If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Demoman!
USE StackOverflow2010;
SET NOCOUNT ON;
GO
/*
--Basic index info
SELECT *
FROM dbo.WhatsUpIndexes AS wui
WHERE wui.table_name = 'Users'
OPTION ( RECOMPILE );
GO
--What's in the buffer pool?
SELECT *
FROM dbo.WhatsUpMemory AS wum
WHERE wum.object_name = 'Users'
OPTION ( RECOMPILE );
GO
*/
--CREATE INDEX ix_whatever ON dbo.Users (Reputation);
GO
SELECT *
FROM dbo.WhatsUpIndexes AS wui
WHERE wui.table_name = 'Users'
OPTION ( RECOMPILE );
GO
DBCC DROPCLEANBUFFERS;
CHECKPOINT;
DBCC FREEPROCCACHE;
CHECKPOINT;
GO 5
SELECT *
FROM dbo.WhatsUpMemory AS wum
WHERE wum.object_name = 'Users'
OPTION ( RECOMPILE );
GO
SET STATISTICS TIME, IO, XML ON;
SET NOCOUNT OFF;
--/*Select a count of everything*/
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE 1 = (SELECT 1);
--/*Select a count of one user*/
-- SELECT COUNT(*) AS records
-- FROM dbo.Users AS u
-- WHERE u.Id = 22656
--AND 1 = (SELECT 1);
--/*Select a count of rep > 100k*/
--SELECT COUNT(*) AS records
--FROM dbo.Users AS u
--WHERE u.Reputation >= 100000
--AND 1 = (SELECT 1);
SET NOCOUNT ON;
SET STATISTICS TIME, IO, XML OFF;
SELECT *
FROM dbo.WhatsUpMemory AS wum
WHERE wum.object_name = 'Users'
OPTION ( RECOMPILE );
GO
If you’re stepping up to a SQL Server you’ve never seen before, you’re probably only armed with what people tell you the problem is.
Sometimes they’re right, more often they’re wrong. Even more often they’re just too vague, and it falls back to you to figure out exactly what’s “slow”.
As you start digging in, you’ll start noticing things you want to change, and building a mental case for why you want to change them:
Maybe the CX waits will be really high, and no one has changed MAXDOP and CTFP from defaults
Maybe there’s a lot of locking waits, and there’s a lot of overlapping indexes or you want to use RCSI
Maybe there’s a lot of PAGEIOLATCH waits and there’s not many nonclustered indexes or you don’t have enough RAM
Those are good general patterns to watch out for, and while there may be regressions in some places, you’re likely to make the server a better place overall.
Sometimes you’ll get handed a query to tune.
Or more realistically, you get handed a few-thousand line stored procedure to tune. It probably calls other stored procedures, too.
Your job, one way or another, is to reduce the length of time between hitting F5 and having it complete.
For different sets of parameters.
Things That Change
In a perfect world, you’d change one variable (this could be a setting, and index, the way a query is written, or an actual variable being passed in), and see how the metrics you care about change.
But that hardly ever happens, does it?
You’ll probably:
Change a few settings you’re confident about
Deduplicate a bunch of indexes for a table at a time
Adjust a bunch of things in a stored procedure as you scroll through
Fix some Heaps all together
Look, it’s okay. You might need to be really effective and make a lot of progress quickly. Not everyone has weeks or months to make incremental changes towards better performance.
But you need to be aware of which metrics you’re hoping to improve when you make a change, and you need to be sure that the changes you make can actually make it wiggle.
For a query, it’s likely just a mix of elapsed time, CPU time, and memory grants. In a way, that’s a lot easier.
For a whole server, you need to understand the problems, and how SQL Server surfaces them.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are plenty of spools in query plans, and they’re all pretty well labeled.
Index
Table
Rowcount
Window
They can be either eager or lazy.
An eager spool will take all the rows at once and cache them, and a lazy spool will only go get rows as needed.
But what else can act like a spool?
Phases On
In general, a blocking operator, or as my upside down friend Paul calls them, “phase separators” can act as a spool.
A spool, after all, is just something that keeps track of some rows, which is exactly what a Sort or a Hash do.
They keep track of rows that arrive, and either sort them according to a need, or create a hash table of the value.
While either of these happen, any downstream work in the query have to wait for them to complete. This is why they’re called blocking, stop and go, or, more eloquently, phase separators.
