SELECT TOP(1)
c.*
FROM dbo.Comments AS c
ORDER BY
c.Score DESC;
SELECT TOP(1)
c.*
FROM dbo.Comments AS c
ORDER BY
ISNULL(c.Score, 0) DESC;
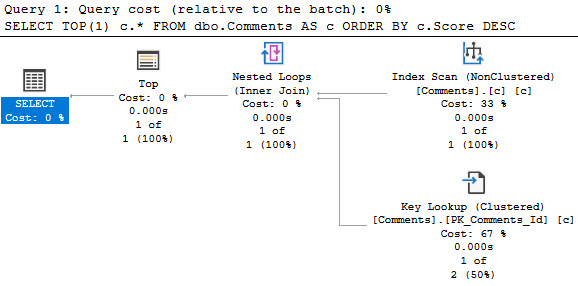
The plan for the first one! Yay!
inky
Look at those goose eggs. Goose Gossage. Nolan Ryan.
The plan for the second one is far less successful.
trashy vampire
We’ve done our query a great disservice.
Not Okay
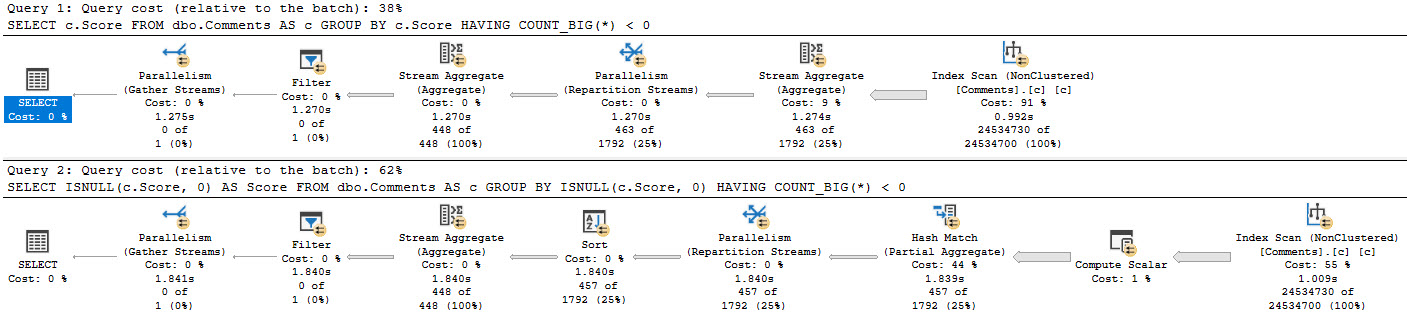
Grouping queries, depending on scope, can also suffer from this. This example isn’t as drastic, but it’s a simple query that still exhibits as decent comparative difference.
SELECT
c.Score
FROM dbo.Comments AS c
GROUP BY
c.Score
HAVING
COUNT_BIG(*) < 0;
SELECT
ISNULL(c.Score, 0) AS Score
FROM dbo.Comments AS c
GROUP BY
ISNULL(c.Score, 0)
HAVING
COUNT_BIG(*) < 0;
To get you back to drinking, here’s both plans.
the opposite of fur
We have, once again, created more work for ourselves. Purely out of vanity.
Indexable
Put yourself in SQL Server’s place here. Maybe the optimizer, maybe the storage engine. Whatever.
If you had to do this work, how would you prefer to do it? Even though I think ISNULL should have better support, it applies to every other function too.
Would you rather:
Process data in the order an index presents it and group/order it
Process data by applying some additional calculation to it and then grouping/ordering
That’s what I thought.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.