When you have queries that need to process a lot of data, and probably do some aggregations over that lot-of-data, batch mode is usually the thing you want.
Originally introduced to accompany column store indexes, it works by allowing CPUs to apply instructions to up to 900 rows at a time.
It’s a great thing to have in your corner when you’re tuning queries that do a lot of work, especially if you find yourself dealing with pesky parallel exchanges.
Oh, Yeah
One way to get that to happen is to use a temp table with a column store index on it.
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
GROUP BY v.UserId
ORDER BY SumBounty DESC;
CREATE TABLE #t(id INT, INDEX c CLUSTERED COLUMNSTORE);
SELECT
v.UserId,
SUM(v.BountyAmount) AS SumBounty
FROM dbo.Comments AS c
JOIN dbo.Votes AS v
ON v.PostId = c.PostId
AND v.UserId = c.UserId
LEFT JOIN #t AS t
ON 1 = 0
GROUP BY v.UserId
ORDER BY SumBounty DESC;
If you end up using this enough, you may just wanna create a real table to use, anyway.
Remarkable!
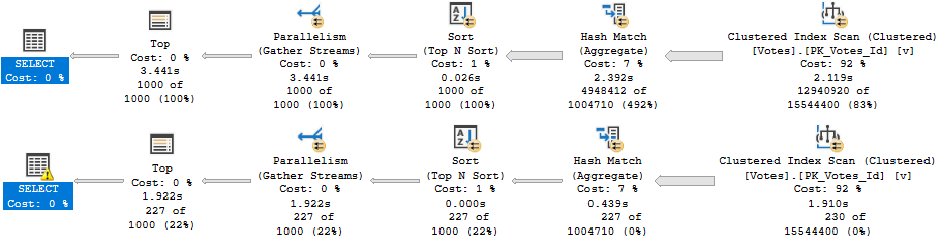
If we look at the end (or beginning, depending on how you read your query plans) just to see the final times, there’s a pretty solid difference.
you can’t make me
The first query takes around 10 seconds, and the second query takes around 4 seconds. That’s a pretty handsome improvement without touching anything else.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You have too many indexes on too many tables already, and the thought of adding more fills you with a dread that has a first, middle, last, and even a confirmation name.
This is another place where temp tables can save your bacon, because as soon as the query is done they basically disappear.
Forever. Goodbye.
Off to buy a pack of smokes.
That Yesterday
In yesterday’s post, we looked at how a temp table can help you materialize an expression that would otherwise be awkward to join on.
If we take that same query, we can see how using the temp table simplifies indexing.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
CREATE CLUSTERED INDEX c ON #Posts(JoinKey);
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Rather than have to worry about how to handle a bunch of columns across the where and join and select, we can just stick a clustered index on the one column we care about doing anything relational with to get the final result.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
A lot of the time when I see queries that are written with all sorts of gymnastics in the join or where clause and I ask some questions about it, people usually start complaining about the design of the table.
That’s fine, but when I ask about changing the design, everyone gets quiet. Normalizing tables, especially for Applications Of A Certain Age™ can be a tremendously painful project. This is why it’s worth it to get things right the first time. Simple!
Rather than make someone re-design their schema in front of me, often times a temp table is a good workaround.
Egg Splat
Let’s say we have a query that looks like this. Before you laugh, and you have every right to laugh, keep in mind that I see queries like this all the time.
They don’t have to be this weird to qualify. You can try this if you have functions like ISNULL, SUBSTRING, REPLACE, or whatever in joins and where clauses, too.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records
FROM dbo.Users AS u
JOIN dbo.Posts AS p
ON u.Id = CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY p.OwnerUserId;
There’s not a great way to index for this, and sure, we could rewrite it as a UNION ALL, but then we’d have two queries to index for.
Sometimes getting people to add indexes is hard, too.
People are weird. All day weird.
Steak Splat
You can replace it with a query like this, which also allows you to index a single column in a temp table to do your correlation.
SELECT
p.OwnerUserId,
SUM(p.Score) AS TotalScore,
COUNT_BIG(*) AS records,
CASE WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END AS JoinKey
INTO #Posts
FROM dbo.Posts AS p
WHERE p.PostTypeId IN (1, 2)
AND p.Score > 100
GROUP BY CASE
WHEN p.PostTypeId = 1
THEN p.OwnerUserId
WHEN p.PostTypeId = 2
THEN p.LastEditorUserId
END,
p.OwnerUserId;
SELECT *
FROM #Posts AS p
WHERE EXISTS
(
SELECT 1/0
FROM dbo.Users AS u
WHERE p.JoinKey = u.Id
);
Remember that temp tables are like a second chance to get schema right. Don’t waste those precious chances.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If your columns aren’t nullable, you’ll run into far fewer problems and ambiguities.