Eager spools have the same basic feature: wait for all the rows from downstream to arrive, and perform an action (or just feed them to another operator).
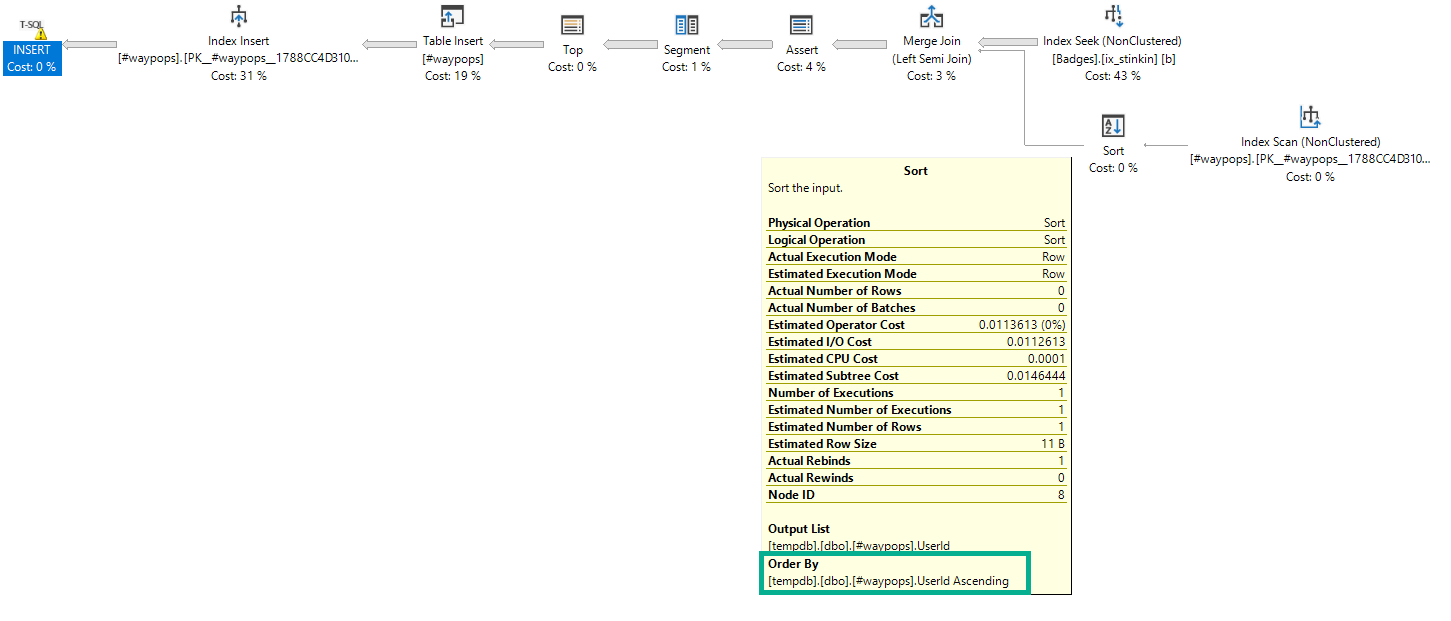
Here’s an example of a Sort acting as a spool:
DROP TABLE IF EXISTS #waypops;
CREATE TABLE #waypops
(
UserId INT
, PRIMARY KEY NONCLUSTERED (UserId) WITH (IGNORE_DUP_KEY = ON)
);
INSERT #waypops WITH(TABLOCKX)
( UserId)
SELECT b.UserId
FROM dbo.Badges AS b
WHERE b.Name = N'Popular Question';
Enjoy the silence
The Sort is in the same order as the index it’s reading from, but just reading from the index wouldn’t provide any separation.
Just Passing By
This is weird, niche stuff. That’s why I’m posting it on a Friday. That, and I wanna bully someone into writing about using a hash join to do the same thing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sometimes, the optimizer can take a query with a complex where clause, and turn it into two queries.
This only happens up to a certain point in complexity, and only if you have really specific indexes to allow these kinds of plan choices.
Here’s a haphazard query:
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 1
AND p.AcceptedAnswerId <> 0
AND p.CommentCount > 5
AND p.CommunityOwnedDate IS NULL
AND p.FavoriteCount > 0
)
OR (
p.PostTypeId = 2
AND p.CommentCount > 1
AND p.LastEditDate IS NULL
AND p.Score > 5
AND p.ParentId = 0
)
AND (p.ClosedDate IS NULL);
There’s a [bunch of predicates], an OR, then a [bunch of predicates]. Since there’s some shared spaced, we can create an okay general index.
