Moved!
This post has been moved here.
Root cause: This one is haunted.
Enjoy the rest of your (now cursed) day.
SQL Server Consulting, Education, and Training
This post has been moved here.
Root cause: This one is haunted.
Enjoy the rest of your (now cursed) day.
Resource Governor can be used to enforce a hard cap on query MAXDOP, unlike the sp_configure setting. However, query plan compilation does not take such a MAXDOP limit into account. As a result, limiting MAXDOP through Resource Governor can lead to unexpected degradations in performance due to suboptimal query plan choices.
We start with the not often seen here three table demo. I’d rather not explain how I came up with this sample data, so I’m not going to. I did my testing on a server with max server memory set to 10000 MB. The following tables take about half a minute to create and populate and only take up about 1.5 GB of space:
DROP TABLE IF EXISTS dbo.SMALL;
CREATE TABLE dbo.SMALL (ID_U NUMERIC(18, 0));
INSERT INTO dbo.SMALL WITH (TABLOCK)
SELECT TOP (100) 5 * ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
OPTION (MAXDOP 1);
DROP TABLE IF EXISTS dbo.MEDIUM;
CREATE TABLE dbo.MEDIUM (ID_A NUMERIC(18, 0));
INSERT INTO dbo.MEDIUM WITH (TABLOCK)
SELECT TOP (600000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL))
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
OPTION (MAXDOP 1);
DROP TABLE IF EXISTS dbo.LARGE;
CREATE TABLE dbo.LARGE (
ID_A NUMERIC(18, 0),
ID_U NUMERIC(18, 0),
FILLER VARCHAR(100)
);
INSERT INTO dbo.LARGE WITH (TABLOCK)
SELECT 2 * ( RN / 4), RN % 500, REPLICATE('Z', 100)
FROM
(
SELECT TOP (8000000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) q
OPTION (MAXDOP 1)
CREATE INDEX IA ON LARGE (ID_A);
CREATE INDEX IU ON LARGE (ID_U);
I thought up the theory behind this demo on a car ride back from a SQL Saturday, but wasn’t able to immediately figure out a way to get the query plan that I wanted. I ended up finally seeing it in a totally different context and am now happy to share it with you. Consider the following query:
SELECT LARGE.ID_U FROM dbo.SMALL INNER JOIN dbo.LARGE ON SMALL.ID_U = LARGE.ID_U INNER JOIN dbo.MEDIUM ON LARGE.ID_A = MEDIUM.ID_A OPTION (MAXDOP 1);
The MAXDOP 1 hints results in a serial plan with two hash joins:
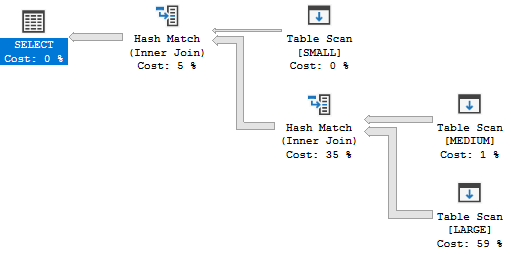
This is a perfectly reasonable plan given the size and structure of the tables. There are no bitmap filters because row mode bitmap filters are only supported for parallel plans. Batch mode is not considered for this query because I’m testing on SQL Server 2017 and there isn’t a columnstore index on any of the tables referenced in the query. On my machine a single query execution uses 2422 of CPU time and 2431 ms of elapsed time.
A parallel plan at MAXDOP 4 is able to run more quickly but with a much higher CPU time. A single execution of the MAXDOP 4 query uses 5875 ms of CPU time and 1617 ms of elapsed time. There are multiple bitmap filters present. I zoomed in on the most interesting part of the plan because I haven’t figured out how images work with WordPress yet:
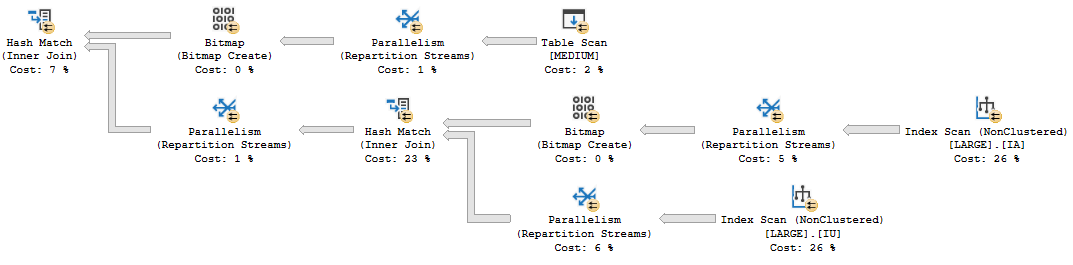
Instead of doing a scan of the LARGE table, SQL Server instead chooses an index intersection plan. The cost of the additional hash join is reduced by multiple bitmap filters. There are only 2648396 and 891852 rows processed on the build and probe side instead of 8 million for each side, which is a significant gain.
Some end users really can’t be trusted with the power to run parallel plans. I thought about making a joke about an “erik” end user but I would never subject my readers to the same joke twice. After enforcing a MAXDOP of 1 at the Resource Governor level, you will probably not be shocked to learn that the query with the explicit MAXDOP 1 hint gets the same query plan as before and runs with the same amount of CPU and elapsed time.
If you skipped or forget the opening paragraph, you may be surprised to learn that the query with a MAXDOP 4 hint also gets the same query plan as before. The actual execution plan even has the parallel racing arrows. However, the query cannot execute in parallel. The parallelism and bitmap operators are skipped by the query processor and all of the rows are processed on one thread:
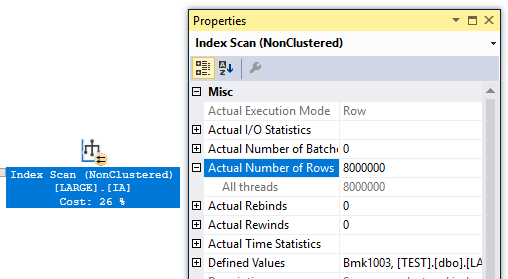
I uploaded the query plan here if you want to look at it. This type of scenario can happen even without Resource Governor. For example, a compiled parallel query may be downgraded all the way to MAXDOP 1 if it can’t get enough parallel threads.
The query performs significantly worse than before, which hopefully is not a surprise. A single execution took 12860 ms of CPU time and 13078 ms of elapsed time. Nearly all of the query’s time is spent on the hash join for the index intersection, with a tempdb spill and the processing of additional rows both playing a role. The tempdb spill occurs because SQL Server expected the build side of the hash join to be reduced to 1213170 rows. The bitmap filtering does not occur so 8 million rows were sent to the build side instead.
In this case, adding a MAXDOP 1 hint to the query will improve performance by about 5X. Larger differences in run times can be easily seen on servers with more memory than my desktop.
If you’re using using Resource Governor to limit MAXDOP to 1, consider adding explicit MAXDOP 1 hints at the query level if you truly need the best possible performance. The MAXDOP 1 hint may at first appear to be redundant, but it gives the query optimizer additional information which can result in totally different, and sometimes significantly more efficient, query plans. I expect that this problem could be avoided if query plan caching worked on a Resource Governor workload group level. Perhaps that is one of those ideas that sounds simple on paper but would be difficult for Microsoft to implement. Batch mode for row store can somewhat mitigate this problem because batch mode bitmap filters operate even under MAXDOP 1, but you can still get classic row mode bitmaps even on SQL Server 2019.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Adaptive joins are a new feature in SQL Server 2017. For adaptive join operators the decision to do a hash or loop join is deferred until enough input rows are counted. You can get an introduction on the topic in this blog post by Joe Sack. Dmitry Pilugin has an excellent post digging into the internals. The rest of this blog post assumes that you know the basics of adaptive joins.