I’d like a new data type called ABYSS. Or maybe VOID.
The Problem: Wrong Data Type And NULL Checks
DECLARE @d date = '20170601';
DECLARE @sql nvarchar(MAX) = N'
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.LastEditDate > @d
AND p.LastEditDate IS NOT NULL;'
EXEC sp_executesql @sql,
N'@d date',
@d;
GO
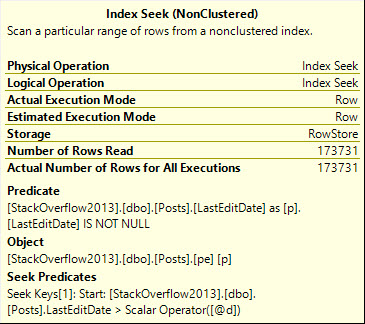
If we pass in a parameter that has a date datatype, rather than date time, an odd thing will happen if we add in a redundant IS NOT NULL check.
yortsed
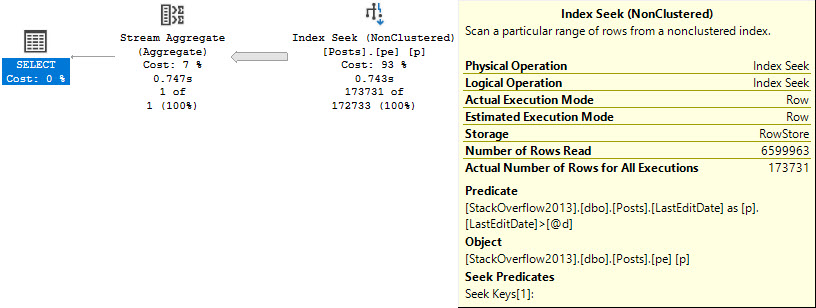
The seek predicate will only seek to the first non-NULL value, rather than immediately to the start of the range of dates we care about, which means we end up reading a lot more rows than necessary.
Note the query runtime of 743 milliseconds, and that we end up reading quite a few more rows than we return.
And here I was told Seeks are always efficient ?
Solution One: Stop Checking For NULLs
If we either stop checking for NULLs, we’ll get around the issue.
DECLARE @d date = '20170601';
DECLARE @sql nvarchar(MAX) = N'
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.LastEditDate > @d;'
EXEC sp_executesql @sql,
N'@d date',
@d;
GO
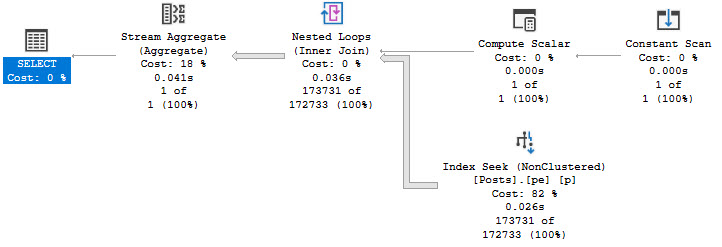
The plan for this query looks a bit different, but performance is no worse for the wear.
still using the wrong datatype
Note the 25 millisecond execution time. A clear improvement over the 743 milliseconds above. Though the query plan does look a bit odd.
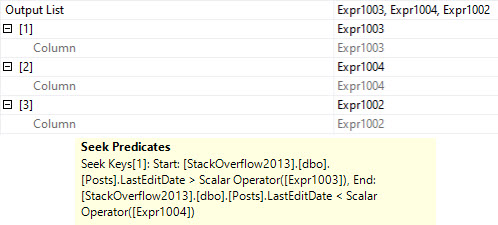
The compute scalar gins up a date range, which is checked in the seek:
HELLO COMPUTER
I wonder what Expr1002 is up to.
Solution Two: Just Use The Right Datatype To Begin With
In reality, this is what we should have done from the start, but the whole point of this here blog post is to show you what can happen when you Do The Wrong Thing™
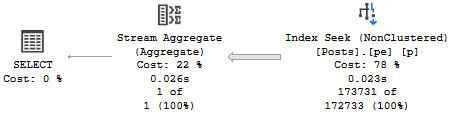
When we use the right datatype, we get a simple plan that executes quickly, regardless of the redundant NULL check.