It’s pretty wide, and it may not be the kind of index I’d normally create, unless I really had to.
CREATE INDEX whatever
ON dbo.Posts (PostTypeId, CommentCount, ParentId)
INCLUDE(AcceptedAnswerId, FavoriteCount, LastEditDate, Score, ClosedDate, CommunityOwnedDate);
It covers every column we’re using. It’s a lot. But I had to do it to show you this.
Computer Love
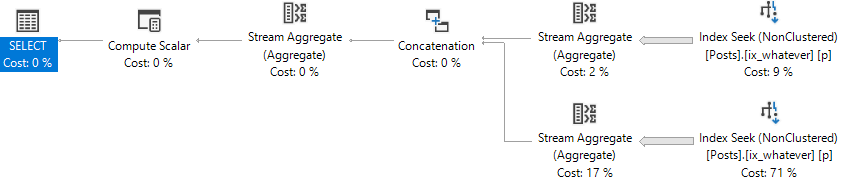
The optimizer took each separate group of predicates, and turned it into a separate index access, with a union operator.
It’s like if you wrote two count queries, and then counted the results of both.
But With A Twist
Let’s tweak the where clause a little bit.
SELECT COUNT(*) AS records
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 1
AND p.AcceptedAnswerId <> 0
AND p.CommentCount > 5
OR p.CommunityOwnedDate IS NULL --This is an OR now
AND p.FavoriteCount > 0
)
OR (
p.PostTypeId = 2
AND p.CommentCount > 1
AND p.LastEditDate IS NULL
OR p.Score > 5 -- This is an OR now
AND p.ParentId = 0
)
AND (p.ClosedDate IS NULL)
Wham!
We don’t get the two seeks anymore. We get one big scan.
Is One Better?
The two seek plan has this profile:
Table 'Posts'. Scan count 10, logical reads 30678
Table 'Worktable'. Scan count 0, logical reads 0
Table 'Workfile'. Scan count 0, logical reads 0
SQL Server Execution Times:
CPU time = 439 ms, elapsed time = 108 ms.
Here’s the scan plan profile:
Table 'Posts'. Scan count 5, logical reads 127472
SQL Server Execution Times:
CPU time = 4624 ms, elapsed time = 1617 ms.
In this case, the index union optimization works in our favor.
We can push the optimizer towards a plan like that by breaking up complicated where clauses.
SELECT COUNT(*)
FROM (
SELECT 1 AS x
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 1
AND p.AcceptedAnswerId <> 0
AND p.CommentCount > 5
AND p.CommunityOwnedDate IS NULL
AND p.FavoriteCount > 0
)
UNION ALL
SELECT 1 AS x
FROM dbo.Posts AS p
WHERE (
p.PostTypeId = 2
AND p.CommentCount > 1
AND p.LastEditDate IS NULL
AND p.Score > 5
AND p.ParentId = 0
)
AND (p.ClosedDate IS NULL)
) AS x
Et voila!
Chicken Leg
Which has this profile:
Table 'Posts'. Scan count 2, logical reads 30001
SQL Server Execution Times:
CPU time = 329 ms, elapsed time = 329 ms.
Beat My Guest
The optimizer is full of all sorts of cool tricks.
The better your indexes are, and the more clearly you write your queries, the more of those tricks you might see it start using
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
One is the loneliest number. Sometimes it’s also the hardest number of rows to get, depending on how you do it.
In this video, I’ll show you how a TOP 1 query can perform much differently from a query where you generate row numbers and look for the first one.
Thanks for watching!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Because you’ve got the cash money to pay for Enterprise Edition, some nice hardware, and also Enterprise Edition on another server or two.
Maybe you have queries that need fresh data going to a sync replica, and queries that can withstand slightly older data going to an async replica.
Every week or every month, you want to be a dutiful data steward and see how your indexes get used. Or not used.
So you run Your Favorite Index Analysis Script® on the primary, and it looks like you’ve got a bunch of unused indexes.
Can you drop them?
Not By A Long Shot
You’ve still gotta look at how indexes are used on any readable copy. Yes, you read that right.
DMV data is not sent back and centralized on the primary. Not for indexes, wait stats, queries, file stats, or anything else you might care about.