It’s pretty easy to create a query that has an adaptive join in SQL Server 2017. Below I create a CCI with 100k rows and an indexed rowstore table with 400k rows:
DROP TABLE IF EXISTS dbo.MY_FIRST_CCI;
CREATE TABLE dbo.MY_FIRST_CCI (
FILTER_ID_1 INT NOT NULL,
FILTER_ID_2 INT NOT NULL,
FILTER_ID_3 INT NOT NULL,
JOIN_ID INT NOT NULL,
INDEX CI CLUSTERED COLUMNSTORE
);
INSERT INTO dbo.MY_FIRST_CCI WITH (TABLOCK)
SELECT TOP (100000)
t.RN
, t.RN
, t.RN
, t.RN
FROM
(
SELECT ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
) t
OPTION (MAXDOP 1);
ALTER TABLE dbo.MY_FIRST_CCI REBUILD WITH (MAXDOP = 1);
CREATE STATISTICS S1 ON dbo.MY_FIRST_CCI (FILTER_ID_1)
WITH FULLSCAN;
CREATE STATISTICS S2 ON dbo.MY_FIRST_CCI (FILTER_ID_2)
WITH FULLSCAN;
CREATE STATISTICS S3 ON dbo.MY_FIRST_CCI (FILTER_ID_3)
WITH FULLSCAN;
CREATE STATISTICS S4 ON dbo.MY_FIRST_CCI (JOIN_ID)
WITH FULLSCAN;
DROP TABLE If exists dbo.SEEK_ME;
CREATE TABLE dbo.SEEK_ME (
JOIN_ID INT NOT NULL,
PADDING VARCHAR(2000) NOT NULL,
PRIMARY KEY (JOIN_ID)
);
INSERT INTO dbo.SEEK_ME WITH (TABLOCK)
SELECT TOP (400000)
ROW_NUMBER() OVER (ORDER BY (SELECT NULL))
, REPLICATE('Z', 2000)
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CREATE STATISTICS S1 ON dbo.SEEK_ME (JOIN_ID)
WITH FULLSCAN;
The full scan stats are just there to show that there isn’t any funny business with the stats. The below query gets an adaptive join:
SELECT * FROM dbo.MY_FIRST_CCI o INNER JOIN dbo.SEEK_ME i ON o.JOIN_ID = i.JOIN_ID
It’s obvious when it happens in SSMS:
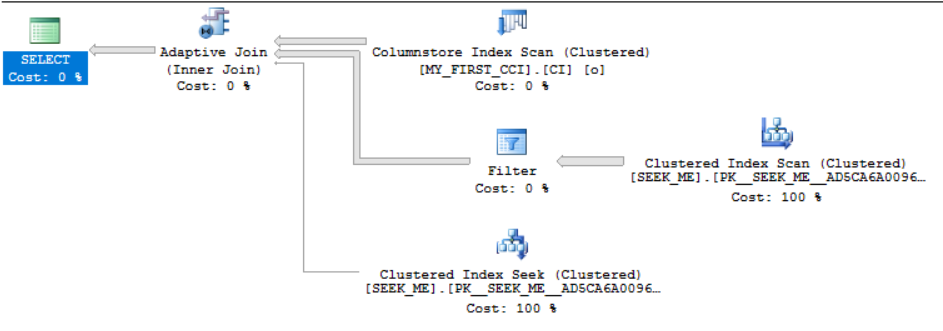
It’s possible to get an adaptive join with even simpler table definitions. I created the tables this way because they’ll be used for the rest of this post.
Unlike some other vendors, Microsoft was nice enough to expose the adaptive row threshold in SSMS when looking at estimated or actual plans:
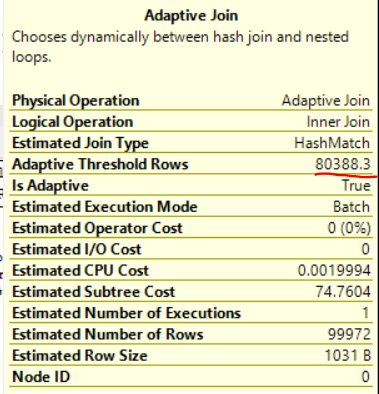
The adaptive join saves input rows to a temporary structure and acts as a blocking operator until it makes a decision about which type of join to use. In this example, if there are less than 80388.3 rows then the adaptive join will execute as a nested loop join. Otherwise it’ll execute as a hash join.
The adaptive threshold row count can change quite a bit based on the input cardinality estimate. It changes to 22680 rows if I add the following filter that results in a single row cardinality estimate:
WHERE o.FILTER_ID_1 = 1
It was surprising to me to see so much variance for this query. There must be some overhead with doing the adaptive join but I wouldn’t expect the tipping point between a loop and hash join to change so dramatically. I would expect it to be close to a traditional tipping point calculated without adaptive joins.
Let’s disable adaptive joins using the 'DISABLE_BATCH_MODE_ADAPTIVE_JOINS' USE HINT and consider how an execution plan would look for this query:
SELECT *
FROM dbo.MY_FIRST_CCI o
INNER JOIN dbo.SEEK_ME i ON o.JOIN_ID = i.JOIN_ID
WHERE o.FILTER_ID_1 BETWEEN @start AND @end
OPTION (
RECOMPILE,
USE HINT('DISABLE_BATCH_MODE_ADAPTIVE_JOINS')
);
We should expect a hash join if the local variables don’t filter out as many rows. Conversely, we should expect a loop join if the local variables on FILTER_ID_1 filter out many rows from the table. There’s a tipping point where the plan will change from a hash join to a loop join if we filter out a single additional row . On my machine, the tipping point is between 48295 and 48296 rows:
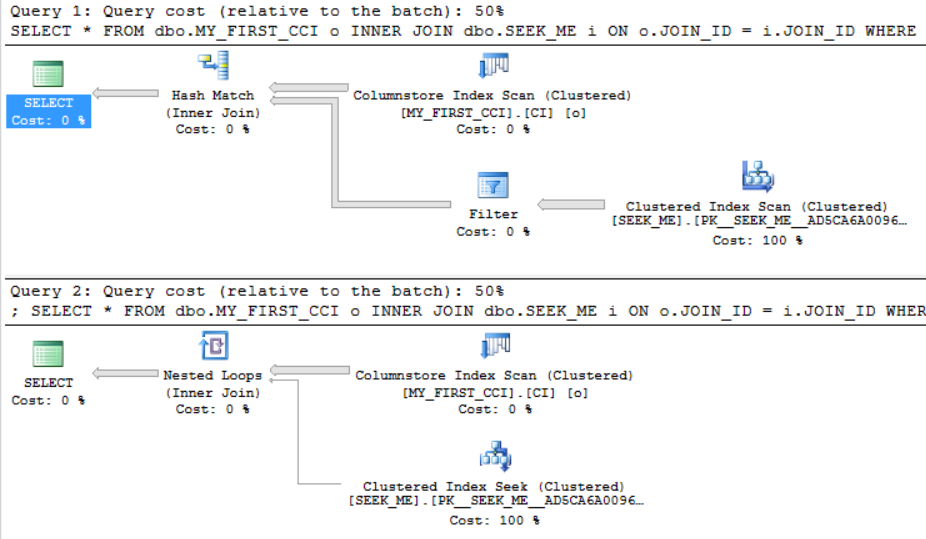
The estimated costs for the two queries are very close to each other: 74.6842 and 74.6839 optimizer units. However, we saw earlier that the tipping point for an adaptive join on this query can vary between 22680 and 80388.3 rows. This inconsistency means that we can find a query that performs worse with adaptive joins enabled.
After some trial and error I found the following query:
SELECT * FROM dbo.MY_FIRST_CCI o INNER JOIN dbo.SEEK_ME i ON o.JOIN_ID = i.JOIN_ID WHERE o.FILTER_ID_1 BETWEEN 1 AND 28000 AND o.FILTER_ID_2 BETWEEN 1 AND 28000 AND o.FILTER_ID_3 BETWEEN 1 AND 28000 ORDER BY (SELECT NULL) OFFSET 100001 ROWS FETCH NEXT 1 ROW ONLY OPTION (MAXDOP 1);
The ORDER BY stuff isn’t important. It’s there just to not send any rows over the network. Here’s the plan:
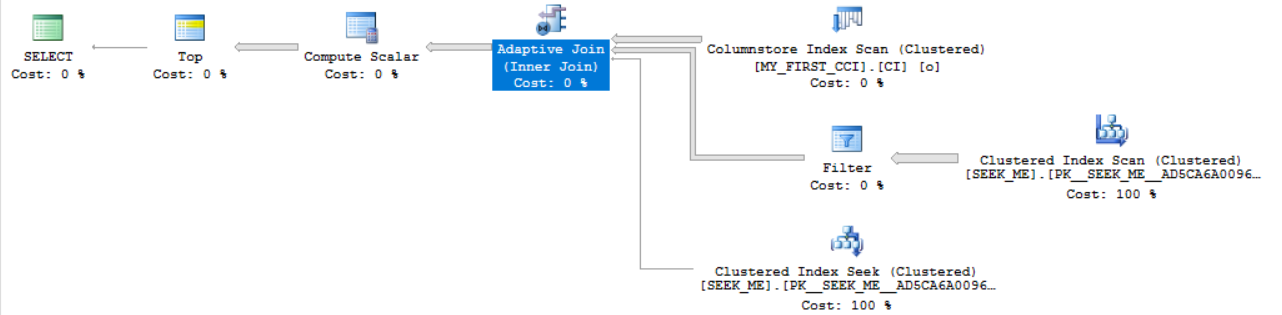
The query has a cardinality estimate of 10777.7 rows coming out of the MY_FIRST_CCI table. The adaptive join has a tipping point of 27611.6 rows. However, I’ve constructed the table and the filter such that 28000 rows will be sent to the join. SQL Server expects a loop join, but it will instead do a hash join because 28000 > 27611.6. With a warm cache the query takes almost half a second:
CPU time = 469 ms, elapsed time = 481 ms.