DECLARE @d date = '20170601';
DECLARE @sql nvarchar(MAX) = N'
SELECT
COUNT_BIG(*) AS records
FROM dbo.Posts AS p
WHERE p.LastEditDate > @d
AND p.LastEditDate IS NOT NULL;'
EXEC sp_executesql @sql,
N'@d datetime',
@d;
no fuss, no muss
Here, the NULL check is a residual predicate rather than the Seek predicate, which results in a seek that really seeks instead of just meandering past some NULLs.
gerd jerb
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
On the one hand, I don’t think the optimizer uses them enough. There are times when hinting a nonclustered index, or re-writing a query to get it to use a nonclustered index can really help performance.
On the other hand, they can really exacerbate parameter sniffing problems, and can even lead to read queries blocking write queries. And quite often, they lead to people creating very wide indexes to make sure particular queries are covered.
It’s quite a tedious dilemma, and in the case of blocking and, as we’ll see, deadlocks, one that can be avoided with an optimistic isolation level Read Committed Snapshot Isolation, or Snapshot Isolation.
Bigger Deal
There are ways to repro this sort of deadlock that rely mostly on luck, but the brute force approach is easiest.
First, create an index that will only partially help out some of our queries:
CREATE INDEX dethklok ON dbo.Votes(VoteTypeId);
Next, get a couple queries that should be able to co-exist ready to run in a loop.
A select:
/* Selecter */
SET NOCOUNT ON;
DECLARE @i INT, @PostId INT;
SET @i = 0;
WHILE @i < 10000
BEGIN
SELECT
@PostId = v.PostId,
@i += 1
FROM dbo.Votes AS v
WHERE v.VoteTypeId = 8;
END;
An update:
/* Updater */
SET NOCOUNT ON;
DECLARE @i INT = 0;
WHILE @i < 10000
BEGIN
UPDATE v
SET v.VoteTypeId = 8 - v.VoteTypeId,
@i += 1
FROM dbo.Votes AS v
WHERE v.Id = 55537618;
END;
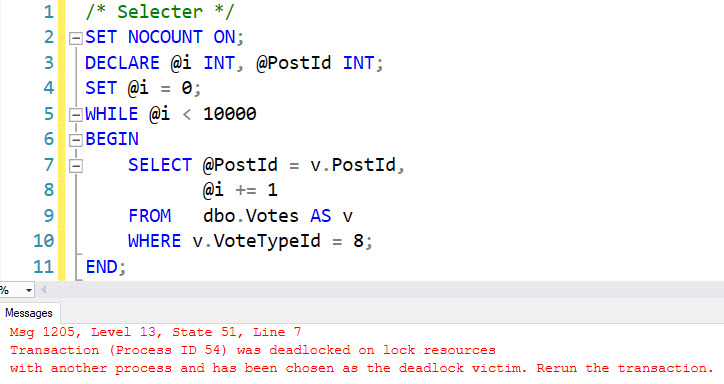
After several seconds, the select query will hit a deadlock.
i see you
But Why?
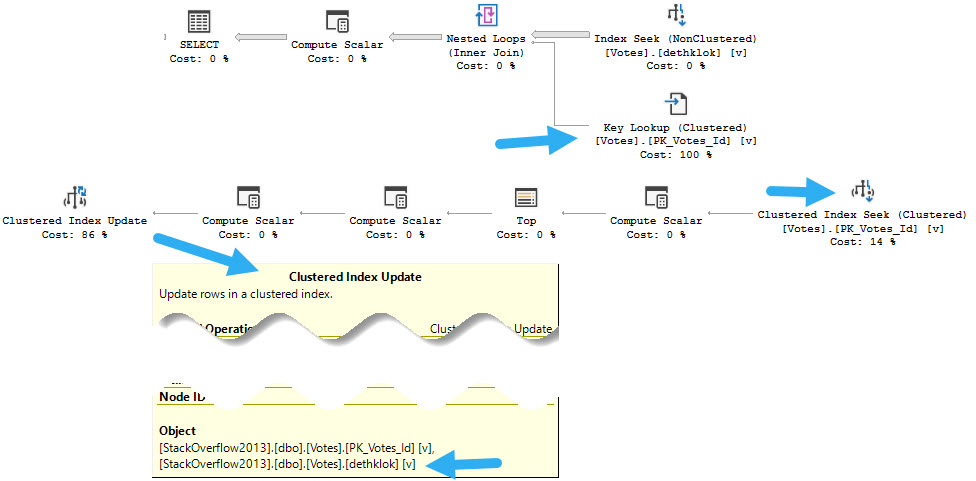
The reason, of course, if that these two queries compete for the same indexes:
who’s who
The update query needs to update both indexes on the table, the read query needs to read from both indexes on the table, and they end up blocking each other:
kriss kross
We could fix this by expanding the index to also have PostId in it:
CREATE INDEX dethklok ON dbo.Votes(VoteTypeId, PostId);
Using an optimistic isolation level:
ALTER DATABASE StackOverflow2013
SET READ_COMMITTED_SNAPSHOT ON WITH ROLLBACK IMMEDIATE;
Or rewriting the select query to use a hash or merge join:
/* Selecter */
SET NOCOUNT ON;
DECLARE @i INT, @PostId INT;
SET @i = 0;
WHILE @i < 10000
BEGIN
SELECT @PostId = v2.PostId,
@i += 1
FROM dbo.Votes AS v
INNER /*MERGE OR HASH*/ JOIN dbo.Votes AS v2
ON v.Id = v2.Id
WHERE v.VoteTypeId = 8
END;
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
But here we are again, with the optimizer treating us like fools for our index choices.