If you wanna centralize that, it’s up to you (or your monitoring tool) to do it. That can make getting good feedback about your indexes tough.
Failovers Also Hurt
Once that happens, your DMV data is all murky.
Things have gotten all mixed in together, and there’s no way for you to know who did what and when.
AGs, especially readable ones, mean you need to take more into consideration when you’re tuning.
You also have to be especially conscious about who the primary is, and how long they’ve been the primary.
If you patch regularly (and you should be patching regularly), that data will get wiped out by reboots.
Now what?
If you use SQL Server’s DMVs for index tuning (and really, why wouldn’t you?), you need to take other copies of the data into account.
This isn’t just for AGs, either. You can offload reads to a log shipped secondary or a mirroring partner, too.
Perhaps in the future, these’ll be centralized for us, but for now that’s more work for you to do.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If you saw my post about parameterized TOPs, one thing you may have immediately hated is the index I created.
And rightfully so — it was a terrible index for reasons we’ll discuss in this post.
If that index made you mad, congratulations, you’re a smart cookie.
CREATE INDEX whatever ON dbo.Votes(CreationDate DESC, VoteTypeId)
GO
Yes, my friends, this index is wrong.
It’s not just wrong because we’ve got the column we’re filtering on second, but because there’s no reason for it to be second.
Nothing in our query lends itself to this particular indexing scenrio.
CREATE OR ALTER PROCEDURE dbo.top_sniffer (@top INT, @vtid INT)
AS
BEGIN
SELECT TOP (@top)
v.Id,
v.PostId,
v.UserId,
v.BountyAmount,
v.VoteTypeId,
v.CreationDate
FROM dbo.Votes AS v
WHERE v.VoteTypeId = @vtid
ORDER BY v.CreationDate DESC;
END;
We Index Pretty
The reason I sometimes see columns appear first in an index is to avoid having to physically sort data.
If I run the stored procedure without any nonclustered indexes, this is our query plan:
EXEC dbo.top_sniffer @top = 1, @vtid = 1;
spillo
A sort, a spill, kablooey. We’re not having any fun, here.
With the original index, our data is organized in the order that we’re asking for it to be returned in the ORDER BY.
This caused all sorts of issues when we were looking for VoteTypeIds that were spread throughout the index, where we couldn’t satisfy the TOP quickly.
There was no Sort in the plan when we had the “wrong” index added.
Primal
B-Tree Equality
We can also avoid having to sort data by having the ORDER BY column(s) second in the key of the index, because our filter is an equality.
CREATE INDEX whatever ON dbo.Votes(VoteTypeId, CreationDate DESC)
GO
Having the filter column first also helps us avoid the longer running query issue when we look for VoteTypeId 4.
EXEC dbo.top_sniffer @top = 5000, @vtid = 4;
I like you better.
Table 'Votes'. Scan count 1, logical reads 2262
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 148 ms.
Solving for Sorts
If you’ve been following my blogging for a while, you’ve likely seen me say this stuff before, because Sorts have some issues.
They’re locally blocking, in that every row has to arrive before they can run
They require additional memory space to order data the way you want
They may spill to disk if they don’t get enough memory
They may ask for quite a bit of extra memory if estimations are incorrect
They may end up in a query plan even when you don’t explicitly ask for them
There are plenty of times when these things aren’t problems, but it’s good to know when they are, or when they might turn into a problem.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A while back I promised I’d write about what allows SQL Server to perform two seeks rather than a seek with a residual predicate.
More recently, a post touched a bit on predicate selectivity in index design, and how missing index requests don’t factor that in when requesting indexes.
This post should tie the two together a bit. Maybe. Hopefully. We’ll see where it goes, eh?
If you want a TL;DR, it’s that neighboring index key columns support seeks quite easily, and that choosing the leading column should likely be a reflection of which is filtered on most frequently.
CREATE NONCLUSTERED INDEX whatever
ON dbo.Posts ( PostTypeId, ClosedDate );
CREATE NONCLUSTERED INDEX apathy
ON dbo.Posts ( ClosedDate, PostTypeId );
Now let’s run two identical queries, and have each one hit one of those indexes.
SELECT p.Id, p.PostTypeId, p.ClosedDate
FROM dbo.Posts AS p WITH (INDEX = whatever)
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01';
SELECT p.Id, p.PostTypeId, p.ClosedDate
FROM dbo.Posts AS p WITH (INDEX = apathy)
WHERE p.PostTypeId = 1
AND p.ClosedDate >= '2018-06-01';
If you run them a bunch of times, the first query tends to end up around ~50ms ahead of the second, though they both sport nearly identical query plans.
