If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
You already know that your temp table needs an index. Let’s say there’s some query plan ouchie from not adding one. You’ve already realized that you should probably use a clustered index rather than a nonclustered index. Adding a nonclustered index leaves you with a heap and an index, and there are a lot of times when nonclustered indexes won’t be used because they don’t cover the query columns enough.
Do not explicitly drop temp tables at the end of a stored procedure, they will get cleaned up when the session that created them ends.
Do not alter temp tables after they have been created.
Do not truncate temp tables
Move index creation statements on temp tables to the new inline index creation syntax that was introduced in SQL Server 2014.
Where it can be a bad option is:
If you can’t get a parallel insert even with a TABLOCK hint
Sorting the data to match index order on insert could result in some discomfort
After Creation
This is almost always not ideal, unless you want to avoid caching the temp table, and for the recompilation to occur for whatever reason.
It’s not that I’d ever rule this out as an option, but I’d wanna have a good reason for it.
Probably even several.
After Insert
This can sometimes be a good option if the query plan you get from inserting into the index is deficient in some way.
Like I mentioned up above, maybe you lose parallel insert, or maybe the DML Request Sort is a thorn in your side.
This can be awesome! Except on Standard Edition, where you can’t create indexes in parallel. Which picks off one of the reasons for doing this in the first place, and also potentially causes you headaches with not caching temp tables, and statement level recompiles.
One upside here is that if you insert data into a temp table with an index, and then run a query that causes statistics generation, you’ll almost certainly get the default sampling rate. That could potentially cause other annoyances. Creating the index after loading data means you get the full scan stats.
Hooray, I guess.
This may not ever be the end of the world, but here’s a quick example:
DROP TABLE IF EXISTS #t;
GO
--Create a table with an index already on it
CREATE TABLE #t(id INT, INDEX c CLUSTERED(id));
--Load data
INSERT #t WITH(TABLOCK)
SELECT p.OwnerUserId
FROM dbo.Posts AS p;
--Run a query to generate statistics
SELECT COUNT(*)
FROM #t AS t
WHERE t.id BETWEEN 1 AND 10000
GO
--See what's poppin'
SELECT hist.step_number, hist.range_high_key, hist.range_rows,
hist.equal_rows, hist.distinct_range_rows, hist.average_range_rows
FROM tempdb.sys.stats AS s
CROSS APPLY tempdb.sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id, 2) LIKE '#t%'
GO
DROP TABLE #t;
--Create a query with no index
CREATE TABLE #t(id INT NOT NULL);
--Load data
INSERT #t WITH(TABLOCK)
SELECT p.OwnerUserId
FROM dbo.Posts AS p;
--Create the index
CREATE CLUSTERED INDEX c ON #t(id);
--Run a query to generate statistics
SELECT COUNT(*)
FROM #t AS t
WHERE t.id BETWEEN 1 AND 10000
--See what's poppin'
SELECT hist.step_number, hist.range_high_key, hist.range_rows,
hist.equal_rows, hist.distinct_range_rows, hist.average_range_rows
FROM tempdb.sys.stats AS s
CROSS APPLY tempdb.sys.dm_db_stats_histogram(s.[object_id], s.stats_id) AS hist
WHERE OBJECT_NAME(s.object_id, 2) LIKE '#t%'
GO
DROP TABLE #t;
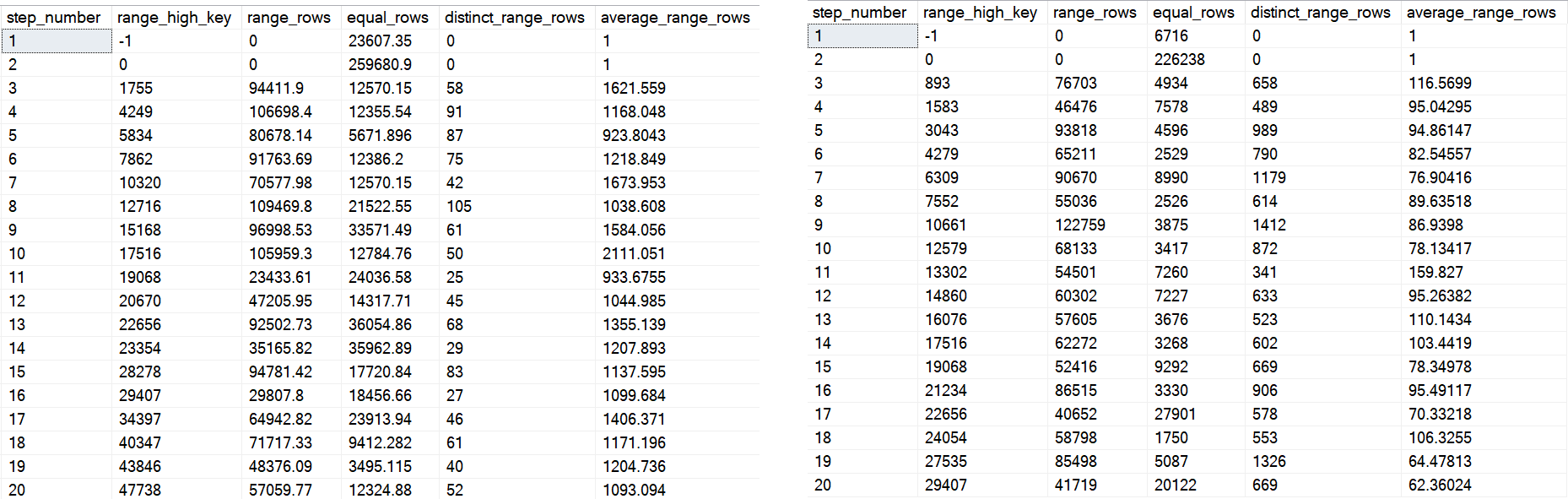
Neckin’ Neck
On the left is the first 20 steps from the first histogram, and on the right is the first 20 from the second one.