Let’s say we have this index on the Comments table:
CREATE INDEX lol
ON dbo.Comments
(UserId)
INCLUDE
(Id, PostId, Score, CreationDate, Text);
Is it a great idea? I dunno. But it’s there, and it should make things okay for this query:
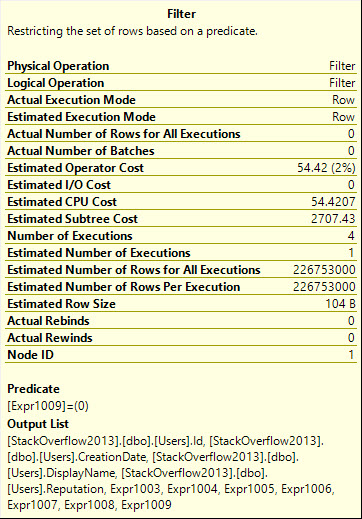
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0;
You’re Round
But when we run the query and collect the plan, something rather astounding happens.
The optimizer uses our index to build a smaller index!
hard at work
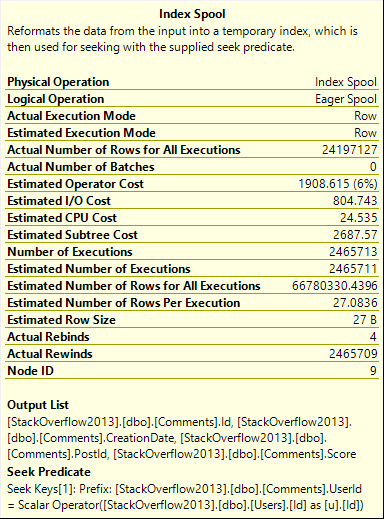
Digging in on the Eager Index Spool, it’s a nearly identical copy of the index we have, just without the Text column.
it’s over
Your Mother Dresses You Funny
Of course, the optimizer being the unreasonable curmudgeon that it is, the only workaround is to also create the more narrow index.
CREATE INDEX lmao
ON dbo.Comments
(UserId)
INCLUDE
(Id, PostId, Score, CreationDate);
Or add the Text column to the select:
SELECT u.Id,
u.DisplayName,
u.Reputation,
ca.Id,
ca.Type,
ca.CreationDate,
ca.Text
FROM dbo.Users AS u
OUTER APPLY
(
SELECT c.Id,
DENSE_RANK()
OVER ( PARTITION BY c.PostId
ORDER BY c.Score DESC ) AS Type,
c.CreationDate,
c.Text
FROM dbo.Comments AS c
WHERE c.UserId = u.Id
) AS ca
WHERE ca.Type = 0;
But that has a weird side effect, too. We’ll look at that tomorrow.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sending rows out to SSMS is annoying. It takes a long time when there are a lot of them, and sometimes you just wanna show a query plan that does a lot of work without all the blah blah.
One other way is a method I used in yesterday’s post.
Let’s be timely and look at that!
Everyone Loves Windowing Functions
They do all sorts of funny stuff. Number things, rank things.
And they make great demos, whether you’re trying to show how to do something cool, or make them perform well.
The funny thing is that the optimizer doesn’t really understand that, unless you intervene, the numbering and ranking doesn’t start at zero.
You can have a whole query run, do a bunch of really hard work, take a long time, and not return any rows, just by filtering to where the function = 0.