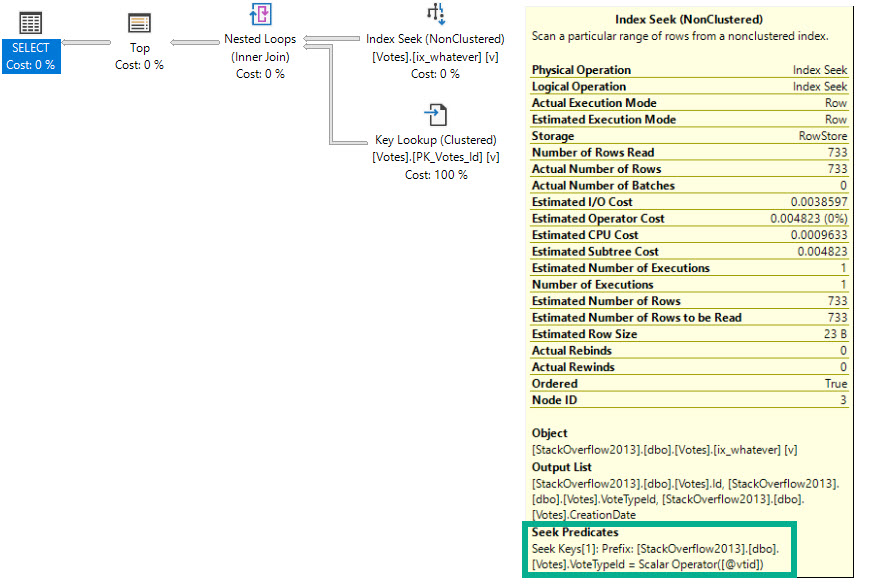
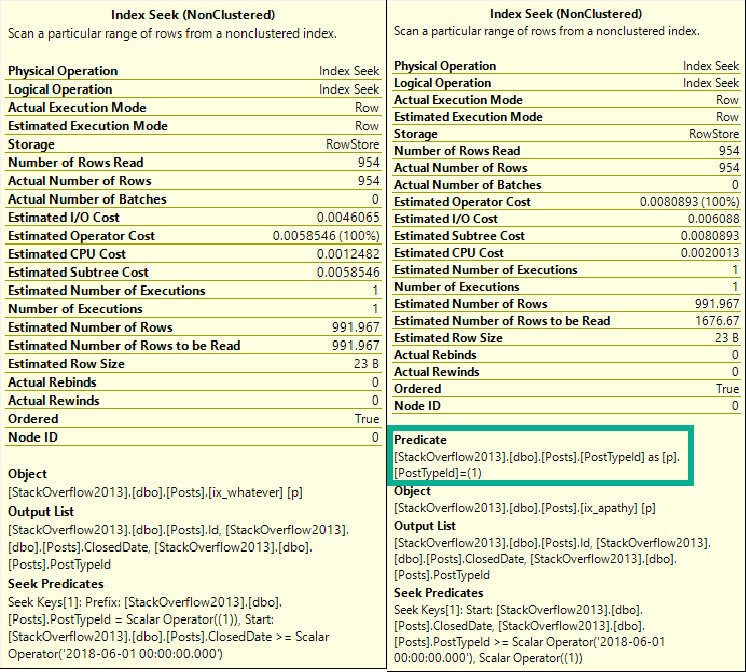
The seek may look confusing, because PostTypeId seems to appear as both a seek and a residual predicate. That’s because it’s sort of both.
The seek tells us where we start reading, which means we’ll find rows starting with ClosedDate 2018-06-01, and with PostTypeId 1.
From there, we may find higher PostTypeIds, which is why we have a residual predicate; to filter those out.
More generally, a seek can find a single row, or a range of rows as long as they’re all together. When the leading column of an index is used to find a range, we can seek to a starting point, but we need a residual predicate to check for other predicates afterwards.
This is why the index rule of thumb for many people is to start indexes with equality predicates. Any rows located will be contiguous, and we can easily continue the seek while applying any other predicates.
Seeky Scanny
There’s also differences in stats time and IO.
Table 'Posts'. Scan count 1, logical reads 8, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 156 ms.
Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 106 ms.
Remember that this is how things break down for each predicate:
Lotsa and Nunna
But in neither case do we need to touch all ~6mm rows of PostTypeId 1 to locate the correct range of ClosedDates.
Downstairs Mixup
When does that change?
When we design indexes a little bit more differenter.
CREATE NONCLUSTERED INDEX ennui
ON dbo.Posts ( PostTypeId ) INCLUDE (ClosedDate);
CREATE NONCLUSTERED INDEX morose
ON dbo.Posts ( ClosedDate ) INCLUDE (PostTypeId);
Running the exact same queries, something changes quite drastically for the first one.
Table 'Posts'. Scan count 1, logical reads 16344, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 297 ms, elapsed time = 301 ms.
Table 'Posts'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 187 ms.
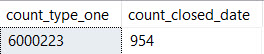
This time, the residual predicate hurts us, when we look for a range of values.
Yaw yaw yaw
We do quite a lot of extra reads — in fact, this time we do need to touch all ~6mm rows of PostTypeId 1.
Off By One
Something similar happens if we only rearrange key columns, too.
CREATE NONCLUSTERED INDEX ennui
ON dbo.Posts ( PostTypeId, OwnerUserId, ClosedDate ) WITH ( DROP_EXISTING = ON );
CREATE NONCLUSTERED INDEX morose
ON dbo.Posts ( ClosedDate, OwnerUserId, PostTypeId ) WITH ( DROP_EXISTING = ON );
I have both columns I’m querying in the key of the index this time, but I’ve stuck a column I’m not querying at all between them — OwnerUserId.
This also throws off the range predicate. We read ~30k more pages here because the index is larger.
Table 'Posts'. Scan count 1, logical reads 19375, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 312 ms, elapsed time = 314 ms.
Table 'Posts'. Scan count 1, logical reads 7, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 178 ms.
The Seeks here look identical to the ones when I had columns in the include section of the index.
What’s It All Mean?
Index column placement, whether it’s in the key or in the includes, can have a non-subtle impact on reads, especially when we’re searching for ranges.
Even when we have a non-selective leading column like PostTypeId with an equality predicate on it, we don’t need to read every single row that meets the filter to apply a range predicate, as long as that predicate is seek-able.
When we move the range column to the includes, or we add a column before it in the key, we end up doing a lot more work to locate rows.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Over in the Votes table in the Stack Overflow database, a couple of the more popular vote types are 1 and 2.
A vote type of 1 means that an answer was accepted as being the solution by a user, and a vote type of 2 means someone upvoted a question or answer.
I Voted!
What this means is that it’s impossible for a question to ever have an accepted answer vote cast for it. A question can’t be an answer, here.
Unfortunately, SQL Server doesn’t have a way of inferring that.
ANSWER ME!
Anything with a post type id of 1 is a question.
The way the tables are structured, VoteTypeId and PostTypeId don’t exist together, so we can’t use a constraint to validate any conditions that exist between them.
VotanPostan
Lost And Found
When we run a query that looks for posts with a type of 2 (that’s an answer) that have a vote type of 1, we can find 2500 of them relatively quickly.
SELECT TOP (2500)
p.OwnerUserId,
p.Score,
p.Title,
v.CreationDate,
ISNULL(v.BountyAmount, 0) AS BountyAmount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 2 --WHERE VoteTypeId = 2
AND p.PostTypeId = 1
ORDER BY v.CreationDate DESC;
Here’s the stats:
Table 'Posts'. Scan count 0, logical reads 29044
Table 'Votes'. Scan count 1, logical reads 29131
SQL Server Execution Times:
CPU time = 63 ms, elapsed time = 272 ms.
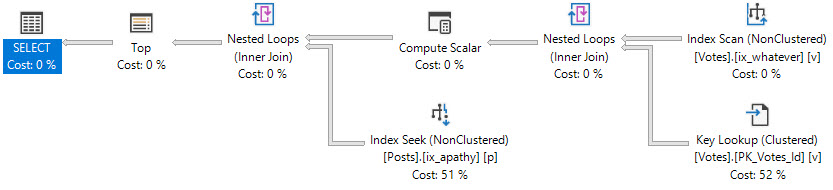
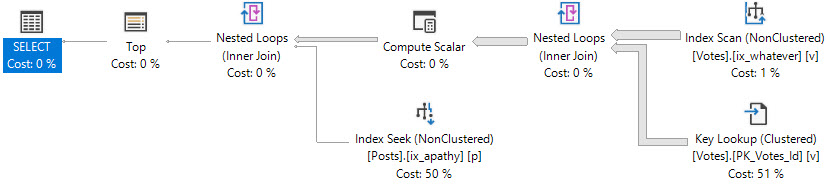
And here’s the plan:
Nelly.