If I disable adaptive joins, the query finishes in less than a fifth of a second:
CPU time = 172 ms, elapsed time = 192 ms.
A loop join is a better choice here, but the adaptive row threshold makes the adaptive join pick a hash join.
This post contains only a single test query, so it’s no cause for panic. It’s curious that Microsoft made the adaptive join tipping so dependent on cardinality estimates going into the join. I’m unable to figure out the design motivation for doing that. I would expect the other side of the join to be much more important.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sometimes parallel queries perform poorly due to bad luck. The parallel page supplier may distribute rows in a way that’s not optimal for performance. The hashing function used by SQL Server to split rows into threads may assign too many rows to a single thread. You may have seen some of these situations in production queries, but they can be hard to reproduce because they may depend on a lot of different factors including the complete data in some of the involved tables. This blog post demonstrates a technique to create demos that show how parallel thread imbalance can lead to poor performance.
This work is inspired by a recent blog post at sql.sasquatch by my friend and colleague @sqL_handLe. For a given data type and DOP it appears that the same hashing function and thread boundaries are always applied, although I haven’t confirmed that. In other words, if an INT of value 1 in a parallel MAXDOP 4 query gets hashed to thread 2 in a query, then it may also get hashed to thread 2 from a different table in a different query. In other words, it appears to be possible to figure out ahead of time where different values will be hashed to. That means that it’s possible to construct a data set with very poor thread balance.
To create the mapping we need to construct a data set that makes it easy to tell which value gets sent to which thread. I inserted 20 distinct values into a table with each value having a row count equal to a different power of 2. Sample code to do this:
DROP TABLE IF EXISTS dbo.FIND_HASH_VALUES; CREATE TABLE dbo.FIND_HASH_VALUES ( ID INT NOT NULL ); DECLARE @start_num INT = 0; INSERT INTO dbo.FIND_HASH_VALUES WITH (TABLOCK) SELECT t.n FROM ( SELECT v.n + @start_num AS n , ROW_NUMBER() OVER (ORDER BY v.n) RN FROM ( VALUES (1), (2), (3), (4), (5) , (6), (7), (8), (9), (10) , (11), (12), (13), (14), (15) , (16), (17), (18), (19), (20) ) v(n) ) t CROSS APPLY ( SELECT TOP (POWER(2, -1 + t.RN)) 1 dummy FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) ca OPTION (MAXDOP 1);
The above code runs in about a second on my machine. To see which value goes to which thread I need a query with a repartition streams operator that has the hash partitioning type. One way to get this is with window functions. The following query naturally goes parallel on my machine and has the operator that I’m looking for:
SELECT TOP 1 ID , COUNT(*) OVER (PARTITION BY ID) CNT FROM FIND_HASH_VALUES OPTION (MAXDOP 4);
The TOP 1 isn’t essential. It’s there to limit the size of the result set. The query finishes quickly and rows are sent to all four threads:
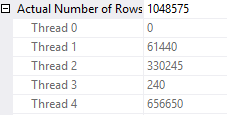
Decoding which value went to which thread can be done in SQL Server using the & operator. The query below finds the thread number for the 20 distinct values in the table:
DECLARE @start_num INT = 0, @thread1 INT = 61440, @thread2 INT = 330245, @thread3 INT = 240, @thread4 INT = 656650; SELECT t.ID , cast(@thread1 & t.bit_comp as bit) + 2 * cast(@thread2 & t.bit_comp as bit) + 3 * cast(@thread3 & t.bit_comp as bit) + 4 * cast(@thread4 & t.bit_comp as bit) AS THREAD FROM ( SELECT v.n + @start_num AS ID , POWER(2, -1 + ROW_NUMBER() OVER (ORDER BY v.n)) bit_comp FROM ( VALUES (1), (2), (3), (4), (5) , (6), (7), (8), (9), (10) , (11), (12), (13), (14), (15) , (16), (17), (18), (19), (20) ) v(n) ) t;
Here’s the result set:
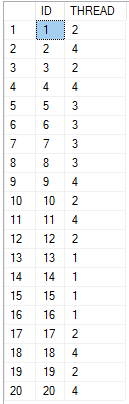
Getting the mapping for other ranges of IDs is as simple as changing the variables for both queries. I put the first 100 values on pastebin in case it’s useful for someone.
For demo purposes I want a table that contains values that will always hash to the same thread at MAXDOP 4. You can find 25 values that hash to the same thread in the pastebin. In the table below I insert 100k rows for each unique value that goes to thread 1:.
DROP TABLE IF EXISTS dbo.SKEWED_DATA; CREATE TABLE dbo.SKEWED_DATA ( ID INT NOT NULL, FILLER VARCHAR(50) ); INSERT INTO dbo.SKEWED_DATA WITH (TABLOCK) SELECT t.n, 'Lamak' FROM ( SELECT v.n FROM ( VALUES (13), (14), (15), (16) , (30), (31), (32), (33) , (46), (47), (48), (49), (50) , (63), (64), (65), (66) , (80), (81), (82), (83) , (97), (98), (99), (100) ) v(n) ) t CROSS APPLY ( SELECT TOP (100000) 1 dummy FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) ca OPTION (MAXDOP 1); CREATE STATISTICS S ON dbo.SKEWED_DATA (ID) WITH FULLSCAN;
The business requirement of the day is to take the first 2.5 million rows from the SKEWED_DATA table, calculate the row number partitioned by ID, and to return all rows with a row number greater than 100k. The query will never return any results based on how data was inserted into the table. Here is one way to express such a query:
SELECT ID, FILLER FROM ( SELECT ID , FILLER , ROW_NUMBER() OVER (PARTITION BY ID ORDER BY (SELECT NULL)) RN FROM ( SELECT TOP (2500000) ID , FILLER FROM dbo.SKEWED_DATA ) t ) t2 WHERE t2.RN > 100000 OPTION (MAXDOP 4);
The query runs at MAXDOP 4 but does not benefit from parallelism at all. All of the rows are sent to the same thread:
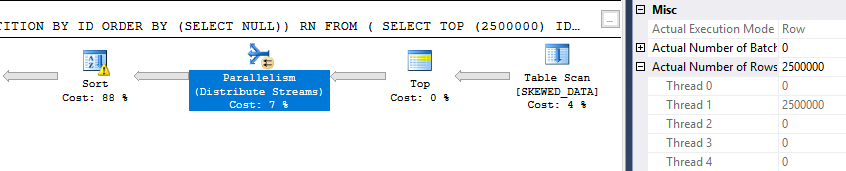
The sort spills to tempdb because the memory grant for the sort is split evenly across all four threads. Threads 2-4 don’t get any rows so 75% of the memory grant is wasted:
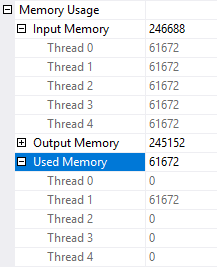
I ran the query five times and it executed in an average of 2816 ms. CPU time was generally pretty close to the elapsed time. This is a very bad example of a parallel query.
The query above is designed to not be able to take advantage of parallelism. The useless repartition streams step and the spill to tempdb suggest that the query might perform better with a MAXDOP 1 hint. With a MAXDOP 1 hint the query runs with an average time of 2473 ms. There is no longer a spill to tempdb.
What happens if the query is run with MAXDOP 3? Earlier I said that the hashing function or thread boundaries can change based on DOP. With MAXDOP 3 I get a much more even row distribution on threads:
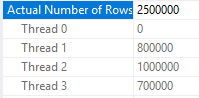
The better distribution of rows means that the spill to tempdb does not happen either:
The query definitely seems like it could benefit from parallelism. After five runs it had an average execution time of 1563 ms, almost a 50% improvement over the MAXDOP 4 query. The ratio of CPU time to elapsed time is also much more in line with what we might expect from a good parallel query:
CPU time = 3219 ms, elapsed time = 1574 ms.