Using yesterday’s query as an example, here’s what happens:
SELECT u.Id,
u.DisplayName,
u.Reputation,
u.CreationDate,
ca.*
FROM dbo.Users AS u
OUTER APPLY
(
SELECT *,
DENSE_RANK()
OVER( PARTITION BY vs.Id
ORDER BY vs.Id DESC ) AS whatever
FROM dbo.VotesSkewed AS vs
WHERE vs.UserId = u.Id
AND vs.VoteTypeId BETWEEN 1 AND 5
) AS ca
WHERE ca.whatever = 0;
Since I’m generating the rank here on the primary key/clustered index for the table, it’s basically free to do. It’s fully supported by the index.
If you create a different index to support that, e.g. a POC index (Partitioning, Ordering, Covering), you can use that too.
FULL SIZE
Bag Of Bones
This query will, of course, return no rows. But it will do all the prerequisite work to generate a result set to filter on. That’s where that filter operator kicks in, and nothing passes through it. It’s a stopping point right before things would actually have to start kicking out to SSMS.
less than zero
But of course, the optimizer doesn’t know that until we get there. If it did, we might just end up with a constant scan and a query that finishes instantly.
For example, if you add a silly where clause like this:
SELECT u.Id,
u.DisplayName,
u.Reputation,
u.CreationDate,
ca.*
FROM dbo.Users AS u
OUTER APPLY
(
SELECT *,
DENSE_RANK()
OVER( PARTITION BY vs.Id
ORDER BY vs.Id DESC ) AS whatever
FROM dbo.VotesSkewed AS vs
WHERE vs.UserId = u.Id
AND vs.VoteTypeId BETWEEN 1 AND 5
) AS ca
WHERE 1 = (SELECT 0)
You end up with this:
O NO A SCAN
That’s That
If you find yourself with a demo that returns a lot of rows, and you don’t want to use a TOP or OFFSET/FETCH to only return some of them, this is a fun way to return nothing.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
It would certainly be a good candidate for index changes though, because the first thing we need to address is that key lookup.
It’s a sensitive issue.
King Index
We’re going to walk through something I talked about what seems like an eternity ago. Why? Because it has practical application here.
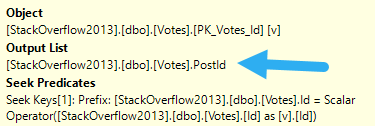
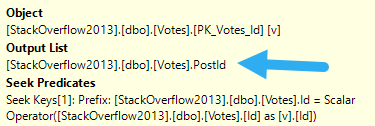
When you look at the core part of the query, PostId is only in the select list. Most advice around key lookups (including, generally, my own) is to consider putting columns only in the output into the includes of the index.
and that’s where this is
But we’re in a slightly different situation, here.
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
We’re getting a distinct count, and SQL Server has some choices for coming up with that.
If we follow the general advice here and create this index, we’ll end up in trouble:
CREATE INDEX v
ON dbo.Votes(VoteTypeId, CreationDate) INCLUDE(PostId)
WITH (DROP_EXISTING = ON);
growling intensifies
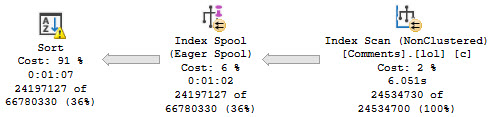
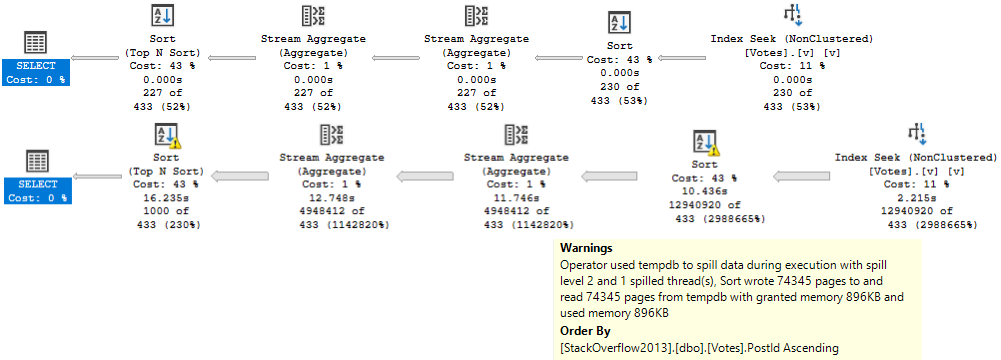
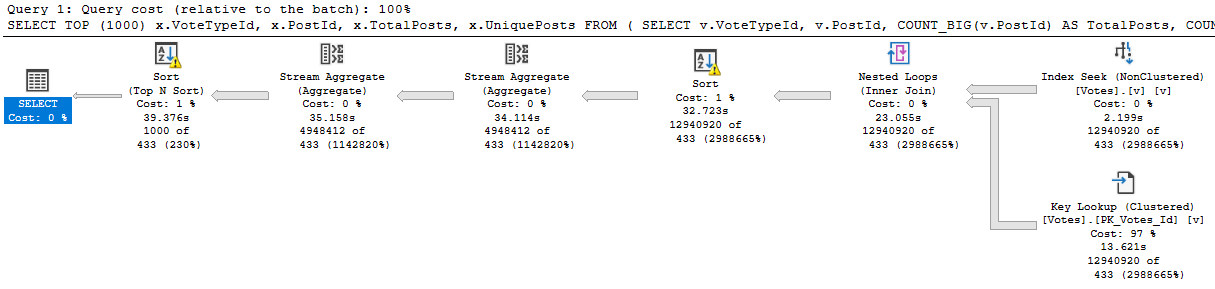
Since the Stream Aggregate expects ordered data, and PostId isn’t in order in the index (because includes aren’t in any particular order), we need to sort it. For a small amount of data, that’s fine. For a large amount of data, it’s not.