Colossus of Woes
Now let’s ask SQL Server for some data that doesn’t exist.
SELECT TOP (2500)
p.OwnerUserId,
p.Score,
p.Title,
v.CreationDate,
ISNULL(v.BountyAmount, 0) AS BountyAmount
FROM dbo.Posts AS p
JOIN dbo.Votes AS v
ON p.Id = v.PostId
WHERE v.VoteTypeId = 1 --Where VoteTypeId = 1
AND p.PostTypeId = 1
ORDER BY v.CreationDate DESC;
Here’s the stats:
Table 'Posts'. Scan count 0, logical reads 11504587
Table 'Votes'. Scan count 1, logical reads 11675392
SQL Server Execution Times:
CPU time = 14813 ms, elapsed time = 14906 ms.
You could say things got “worse”.
Not only that, but they got worse for the exact same plan.
Argh.
So What Happened?
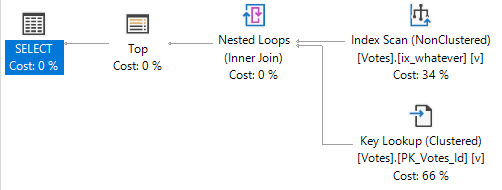
In the original plan, the TOP asked for rows, and quickly got them.
In the second plan, the TOP kept asking for rows, getting them from the Votes table, and then losing them on the join to Posts.
There was no parameter sniffing, there were no out of date stats, no blocking, or any other oddities. It’s just plain bad luck because of the data’s relationship.
If we apply hints to this query to:
Scan the clustered index on Votes
Choose Merge or Hash joins instead of Nested Loops
Force the join order as written
We get much better performing queries. The plan we have is chosen because the TOP sets a row goal that makes a Nested Loops plan using narrow (though not covering) indexes attractive to the optimizer. When it’s right, like in the original query, you probably don’t even think about it.
When it’s wrong, like in the second query, it can be quite mystifying why such a tiny query can run forever to return nothing.
If you want to try it out for yourself, use these indexes:
CREATE INDEX whatever
ON dbo.Votes( CreationDate, VoteTypeId, PostId );
CREATE NONCLUSTERED INDEX apathy
ON dbo.Posts ( PostTypeId )
INCLUDE ( OwnerUserId, Score, Title );
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
For Row Store indexes — Columnstore is different and should be maintained differently — rebuilding indexes gets prescribed as a cure for performance issues of all types.
Sudden query slowdown? Rebuild’em!
Blocking? Rebuild’em!
High CPU? Rebuild’em!
No idea what’s going on? Rebuild’em!
While an index rebuild will update stats, which is sometimes beneficial, it’s a lot easier to, you guessed it, just update stats.
It’ll have the same net effect on plan invalidation, with a heck of a lot of less resource usage and, potentially, blocking.
Bear Bile
It’s my opinion, and you can take it or leave it, that index rebuilds should be reserved for special circumstances.
You deleted a lot of data
You need to change something about the index
You have a Heap with a lot of forwarded fetches
But why is that my opinion? What evidence has informed it? No, it’s not just because I like to be disagreeable. It’s mostly that I went through a fairly normal progression.
A lot of people are talking about index fragmentation, sounds bad!
Hey, I think this fixed something? I’m gonna keep doing it.
Well, I still have problems, but at least I don’t have fragmentation.
I don’t have enough time to run CHECKDB, I need to rebuild less often.
No one seems to be complaining when I don’t rebuild indexes…
My problems had nothing to do with index fragmentation!
Here’s How To Order
But what metrics might an index rebuild fix, and why was so much fuss made about them for so long?
To test this, and to get you, dear reader, an explanation, I set up some tests.
First, I created a simple index.
CREATE INDEX ix_whatever ON dbo.Users (Reputation);
Then, I wrote queries that will touch 1%, 10%, and 100% of the Users table (2013 version, 2.4mm rows).