You can see some big differences — whether or not they end up helping or hurting performance would take a lot of different tests. Quite frankly, it’s probably not where I’d start a performance investigation, but I’d be lying if I told you it never ended up there.
All Things Considerateded
In general, I’d stick to using the inline index creation syntax. If I had to work around issues with that, I’d create the index after loading data, but being on Standard Edition brings some additional considerations around parallel index creation.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
I’ve posted quite a bit about how cached plans can be misleading.
I’m gonna switch that up and talk about how an actual plan can be misleading, too.
In plans that include calling a muti-statement table valued function, no operator logs the time spent in the function.
Here’s an example:
SELECT TOP (100)
p.Id AS [Post Link],
vs.up,
vs.down
FROM dbo.VoteStats() AS vs --The function
JOIN dbo.Posts AS p
ON vs.postid = p.Id
WHERE vs.down > vs.up_multiplier
AND p.CommunityOwnedDate IS NULL
AND p.ClosedDate IS NULL
ORDER BY vs.up DESC
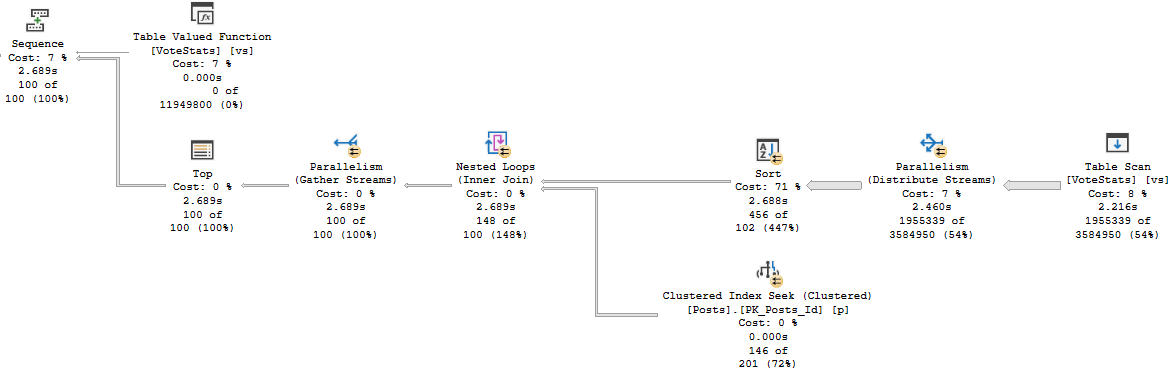
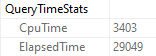
When I run the query, it drags on for 30-ish seconds, but the plan says that it only ran for about 2.7 seconds.
As we proceed
But there it is in Query Time Stats! 29 seconds. What gives?
Hi there!
Estimations
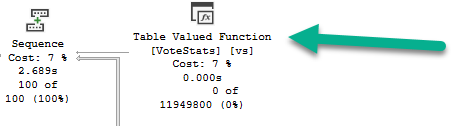
If we look at the estimated plan for the function, we can see quite a thick arrow pointing to the table variable we populate for our results.
Meatballs
That process is all part of the query, but it doesn’t show up in any of the operators. It really should.
More specifically, I think it should show up right here.
Thanks for reading!
Going Further
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.
Of the new things in SQL Server 2019 that I plan on presenting about, the Batch Mode on Row Store (BMOR, from here) enhancements are probably the most interesting from a query tuning point of view.
The thing with BMOR is that it’s not just one thing. Getting Batch Mode also allows Adaptive Joins and Memory Grant Feedback to kick in.
But they’re all separate heuristics.