There is a second Sort in the plan further down, but it’s on the count expression, which means we can’t index it without adding in additional objects, like an indexed view.
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts, -- this is the expression
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC; -- this is the ordering
What’s An Index To A Non-Believer?
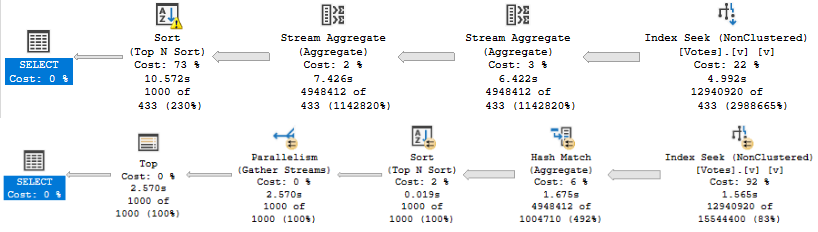
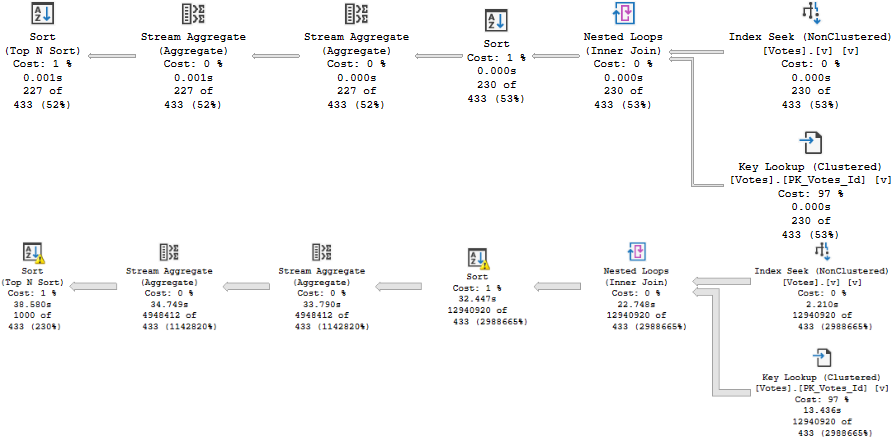
A better index in this case looks like this:
CREATE INDEX v
ON dbo.Votes(VoteTypeId, PostId, CreationDate)
WITH (DROP_EXISTING = ON);
It will shave about 6 seconds off the run time, but there’s still a problem when the “big” data doesn’t go parallel:
big data differences
When the plan goes parallel, it’s about 4x faster than the serial version. Now I know what you’re thinking, here. We could use OPTIMIZE FOR to always get the plan for the big value. And that’s not a horrible idea — the small data parameter runs very quickly re-using the parallel plan here — but there’s another way.
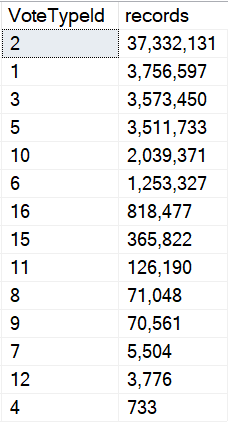
Let’s look at our data.