It was fun to construct a query that runs faster when MAXDOP is lowered from 4 to 3. Hopefully the details were interesting in of themselves.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
This blog post contains a few demos for generating hash partitioned exchange spills. It does not attempt to explain why performance is so bad in some cases, but I think that the behavior here is simply interesting to observe. Note that all of the demos were done on SQL Server 2016 SP1 CU4. Some of this may not be reproducible on other versions.
First I need to say a few words about repartition and gather streams operators. Here’s an example of one:
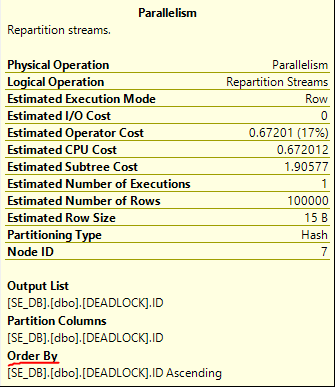
These operators are easy to misunderstand. Even when they have an “order by” they do not directly do a sort in the traditional sense. Instead, they rely on the ordered input threads to produce 1 or more ordered output threads. There’s no memory grant associated with them. For an illustration of how this could work, consider a very simple example with 4 rows on two threads:
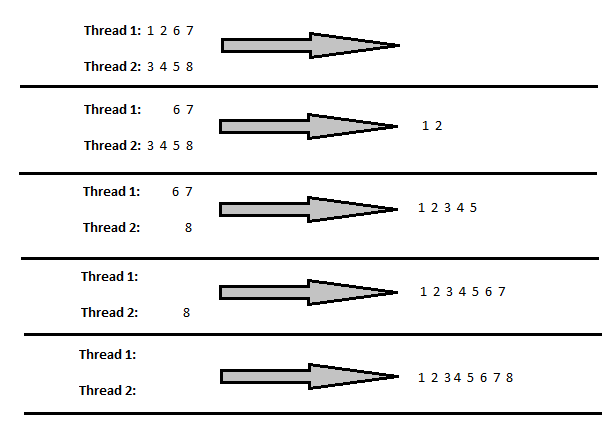
After the first step, values 1 and 2 from thread 1 are processed. There is a switch to thread 2 that moves 3, 4, and 5, and so on. This all explained in a much better way by Paul White in his talk on parallelism at the 2013 PASS Summit:
As usual, the good stuff is hidden in extended event descriptions:
Occurs when the memory communication buffers for a query with multiple Parallelism operators become full, resulting in one of the operators writing to TempDB. If this happens multiple times in a single query plan the query performance is impacted. Use this event in conjunction with any of the *_showplan events to determine which operation in the generated plan is causing the exchange spill using the node_id field
According to Paul White, one way to get a deadlock is when the buffers are full but there aren’t any rows on one of the threads. There is a brilliant demo that involves partitioning by round robin near the end of the talk that starts here:
This blog post focuses on deadlocks that occur with hash partitioning.
Only one table is needed to see exchange spills caused by hash partitioning. The first column stores the ID used for the join and the second column is used to pad out the pages. The clustered index isn’t a primary key to allow for duplicate values. Table definition:
DROP TABLE IF EXISTS DEADLOCK; CREATE TABLE DEADLOCK ( ID BIGINT NOT NULL, FLUFF VARCHAR(100) ); CREATE CLUSTERED INDEX CI__DEADLOCK ON DEADLOCK (ID);
The query that I’ll run forces a parallel merge join with varying MAXDOP:
SELECT t1.ID
FROM DEADLOCK t1
WHERE EXISTS (
SELECT 1
FROM DEADLOCK t2
WHERE t1.ID = t2.ID
)
ORDER BY t1.ID
OPTION (QUERYTRACEON 8649, MERGE JOIN, MAXDOP 2);
With this query, we can force an order preserving repartition streams to be hashed against a column with as few distinct values as we like. Note that there is an element of chance to this. For some data distributions a deadlock may not always occur. The performance of the same query can vary to an extreme degree as well.
One way to see a deadlock is by putting 50k rows into the table with four distinct values for ID:
TRUNCATE TABLE DEADLOCK;
INSERT INTO DEADLOCK WITH (TABLOCK)
SELECT
(RN - 1) / 12500
, REPLICATE('Z', 100)
FROM (
SELECT TOP (50000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) t
OPTION (MAXDOP 1);
UPDATE STATISTICS DEADLOCK CI__DEADLOCK WITH FULLSCAN;
Running the SELECT query from before with MAXDOP 2 seems to pretty reliably produce a deadlock. The query typically takes around 7 seconds to run at first but it usually finishes much quicker after the deadlock checker has woken up. The deadlock can be seen with the exchange_spill extended event or by the tempdb spill in the repartition streams operator:

Some queries have extremely variable performance. They can run for seconds, minutes, hours, or even longer than a day. They can eventually be killed by the deadlock monitor. I had one such query running for longer than 24 hours, but apparently Microsoft got embarrassed and killed SSMS:

There are many ways to see this behavior. Inserting alternating 0s and 1s seems to do the trick:
TRUNCATE TABLE DEADLOCK;
INSERT INTO DEADLOCK WITH (TABLOCK)
SELECT
RN % 2
, REPLICATE('Z', 100)
FROM (
SELECT TOP (100000) ROW_NUMBER()
OVER (ORDER BY (SELECT NULL)) RN
FROM master..spt_values t1
CROSS JOIN master..spt_values t2
CROSS JOIN master..spt_values t3
) t
OPTION (MAXDOP 1);
UPDATE STATISTICS DEADLOCK CI__DEADLOCK WITH FULLSCAN;
The first 49000 rows or so are displayed fairly consistently in SSMS. After that the query slows to a crawl. It only used 140 ms of CPU time after five minutes of execution. I wasn’t able to get this query to finish on my machine, but other similar queries finished after many hours. The data in sys.dm_exec_query_profiles is interesting:
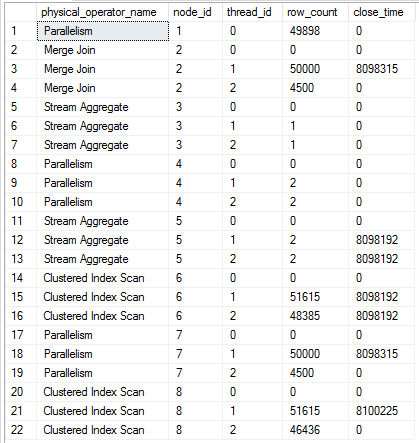
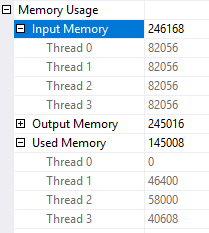
Assuming a packet size of 4500 rows, the scan at node id 8 is just one packet away from finishing. Thread 1 for the repartition streams is finished along with thread 1 of the merge join. All 50k rows with a value of 0 have been processed by the merge join but only 49898 rows made it to the gather streams at the end of the plan. I’ve seen this kind of behavior with the performance issue that affects some parallel queries with a TOP operator.
All six rows from sys.dm_os_waiting_tasks have a wait type of CXPACKET. There are resource descriptions of WaitType=e_waitPortClose. Ultimately, it’s not clear to me why this query appears to run “forever”, but one way or another it should eventually finish.
The same behavior can be seen in 2017 RC2. I couldn’t get either of the two example queries to finish on that version. Some of my test cases don’t cause deadlocks in 2016 SP1 CU2. It appears that Microsoft has done work in this area with negative consequences for some data distributions. A theory for why this happens can be found here. Microsoft appears to have fixed this in 2016 SP1 CU6.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
String aggregation is a not uncommon problem in SQL Server. By string aggregation I mean grouping related rows together and concatenating a string column for that group in a certain order into a single column. How will do CCIs do with this type of query?
A simple table with three columns is sufficient for testing. ITEM_ID is the id for the rows that should be aggregated together. LINE_ID stores the concatenation order within the group. COMMENT is the string column to be concatenated. The table will have 104857600 rows total with 16 rows per ITEM_ID.