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Reputation = 289
AND 1 = (SELECT 1);
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE u.Reputation BETWEEN 100 AND 450
AND 1 = (SELECT 1);
SELECT COUNT(*) AS records
FROM dbo.Users AS u
WHERE 1 = (SELECT 1);
After that, it’s a matter of introducing the “harmful” kind of fragmentation — empty space on pages.
This is the kind of fragmentation that bloats your indexes, both on disk and in memory, leaving less room for other things.
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 5);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 10);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 20);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 30);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 40);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 50);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 60);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 70);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 80);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 90);
ALTER INDEX ix_whatever ON dbo.Users REBUILD WITH(FILLFACTOR = 100);
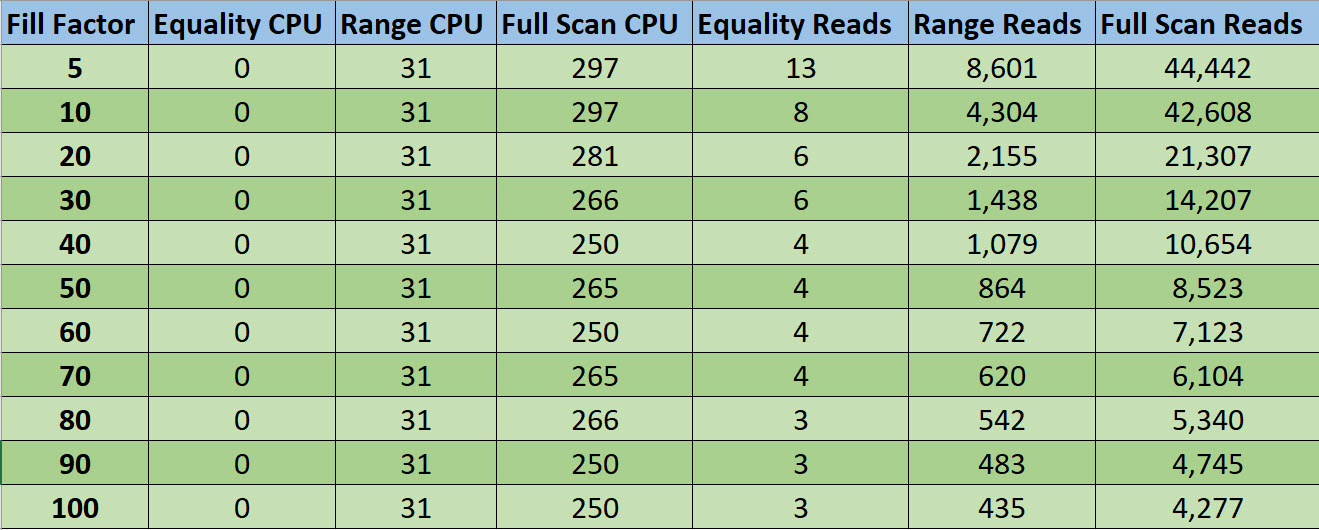
Now, since I don’t wanna take that many screenshots, I embraced my long-lost ENTJ and made an Excel table.
Retirement Plan
Not surprisingly, the chief metric that went down as fill factor went up is reads. CPU didn’t change much, if at all.
That being said, you have to be real goofy about fill factor to get reads to matter.
Within a sane boundary of fill factors, which I’d call 70 to 100, ask yourself if any variation there is the root cause of your performance problems.
Now, I know you. It’s hard to talk you out of your superstitions, and you’re gonna keep thrashing that expensive SAN with constant I/O nonsense.
But maybe I can talk you into raising the threshold that you do it at. Maybe I can get you to not rebuild (or reorg) your indexes until they hit >70% fragmentation. That’s 30% fill factor on the chart.
Virgin Wax
Alright, now we know that rebuilds help reads. When would number of reads matter most?
If your disks are the quite elderly spinning variety
And you don’t have enough memory to cache your hot data
And maybe your hot data could fit into memory if were defragmented to 100% fill factor
You can kinda start to put a picture together of when it mattered. Before SSDs, before 64bit OSes (32b capped out at ~3GB RAM), and well before flash storage, etc.
Way back when, rebuilding made sense. Reading unordered data could have a big impact on a workload because disks would have to physically move to find unordered/spread out data.
So yeah, if you notice that your workload is doing a lot more reads over time, and rebuilding at 100% fill factor reduces reads, it might be worth rebuilding at some point. But to solve any other common workload problems, look somewhere else. Rebuilding indexes is not the cure.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.