Don’t Just Stare At It
Let’s draw an arbitrary line. I think a million is a popular number. I wish it was a popular number in my bank account, but you know.
unwritten law
I know we’re ignoring the date column data, but this is good enough for now. There’s only so much I can squeeze into one blog post.
The point here is that we’re going to say that anything under a million rows is okay with using the small plan, and anything over a million rows needs the big plan.
Sure, we might need to refine that later if there are outliers within those two groups, but this is a blog post.
How do we do that? We go dynamic.
Behike 54
Plan ol’ IF branches plan ol’ don’t work. We need something to get two distinct plans that are re-usable.
Here’s the full procedure:
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
DECLARE @sql NVARCHAR(MAX) = N'';
SET @sql += N'
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
/*dbo.VoteCount*/
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), ''2014-01-01'')
AND v.VoteTypeId = @VoteTypeId '
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
SET @sql += N'
AND 1 = (SELECT 1)'
END
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
SET @sql += N'
AND 2 = (SELECT 2)'
END
SET @sql += N'
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC;
';
RAISERROR('%s', 0, 1, @sql) WITH NOWAIT;
EXEC sys.sp_executesql @sql,
N'@VoteTypeId INT, @YearsBack INT',
@VoteTypeId, @YearsBack;
END;
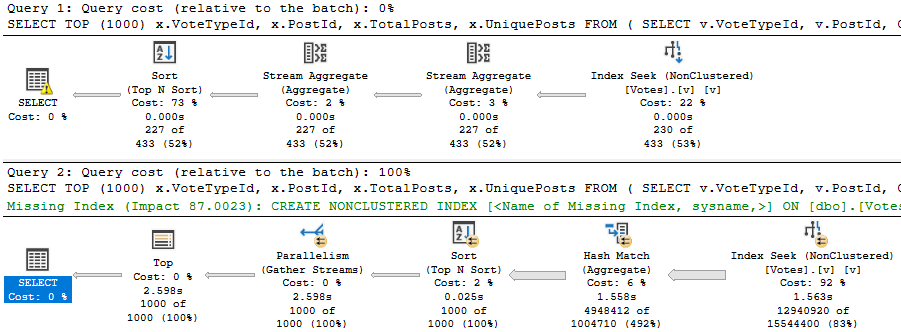
There’s a bit going on in there, but the important part is in the middle. This is what will give use different execution plans.
IF @VoteTypeId IN (2, 1, 3, 5, 10, 6)
BEGIN
SET @sql += N'
AND 1 = (SELECT 1)'
END
IF @VoteTypeId IN (16, 15, 11, 8, 9, 7, 12, 4)
BEGIN
SET @sql += N'
AND 2 = (SELECT 2)'
END
Sure, there are other ways to do this. You could even selectively recompile if you wanted to. But some people complain when you recompile. It’s cheating.
Because the SQL Server Query Optimizer typically selects the best execution plan for a query, we recommend only using hints as a last resort for experienced developers and database administrators.
See? It’s even documented.
Now that we’ve got that all worked out, we can run the procedure and get the right plan depending on the amount of data we need to shuffle around.
strangers in the night
Little Star
Now I know what you’re thinking. You wanna know more about that dynamic SQL. You want to solve performance problems and have happy endings.
We’ll do that next week, where I’ll talk about common issues, best practices, and more tricks you can use to get queries to perform better with it.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
There are lots of different ways that parameter sniffing can manifest in both the operators chosen, the order of operators chosen, and the resources acquired by a query when a plan is compiled. At least in my day-to-day consulting, one of the most common reasons for plans being disagreeable is around insufficient indexes.
One way to fix the issue is to fix the index. We’ll talk about a way to do it without touching the indexes tomorrow.
Let’s say we have this index to start with. Maybe it was good for another query, and no one ever thought twice about it. After all, you rebuild your indexes every night, what other attention could they possible need?
CREATE INDEX v
ON dbo.Votes(VoteTypeId, CreationDate);
If we had a query with a where clause on those two columns, it’d be be able to find data pretty efficiently.
But how much data will it find? How many of each VoteTypeId are there? What range of dates are we looking for?
Well, that depends on our parameters.
Cookie Cookie
Here’s our stored procedure. There’s one column in it that isn’t in our index. What a bummer.