CREATE TABLE dbo.CCI_FOR_STRING_AGG ( ITEM_ID BIGINT NOT NULL, LINE_ID BIGINT NOT NULL, COMMENT VARCHAR(10) NULL, INDEX CCI CLUSTERED COLUMNSTORE ); DECLARE @loop INT = 0 SET NOCOUNT ON; WHILE @loop < 100 BEGIN INSERT INTO dbo.CCI_FOR_STRING_AGG WITH (TABLOCK) SELECT t.RN / 16 , 1 + t.RN % 16 , CHAR(65 + t.RN % 16) FROM ( SELECT TOP (1048576) (1048576 * @loop) - 1 + ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM master..spt_values t1 CROSS JOIN master..spt_values t2 ) t OPTION (MAXDOP 1); SET @loop = @loop + 1; END;
On my machine this codes takes around a minute and a half and the final table size is around 225 MB. I’m inserting batches of 1048576 rows with MAXDOP 1 to get nice, clean rowgroups.
Let’s concatenate the strings at an ITEM_ID level for all ITEM_IDs with an id between 3276800 and 3342335. All of the data is stored in a single rowgroup and the CCI was built in such a way that all other rowgroups can be skipped with that filter. This should represent the best case for CCI performance. A common way to concatenate a column is with the FOR XML PATH method:
SELECT
o.ITEM_ID
, STUFF(
(
SELECT ','+ i.COMMENT
FROM dbo.CCI_FOR_STRING_AGG i
WHERE o.ITEM_ID = i.ITEM_ID
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '') ALL_COMMENTS
FROM dbo.CCI_FOR_STRING_AGG o
WHERE o.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY o.ITEM_ID;
Note that I’m not bothering with the additional arguments for the XML part, but you should whenever using this method in production.
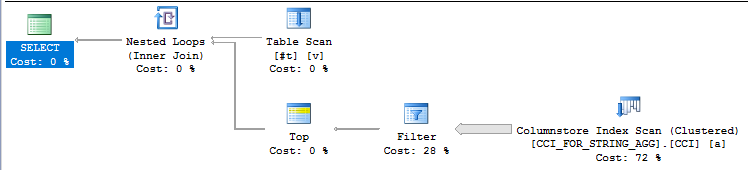
The query plan looks reasonable at first glance:

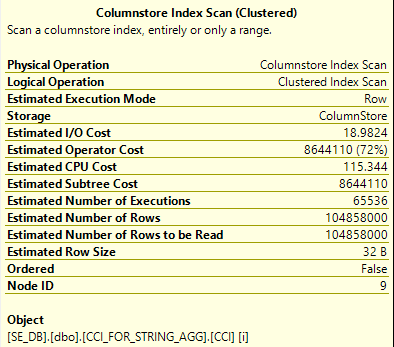
However, the query takes nearly six minutes to complete. That’s not the lightning fast CCI query performance that we were promised!
We can see from the actual execution plan that SQL Server scanned all 104.8 million rows from the CCI on a single thread:
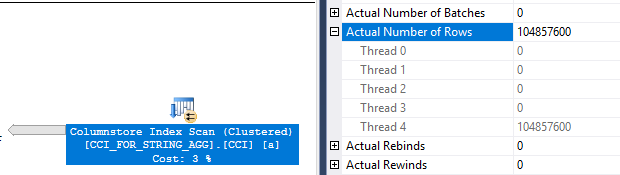
Those rows were then sent into an index spool which was read from all four threads in the nested loop. The CCI scan and the build of the index spool took the most time in the plan so it makes sense why CPU time is less than elapsed time, even with a MAXDOP 4 query:
CPU time = 305126 ms, elapsed time = 359176 ms.
Thinking back to how parallel nested loop joins work, it seems unavoidable that the index spool was built with just one thread. The rows from the outer result set are sent to the inner query one row at a time on different threads. All of the threads run independently at MAXDOP 1. The eager spool for the index is a blocking operation and the blocking occurs even when the subquery isn’t needed. Consider the following query in which the ITEM_ID = 3400000 filter means that rows from the FOR XML PATH part of the APPLY will never be needed:
SELECT o.ITEM_ID
, ac.ALL_COMMENTS
FROM
(
SELECT TOP (9223372036854775807) b.ITEM_ID
FROM dbo.CCI_FOR_STRING_AGG b
WHERE b.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY b.ITEM_ID
) o
OUTER APPLY (
SELECT 'TEST'
UNION ALL
SELECT STUFF(
(
SELECT ','+ i.COMMENT
FROM dbo.CCI_FOR_STRING_AGG i
WHERE o.ITEM_ID = i.ITEM_ID
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '')
WHERE o.ITEM_ID = 3400000
) ac (ALL_COMMENTS)
OPTION (MAXDOP 4, QUERYTRACEON 8649);
The index spool is still built for this query on one thread even though the startup expression predicate condition is never met. It seems unlikely that we’ll be able to do anything about the fact that the index spool is built with one thread and that it blocks execution for the query. However, we know that we only need 1048576 rows from the CCI to return the query’s results. Right now the query takes 104.8 million rows and throws them into the spool. Can we reduce the number of rows put into the spool? The most obvious approach is to simply copy the filter on ITEM_ID into the subquery:
SELECT
o.ITEM_ID
, STUFF(
(
SELECT ','+ i.COMMENT
FROM dbo.CCI_FOR_STRING_AGG i
WHERE o.ITEM_ID = i.ITEM_ID
and i.ITEM_ID BETWEEN 3276800 AND 3342335
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '') ALL_COMMENTS
FROM dbo.CCI_FOR_STRING_AGG o
WHERE o.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY o.ITEM_ID;
This doesn’t have the desired effect:
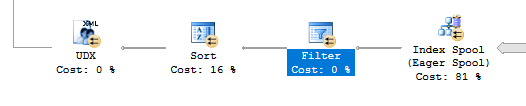
The filter is moved after the index build. We’ll still get all of the rows from the table put into the spool, but no rows will come out unless ITEM_ID is between 3276800 and 3342335. This is not helpful. We can get more strict with the query optimizer by adding a superfluous TOP to the subquery. That should force SQL Server to filter on ITEM_ID before sending rows to the spool because otherwise the TOP restriction may not be respected. One implementation:
SELECT
o.ITEM_ID
, STUFF(
(
SELECT ','+ i.COMMENT
FROM
(
SELECT TOP (9223372036854775807)
a.ITEM_ID, a.LINE_ID, a.COMMENT
FROM dbo.CCI_FOR_STRING_AGG a
WHERE a.ITEM_ID BETWEEN 3276800 AND 3342335
) i
WHERE o.ITEM_ID = i.ITEM_ID
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '') ALL_COMMENTS
FROM dbo.CCI_FOR_STRING_AGG o
WHERE o.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY o.ITEM_ID;
SQL Server continues to outsmart us:

As you can see in the plan above, the spool has completely disappeared. I was not able to find a way, even with undocumented black magic, to reduce the number of rows going into the spool. Perhaps it is a fundamental restriction regarding index spools. In fact, we can use the undocumented trace flag 8615 to see that spools are not even considered at any part in the query plan for the new query. On the left is the previous query with the spool with an example highlighted. On the right is the new query. The text shown here is just for illustration purposes, but we can see the spool on the left:

The important point is that for this query we appear to be stuck.