Getting Batch Mode
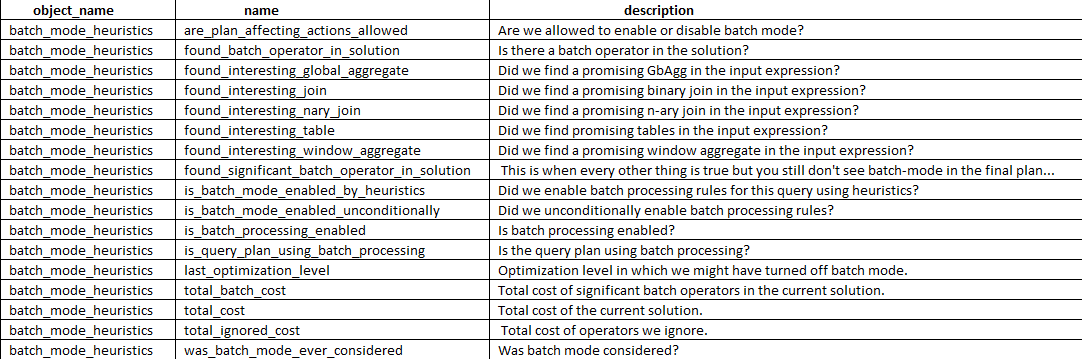
To get Batch Mode to kick in for a Row Store query, it has to pass a certain set of heuristics, which can be viewed in Extended Events.
SELECT dxoc.object_name, dxoc.name, dxoc.description
FROM sys.dm_xe_object_columns AS dxoc
JOIN sys.dm_xe_objects AS dxo
ON dxo.package_guid = dxoc.object_package_guid
AND dxo.name = dxoc.object_name
WHERE dxo.name = 'batch_mode_heuristics' AND dxoc.column_type = 'data'
ORDER BY dxoc.name;
Once we’ve got Batch Mode, we can use the other stuff. But they have their own jim-jams.
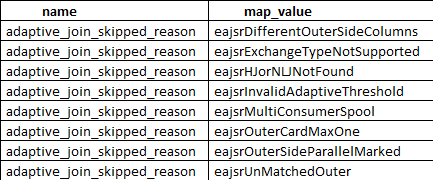
Getting Adaptive Joins
To get Adaptive Joins, you need to pass these heuristics.
SELECT dxmv.name,
dxmv.map_value,
dxo.description
FROM sys.dm_xe_map_values AS dxmv
JOIN sys.dm_xe_objects AS dxo
ON dxmv.object_package_guid = dxo.package_guid
AND dxmv.name = dxo.name
WHERE dxmv.name = 'adaptive_join_skipped_reason';
Try refreshing
No, those aren’t plain English, but you can decode most of them. They mostly deal with index matching, and cardinality making sense to go down this route.
For excessive grants, if the granted memory is more than two times the size of the actual used memory, memory grant feedback will recalculate the memory grant and update the cached plan. Plans with memory grants under 1MB will not be recalculated for overages.
For insufficiently sized memory grants that result in a spill to disk for batch mode operators, memory grant feedback will trigger a recalculation of the memory grant. Spill events are reported to memory grant feedback and can be surfaced via the spilling_report_to_memory_grant_feedback XEvent event. This event returns the node id from the plan and spilled data size of that node.
We can still see some stuff, though.
SELECT dxoc.object_name,
dxoc.name,
dxoc.description
FROM sys.dm_xe_object_columns AS dxoc
JOIN sys.dm_xe_objects AS dxo
ON dxo.package_guid = dxoc.object_package_guid
AND dxo.name = dxoc.object_name
WHERE dxo.name = 'memory_grant_feedback_loop_disabled'
AND dxoc.column_type = 'data'
UNION ALL
SELECT dxoc.object_name,
dxoc.name,
dxoc.description
FROM sys.dm_xe_object_columns AS dxoc
JOIN sys.dm_xe_objects AS dxo
ON dxo.package_guid = dxoc.object_package_guid
AND dxo.name = dxoc.object_name
WHERE dxo.name = 'memory_grant_updated_by_feedback'
AND dxoc.column_type = 'data'
ORDER BY dxoc.name;
Leeches
Getting All Three
In SQL Server 2019, you may see plans with Batch Mode operators happening for Row Store indexes, but you may not get an Adaptive Join, or Memory Grant Feedback. If you have a lot of single-use plans, you’ll never see them getting Memory Grant Feedback (I mean, they might, but it won’t matter because there won’t be a second execution, ha ha ha).
It’s important to remember that this isn’t all just one feature, but a family of them for improving query performance for specific scenarios.
If this is the kind of SQL Server stuff you love learning about, you’ll love my training. I’m offering a 75% discount to my blog readers if you click from here. I’m also available for consulting if you just don’t have time for that and need to solve performance problems quickly.