CREATE OR ALTER PROCEDURE dbo.VoteCount (@VoteTypeId INT, @YearsBack INT)
AS
BEGIN
SELECT TOP (1000)
x.VoteTypeId,
x.PostId,
x.TotalPosts,
x.UniquePosts
FROM
(
SELECT v.VoteTypeId,
v.PostId,
COUNT_BIG(v.PostId) AS TotalPosts,
COUNT_BIG(DISTINCT v.PostId) AS UniquePosts
FROM dbo.Votes AS v
WHERE v.CreationDate >= DATEADD(YEAR, (-1 * @YearsBack), '2014-01-01')
AND v.VoteTypeId = @VoteTypeId
GROUP BY v.VoteTypeId,
v.PostId
) AS x
ORDER BY x.TotalPosts DESC;
END;
That doesn’t matter for a small amount of data, whether it’s encountered because of the parameters used, or the size of the data the procedure is developed and tested against. Testing against unrealistic data is a recipe for disaster, of course.
Cookie Cookie
What can be tricky is that if the sniffing is occurring with the lookup plan, the optimizer won’t think enough of it to request a covering index, either in plan or in the index DMVs. It’s something you’ll have to figure out on your own.
i said me toooh yeah that
So we need to add that to the index, but where? That’s an interesting question, and we’ll answer it in tomorrow’s post.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Alright, maybe not any database. Let’s stick with SQL Server. That’s the devil we know.
At some point in your life, you’re going to construct a query that takes user input, and that input is likely going to come in the form of a parameter.
It could be a stored procedure, dynamic SQL, or something from your application. But there it is.
Waiting. Watching.
Sniffing.
Defining A Problem
When we use parameters, we re-use execution plans, at least until a Qualifying Event™ occurs.
What’s a qualifying event?
Recompile hint
Stats update
Temp table modification threshold
Plan eviction
Server restart
Now, it might be reasonable to think that a mature optimizer — and it is an optimizer, not just a planner — would be able to do something a bit more optimal. After all, why would anyone think it would take the same amount of work to get through 100 rows as it would take to get through 1,000,000 rows? It’s a fundamentally different approach.
Doing a run to the grocery store to replenish a few things requires a far different mindset from going to prepare for a large family meal. You have to choose between a basket or a cart, whether you can jump right to the couple spots you need or you need to walk up and down every aisle, and even if you might need to write down a list because it doesn’t fit into brain memory.
One might also have the expectation that if a significant inaccuracy is detected at runtime, the strategy might change. While that does sort of happen with Adaptive Joins, it’s not a full plan rewrite.
Detecting A Problem
The plan cache usually sucks for this, unless you’re saving the data off to more stable tables. Why? Because most people only figure out they’ve been sniffed after a plan changes, which means it’s not in the cache anymore. You know, when end users start complaining, the app goes unresponsive, you can’t connect to the server, etc.
You could set your watch to it.
But sometimes it’s there. Some funny looking little plan that looks quite innocent, but seems to do a lot of work when you bang it up against other DMVs.
If you have the luxury, Query Store is quite a better tool for detecting plan changes. It’s even got reports built in just for that.
how nice of you.
For the extra fancy amongst you, I pray that your expensive monitoring tool has a way to tell you when query plans change, or when normally fast plans deviate from that.
Deciphering A Problem
This is where things can get difficult, unless you’re monitoring or logging information. You typically need a few different combinations of parameter values to feed in to your query, so you can see what changed and when. Quite often, there’s no going back easily.
Let’s say you had a plan, and it was a good plan. Then one of those pesky qualifying events comes along, and it’s decided that you need a new plan.
And what if… that new plan is worse? No matter how much you recompile or update stats or toggle with cardinality estimation, you just can’t go back to the way things were without lots of hints or changes to the query? Maybe that’s not parameter sniffing. Maybe that’s parameter snuffing. I’m gonna copyright that.
Most parameter sniffing will result in a plan with a set of bad choices for different amounts of data, which will result in something like this:
not crafty
This isn’t a “bad estimate” — it was a pretty good estimate for the first parameter value. It just wasn’t a good estimate for the second parameter value.
And to be honest, quite a bit of parameter sniffing issues come from Nested Loops. Not because it’s bad, but because it’s bad for large amount of data, especially in a serial plan. It’s a pretty easy way to gum up a query, though. Make it get stuck in a loop for 13 million rows. It wasn’t fast? No kidding. Poof, be gone.
But then opposite-land isn’t good, either.
like falling, baby
This plan probably makes plenty of sense for a big chunk of data. One big scan, one big hash, one big sort. Done.
Of course, for a small amount of data, we go from taking 1ms to taking 2s. Small amount of data people will likely not be happy with that. Your server might not be either, what with all the extra CPU resources we’re using in this here parallel plan all the time now.
Tomorrow, we’ll look at how sometimes you can fix parameter sniffing with better indexes.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.