We can try our luck without the spool by relying on rowgroup elimation alone. The spool can’t be eliminated with the NO_PERFORMANCE_SPOOL hint, but another option (other than the TOP trick above) is to use the undocumented QUERYRULEOFF syntax to disable the optimizer rule for building spools:
SELECT
o.ITEM_ID
, STUFF(
(
SELECT ','+ i.COMMENT
FROM dbo.CCI_FOR_STRING_AGG i
WHERE o.ITEM_ID = i.ITEM_ID
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '') ALL_COMMENTS
FROM dbo.CCI_FOR_STRING_AGG o
WHERE o.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY o.ITEM_ID
OPTION (QUERYRULEOFF BuildSpool);
The spool is gone but we don’t get rowgroup elimination:
We can get rowgroup elimination even without hardcoded filters with a bitmap from a hash join. Why don’t we get it with a nested loop join? Surely SQL Server ought to be able to apply rowgroup elimination for each outer row as it’s processed by the inner part of the nested loop join. We can explore this question further with tests that don’t do string aggregation. The query below gets rowgroup elimination but the constant filters are passed down to the CCI predicate:
SELECT * FROM (VALUES (1), (2), (3), (4)) AS v(x) INNER JOIN dbo.CCI_FOR_STRING_AGG a ON v.x = a.ITEM_ID OPTION (FORCE ORDER, LOOP JOIN);
If we throw the four values into a temp table:
SELECT x INTO #t FROM (VALUES (1), (2), (3), (4)) AS v(x)
The join predicate is applied in the nested loop operator. We don’t get any rowgroup elimination. Perhaps TOP can help us:
SELECT * FROM #t v CROSS APPLY ( SELECT TOP (9223372036854775807) * FROM dbo.CCI_FOR_STRING_AGG a WHERE v.x = a.ITEM_ID ) a OPTION (LOOP JOIN);
Sadly not:
The join predicate is applied in the filter operation. We still don’t get any rowgroup elimination. Frustratingly, we get the behavior that we’re after if we replace the CCI with a heap:
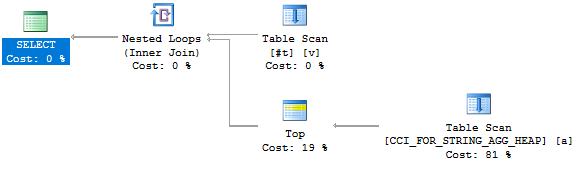
I don’t really see an advantage in pushing down the predicate with a heap. Perhaps Microsoft did not program the optimization that we’re looking for into the query optimizer. After all, this is likely to be a relatively uncommon case. This query is simple enough in that we filter directly against the CCI. In theory, we can give our query a fighting chance by adding a redundant filter on ITEM_ID to the subquery. Here’s the query that I’ll run:
SELECT
o.ITEM_ID
, STUFF(
(
SELECT ','+ i.COMMENT
FROM dbo.CCI_FOR_STRING_AGG i
WHERE o.ITEM_ID = i.ITEM_ID
and i.ITEM_ID BETWEEN 3276800 AND 3342335
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '') ALL_COMMENTS
FROM dbo.CCI_FOR_STRING_AGG o
WHERE o.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY o.ITEM_ID
OPTION (QUERYRULEOFF BuildSpool);
Unfortunately performance is even worse than before. The query finished in around 51 minutes on my machine. It was a proper parallel query and we skipped quite a few rowgroups:
Table ‘CCI_FOR_STRING_AGG’. Segment reads 65537, segment skipped 6488163.
CPU time = 10028282 ms, elapsed time = 3083875 ms.
Skipping trillions of rows is impressive but we still read over 68 billion rows from the CCI. That’s not going to be fast. We can’t improve performance further with this method since there aren’t any nonclustered indexes on the CCI, so there’s nothing better to seek against in the inner part of the loop.
We can use the humble temp table to avoid some of the problems with the index spool. We’re able to insert into it in parallel, build the index in parallel, and we can limit the temp table to only the 1048576 rows that are needed for the query. The following code finishes in less than two seconds on my machine:
CREATE TABLE #CCI_FOR_STRING_AGG_SPOOL (
ITEM_ID BIGINT NOT NULL,
LINE_ID BIGINT NOT NULL,
COMMENT VARCHAR(10) NULL
);
INSERT INTO #CCI_FOR_STRING_AGG_SPOOL WITH (TABLOCK)
SELECT a.ITEM_ID, a.LINE_ID, a.COMMENT
FROM dbo.CCI_FOR_STRING_AGG a
WHERE a.ITEM_ID BETWEEN 3276800 AND 3342335;
CREATE CLUSTERED INDEX CI_CCI_FOR_STRING_AGG_SPOOL
ON #CCI_FOR_STRING_AGG_SPOOL (ITEM_ID, LINE_ID);
SELECT
o.ITEM_ID
, STUFF(
(
SELECT ','+ i.COMMENT
FROM #CCI_FOR_STRING_AGG_SPOOL i
WHERE o.ITEM_ID = i.ITEM_ID
ORDER BY i.LINE_ID
FOR XML PATH('')
)
,1 ,1, '') ALL_COMMENTS
FROM dbo.CCI_FOR_STRING_AGG o
WHERE o.ITEM_ID BETWEEN 3276800 AND 3342335
GROUP BY o.ITEM_ID;
The query plan for the last query:
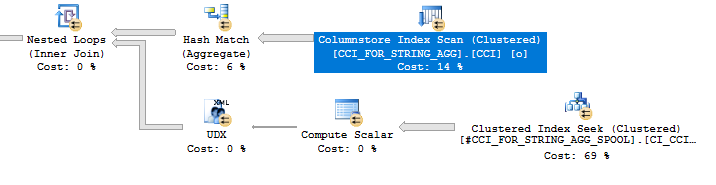
With this approach we’re not really getting much from defining the underlying table as a CCI. If the table had more columns that weren’t needed then we could skip those columns with column elimination.
An obvious solution is simply to add a covering nonclustered index to the table. Of course, that comes with the admission that columnstore currently doesn’t have anything to offer with this type of query. Other solutions which are likely to be more columnstore friendly include using a CLR function to do the aggregation and the SQL Server 2017 STRING_AGG function.
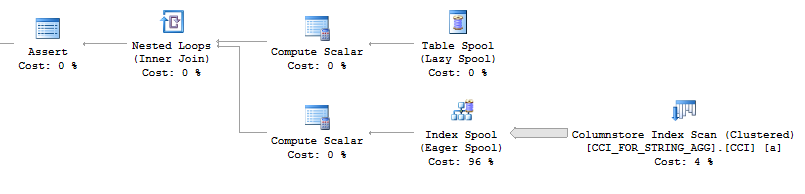
Note that recursion is not likely to be a good solution here. Every recursive query that I’ve seen involves nested loops. The dreaded index spool returns:
Note that the poor performance of these queries isn’t a problem specific to columnstore. Rowstore tables can have the similar performance issues with string aggregation if there isn’t a sufficient covering index. However, if CCIs are used as a replacement for all nonclustered indexes, then the performance of queries that require the table to be on the inner side of a nested loop join may significantly degrade. Some of the optimizations that make querying CCIs fast appear to be difficult to realize for these types of queries. The same string aggregation query when run against a table with a rowstore clustered index on ITEM_ID and LINE_ID finished in 1 second. That is an almost 360X improvement over the CCI.
Thanks for reading!
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Sometimes simple changes to a query can lead to dramatic changes in performance. I often find it helpful to dig into the details as much as I can whenever this happens.
All that’s needed is a table with a clustered key defined on both columns. The first column will always have a value of 1 and the second column will increment for each row. We need two identical tables and may change the number of rows inserted into both of them for some tests. Below is SQL to follow along at home:
DROP TABLE IF EXISTS dbo.outer_tbl; DROP TABLE IF EXISTS dbo.inner_tbl; CREATE TABLE dbo.outer_tbl ( ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID1, ID2) ); CREATE TABLE dbo.inner_tbl ( ID1 BIGINT NOT NULL, ID2 BIGINT NOT NULL, PRIMARY KEY (ID1, ID2) ); INSERT INTO dbo.outer_tbl WITH (TABLOCK) SELECT TOP (20000) 1 , ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; INSERT INTO dbo.inner_tbl WITH (TABLOCK) SELECT TOP (20000) 1 , ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; UPDATE STATISTICS dbo.outer_tbl WITH FULLSCAN; UPDATE STATISTICS dbo.inner_tbl WITH FULLSCAN;
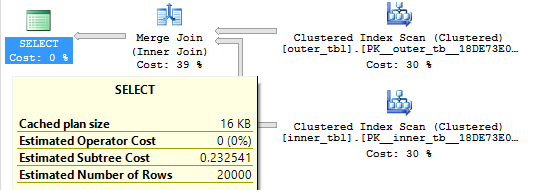
The following query will return one row from outer_tbl if there is at least one row in inner_tbl with a matching value for ID1 and ID2. For our initial data this query will return all 20000 rows. The query optimizer unsurprisingly picks a merge join and the query finishes with just 15 ms of CPU time:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = i.ID2 );
Query plan:
Now let’s make a small change:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 IN (-1, i.ID2) );
Query plan:
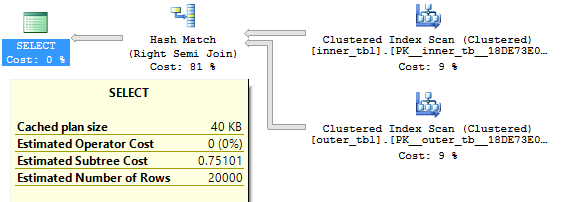
Now the query will return one row from outer_tbl if ID1 = -1 and there is at least one row in inner_tbl with a matching value for ID1 or if there is at least one row in inner_tbl with a matching value for ID1 and ID2. The query optimizer gives me a hash join and the query finishes with 11360 ms of CPU time. If I force a loop join the query finishes with 10750 ms of CPU time. If I force a merge join the query finishes with 112062 ms of CPU time. What happened?
The problem becomes easier to see if we change both of the tables to have just one column. We know that ID1 always equals 1 for both tables so we don’t need it in the query for this data set. Here’s the new set of tables:
DROP TABLE IF EXISTS dbo.outer_tbl_single; DROP TABLE IF EXISTS dbo.inner_tbl_single; CREATE TABLE dbo.outer_tbl_single ( ID2 BIGINT NOT NULL, PRIMARY KEY (ID2) ); CREATE TABLE dbo.inner_tbl_single ( ID2 BIGINT NOT NULL, PRIMARY KEY (ID2) ); INSERT INTO dbo.outer_tbl_single WITH (TABLOCK) SELECT TOP (20000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; INSERT INTO dbo.inner_tbl_single WITH (TABLOCK) SELECT TOP (20000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM master..spt_values t1 CROSS JOIN master..spt_values t2; UPDATE STATISTICS dbo.outer_tbl_single WITH FULLSCAN; UPDATE STATISTICS dbo.inner_tbl_single WITH FULLSCAN;
If I try to force a hash join:
SELECT * FROM dbo.outer_tbl_single o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl_single i WHERE o.ID2 IN (-1, i.ID2) ) OPTION (MAXDOP 1, HASH JOIN);
I get an error:
Msg 8622, Level 16, State 1, Line 27
Query processor could not produce a query plan because of the hints defined in this query. Resubmit the query without specifying any hints and without using SET FORCEPLAN.
That makes sense. Hash join requires an equality condition and there isn’t one. Attempting to force a merge join throws the same error. A loop join is valid but there’s a scan on the inner side of the loop:
SELECT * FROM dbo.outer_tbl_single o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl_single i WHERE o.ID2 IN (-1, i.ID2) ) OPTION (MAXDOP 1, NO_PERFORMANCE_SPOOL);
Query plan:
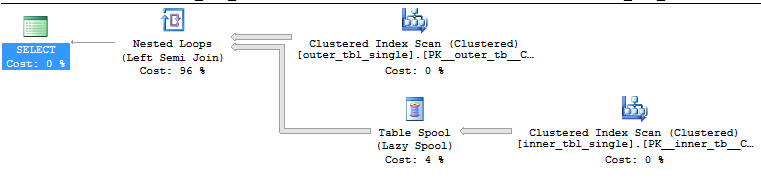
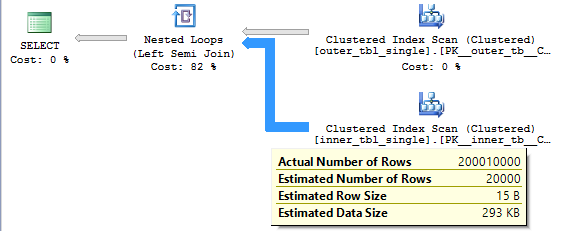
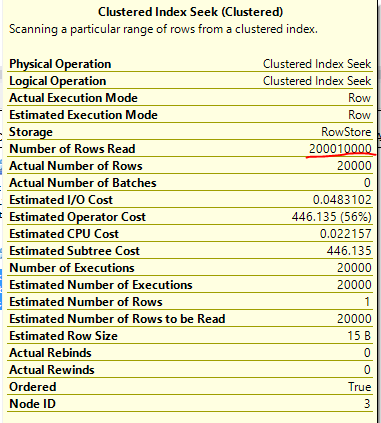
Note that we don’t need to read the 400 million (20000 * 20000) rows from the inner table. This is a semi join so the loop stops as soon as it finds a matching row. On average we should read (1 + 20000) / 2 rows from the inner table before finding a match so the query should need to read 20000 * (1 + 20000) / 2 = 200010000 rows from the inner table. This is indeed what happens:
Let’s go back to the initial slow query with two columns. Why is the query eligible for a hash join? Looking at the details of the hash join we can see that the hash probe is only on the ID1 column:
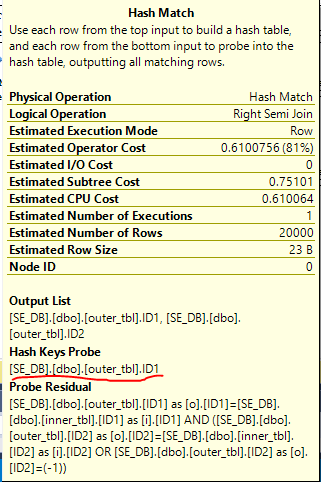
With this data set we end up with the worst possible case for a hash join. All of the rows from the build will hash to the same value and no rows from the probe will be eliminated. It’s still a semi join, so while we don’t know what the order of the hash table is we can still expect to need to (1 + 20000) / 2 entries of the hash table on average before finding the first match. This means that we’ll need to check 200010000 entries in the hash table just for this query. Since all of the work is happening in the hash join we should also expect quadratic performance for this query compared to the number of the rows in the table. If we change the number of rows in the table we see the quadratic relationship:
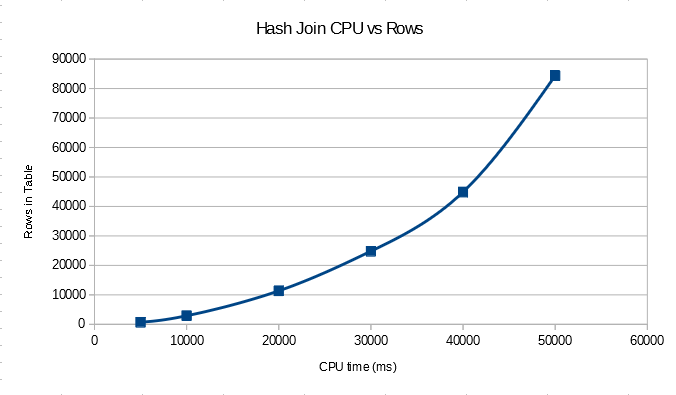
For the table scans in the query we’re likely to do allocation order scans so the data may not be fed into the hash join in index order. However I just created the tables and data is returned in order in other queries, so I’m going to assume that data is fed into the join in order in this case. You may voice your objections to this assumption in the comments. Of course, the final output of the join may not be in order. We can monitor the progress of the query in a lightweight way using sys.dm_exec_query_profiles with trace flag 7412 enabled. I tested with 40k rows in each table to get a longer running join. The number of rows processed every quarter second was not constant:
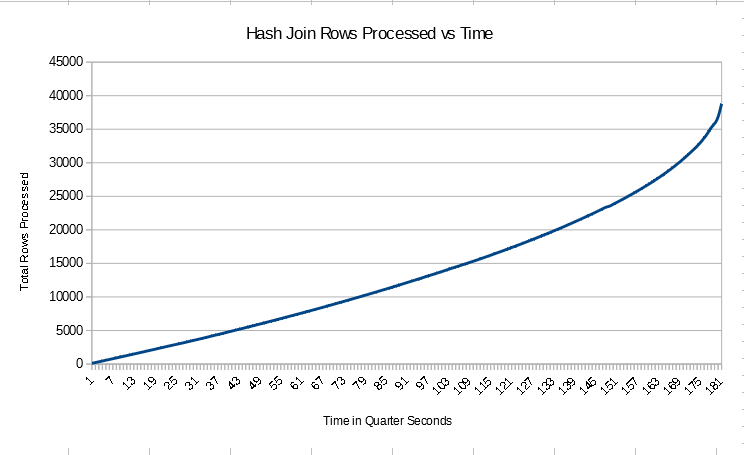
In fact, the query seemed to speed up as time went on. This was unexpected. Perhaps the hash table is built in such a way that the earliest rows for a hash value are at the end of the linked list and the last values processed are at the start? That would explain why the beginning of the query had the lowest number of rows processed per second and the number of rows processed per second increased over time. This is complete speculation on my part and is very likely to be wrong.
The costing for the hash join with the new CE is disappointing. All of the information is available in the statistics to suggest that we’ll get the worst case for the hash join but the total query cost is only 0.75 optimizer units. The legacy CE does better with a total query cost of 100.75 optimizer units but the hash join is still selected.
For merge join the data is only sorted by ID1 for the join:
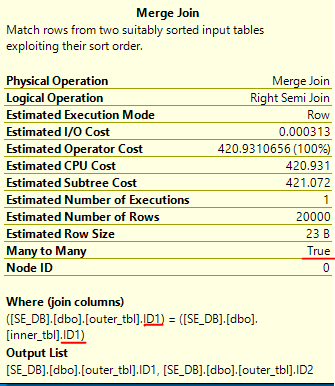
The other part of the join involving the ID2 column is processed as a residual. This is also a many-to-many join. Craig Freedman has a good explanation of how many-to-many joins can lead to a lot of extra work in the join operator:
Merge join can also support many-to-many merge joins. In this case, we must keep a copy of each row from input 2 whenever we join two rows. This way, if we later find that we have a duplicate row from input 1, we can play back the saved rows. On the other hand, if we find that the next row from input 1 is not a duplicate, we can discard the saved rows. We save these rows in a worktable in tempdb. The amount of disk space we need depends on the number of duplicates in input 2.
We have the maximum number of duplicates per possible. It seems reasonable to expect very bad performance along with lots of tempdb activity. Since we’re reading the data in order we might expect to see the maximum rate of rows processed per second to be at the beginning and for the query to slow down as time goes on. As ID2 increases we need to read through more and more previous rows in tempdb. My intuition does not match reality at all in this case. There’s some silly bug with sys.dm_exec_query_profiles that needs to be worked around (merge join always reports 0 rows returned), but the rows processed per second was linear:
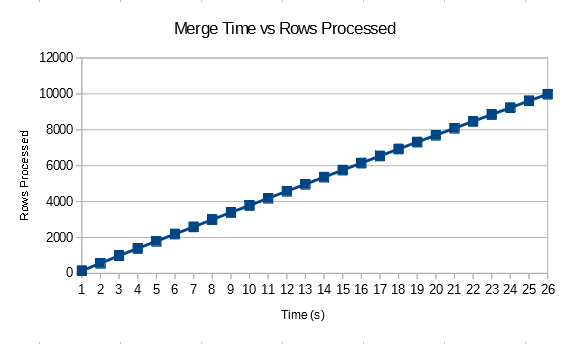
The logical reads for the join is also linear and stabilizes to 49 reads per row returned with 10k rows in the base table.
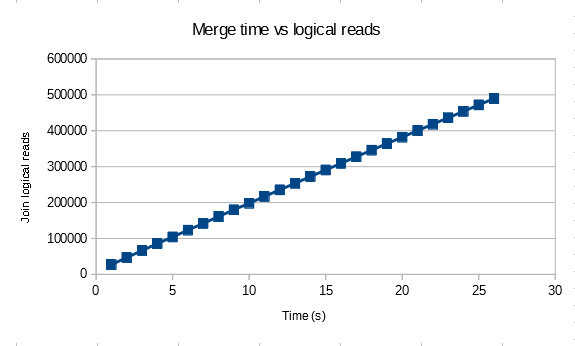
The number of logical reads per row returned stabilizes to 95 when there are 20k rows in the base table. This doesn’t appear to be a coincidence. Perhaps the data stored in tempdb is stored in a format that does not preserve the original ordering. We can look at the merge_actual_read_row_count column from the DMV for the merge join to see that the number of rows read per row processed from the inner table approaches the number of rows in the table. The ramp up happens very quickly. The measurements aren’t very precise, but for the 20k row test I saw that the merge join had processed 380000 rows after just reading 20 rows from the inner table. That would explain why the logical reads and runtime of the merge join grows quadratically with the number of rows in the table but the number of rows processed per second appears to be constant for a given table size.
For the merge join the query optimizer appears to be aware of the problem. Many-to-many joins seem to have quite a bit of a penalty from a costing perspective. With the new CE we get a total query cost of 421.072 optimizer units. The legacy CE gives a very similar cost.
For the loop join we need to pay attention the clustered index seek in the inner part of the join:

The -1 predicate causes trouble here as well. A filter condition will only be used as a seek predicate if it can be safely applied to every row. With the -1 check we don’t have anything to seek against for the inner table, so we only seek against ID1. As before, we should expect to read 200010000 rows from the seek. Our expectations are met:
This is the first join which exposes the problem in a direct way in the XML for the actual plan which is nice. However, the performance will be quadratic with the number of rows in the table as with hash join and merge join. This is the first query that we have a shot at fixing. All that we need to do is to write the join in such a way that a seek can always be performed against the ID2 column in the inner table. The fact that the column cannot be NULL makes this possible. Consider the following query:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND i.ID2 BETWEEN ( CASE WHEN o.ID2 = -1 THEN -9223372036854775808 ELSE o.ID2 END ) AND CASE WHEN o.ID2 = -1 THEN 9223372036854775807 ELSE o.ID2 END ) ) OPTION (MAXDOP 1, LOOP JOIN);
Note that I’m only using BETWEEN to work around a wordpress bug.
When o.ID2 = -1 the code simplifies to the following:
WHERE o.ID1 = i.ID1 AND i.ID2 BETWEEN -9223372036854775808 AND 9223372036854775807
When o.ID2 <> -1 the code simplifies to the following:
WHERE o.ID1 = i.ID1 AND i.ID2 BETWEEN o.ID2 AND o.ID2
In other words, can we use the bounds of the BIGINT to create a seek on ID2 that can always be done:
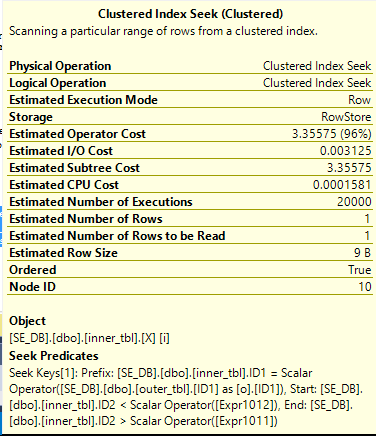
The improved query returns the results with just 47 ms of CPU time. Only 20000 rows are read from the index seek which is the best possible result for our data set. The estimated cost of the query is dramatically reduced to 3.51182 for the new CE, but that isn’t enough for it to be naturally chosen over the much less efficient hash join. That is unfortunate. As you might have guessed the LOOP JOIN hint is not necessary when using the legacy CE.
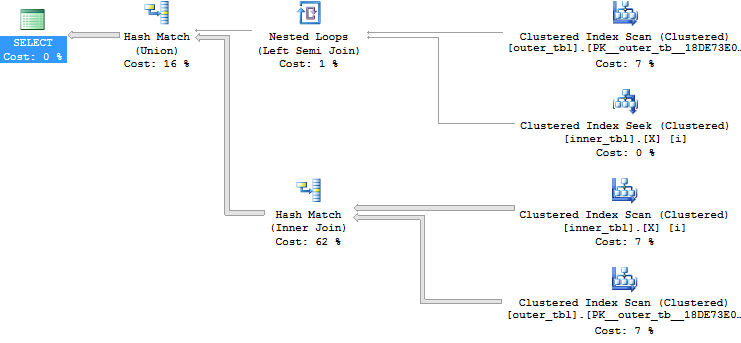
We can avoid the problem all together by changing the join condition to allow joins to work in a much more natural way. Splitting it up with a UNION finishes very quickly with our sample data set:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = i.ID2 ) UNION SELECT * FROM dbo.outer_tbl o WHERE o.ID2 = -1 AND EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 );
Query plan:
Splitting it into two semijoins does fine as well, although the hash match (aggregate) at the end is a bit more expensive for this data set than the hash match (union) employed by the other query:
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = -1 ) OR EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 = i.ID2 );
Query plan:
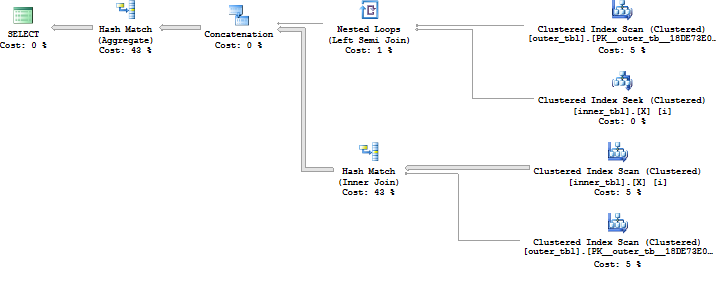
Fully optimizing the above query is an interesting exercise but Paul White already covered the problem quite well here.
At first glance the following query is a little suspicious but the worst case performance scenario wasn’t immediately obvious (at least to me):
SELECT * FROM dbo.outer_tbl o WHERE EXISTS ( SELECT 1 FROM dbo.inner_tbl i WHERE o.ID1 = i.ID1 AND o.ID2 IN (-1, i.ID2) );
In fact, it will even perform well for some data sets. However, as the number of duplicate rows for a single ID grows we can end up with a triangular join. I found it interesting that all three join types scaled in the same way. Thanks for reading!